
はじめまして、AI Labの大平です。
普段は対話システムの研究開発をしています。
最近、VAPIをはじめとしてたくさんの対話システムが市場に出てきました。それに伴い対話システムを使ったビジネスを始めようとする方も多いかと思います。
そこで問題になってくる「対話システムの品質担保」について1つ書いてみようと思い立ちました。
VoiceInteractionEvaluatorとは
本稿では、音声対話システムの品質を評価するためのツール「VoiceInteractionEvaluator」について紹介します。
VoiceInteractionEvaluatorは、私たちが開発したオープンソースの評価ツールで、音声対話システムの挙動を定量化し、デバッグを支援することを目的としています。
GitHubで公開されており、誰でも利用・改変が可能です。
このツールは、CyberAgent AI Labでの対話システム開発の実務から生まれたもので、実際の開発現場で「音声対話の品質をどう評価するか」という課題を解決するために開発されました。
個人プロジェクトとして取り組んでいるもので、会社の公式プロジェクトではありません。
実際の動作イメージ(デモ動画)
まずは、VoiceInteractionEvaluatorを使用して実際の音声対話システムを評価している様子を動画でご確認ください。
具体的な動作を見ていただくことで、後続の説明がより理解しやすくなります。
ケース1:通常対話テスト
ユーザー(自動生成音声)とボットのテンポを客観的に可視化しているデモです。
ケース2:割り込み(Barge-in)テスト
ユーザーの割り込みに対して、システムがどれだけ早く反応して発話を停止できるかを検証しています。
音声対話システムの評価が難しい理由
一般的なテキストベースのチャットボットやAPIのテストとは異なり、音声対話システムの評価には特有の難しさがあります。
● 時間的な要素の評価
テキストベースのテストでは「正しい応答が返ってきたか」だけを確認すれば十分ですが、音声対話では「どのくらいの時間で応答が返ってきたか」がユーザー体験に大きく影響します。
人間同士の会話では200〜800ms程度の応答が自然とされますが、この「間」をどう定量化し、評価するかが課題です。
● 音声特有の物理的な挙動
音声インターフェースでは、発話の検知(VAD)、割り込み(Barge-in)への対応、ノイズ環境下での認識精度など、テキストでは存在しない物理的な要素が品質に直結します。
これらは単なるAPIの応答時間とは異なり、音声波形の解析やリアルタイムでの検知が必要になります。
● 複数のレイヤーが絡み合う複雑さ
音声対話システムは、システムレベルの接続状態、音声処理のタイミング、対話ロジックの整合性など、複数のレイヤーが同時に動作しています。
「なんとなく違和感がある」という主観的な感覚が、どのレイヤーの問題なのかを特定するのが困難です。
● 主観的な「違和感」の定量化
人間が耳で聴いて感じる「違和感」や「不自然さ」を、どう数値として表現するかが課題です。
単なるテキストの一致チェックでは、応答の自然さや会話の流れを評価できません。
VoiceInteractionEvaluatorは、こうした課題に対して、音声波形の解析、タイムスタンプの記録、LLMによる意味的評価などを組み合わせることで、「なんとなく悪い」という感覚を「どこが悪いか」という工学的な問題へ落とし込むことを目指しています。
VoiceInteractionEvaluatorの目的とスコープ
VoiceInteractionEvaluatorがフォーカスするのは、こうした不確実な要素の中でも、特に
「物理的なUXレイヤー」の自動評価です。
人間が耳で聴いて感じる「違和感」を数値化し、デバッグの目安にすることを目的としています。
現時点での主なスコープは、開発エンジニアがローカル環境や検証環境で、
対話システムの定量評価を手動で行うことにあります。
GitHub Actions などを用いた CI/CD 向けの自動テストについては、
Botium のような既存ツールが適しているケースもあります。
VoiceInteractionEvaluator はそれらと競合するものではなく、
「手元で挙動を確かめたいときのデバッグ支援ツール」として、
変更がどの層に影響したのかを素早く把握することを目的としています。
評価レイヤーの構成
先ほど述べた「複数のレイヤーが絡み合う複雑さ」に対応するため、VoiceInteractionEvaluatorでは評価対象を次の 3 つの階層に整理しています。
これにより、「なんとなく違和感がある」という主観的な感覚を、どのレイヤーの問題なのかに分解して評価できるようになります。
特に 第2層(音声・物理階層) が VoiceInteractionEvaluator の中核となります。
1. システム・プログラム階層(生存確認)
WebSocket 接続が維持されているか、双方向の音声ストリームが継続して流れているか、
また LLM や音声合成エンジンなどの外部 API が正常に応答しているかといった、
システムとして最低限の稼働条件を確認します。
2. 音声・物理階層(Turn-taking / Sound)
VoiceInteractionEvaluator が最も重視するレイヤーです。
ユーザーの発話終了から応答開始までの遅延、発話中の割り込み(Barge-in)への対応、
ノイズ環境下での認識挙動など、音声インターフェース特有の時間的・物理的挙動を評価します。
3. 対話・ロジック階層(Consistency / Logic)
音声として返された内容と、実際に実行された処理(Toolcall)が一致しているかを検証します。
「言っていること」と「実際に行われた処理」に乖離がないかをチェックすることで、
対話としての信頼性を評価します。
想定される利用シーン
● AIチューバー / ライブ配信
リアルタイム性が求められる配信では、わずかな遅延が視聴体験を損ないます。
ただし配信基盤側の遅延も存在するため、他用途と比べると多少のバッファ許容が可能です。
● AIコールセンター / 自動受付
電話応対においては、応答の間や聞き返しの自然さが顧客満足度に直結します。
内容と処理結果の不一致は致命的な問題になります。
● フィールド設置型対話システム
駅や商業施設など、騒音が激しくネットワークも不安定な環境では、
雑音除去・通信揺らぎ・リアルタイム応答すべてに高い耐性が求められます。
最も厳しい条件下での検証対象です。
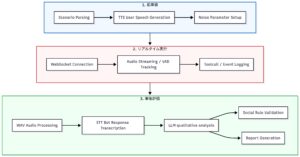
各フェーズの役割と重要性
前準備(Preprocessing)
.convo シナリオを解析し、ユーザーの発話を事前に音声波形へ変換します。
実行時にリアルタイムで TTS を行うと、評価ツール自体の生成レイテンシが測定結果に混入してしまうため、
あらかじめ「黄金の波形」を用意しておくことが重要です。
この工程により、ミリ秒単位の正確なレイテンシ計測が可能になります。
リアルタイム実行(Execution)
ターゲットサーバーへ WebSocket で接続し、準備した音声をストリーミングします。
同時に、サーバーから返ってくる音声を VAD(Voice Activity Detection)によって監視します。
ここでは単なる通信ログではなく、実際の音声波形を元に
「有音区間」がどこからどこまで続いたのかを検出し、
正確なタイムスタンプを記録します。
事後評価(Evaluation)
記録された WAV ファイルとイベントログをもとに、後処理による評価を行います。
単なるテキスト一致ではなく、以下のような観点で多角的に分析します。
- 音響的指標(SNR など)
- STT(音声認識)結果の妥当性
- LLM による意味的整合性・応答品質の評価
これらを統合し、最終的な評価レポートとして出力します。
システム構成:WebSocketにおける役割分担
本システムは WebSocket Client として動作し、評価対象となる対話システム(WebSocket Server)へ接続します。
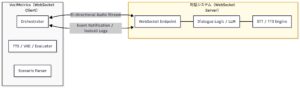
VoiceInteractionEvaluator 側で合成された「擬似ユーザー音声」をサーバーへ送信し、
サーバー側から返ってくる応答音声を VoiceInteractionEvaluator 側でリアルタイムに解析・記録する構成です。
評価レイヤー
VoiceInteractionEvaluator では、音声対話の品質を以下の4つのレイヤーに分解してスコアリングします。
これにより、「なんとなく悪い」という感覚を「どこが悪いか」という工学的な問題へ落とし込みます。
① Turn-taking(タイミングの定量化)
会話の「間」と「リズム」、そして主導権の切り替わりを評価します。
- Response Latency:ユーザーの発話終了からボットが話し始めるまでの時間
- Speech Duration:ユーザー・ボットそれぞれの発話持続時間
- Barge-in(割り込み):発話中にユーザーが話し始めた際、適切に発話を中断できるか
人間同士の会話では、おおよそ 200〜800ms 程度の応答が自然とされます。
VoiceInteractionEvaluator はこの「黄金の間」からの乖離をミリ秒単位で可視化します。
② Sound(ノイズ耐性の検証)
「静かな会議室」ではなく、「騒がしい街中」や「カフェ」のような現実環境を想定した評価レイヤーです。
現在は、送信するユーザー音声に対して意図的にホワイトノイズを重畳することで、
ノイズ耐性を検証できる仕組みを備えています。
③ Toolcall / Logic(命令実行の整合性)
音声対話における最も致命的な問題の一つが、発話内容と実際の処理が食い違うケースです。
たとえば、ユーザーが「玄関のドアを開けて」と言い、
ボットが「わかりました」と応答したにもかかわらず、
実際には解錠 API が呼ばれていない──といった事態を自動検出します。
発話内容と内部ステータスの不一致を検出することで、
「言行不一致」による不信感を未然に防ぐことを目的としています。
④ Conversation Quality(定性評価)
対話全体の自然さを、定量・定性の両面から評価します。
- 対話の成立性(Dialogue Consistency)
文脈が破綻していないか、ユーザーの目的が達成されているかを評価します。 - 応答の自然さ(Response Naturalness)
トーンの適切さや語調を、LLMベースの評価と編集距離などの定量指標で測定します。
シナリオ設計
VoiceInteractionEvaluatorは、単なるテキストの送受信ログを記録するツールではなく、
音声対話システム特有の挙動を評価するために設計された仕組みです。
そのため、一般的な音声解析ツールとは異なる設計思想を持っています。
発話検知と Turn-taking の計測(webrtcvad)
リアルタイム対話システムでは、ユーザーが発話していない時間帯であっても、
音声データ自体は常にストリーミングされています。
そのため、対話の中から意味のある発話区間を正確に切り出すには、
VAD(Voice Activity Detection)や STT による有音判定が不可欠となります。
VoiceInteractionEvaluator では、受信した音声バイナリを webrtcvad を用いて
リアルタイムに解析しています。
これは単に音声の有無を判定するためではなく、
既存の対話システム側に大きな改修を求めず、
最小限の実装変更で評価を可能にすることを目的としています。
これにより、既存システムにほとんど手を加えることなく導入でき、
この設計により、開発段階・検証段階を問わず、
現実的な負荷条件下での挙動を継続的に観測できるようになります。
雑音評価の省略
一般的な音声評価では SNR(信号対雑音比)が重要視されますが、
VoiceInteractionEvaluator ではこの評価をあえて行っていません。
その理由は、入力される音声がマイク経由の生音ではなく、
システム内部で生成された「デジタル音声」だからです。
物理空間由来のノイズが存在しないため、
雑音耐性の評価は本質的ではなく、
代わりに「意図した音声がどれだけ正確に、速く処理されたか」に評価軸を置いています。
今後の拡張:ループバック(エコーキャンセル)評価
将来的には、実際のハードウェア環境を想定した
「ループバック評価」への対応も予定しています。
これは、スピーカーから出力された音声がマイクに回り込んだ際に、
システムがそれをどの程度正確に除去し、ユーザーの声を識別できるかを検証するものです。
物理デバイスを含めた実運用レベルの検証を行うことで、
より現実的な音声インターフェースの品質評価を目指します。
LLM-as-a-Judge(構造化評価)
定性的な評価には OpenAI の gpt-4o-mini を利用しています。
単なる自由記述ではなく、JSON Schema を用いて構造化された評価結果を取得することで、
自動評価パイプラインとしての安定性を確保しています。
シナリオ設計:.convo ファイル
VoiceInteractionEvaluator のテストシナリオは、チャットボット評価で一般的な
.convo 形式を拡張した構造を採用しています。
パターンA:既存音声の再生
事前に録音された音声ファイルを再生し、VAD検出のみを行うシンプルな構成です。
# IVE Test Scenario
# 音声ファイルパスとVAD検出のみを利用
#me tests/hello.wav
#bot [speechStart]
#bot [speechEnd]
#me tests/hello.wav
#bot [speechStart]
#bot [speechEnd]
パターンB:自然言語テキストによる対話
実行時にテキストを音声へ変換し、対話を行うパターンです。
# IVE Test Scenario
# 自然言語テキストを使用した対話
# TTSで音声を生成
#me こんにちは、お元気ですか?
#bot こんにちは、元気です。ありがとうございます。
#me 今日はいい天気ですね
#bot そうですね、とてもいい天気です。
#me ありがとうございます
#bot どういたしまして。
LLMによる意図解釈
ここでの #bot は「正解文」ではなく、
期待される意味内容を表します。
実際の応答が語彙的に異なっていても、意味的に一致していれば高評価となるよう、
LLM を用いた意味類似度評価を行います。
パターンC:割り込み・API連携の検証
# 割り込み(Barge-in)テスト
# ボットが話し始めて500ms後にユーザーが遮る
#bot [speechStart]
#interrupt 500 すみません、やっぱり今のなしで
#bot [speechEnd]
# 外部API連携の検証
#me フロントドアの鍵を開けてください
#bot わかりました、解錠します。
#toolcall open_door {"target": "front_door"}
このように、ボットの発話中断や API 呼び出しの整合性を検証することで、
実運用に耐える対話品質を担保します。
実際の評価結果とデバッグへの活用
実際の実行ログには、開発者が「次に何を直すべきか」を判断するための多くのヒントが含まれています。
今回は、どんな問いかけに対しても常に「なるほどですね」と返答する対話システムを対象に、
デバッグを行った結果を紹介します。
このシステムでは、発話のたびに ToolCall も実行される構成となっています。
以下がその実行ログです。
============================================================
[turntake] Score: 100.0/100
Response Latency: 427.3ms
User Speech Duration: 1404ms
Bot Speech Duration: 1702ms
[sound] Score: 100.0/100
SNR: 81.1dB
Noise Type: low_freq
[toolcall] Score: 0.0/100
Expected: 0
Actual: 3
Unexpected: 3
[dialogue] Score: 20.0/100
Similarity score 1: 0.200
Similarity score 2: 0.200
Similarity score 3: 0.200
[conversation_quality] Score: 41.7/100
Backchannel Score: 20.0/100
Tone Consistency Score: 80.0/100
Omotenashi Score: 2/5 (25.0/100)
============================================================
Client completed successfully!
Timeline saved to: reports/test_169212_timeline.json
Log file: logs/test_169212.log
Recording file: reports/test_169212_recording.wav
評価結果の読み解き
Response Latency(427.3ms) は非常に高速です。
事前に合成された音声ファイルを再生しているため、推論や音声生成の遅延がほぼ存在しません。
一方で、Toolcall(Unexpected: 3) という結果は重大な問題を示しています。
本来は一度も呼ばれないはずの API が、3 回も実行されていることを意味します。
また、Similarity Score(0.200) が示す通り、
すべての発話に対して「なるほどですね」という定型文が返されているため、
対話内容がシナリオの意図とまったく一致していません。
どれだけレスポンスが速くても、内容が伴っていなければ
ユーザー体験としては破綻している、ということが数値として明確に表れています。
以下は、実際に評価に使用された音声ファイルです。
耳で実際に聴いてみると、
「内容が伴っていない」「反応が機械的である」と感じるポイントが、
スコアとしてどのように反映されているかが分かります。
このように、VoiceInteractionEvaluator は単なる数値評価に留まらず、
人間の直感とログデータの対応関係を可視化することを目的としています。
対話システム側で最低限必要な対応
VoiceInteractionEvaluatorで評価を行うためには、評価対象となるシステム側でいくつか対応が必要なことがあります。
ここでは、対話のロジック以前に、通信プロトコルとして最低限満たしておくべき要件をまとめます。
1. 音声パケットを送り続けること
VoiceInteractionEvaluatorは、計測中に音声パケットが双方向に流れ続けていることを前提としています。
そのため、サーバー側はVoiceInteractionEvaluatorからのパケットを受け取るだけでなく、
自らも「無音」であってもパケットを返し続ける必要があります。
import asyncio
from aiohttp import web
async def websocket_handler(request):
"""VoiceInteractionEvaluatorとの間で常に音声パケットをやり取りする実装例"""
ws = web.WebSocketResponse()
await ws.prepare(request)
# 応答中かどうかのフラグ
is_responding = False
# 常に音声を送り続けるためのタスク
async def audio_sender_task():
# 10ms分の無音データ(例: 16kHz, int16なら320バイト)
silence_chunk = b'\x00' * 320
while not ws.closed:
if is_responding:
# 応答が必要な場合は実際の音声パケットを送信
await ws.send_bytes(get_next_response_chunk())
else:
# 応答がない間も、常に「無音」パケットを送り続ける
await ws.send_bytes(silence_chunk)
# 一定の間隔(10ms〜20ms)を維持して待機
await asyncio.sleep(0.01)
# 送信タスクをバックグラウンドで開始
sender_task = asyncio.create_task(audio_sender_task())
try:
async for msg in ws:
if msg.type == web.WSMsgType.BINARY:
# VoiceInteractionEvaluatorから送られてくる音声パケットを受信
process_incoming_audio(msg.data)
finally:
sender_task.cancel()
return ws
2. 設定による遅延の目安と「誤差」
VoiceInteractionEvaluatorで計測されるレイテンシには、システムの設定によって発生する遅延が含まれます。
これらが全てではありませんが、主に以下のような要素が影響します。
サーバー側の無音待機時間 (min_silence_duration_ms)
ユーザーが話し終わったと判定するために、サーバー側で設ける待ち時間です。
この値を長くすると判定は安定しますが、レイテンシの結果は数値上悪くなります。
逆に短すぎると、発話の途中のわずかな合間でVADが終了と誤判定してしまい、
VoiceInteractionEvaluatorが無理やり応答を差し込むなど、意図しない挙動になる可能性があります。
処理単位による遅延 (20ms程度)
音声パケットを処理するフレーム長などに起因して発生する物理的な遅延です。
例えば、無音検知を 300ms に設定している場合、
どれほど高速なシステムでも合計で 320ms 程度は必ず遅れて計算されることになります。
計測にあたっては、この「設定から予測される時間」と、
実際の計測結果との差分を「検証上の誤差」として捉えるのが現実的です。
もし計測結果が 350ms であれば、
その差である 30ms くらいが、処理のオーバーヘッドなどによって生じた「誤差」ということになります。
まとめ
VoiceInteractionEvaluatorは、実際に音声を聴いて人間が感じる「違和感」や「納得感」が、
システム側のログ数値とどれくらい一致しているかを確認するためのツールとして作られました。
数値を出すことでできること
「なんとなく良くなった」「今日は調子が悪い」といった主観的な感覚を、
ログと突き合わせることで以下のような使い方ができるようになります。
- 直感の答え合わせ
- 「なんか変だ」の正体を突き止める
- 主観評価のズレを埋める
- 変更の影響を定量化する
今後の予定
- ループバック能力(エコーキャンセル)の評価
- イベント通知による詳細な内訳分析
- デモ用資産の出力機能
- 実音声ログによる再現テスト
- 人間による評価用インターフェース
- シナリオへのシチュエーション設定
既存のフレームワークが「何を言うか」の正しさを検証してくれるように、
VoiceInteractionEvaluatorは「どう聞こえるか」という部分の確認をサポートするツールでありたいと思っています。
実際に手を動かして、波形とログを突き合わせるパイプラインを作ったことで、
開発中のシステムの挙動が以前よりは把握しやすくなりました。
本稿の内容が、同じように音声インターフェースの開発で試行錯誤している方の参考になれば幸いです。
GitHub リポジトリ
https://github.com/tennmoku71/VoiceInteractionEvaluator