
こんにちは、株式会社AJA の SSP Division でソフトウェアエンジニアをしている石上敬祐(@kei01234kei)です。こちらはCyberAgent Developers Advent Calendar 2025 21日目の記事です。
私は Kubernetes 1.35 の release cycle において release team の release signal というグループに所属し、Kubernetes の CI 周りの監視をするお仕事をしていました(Kubernetes v1.35 Release Team)。このお仕事の中で Kubernetes の CI 環境が興味深く、よくできているという印象を持ちました。そこで今回は、Kubernetes の CI 基盤について deep dive した内容をご紹介します。
目次
- Kubernetes の test infra の概要
- job のトリガーについて
- 個人的に特に面白いテストをご紹介
- まとめ
Kubernetes の test infra の概要
test infra とは Kubernetes の CI 基盤のことで、prow や testgrid、triage などの様々なコンポーネントから構成されています。以下が test infra のアーキテクチャ図です。
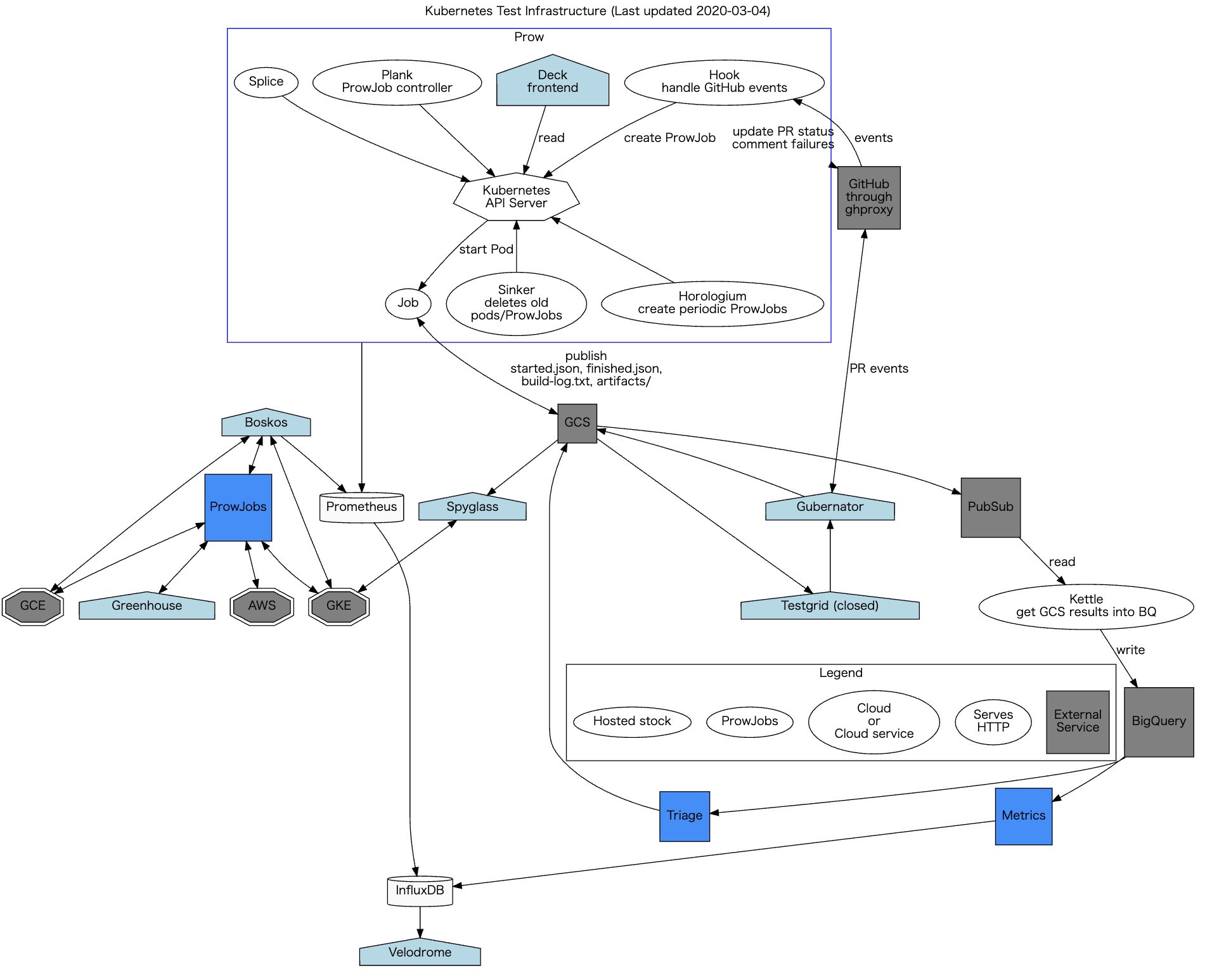
{kind=link}
画像からもわかるように、test infra は GKE や EKS、GCS、BigQuery などのクラウドサービスを活用して構成されています。ここで、 test infra の主要コンポーネントである prow、testgrid、triage についてご説明します。
Prow
Prow は Kubernetes ベースの CI/CD システムで、Kubernetes プロジェクトの CI 基盤の中核を担っています。Prow の特徴は ChatOps 機能と、シンプルで使いやすい UI です。ChatOps 機能により、GitHub の PR コメント欄で /lgtm、/approve、/retest などのスラッシュコマンドを使って、レビューやテストの再実行などの操作を行うことができます。
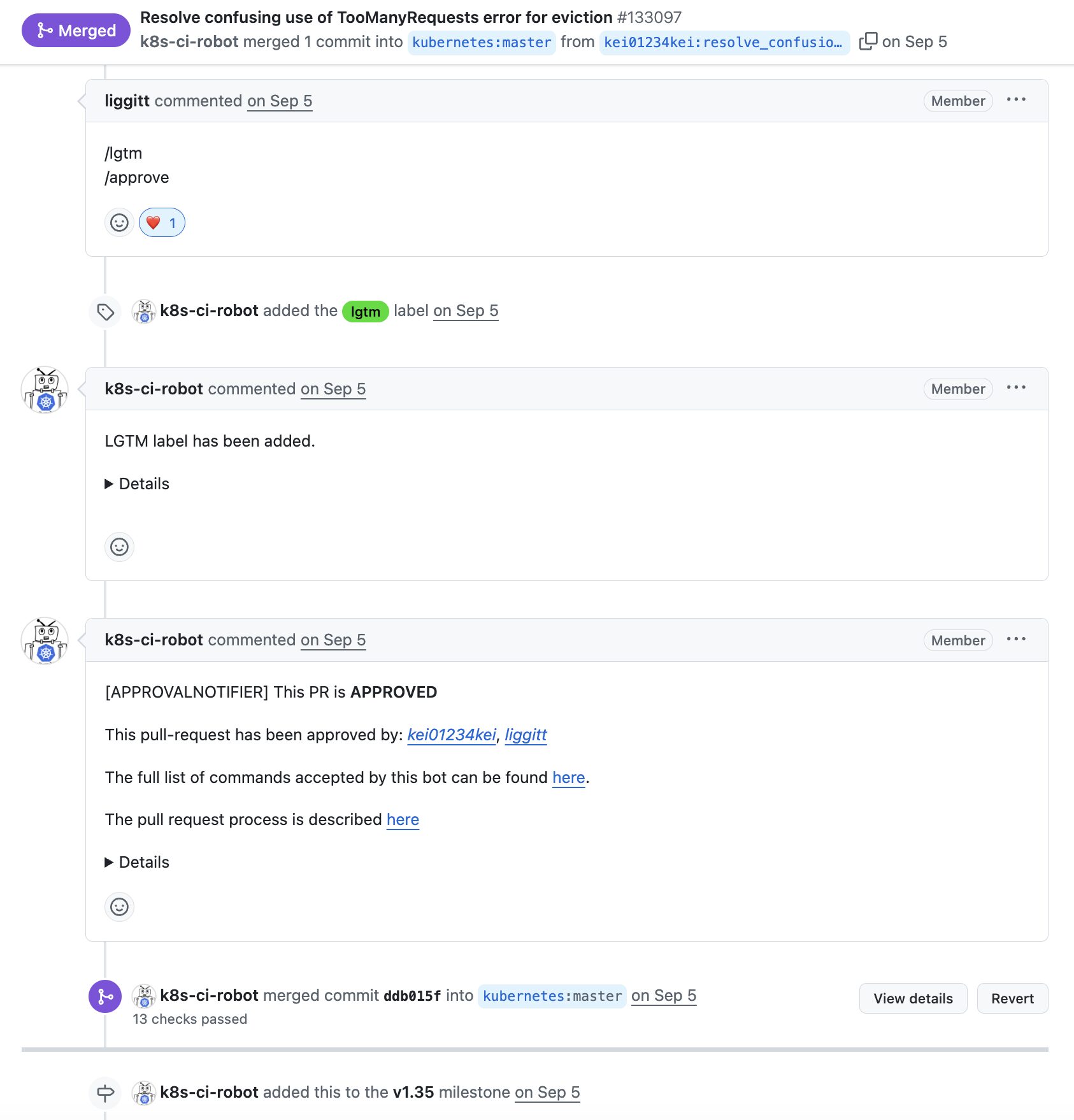
引用: https://github.com/kubernetes/kubernetes/pull/133097
下の画像は Prow の job 実行結果の UI です。シンプルでテスト失敗時のログ確認がしやすく、個人的にかなり気に入っています。
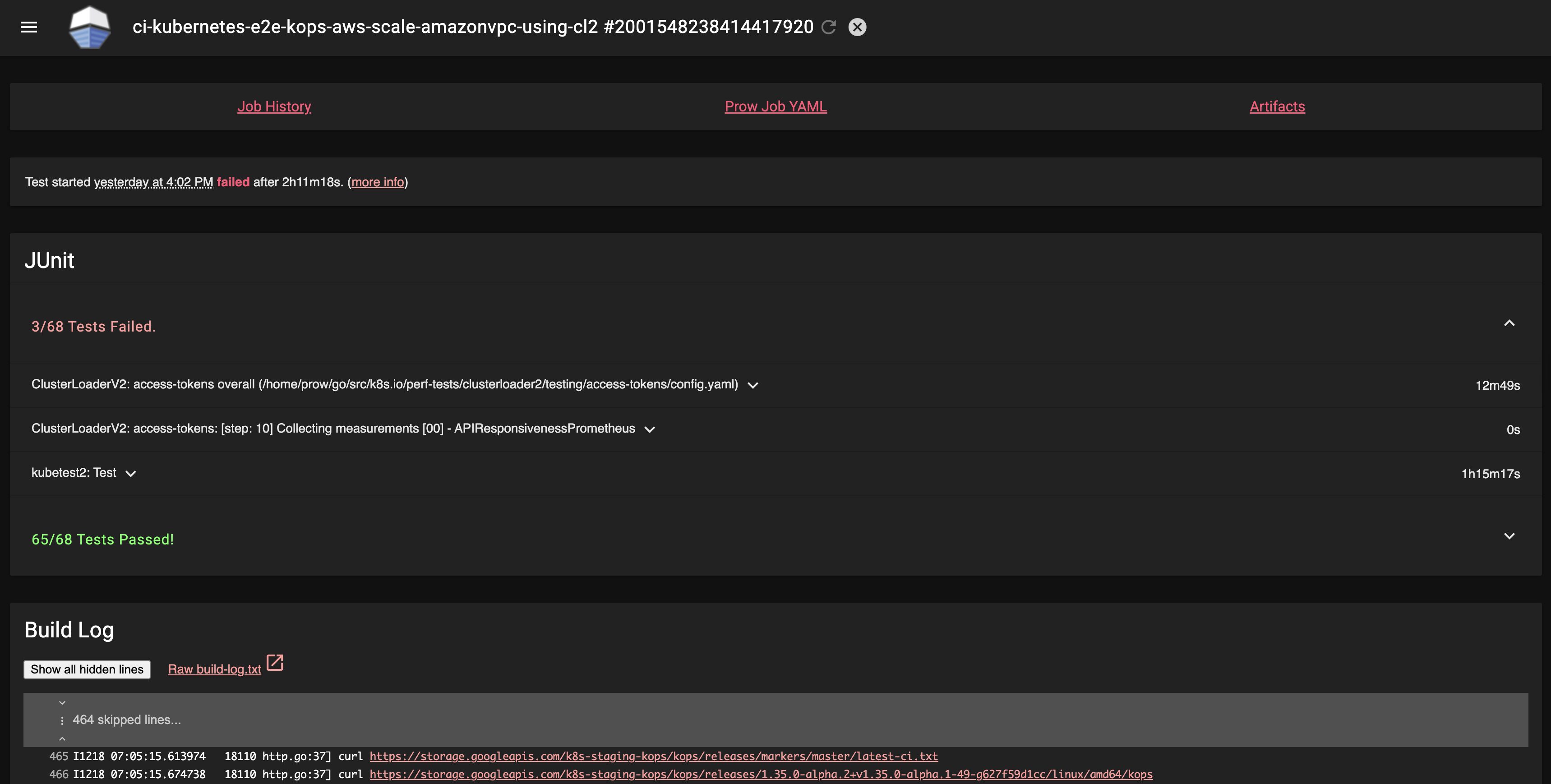
TestGrid
TestGrid は Kubernetes の CI テスト結果を可視化するダッシュボードです。Prow が Google Cloud Storage にアップロードしたテスト実行結果を読み取り、それらを時系列で表示します。
TestGrid は各ダッシュボードタブに対して、最近のテスト実行結果に基づいてステータスを割り当てます。
- PASSING: 最近のテスト実行で失敗が見つからない
- FAILING: 最近のテスト実行で一貫した失敗がある
- FLAKY: 合格でも不合格でもなく、少なくとも 1 つの最近の失敗結果がある
主要な job が flaky または failing ステータスになると release team に通知としてメールが送信される仕組みもあり、個人的にとても助かっています。
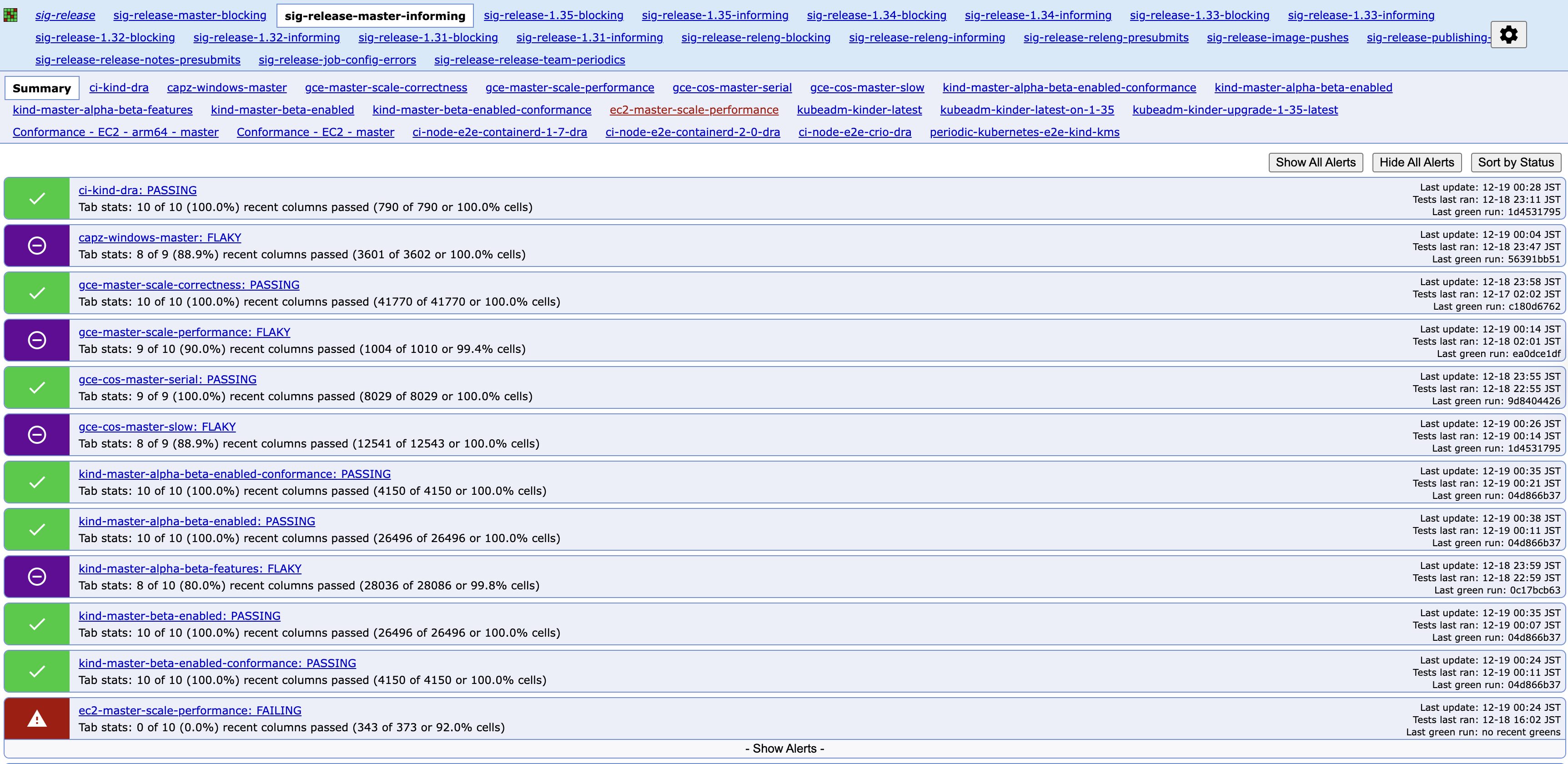
引用: https://testgrid.k8s.io/sig-release-master-informing
gce-master-scale-performance job の test 実行結果一覧を確認できるタブ。特定のテストが継続的に失敗しているのか、それとも散発的に失敗している(flaky)のかを一目で把握できます。
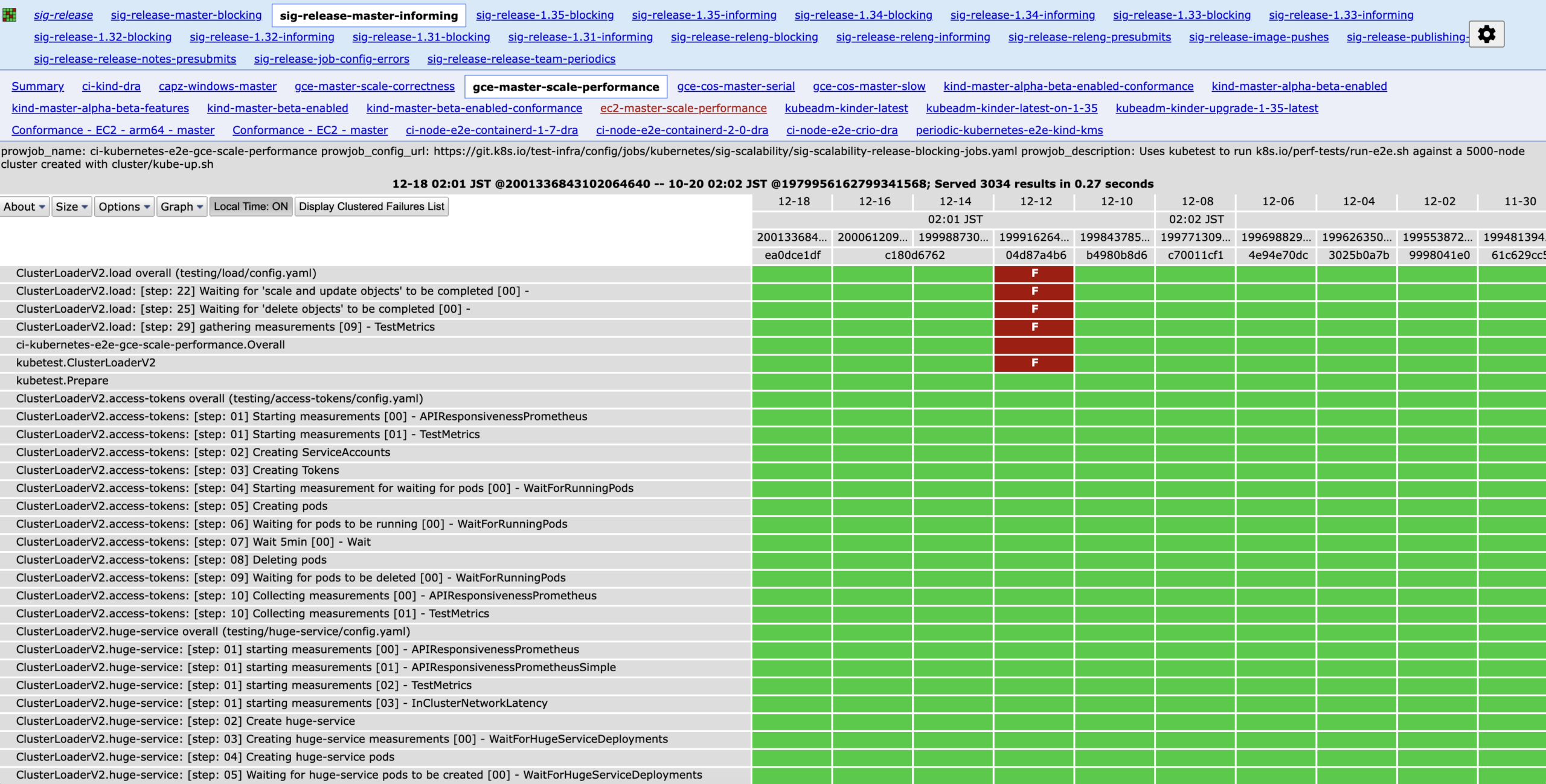
引用: https://testgrid.k8s.io/sig-release-master-informing#gce-master-scale-performance
Triage
Triage は、類似したテスト失敗をクラスタリングして表示するツールです。Kubernetes プロジェクト全体で発生している似たようなテスト失敗を自動的にグループ化することで、共通の原因を持つ問題を効率的に特定できます。
Triage は BigQuery から過去 14 日間のテスト失敗データを取得し、以下の 2 段階でクラスタリングを行います。
- ローカルクラスタリング
各テストの失敗メッセージを類似度に基づいてグループ化します。例えば、test-e2e-gce というテスト内で発生した失敗のうち、エラーメッセージが似ているものを一つのローカルクラスタにまとめます。処理後のデータ構造は テスト名 ⇒ ローカルクラスタテキスト ⇒ テスト失敗のグループ となります。
- グローバルクラスタリング
異なるテスト間で類似したローカルクラスタを見つけ、それらを統合します。例えば、test-e2e-gce と test-e2e-aws で似たようなエラーメッセージのクラスタが見つかった場合、それらを一つのグローバルクラスタにマージします。最終的なデータ構造は グローバルクラスタテキスト ⇒ テスト名 ⇒ テスト失敗のグループ となります。
参照: https://github.com/kubernetes/test-infra/tree/master/triage#methodology
類似度の計算には Ukkonen のアルゴリズムという編集距離アルゴリズムが使用されています。これは従来のレーベンシュタイン距離を計算する動的計画法が O(distance²) の空間計算量を必要とするのに対し、O(distance) に削減した効率的な実装になっています。
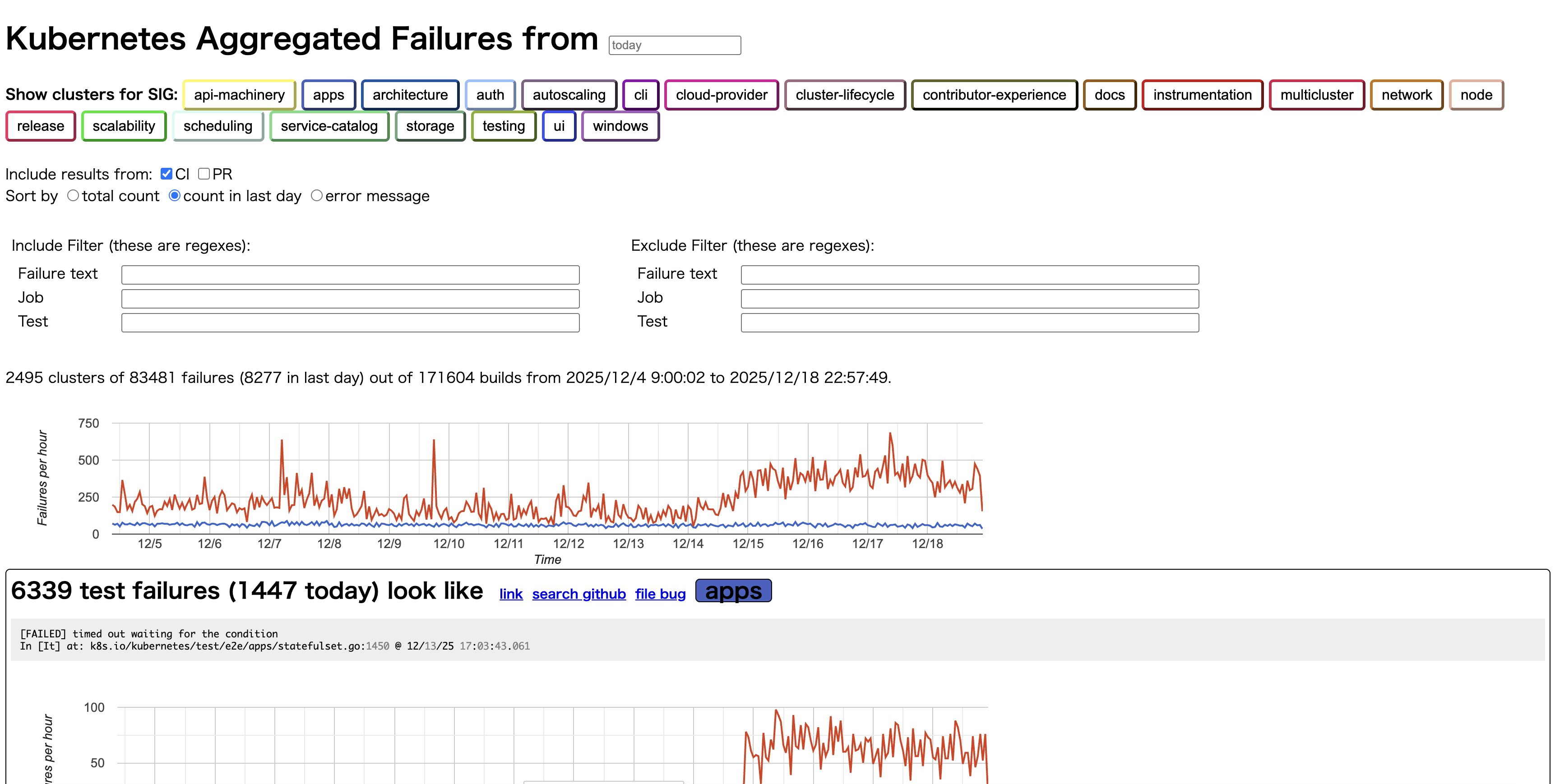
Triage は job をまたいで散発的に発生する flaky なテストの調査に便利で、TestGrid では個別の job ごとにしか確認できない失敗パターンを横断的に把握できます。
job のトリガーについて
Prow では、様々なタイミングで job をトリガーする仕組みが用意されています。job は大きく 3 つのタイプに分類されます。
1. Presubmit job
Presubmit job は PR が作成されたときにトリガーされる job です。マージ前のコードに対してテストを実行し、変更が環境を壊さないといったことを検証します。
例えば、pull-kubernetes-verify という job は、PR が作成されるたびに自動的に実行され、コードのフォーマットチェックや lint、単体テストなどの軽量な検証を行います。 https://github.com/kubernetes/test-infra/blob/e0471ba2f38f64082799de685fa3c92b6468fcaf/config/jobs/kubernetes/sig-testing/verify.yaml#L3-L46
2. Postsubmit job
Postsubmit job は PR がマージされ、新しいコミットが作成されたときにトリガーされる job です。マージ後のコードに対してテストを実行し、main ブランチの品質を確認します。
例えば、etcd-manager-postsubmit-push-to-staging という job は、main ブランチにコードがマージされた後、自動的に実行され、コンテナイメージをビルドして staging registry に push します。Postsubmit job は main ブランチの品質を継続的に監視する役割を担っています。
3. Periodic job
Periodic job は時間ベースでトリガーされる job で、git の変更とは無関係に定期的に実行されます。cron 形式で実行タイミングを指定できます(例: cron: "05 15 * * 1-5" で月曜から金曜の 15:05 UTC に実行)。
代表的な例として、ci-kubernetes-e2e-gce-scale-performance という job があります。この job は Kubernetes の大規模環境でのパフォーマンステストを実行するもので、5000 ノードのクラスタを構築して様々な負荷テストを行います。このような大規模なテストは実行に数時間かかり、大量のリソースを消費するため、毎回の PR やコミットで実行するのは現実的ではありません。そのため、periodic job として定期的(2 日に 1 回)に実行されています。これにより、CI インフラのコストとパフォーマンスのバランスを取りながら、継続的に品質を監視できます。
参照: https://docs.prow.k8s.io/docs/jobs/
個人的に特に面白いテストをご紹介
最後に、特に興味深いと思ったテストをいくつかご紹介します。
1. ci-kubernetes-e2e-gce-scale-performance
このテストは、Kubernetes の大規模環境でのパフォーマンスとスケーラビリティを検証するテストです。5000 ノードという非常に大規模なクラスタを GCE 上に構築します。
Load test では約 30 * ノード数 の Pod を作成するため、5000 ノードの場合は約 150,000 個の Pod が作成されます。
Kubernetes が公式にサポートする上限(5000 ノード、150,000 Pod)は、この ci-kubernetes-e2e-gce-scale-performance テストで検証されていることに基づいています。つまり、このテストが継続的に成功することで、Kubernetes コミュニティは「5000 ノード、150,000 Pod までは問題なく動作する」と保証できるのです。
参照:
- https://github.com/kubernetes/test-infra/blob/e0471ba2f38f64082799de685fa3c92b6468fcaf/config/jobs/kubernetes/sig-scalability/sig-scalability-release-blocking-jobs.yaml#L76-L184
- https://github.com/kubernetes/perf-tests/blob/f2161acad93424407ca23f483aec4b84511e7b81/clusterloader2/testing/load/config.yaml#L12
2. ci-kubernetes-kubemark-gce-scale
Kubemark は、シミュレートされたクラスタで実験を行うことができるパフォーマンステストツールです。このテストの特徴は、hollow ノードと呼ばれる軽量な疑似ノードを使用することです。
Hollow ノードは実際にはコンテナを実行せず、ストレージもアタッチしませんが、etcd への更新などを含め、あたかも実行しているかのように振る舞います。1 つの hollow ノードは非常に軽量で、84 台の実ノード(各 e2-standard-8)で 5000 個の hollow ノードをシミュレートできます。
このテストの目的は、大規模クラスタでのみ現れるマスターコンポーネント(API server、controller manager、scheduler)の問題(例: 小さなメモリリーク)を発見することです。実際の 5000 ノードクラスタを構築するには膨大なコストがかかりますが、Kubemark を使うことで費用対効果の高いテストが可能になります。
参照:
- https://github.com/kubernetes/test-infra/blob/e0471ba2f38f64082799de685fa3c92b6468fcaf/config/jobs/kubernetes/sig-scalability/sig-scalability-periodic-jobs.yaml#L441-L525
- https://github.com/kubernetes/community/blob/master/contributors/devel/sig-scalability/kubemark-guide.md
まとめ
今回は、Kubernetes の CI 基盤に deep dive してきました。
Kubernetes の CI 基盤は、Prow、TestGrid、Triage といった複数のコンポーネントが連携して動作しており、それぞれが重要な役割を担っています。Prow は ChatOps 機能とシンプルな UI で job の実行を管理し、TestGrid は GCS からテスト結果を読み取って時系列で可視化し、Triage は BigQuery からデータを取得して類似したテスト失敗をクラスタリングします。
また、job のトリガー方式も、Presubmit、Postsubmit、Periodic の 3 つのタイプがあり、テストの特性や実行コストに応じて適切に使い分けられていることがわかりました。特に ci-kubernetes-e2e-gce-scale-performance のような大規模テストは、Kubernetes が公式にサポートする上限(5000 ノード、150,000 Pod)の根拠となっており、CI 基盤の重要性を物語っています。
Kubernetes の CI 基盤は、単にテストを実行するだけでなく、コストとパフォーマンスのバランスを考慮した設計、効率的な問題発見のための可視化、そして大規模環境での品質保証まで、非常によく設計されたシステムだと感じました。
良い Kubernetes ライフを!Kubernetes の PR や issue などで皆様を見かけることができたら嬉しいです 🙂