
Merry Christmas 🎅🎄
というわけで CyberAgent Group SRE Advent Calendar 2025 25 日目(最終日)になります。
株式会社AbemaTV で SRE / Platform Engineer をしている @ren510dev です。今年に入り Google Cloud Professional 認定資格を全冠 しました。
このブログでは、約半年間にわたり実施してきた ABEMA 広告配信システムの運用基盤および Google Cloud プロジェクト移設の裏側ついて紹介します。
目次
- はじめに
- プロジェクトの背景
- 移行計画とロードマップ
- マネージドサービスの移設戦略
- プロジェクト管理とコミュニケーション計画
- おわりに
1. はじめに
約半年間にわたり、ABEMA の広告配信システムの運用基盤を刷新すべく Google Cloud の移設プロジェクトを推進しました。
このブログでは、大規模な Google Cloud 環境の移設を完遂するための技術戦略、意思決定プロセスやプロジェクトを動かすためのコミュニケーション計画についてハイライトを紹介できればと思います。
2. プロジェクトの背景
ABEMA のサービスを支えるシステムは、開局当初より「ABEMA 本体のアプリケーションを開発するチーム(以後、ABEMA 本体)」と「ABEMA へ広告を入稿・配信するシステムを開発するチーム」の 2 つの運用基盤に分かれています。これまで両者は異なる方針で運用されてきましたが、サービスの成長に伴い、広告配信システムにおいても ABEMA 本体と同等の運用水準や効率性が求められるようになりました。
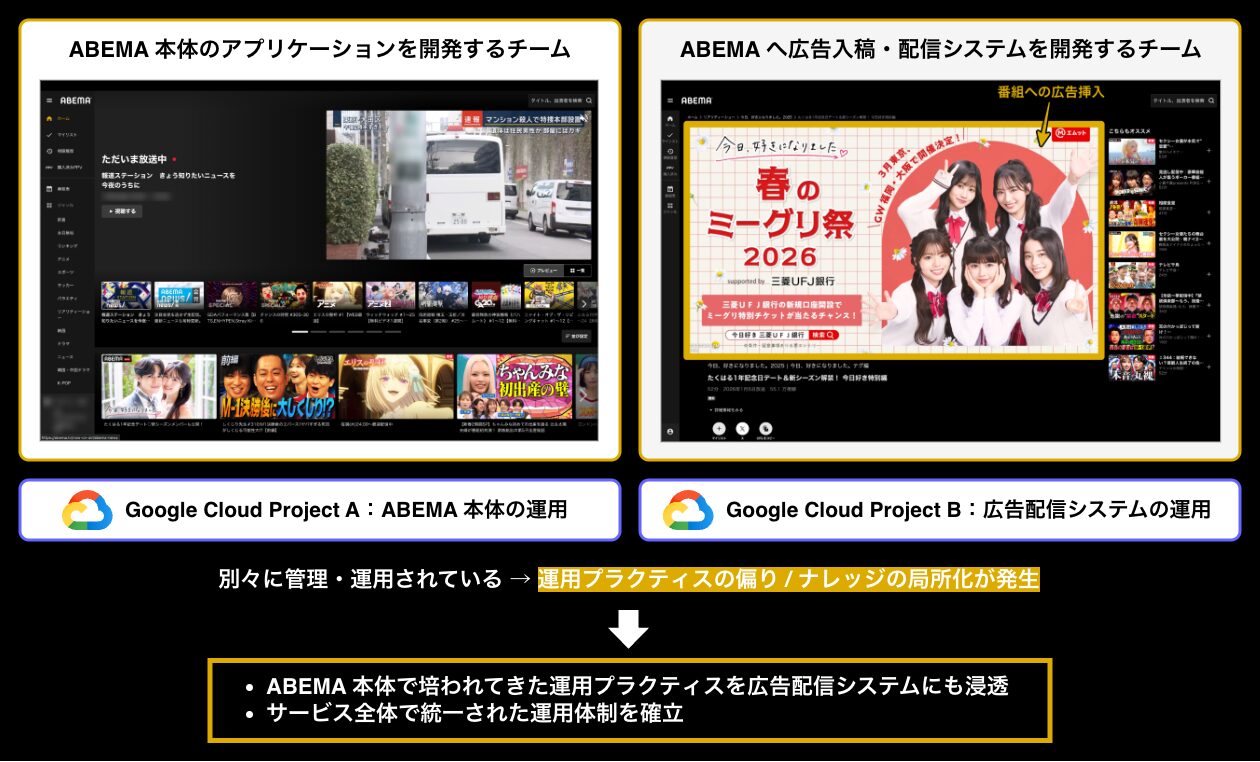
本プロジェクトは、ABEMA 本体で培われてきた運用プラクティスを広告配信システムにも適用し、サービス全体で統一された運用体制を確立することを目指すものです。
しかし、既存のプロジェクト構造がボトルネックとなり、これらを達成するには既存環境の延長ではなく、抜本的な刷新が必要という結論に至りました。
広告配信システム基盤の課題
移設前の環境には、構造的な問題が大きく 3 つあり、これらは技術的負債として日々の運用負荷を高める原因となっていました。
環境混在によるセキュリティ統制の複雑化
開発(DEV)/ 検証(STG)/ 本番(PRD)といった用途が異なる運用環境が混在しており、IAM やネットワークの分離の観点で統一化された運用がなされていない。
ABEMA 本体と広告配信システムとの運用ノウハウの分断
ABEMA 本体で実践している IaC や GitOps、ポリシ管理といった運用ノウハウを広告配信システムの運用基盤に浸透できていない。
手動オペレーションによるスケーリング操作の常態化
高負荷が予想される時間帯に合わせて手動で Pod 数を調整する運用が行われており、スケーリングの自動化が困難になっている。
サービス特性上、番組開始時のスパイク対策として KEDA 等の高度なオートスケーリング機構の導入が求められていましたが、既存構成ではその前提条件となるメトリクス基盤やモニタリングコンポーネントが API バージョンの要件を満たせず、手動運用による対応を余儀なくされていました。
リアーキテクティングへの踏切
これらの構造的な課題は、アプリケーション側だけの対応や、既存インフラ構成を維持したままの改修だけでは解決できません。そこで、既存の構成を部分的に修正するのではなく、Google Cloud プロジェクトそのものを新規に準備し、そこへアプリケーションを移し替えるという、抜本的なリアーキテクティングを行う方針を固めました。
具体的には、以下 3 つの戦略を軸に、新しい運用基盤を再設計しました。
環境混在の解消:Google Cloud プロジェクトの分離
環境毎に独立した Google Cloud プロジェクトを準備し、リソースを完全に分離します。
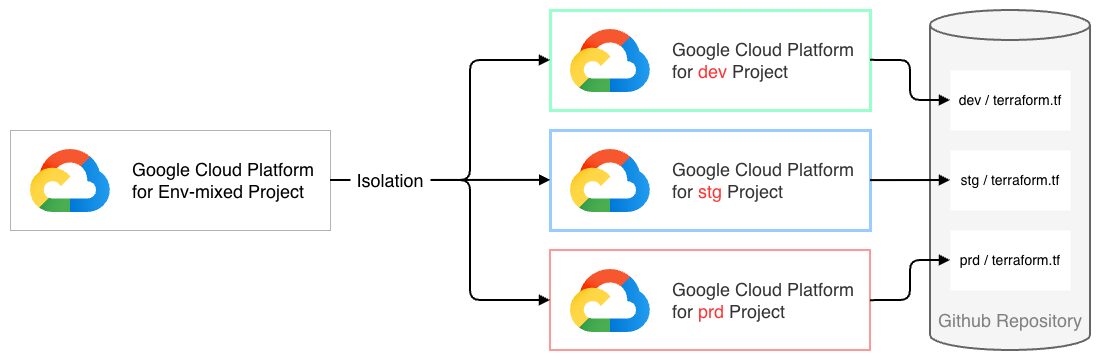
これにより、環境混在によるセキュリティ統制の複雑化を解消し、ネットワークや権限分離を強制することで、開発環境での操作が本番環境へ影響を与えるリスクを低減します。
運用ノウハウの統合:ABEMA 本体標準基盤の採用
独自の基盤構成を廃止し、Terraform によるインフラのコード化(IaC)やポリシ管理、PipeCD による GitOps 運用といった、ABEMA 本体で標準化されている運用アーキテクチャを採用します。
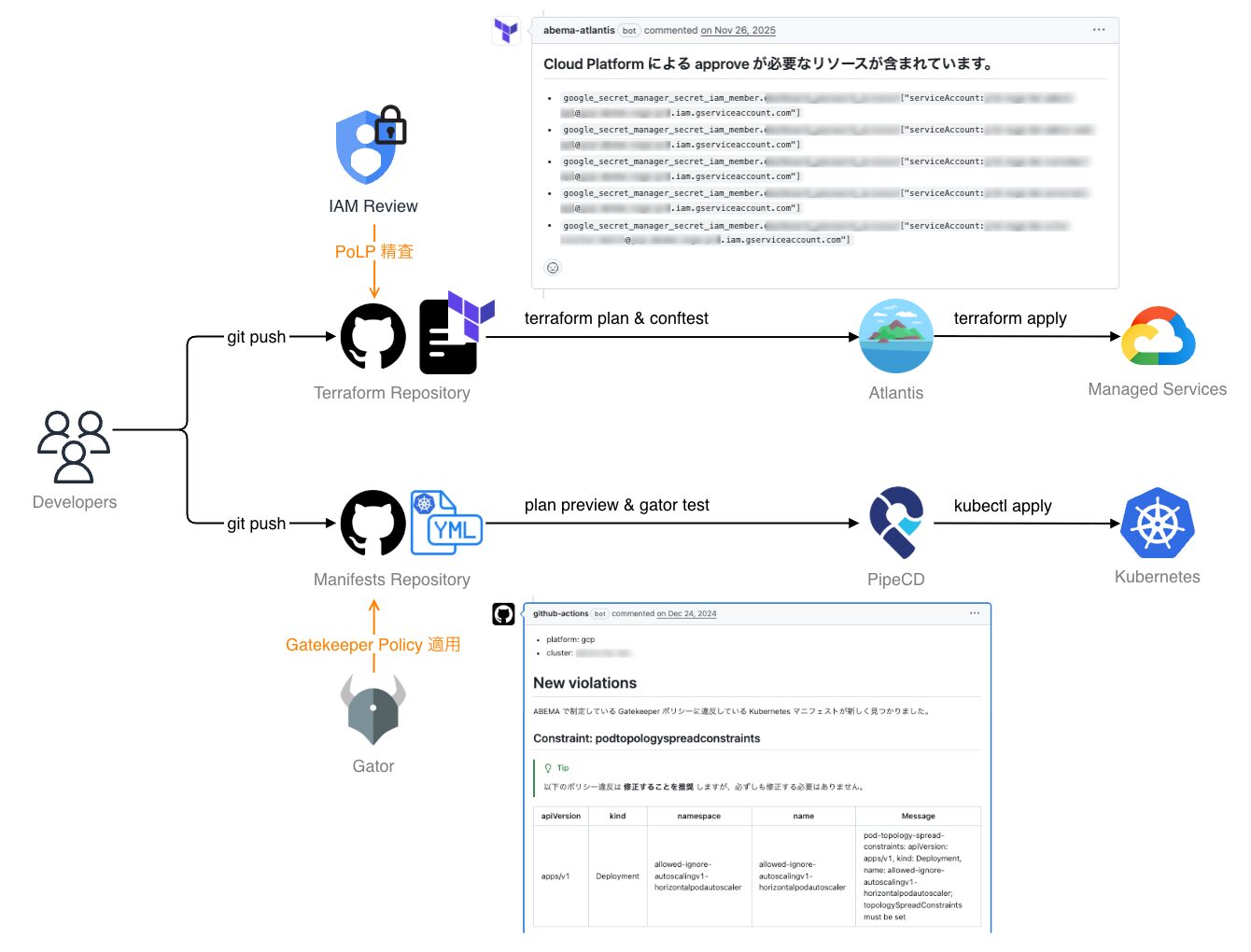
これにより、組織間で分断されていた運用ノウハウやナレッジを統合し、ABEMA 標準のセキュリティ基準や機能改善を継続的に取り込める体制へと引き上げます。
スパイク対策の自動化:KEDA による予測的スケーリングの導入
モニタリング基盤そのものを刷新し、ABEMA 本体ですでに実績のある KEDA(Kubernetes Event Driven Autoscaling)の導入を前提としたプラットフォームを整備します。
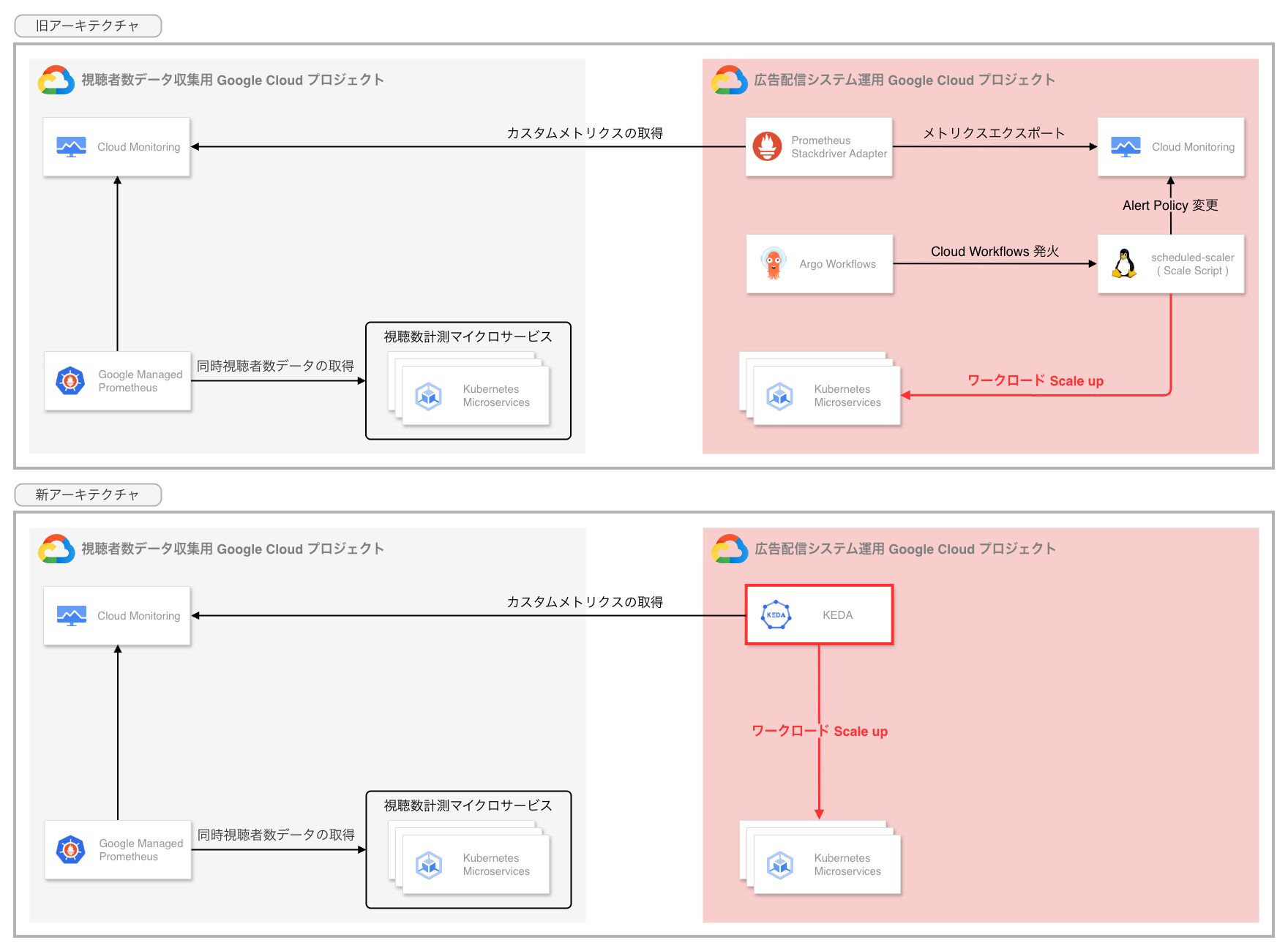
これにより、従来の CPU / Memory 使用率といった指標に加え、番組の視聴予測やリアルタイム視聴データに基づいた予測的な事前スケーリングが可能となり、手動運用からの脱却とスパイクにも耐え得る柔軟なキャパシティ戦略を目指します。
3. 移行計画とロードマップ
移設プロジェクトにおいて最大のリスクは、不具合発生時にインフラ起因なのかアプリケーション起因なのかの切り分けが困難になることです。そのため、今回の移設スコープでは 機能改修やコードのリファクタリングを最小限に抑え、インフラ基盤の刷新のみに注力することで変更変数を最小化 し、トラブルシューティングの複雑さを排除する方針をとりました。
プロジェクト肥大化の防止策策定
本戦略の実効性を担保するため、プロジェクトの遂行基準として以下の 2 点を定義しました。
Definition of Done:ゴール・ノンゴールの明確化
大規模な移設プロジェクトでは、ついつい「あれもこれも」と機能改善や細かな修正を同時に行いたくなりますが、これらはプロジェクトの複雑性を高め、収拾がつかなくなる要因となります。
そこで本プロジェクトでは、「どのような問題を解消すべきか」「今すぐやる必要がないことは何か(やらないことの取り決め)」の議論を徹底し、移設のスコープを明確にしました。具体的には、「新環境への移行」および「旧環境の完全撤去」のみを完了条件 とし、それ以外の改善事項は移設後のフェーズへ先送りする方針(ノンゴール)としました。目的を「移設」一点に絞ることで、プロジェクトの肥大化を防ぎ、確実な完了を優先しました。
Production Readiness:本番データを用いた並行稼働検証
検証環境と本番環境ではデータセットの規模や特性が異なるため、検証環境でのテストだけでは不十分な場合があります。今回は新旧環境間でデータ同期を確立し、切り替え前に本番データを用いた検証(QA)を可能にしました。これにより、クエリパフォーマンスやデータ整合性、権限不足による Permission エラーの問題を、ユーザトラフィックが流れる前に検知・修正する体制を整えました。
基本的な方針
以下は最初に取り決めた方針の一部です。
- Google Cloud プロジェクトは環境毎に準備して各種マネージドサービスを移設する
- Terraform:Atlantis による GitOps 運用(Conftest / IAM レビューポリシの導入)の強制
- Kubernetes マニフェスト:PipeCD による GitOps 運用(Gatekeeper Policy の導入)の強制
- IAM での制御が可能なデータストア(Spanner / Bigtable / Cloud Storage / BigQuery / PubSub 等)は移設を行わずひとまず既存プロジェクトに残留する
- Cloud SQL / Memorystore for Redis に限定する
- MongoDB Atlas は Private Service Connect の接続先のみ変更する
- 可能な限り Ingress に紐付けたドメインによる段階的移行(Phased Migration)でトラフィックを切り替える
- 一括切り替えまたは DNS-WRR(Weighted Round Robin) によりゼロダウンタイムで切り替える
移設期間中の構成
以下はコンポーネントの移設順序の概略です。
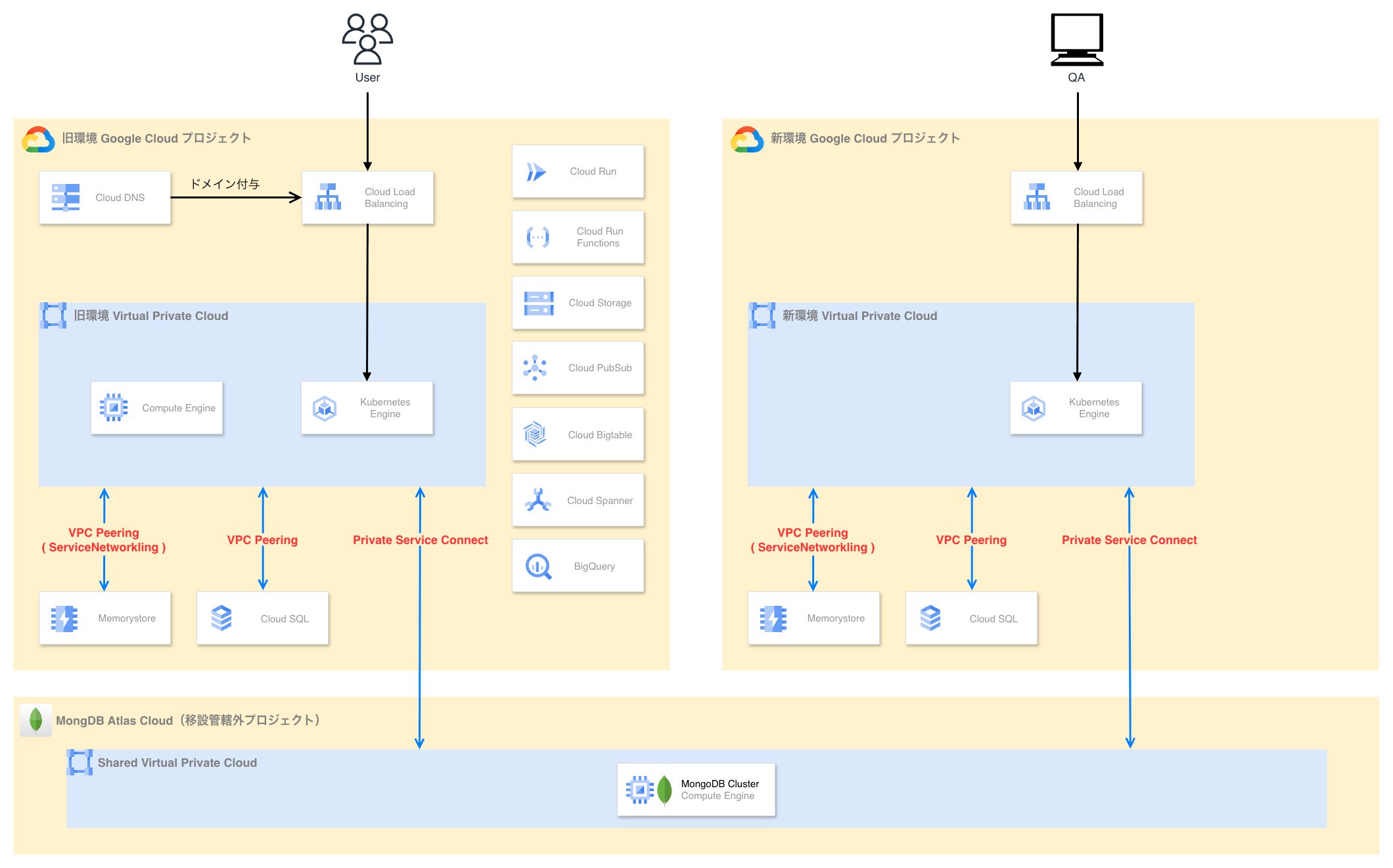
1. 新環境のアクティベーションと旧環境との同期
最初の段階では、GKE ワークロードとデータベースを新環境側で起動させます。
この段階では、Cloud SQL は旧環境とレプリケーションによる同期を行い、Memorystore は既存ワークロードからのダブルライトによって整合性をとります。
また、GKE で稼働する各種ワークロードの Ingress にはダミードメインを付与しておき、これを通じて QA を実施することで、ユーザへの影響を回避しつつ、新環境の検証を実施します。
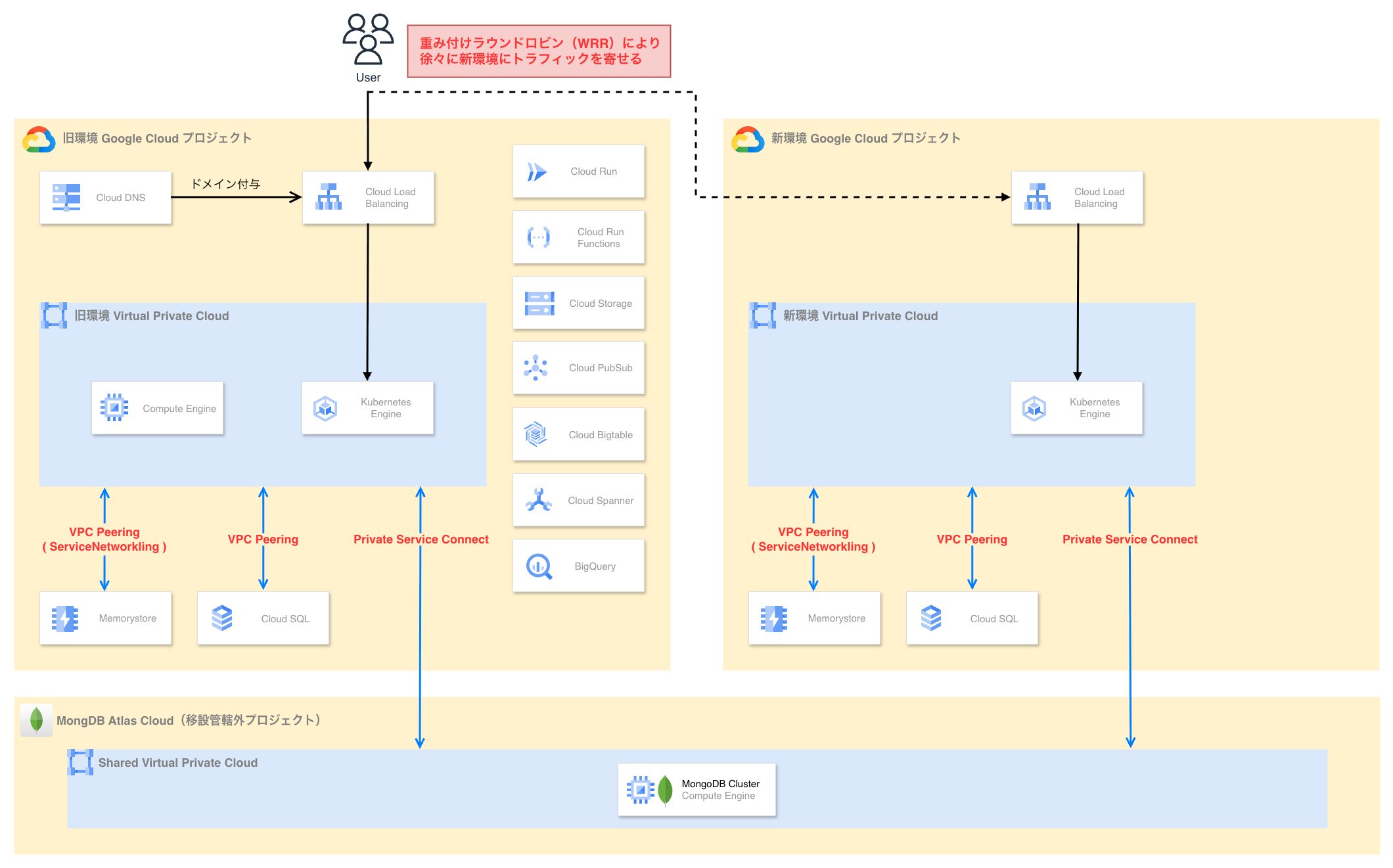
2. 新環境への段階的な切り替え
旧環境の Ingress へ向けているトラフィックを段階的に新環境の Ingress へ切り替えます。
今回は全てのドメインを Cloud DNS で管理しており、WRR によるトラフィック比率を新旧間で段階的に切り替えることでユーザリクエストを新環境へ徐々に流します。
3. Cloud Run / Cloud Run Functions の移設
Cloud Run や Cloud Run Functions といった GKE 以外のサーバレスソリューションで動いている各種コンポーネントを移設します。
この時、ジョブやバッチ処理を行うコンポーネントは段階的な切り替えが難しいと判断し、ユーザリクエストまたはオペレーション業務が極めて少ない時間帯を狙い、一括切り替えによって新環境のアクティベーションを実施する方針としました。
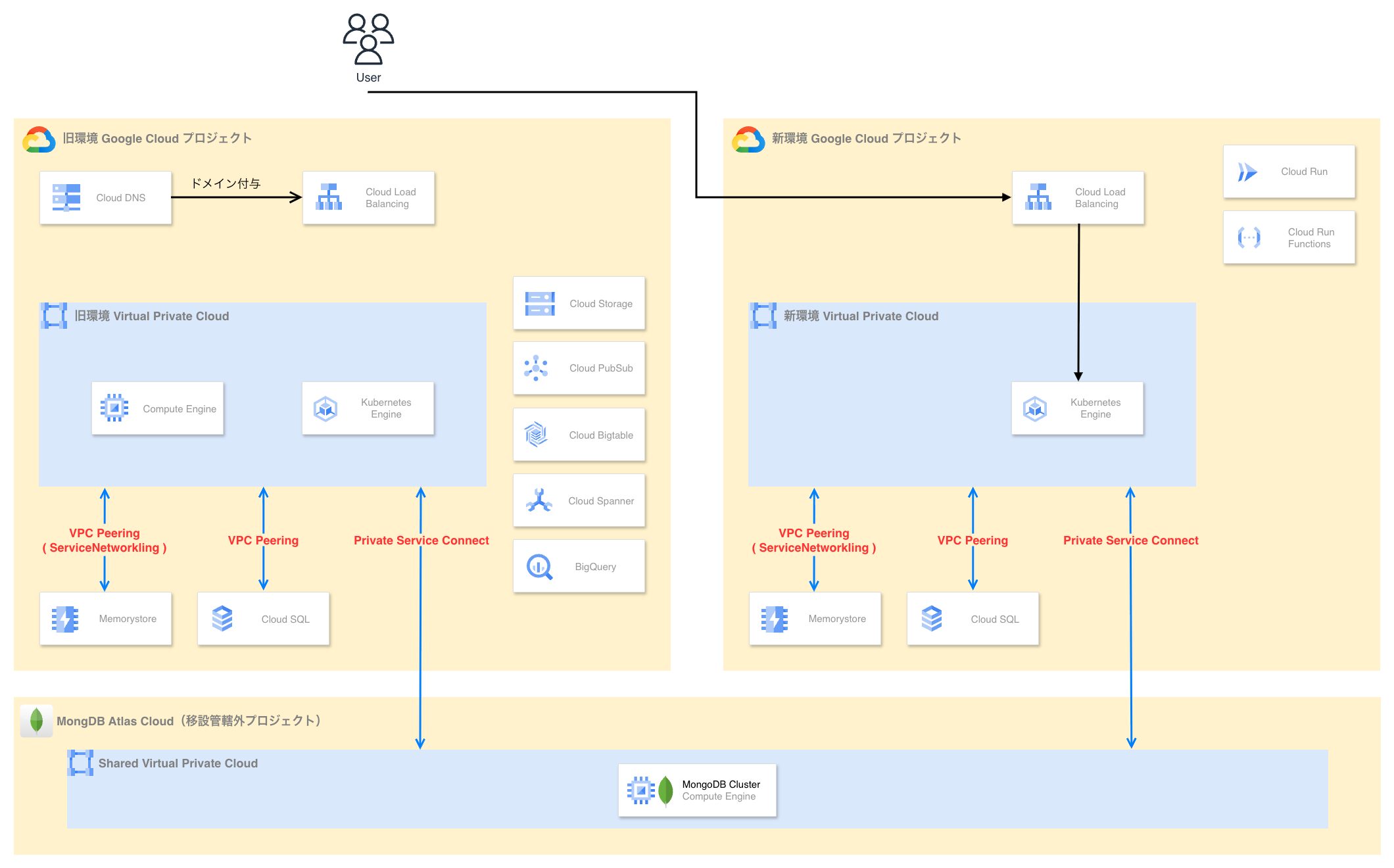
4. 旧環境の縮退作業
ユーザリクエストが新環境に完全に向き切ったことを確認した後、旧環境を縮退させます。
GKE クラスタや関連コンポーネントを停止・削除した後、新環境と同期させていた各種データベースをバックアップ & カットオーバーします。
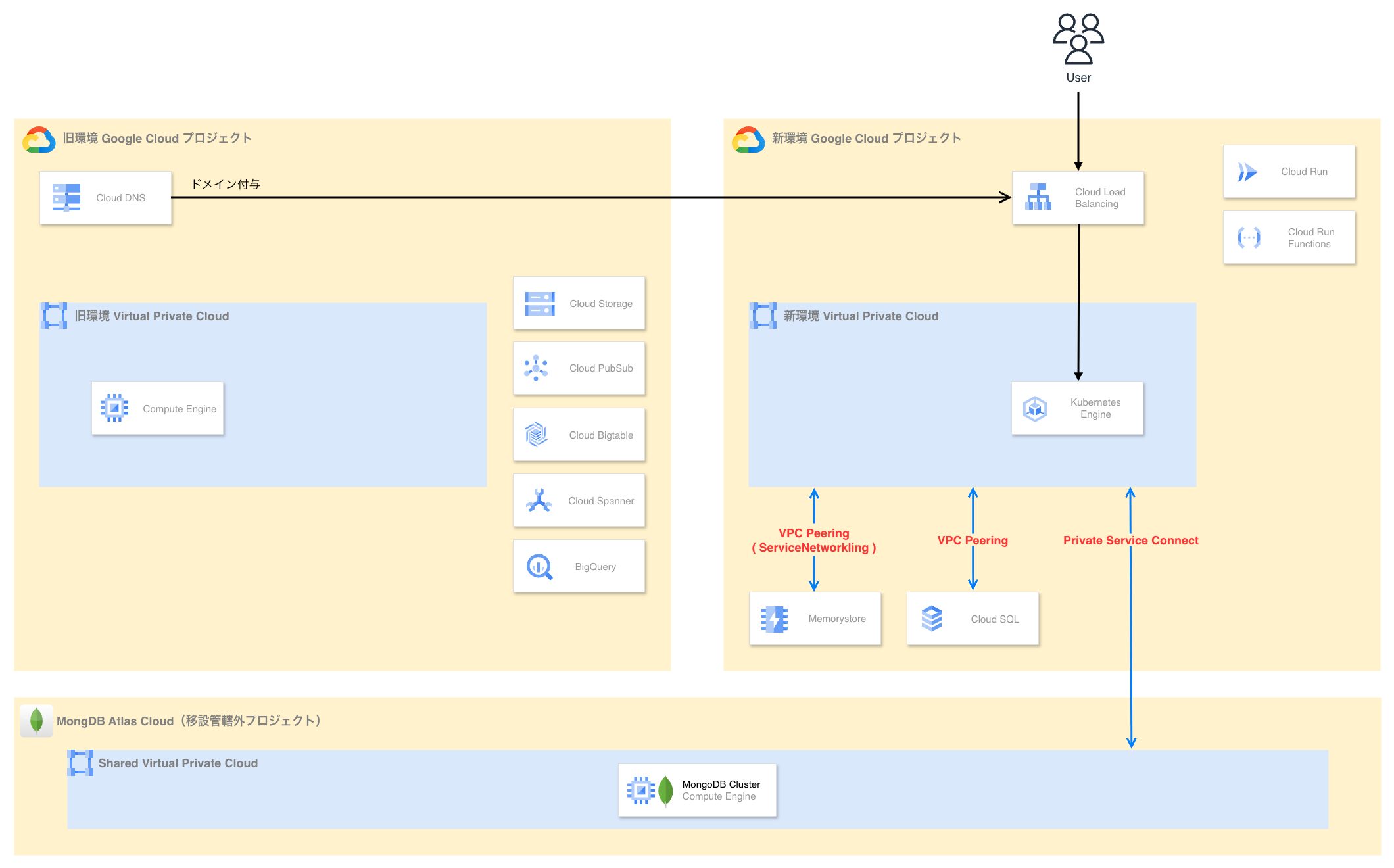
4. マネージドサービスの移設戦略
本プロジェクトでは多数のコンポーネントが対象となりましたが、ここでは特に技術的な工夫や事前の考慮が重要となった 3 つのマネージドサービスに絞って移設手法と戦略を紹介します。
Cloud SQL 移設
Cloud SQL for MySQL の移行には DMS(Database Migration Service)を使用し、ダウンタイムを最小限に抑える構成をとりました。
DMS は、Source データベースから Destination データベースへのデータ移行を支援する Google Cloud のフルマネージドサービスです。初期のフルダンプ(初期スナップショット)移行だけでなく、移行中に Source データベースで発生した変更を継続的にキャプチャして Destination データベースへ適用する CDC(Change Data Capture) 機能を備えています。これにより、移行完了の直前までアプリケーションを停止することなく、新旧データベース間の同期を維持することが可能です。
DMS の詳細に関しては こちらのブログ で詳しく紹介しています。
移行手順の概要
DMS を活用したデータベース移行の基本的な流れは以下の通りです。
- 事前準備:DMS の Migration Job を作成し、旧環境の Cloud SQL(Source)から新環境の Cloud SQL(Destination)へのレプリケーションを開始する
- データ同期:Full Dump による初期データの転送と、CDC による継続的な差分同期が行われ、新旧データベース間の整合性を担保する
- 切替作業:切り替えのタイミングで旧 DB を Read Only 化して更新を停止した後、DMS の同期を終了し、新 DB をプロモーションおよびマスター昇格してスタンドアロン化(Writable)する
レプリケーションネットワークの構成
DMS を利用するためには、Source(旧環境 DB)と Destination(新環境 DB)間の接続経路を確保する必要があります。主な接続方式として、VPC Peering や VPN を介した Private IP 接続と、インターネットを経由する Public IP 接続がありますが、今回は後者を採用することにしました。
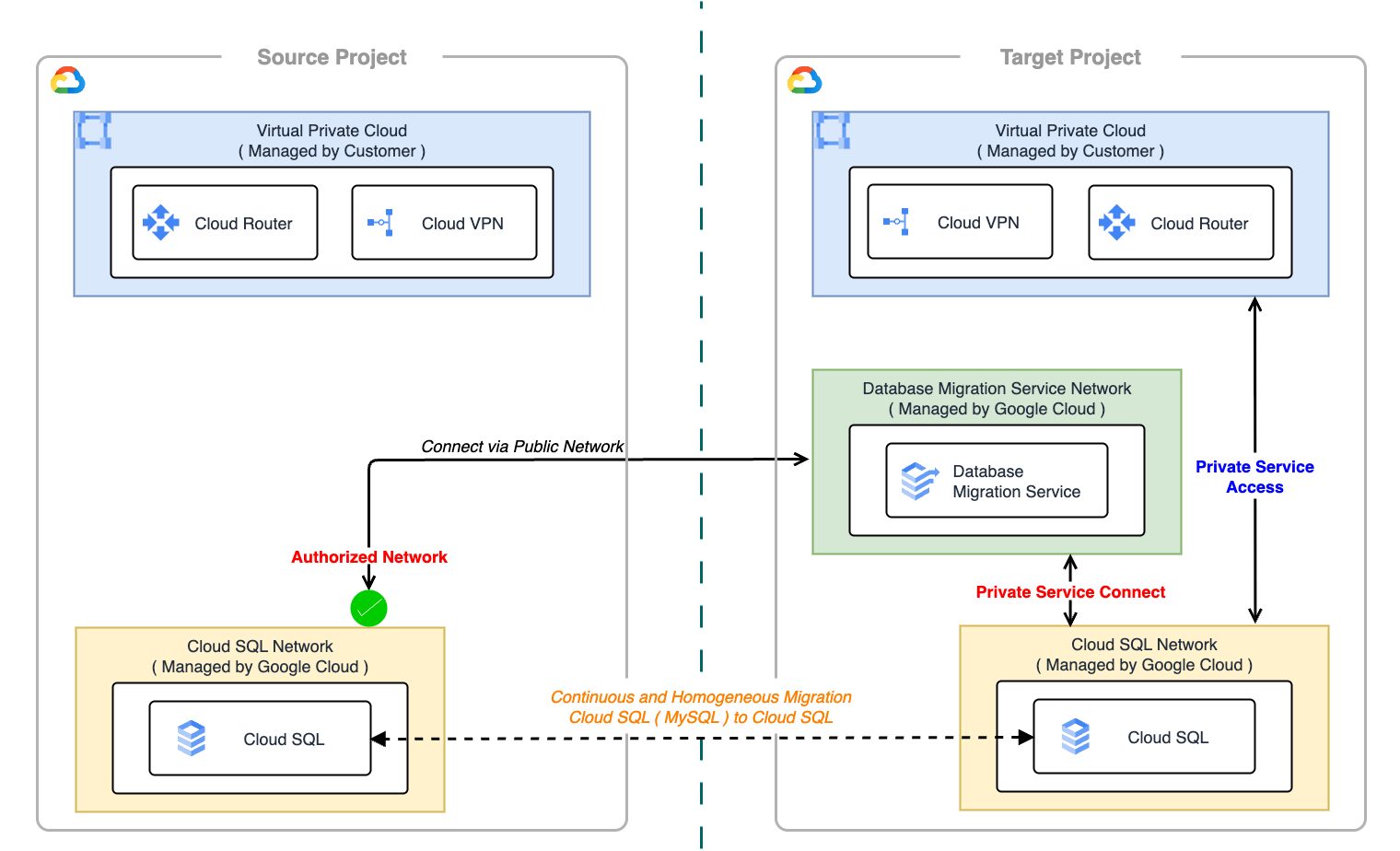
当初は、よりセキュアな PSA(Private Service Access) と Cloud VPN を用いたプライベート接続も検討しましたが、PSA の構成変更にはネットワーク起因でのダウンタイムが発生するため、柔軟性が高い Public IP 接続を選択しました。もちろん、DMS 自体の SSL/TLS 暗号化通信と、Cloud SQL の承認済みネットワークを組み合わせることで、通信経路のセキュリティは十分に担保できます。参考
Cloud SQL → Cloud SQL の制約
2025 年 6 月時点では、DMS の仕様として、Source と Destination の両方を Cloud SQL インスタンスとして構成できない制約がありました。そのため、構成上は Source=MySQL (on Compute Engine 扱い), Destination=Cloud SQL としてセットアップする必要がありました。
こうした事前の検証で発見しにくい制約はスケジュールの遅延要因となります。実際、本プロジェクトでも Google Cloud サポートへの問い合わせや調整が発生したため、特に期限が決まっているプロジェクトでは、早期の PoC フェーズでの洗い出しと、予期せぬトラブルを見越したバッファの確保が重要になります。
カットオーバーの注意点
旧 Cloud SQL を Read Only に設定する際、アプリケーションの実装によっては書き込み失敗を検知して CrashLoopBackOff や Error ステータスに陥り、その後の再接続や新環境への切り替えがスムーズに行かなくなる可能性があります。
そのため、DB 接続エラーや書き込みエラーが発生したとしても、アプリケーションプロセス自体は生存し続け、接続先が書き込み可能(Writable)になった時点で即座に復旧できるよう、適切なエラーハンドリングと再試行ロジックを実装しておくことが必要です。本番作業前に、意図的に Read Only エラーを発生させる障害試験を行い、panic や nil pointer dereference 等による CrashLoopBackOff が発生しないか、アプリケーションの挙動を確認しておくことが推奨されます。
Memorystore 移設
Memorystore for Redis の移行には、アプリケーション側でのダブルライト(Dual-Write)方式を採用しました。

移行手順の概要
Memorystore では DMS のようなマネージド移行サービスは利用できないため、アプリケーションレイヤでダブルライトを行います。
- VPN 接続確立:Cloud VPN を用いて新旧 VPC 間を相互接続し、旧環境から新環境の Memorystore(Private IP)への到達性を確保する
- ダブルライト開始:旧環境のアプリケーションを改修し、旧 Redis(Primary)と新 Redis(Secondary)の両方へ書き込み(非同期または同期)を行うようにデプロイする
- 新環境アクティベーション:新環境でアプリケーションを起動し、新 Redis に対して Read / Write を行う状態にする
- 旧環境デコミッション:旧環境へのトラフィックがなくなったことを確認後、ダブルライトを停止し、同環境の Memorystore を削除する
Cloud VPN を用いて、異なる Google Cloud プロジェクトの VPC をセキュアに接続する方法については こちらのブログ で紹介しています。
Routes-based Cluster 問題
Memorystore の移行において最大の障壁となったのが、旧環境の一部に残っていた Routes-based GKE Cluster の存在です。VPC Native GKE Cluster(Alias IP)の場合、VPC サブネットに Secondary IP Range が割り当てられ、この範囲に対する経路が対向 VPC に広報されるため、Memorystore との接続が可能ですが、Routes-based Cluster はノード単位に Pod CIDR を割り振り、VPC ルートテーブルでルーティングを行う仕様となっています。
この構成では、Cloud VPN を介した VPC 間通信において、VPC ルートテーブルで管理される Pod CIDR を BGP で対向 VPC へ自動広報することが難しく、都度静的ルートを追加する必要がある等の運用コストや制約が発生し、結果として Pod から新環境の Memorystore へ直接接続することが困難でした。
これに対し、VPC Native なサブネットワーク上に TCP Proxy(Redis Proxy) を構築し、そこを経由させることで接続性を確保しました。
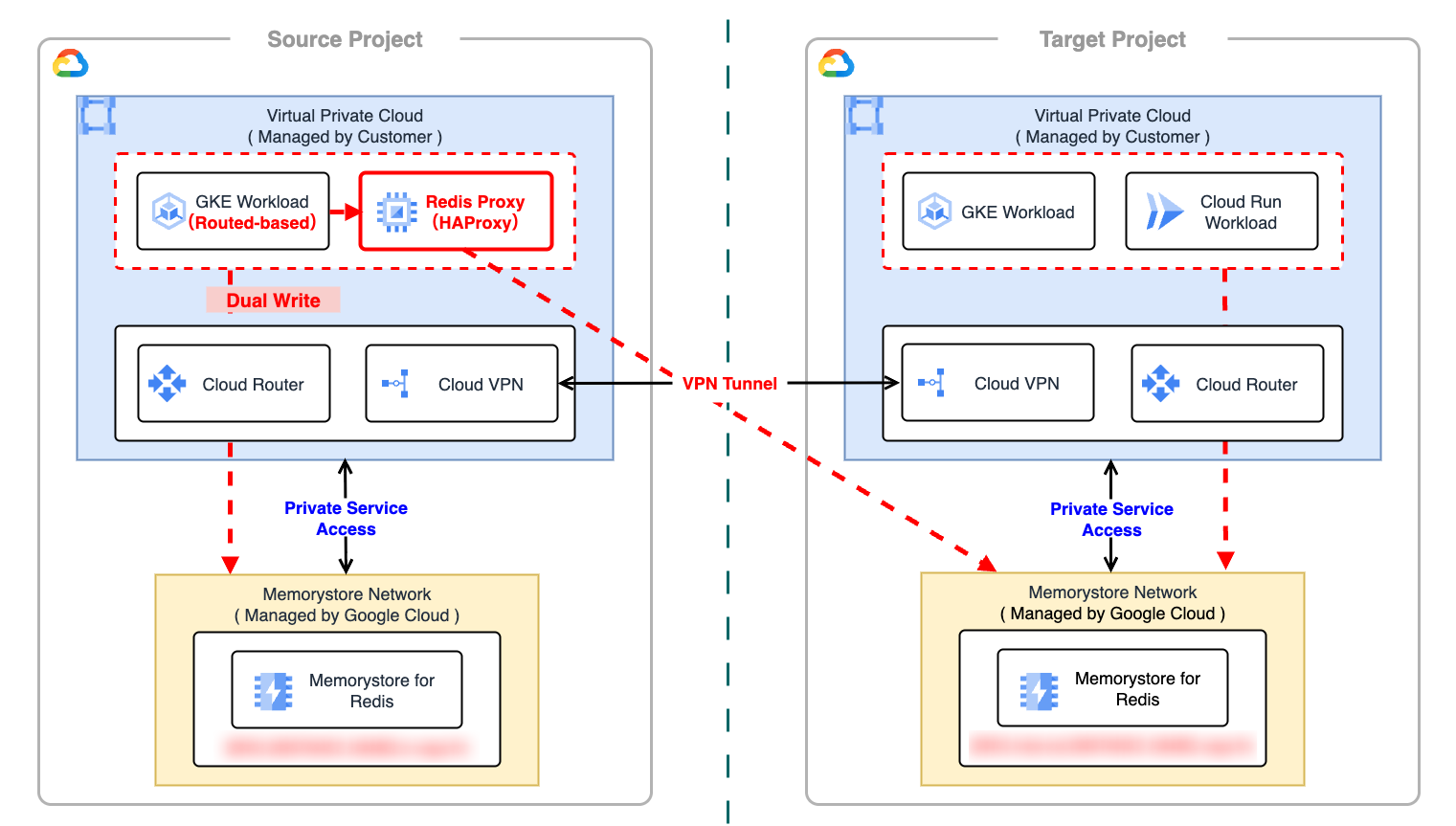
TCP Proxy を介した接続
TCP Proxy は Instance Group を用いて VM(Compute Engine)として構築しました。
また、構築した TCP Proxy が移行期間中のボトルネックとならないよう、Datadog の HAProxy Integration を用いたモニタリング環境を整備しました。これにより、セッションレートや接続エラー、レイテンシ等をリアルタイムに監視し、プロキシ層の健全性を常に担保する体制を整えました。
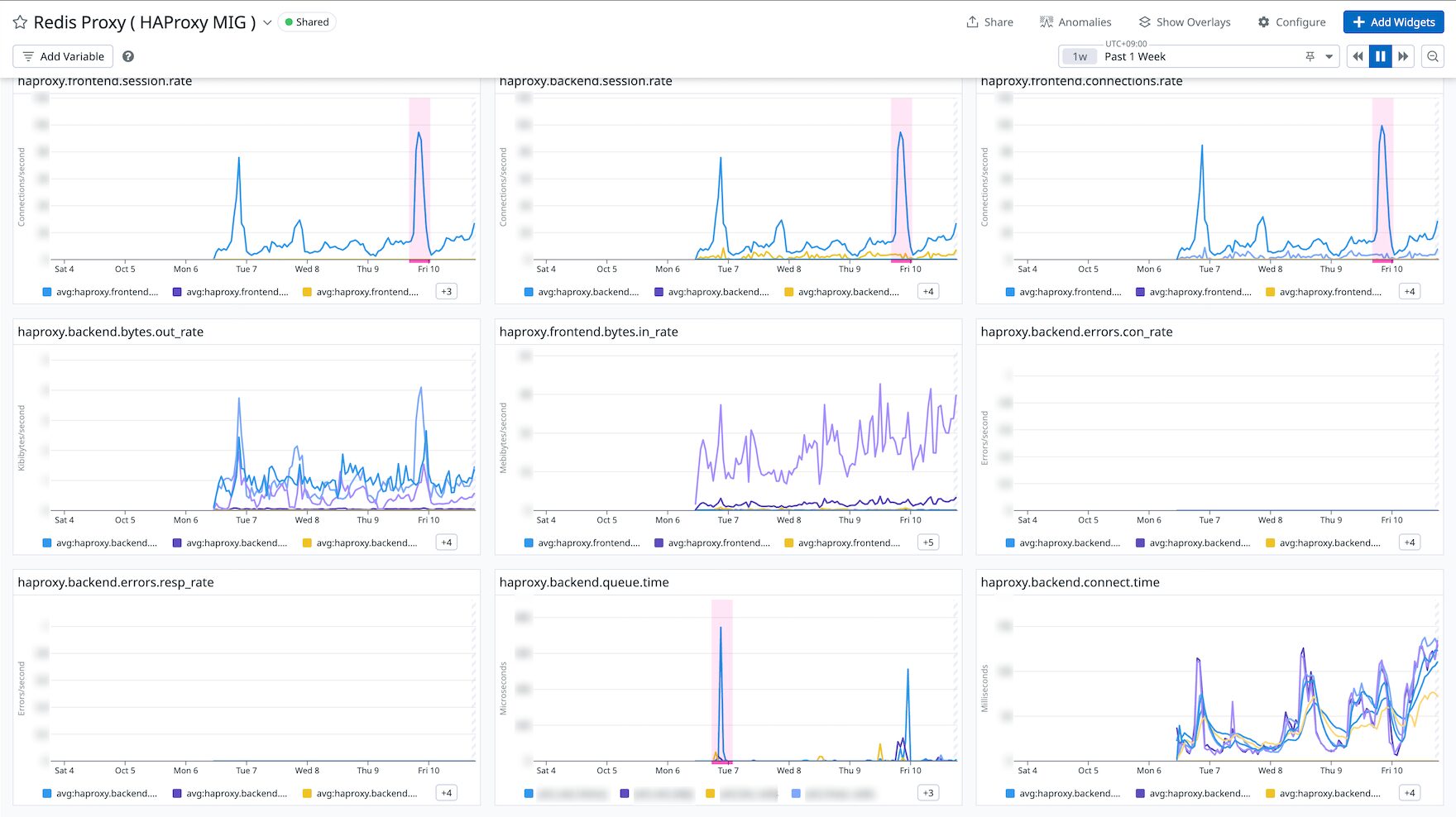
これは一時的なワークアラウンドですが、移行期間中の通信を成立させるための現実的な解として採用しました。こうしたイレギュラーな対応は手順書に明記し、移行完了後には速やかに構成を標準化(TCP Proxy の撤去)する計画もセットで管理しました。
Cloud Run Service 移設
Cloud Run Service をはじめとするサーバレスソリューションについては、アプリケーション自体はコンテナイメージをデプロイするだけで済みますが、データベース接続やドメイン管理といった周辺構成において、いくつかの工夫が必要となりました。
移行手順の概要
- Direct VPC Egress 構成の維持:旧環境の Cloud Run が利用している Direct VPC Egress または Serverless VPC Connector の構成をそのまま維持する
- Cloud Run エンドポイント切り替え:アプリケーションの接続先データベース設定を新環境 Cloud SQL の Private IP へ向ける
- Domain Mapping 撤退と GCLB 移行:新環境では Cloud Run Domain Mapping を廃止し、GCLB + Serverless NEG 構成へ移行する
Direct VPC Egress 利用時のクロスプロジェクト通信
旧環境の Cloud Run では、VPC 内リソースへの接続に Direct VPC Egress を利用していました。今回の移行では、プロジェクト間を Cloud VPN で接続し、双方の VPC がプライベートネットワーク経由で疎通できるように構成することで、Cloud Run の構成を大きく変更することなく新環境への接続を実現しました。
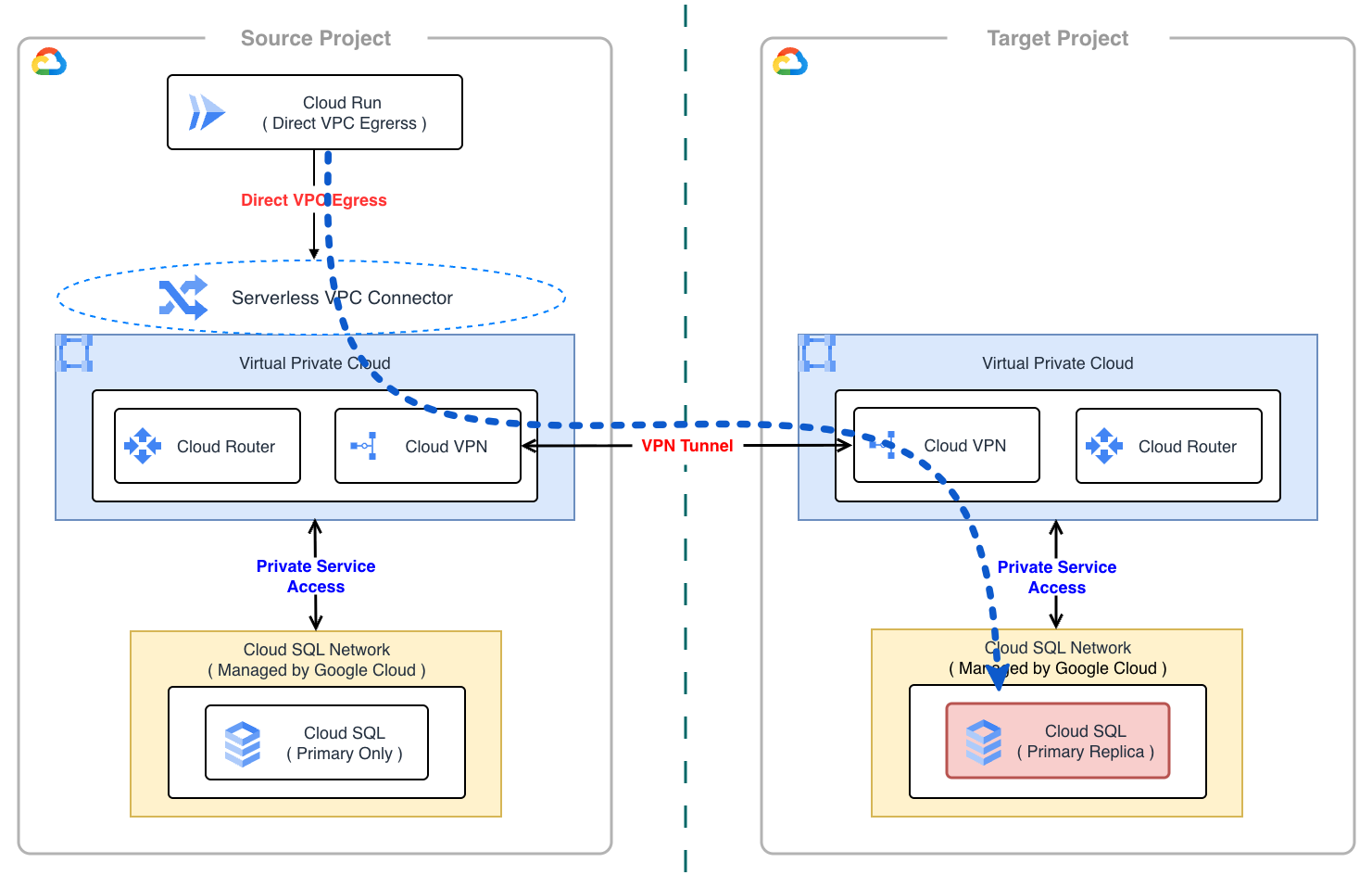
Direct VPC Egress は特定の VPC にバインドされますが、Cloud VPN によって対向環境の VPC へのルーティング情報が学習されていれば、Google Cloud のバックボーンネットワークを経由して Private Service Access 経由で新環境 Cloud SQL の Private IP へ直接アクセスすることが可能です。この仕組みにより、アプリケーション側は接続先のエンドポイント(DB ホスト)を新環境の Private IP に切り替えるだけで済み、最小限の変更コストで移行を実現できました。
Cloud Run Domain Mapping からの撤退
旧環境では、一部のサービスでカスタムドメインの割り当てに Cloud Run Domain Mapping を利用していましたが、新環境では Global External HTTPS Load Balancer(GCLB)+ Serverless NEG の構成へ移行することにしました。
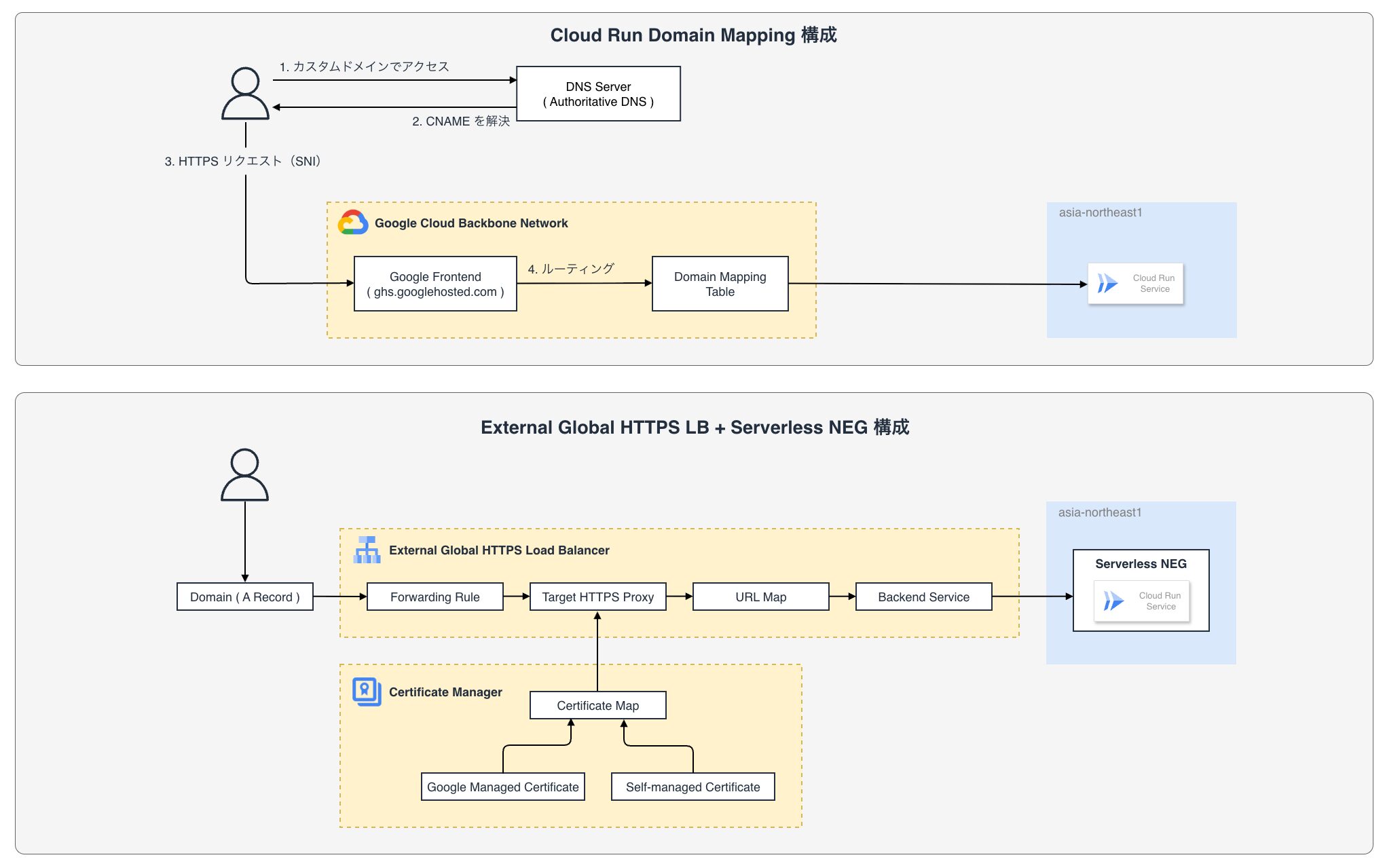
Domain Mapping は手軽に導入できる反面、ヘアピンルーティング等によるレイテンシの増大や Cloud Armor、Cloud CDN が利用できないといった機能制限の諸問題がありましたが、GCLB に移行することでこれらの課題を解消し、堅牢でスケーラブルな構成を目指す目的があります。
Cloud Run Domain Mapping からの撤退理由や、移行時のダウンタイムを最小限に抑える戦略については こちらのブログ で詳しく紹介しています。
証明書プロビジョニングの高速化
GCLB 移行時の課題として、Google マネージド証明書の発行に時間がかかる(DNS プロパゲーションを含めて最大 72 時間)という点がありました。これに対し、Certificate Manager の Certificate Map を活用することで解決しました。
具体的には、事前にワイルドカード証明書(Self-managed)を用意して GCLB にアタッチしておき、DNS 切り替えと同時に即座に HTTPS 通信を開始できるようにしました。その後、バックグラウンドで Google マネージド証明書の発行を行い、完了次第そちらに切り替えることで、ゼロダウンタイムでの移行を実現しました。
$ while true; do
echo "--- $(date '+%H:%M:%S') ---"
openssl s_client \
-connect domain-mapping-migration.example.com:443 \
-servername domain-mapping-migration.example.com \
/dev/null | \
openssl x509 \
-noout -subject -serial -fingerprint -sha256
sleep 3
done
--- 16:27:50 ---
subject=CN=*.example.com
serial=1000000000000000000000000000000000000001
sha256 Fingerprint=AA:BB:CC:DD:EE:FF:00:11:22:33:44:55:66:77:88:99:AA:BB:CC:DD:...
--- 16:27:53 ---
subject=CN=*.example.com
serial=1000000000000000000000000000000000000001
sha256 Fingerprint=AA:BB:CC:DD:EE:FF:00:11:22:33:44:55:66:77:88:99:AA:BB:CC:DD:...
--- 16:27:56 ---
subject=CN=*.example.com
serial=1000000000000000000000000000000000000001
sha256 Fingerprint=AA:BB:CC:DD:EE:FF:00:11:22:33:44:55:66:77:88:99:AA:BB:CC:DD:...
--- 16:27:59 --- # ここで即座に切り替わる
subject=CN=domain-mapping-migration.example.com
serial=20000000000000000000000000000000
sha256 Fingerprint=11:22:33:44:55:66:77:88:99:AA:BB:CC:DD:EE:FF:00:11:22:33:44:...
--- 16:28:02 ---
subject=CN=domain-mapping-migration.example.com
serial=20000000000000000000000000000000
sha256 Fingerprint=11:22:33:44:55:66:77:88:99:AA:BB:CC:DD:EE:FF:00:11:22:33:44:...
--- 16:28:05 ---
subject=CN=domain-mapping-migration.example.com
serial=20000000000000000000000000000000
sha256 Fingerprint=11:22:33:44:55:66:77:88:99:AA:BB:CC:DD:EE:FF:00:11:22:33:44:...
5. プロジェクト管理とコミュニケーション計画
大規模かつ長期間にわたる移設プロジェクトを成功させるためには、技術的なアプローチ以上に、プロジェクト管理への慎重な投資が重要になります。特に、関わるメンバーが増えるほど、個々のタスク状況や全体のロードマップを正確に把握することは困難になります。
私は今回、Platform Engineer としてだけでなく、Project Manager(PM)としての役割も担ってきました。技術的な意思決定はもちろんですが、それ以上に「開発者が迷いなく開発に集中できる環境」を作り、プロジェクト全体の見通しを常にクリアに保つことに注力しました。
本プロジェクトでは、開発チームを跨いだ円滑なコラボレーションと見通しの良いタスク管理を実現するために、以下の運用ルールを徹底しました。
タスク管理の標準化と可視化
日々のタスク管理には GitHub Projects を採用し、カンバン形式ですべての進捗を可視化しました。

運用において最も重視したのは「個々人がタスクを進めやすく、かつプロジェクト全体の見通しを良くする」ことです。Issue の粒度や記載内容がバラバラになると管理コストが増大するため、ツールや運用方針を徹底的に定義しました。
タスクの親子関係と階層構造
GitHub の Parent / Child Issue 機能を活用してタスクの依存関係を整理しましたが、運用の肝となったのは「環境単位での Issue 分割」と「親 Issue の粒度」です。
まず、作業タスク(子 Issue)は必ず 1 環境(DEV / STG / PRD)毎に作成することを徹底しました。単一の Issue で全環境の作業を管理してしまうと、すべての環境で完了するまで Issue をクローズできず、結果として進捗が停滞しているように見えてしまうためです。
また、これらを束ねる親 Issue は「環境毎(例:Dev 環境対応)」ではなく、「機能・トピック毎(例:Cloud SQL 移設)」に作成する方針としました。環境毎に親 Issue を切ってしまうと、その下に紐付くタスクが膨大になり Issue のカーディナリティが高くなることで管理コストが増大してしまうためです。「機能毎の親 Issue」の下に「環境毎の子 Issue」を紐付ける構造にすることで、機能単位での進捗状況を正確に把握しつつ、環境毎の完了ステータスを可視化できるようにしました。
これらの Issue には優先度や紐付く親 Issue を示すラベルを付与し、依存関係や遅延リスクを一目で把握できるようにしました。
階層は深くなり過ぎると全体像が見えにくくなるため、特に複数のタスクが羅列される場合は階層に制限を設ける(今回の場合は最大 3 階層までとした)ことを推奨します。
会議体の設計と進捗管理
定例ミーティングは、単なる報告の場ではなく、課題解決と意思決定の場にする ことを徹底します。 アジェンダの無い MTG は実施しないことを原則とし、Daily スクラムは GitHub Projects をベースに以下のサイクルを回しました。
- カンバンによる進捗確認:遅れているタスクや依存関係でブロックされているタスクを特定する
- ブロッカーの解消:進捗が滞っている理由を明確にし、解決策の提示やタスク順序の入れ替え(前後調整)を行う
- ガントチャートとの整合:原則として、当初引いたガントチャートに沿った進行を意識しつつ、状況に応じて柔軟に計画を修正する
技術的な調査や戦略策定に時間をかけることはもちろん重要ですが、それ以上に「プロジェクト管理」そのものに慎重に時間を掛け、チーム全員が迷いなく動ける環境を整えることが、結果として最短でのゴール到達に繋がると考えています。
ゴール・ノンゴールの再確認
プロジェクト進行中、新たな要望や改善案が出てくることは避けられませんが、今回であれば、前でも書いた通り「移設」以外の要素を取り込むことはプロジェクトの肥大化と遅延を招きます。定期的な振り返りやタスク整理の場において、常に「これは今回のゴール(移設完了)に必要なことなのか」を問い直し、ノンゴールと定めた項目については「やらない」判断を下し続けました。
この徹底したスコープ管理こそが、複雑なプロジェクトを期限内に完遂させるための最も重要なファクタであったと実感しています。
6. おわりに
本記事では ABEMA 広告配信システムの運用基盤刷新と Google Cloud 移設について、技術戦略とプロジェクトマネジメントの両面から紹介しました。
本プロジェクトは単なるインフラ移行ではなく、将来的な成長を見据えたリアーキテクティングであり、Google Cloud プロジェクトの分離や IaC / GitOps の徹底、DNS を活用した段階的移行等、技術的な挑戦の連続でした。
また、技術面だけでなく、見通しの良いプロジェクト管理と明確なスコープ定義もプロジェクトを推進する上で重要な役割を果たしました。 技術的な理想とビジネス要件のバランスを取り、チーム全員が迷いなく進める環境を作れたことが、無事に移設を完了できた一つの要因だと考えています。
最後までお読みいただき、ありがとうございました。
それでは、良いお年を 👋