
はじめに
はじめまして。株式会社タップルで SRE(25新卒)をやっている鈴木友也です。
最近はセキュリティエンジニアみたいなことをやっています。
本記事は CyberAgent Group SRE Advent Calendar 2025 の 24 日目の記事です。
明日の記事は @ren510dev さんによる ABEMA 広告配信プラットフォーム強化における移設戦略とハイライトです。
直近タップルでは JavaScript で書かれた巨大なモノリスを TypeScript で書かれたマイクロサービスに移行するプロジェクトに取り組んでいました。このプロジェクトは事業的にも優先度が高く、SRE である僕もガッツリ開発に入り込み、大きめの機能移行を二つ担当しました。開発に参加する中で、色々な苦労や学びがあったため、本記事ではそれらについて SRE 視点で振り返ってみようと思います。
移行プロジェクトの全体像
タップルではマイクロサービス構成を採用しており、決済・認証・監視などは個別のマイクロサービスに切り出しています。今回のプロジェクトは旧モノリスの中に残っている全ての機能を適切にマイクロサービスに移行することを目的としています。移行自体は基本的には同じ機能を TypeScript 側のコードでも再現するだけ(これももちろん大変)ですが、今回のプロジェクトではチーム全体の方針として「単に移行するだけでなく、事業的な価値を上乗せしながら進めよう」という意思決定をしていました。以下に、大変だったけどやって良かったなと思う取り組みを説明します。
DDD によるリモデリング
一番やって良かったのがこれです。JavaScript から TypeScript になるだけでもある程度コードの品質は上がりそうですが、今回の移行ではソフトウェアとしての価値を最大化するために、Domain-Driven Design(DDD)を採用して一から機能のモデリング作業を行いました。DDD の詳細な説明は省きますが、その名の通りドメインに焦点を当てたソフトウェア開発手法です。DDD におけるドメインとはソフトウェアによって解決しようとしている特定の問題領域のことを指し、タップルの場合は「マッチング・恋愛」ドメインになります。DDD ではドメインを構成する概念とその関係性等をドメインモデルを用いて設計します。
ドメインモデリングは以下のステップで行います。
- 現状の仕様・振る舞いの詳細把握
- 特定の機能の理想状態を設計するためには、現状を把握する必要があります。調査の過程では、その機能にどのような制約条件があり、どのような振る舞いをするのかを詳細に調査します。また、他の機能との関わりも非常に重要なポイントになります。
- 理想状態の設計
- 調査結果をもとに、DDD の概念を適宜使いながら、移行する機能の理想状態を設計します。この時点で設計するのは抽象的な理想状態であり、具体的な実装ではありません。理想状態を考える時には、エンティティ、値オブジェクト、集約など DDD の世界の道具を使います。理想状態を設計するときに特に悩むのは、集約境界をどこに設定するか、集約を跨ぐ処理をどのように実現するか、などです。この辺りは DDD 的な一般論を踏まえた上で、チームにフィットするように全員で落とし所を議論しました。
- 実装方針の設計
- 理想状態が設計できると、往々にして現状の実装とギャップが生まれます。このギャップを可能な限り小さくできることが望ましいですが、パフォーマンスや既存のデータベースのスキーマ、その他様々な機能要件・非機能要件の問題などもあるため、完全に理想状態にするのは中々に骨が折れます。どの程度理想状態に近づけるかは本当にケースバイケースなため、この辺りはエンジニア・PM 間で議論をしながら具体的な実装を決めていきます。
僕は DDD に関してはなんとなく知ってるくらいの知識レベルだったため、社内の DDD プロに適宜相談しながら実装を進めました。以下の画像にもある通り、今回の機能は複数の機能が集約されるモジュラモノリス(これもマイクロサービスの一つ)が移行先だったため、DDD だけでなくモジュラモノリスとしての設計方針をどうするかなども相談しながら進めています。
SRE としてこれをやって良かったのは、インフラ関連のタスクだけをメインにこなしている時よりも格段にドメインに対する理解度が向上したからです。このドメインのこの機能・振る舞いはユーザーにどのような価値を提供しているのかを理解できるようになりました。これは SLI / SLO などのシステムの信頼性指標を考える上でも、非常に重要だと思います。
キャッシュ改善
機能全体を移行するなら、関連するインフラ周りもシンプルにしたいものです。
特に自分は SRE なので、ここは自分の出せるバリューの一つでもあります。
僕が担当したコア機能の一つは、大半のリクエストがデータの参照である典型的な read heavy な機能でした。read heavy であるが故に、大量のキャッシュを使うことでリクエストを捌いており、キャッシュサーバーである Redis クラスタがダウンするとサービスの利用が困難になる程の致命的な影響が予想される状態でした(以下の画像を参照)。
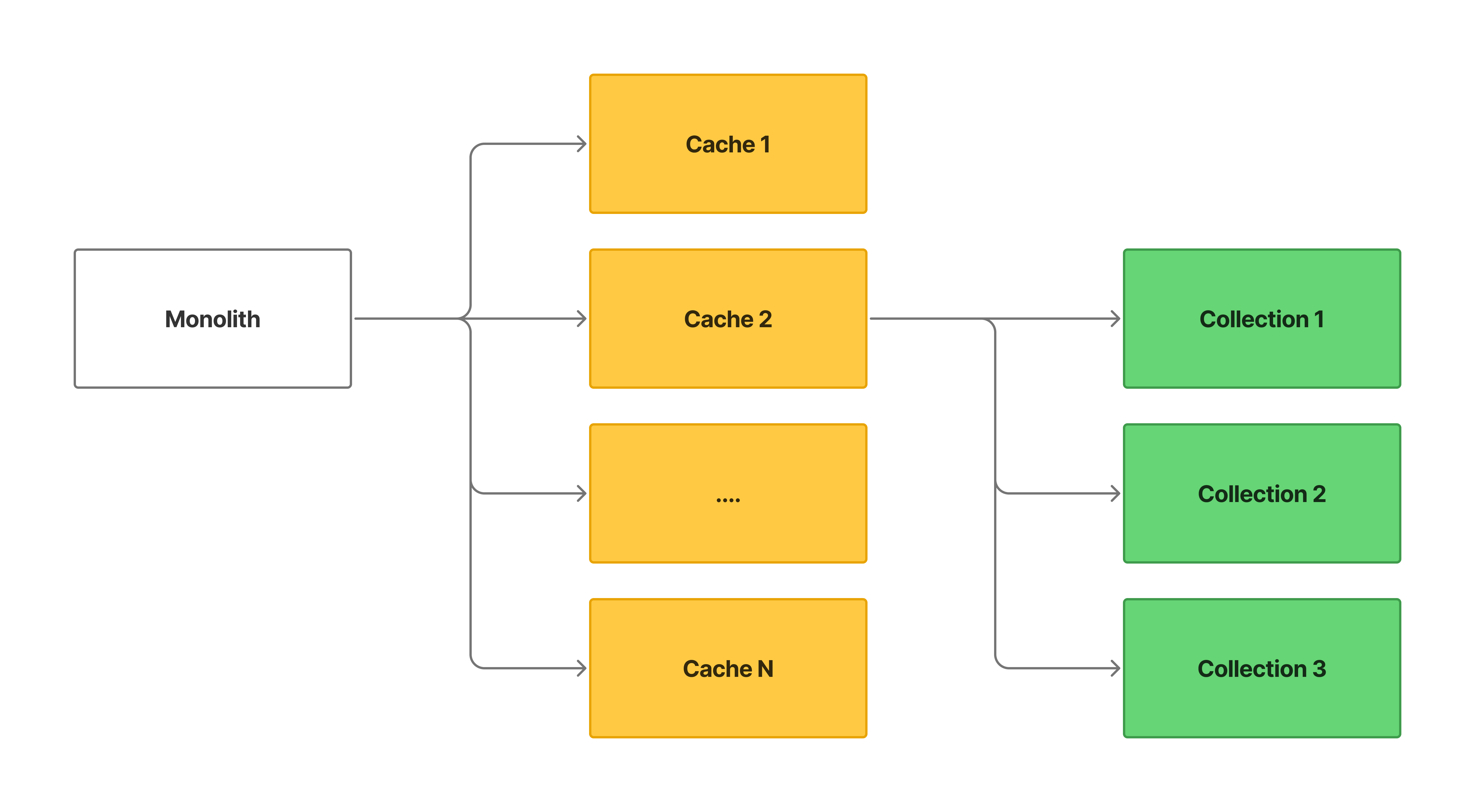
また、キャッシュは複数のコレクションやドキュメントから作られており、単純にドキュメントと 1:1 対応するようなシンプルな前段キャッシュではありませんでした。そのため、どうしても参照系のロジックが複雑になってしまうという問題も抱えていました。参照系の振る舞いで最もシンプルなのは、データを RDB などの永続データベースから取得してそのまま返すことです。ここに関してはレイテンシとのトレードオフですが、今回は「アプリケーションの実装・DB クエリの改善だけでレイテンシを十分に出せるものはキャッシュの利用を辞める」方針を採用しました。DB のスキーマを変える必要があったり、どう頑張ってもレイテンシが悪化しそうなものは素直に諦めています。また、以下のようなケースも妥協しています。
- 移行に伴い互換性の担保が求められるケース
- クライアントの修正が必要なケース
1 のケースは以下の画像のようなケースで、具体的には「色々な場所から参照されており、定期的にキャッシュの更新が求められるケース」です。
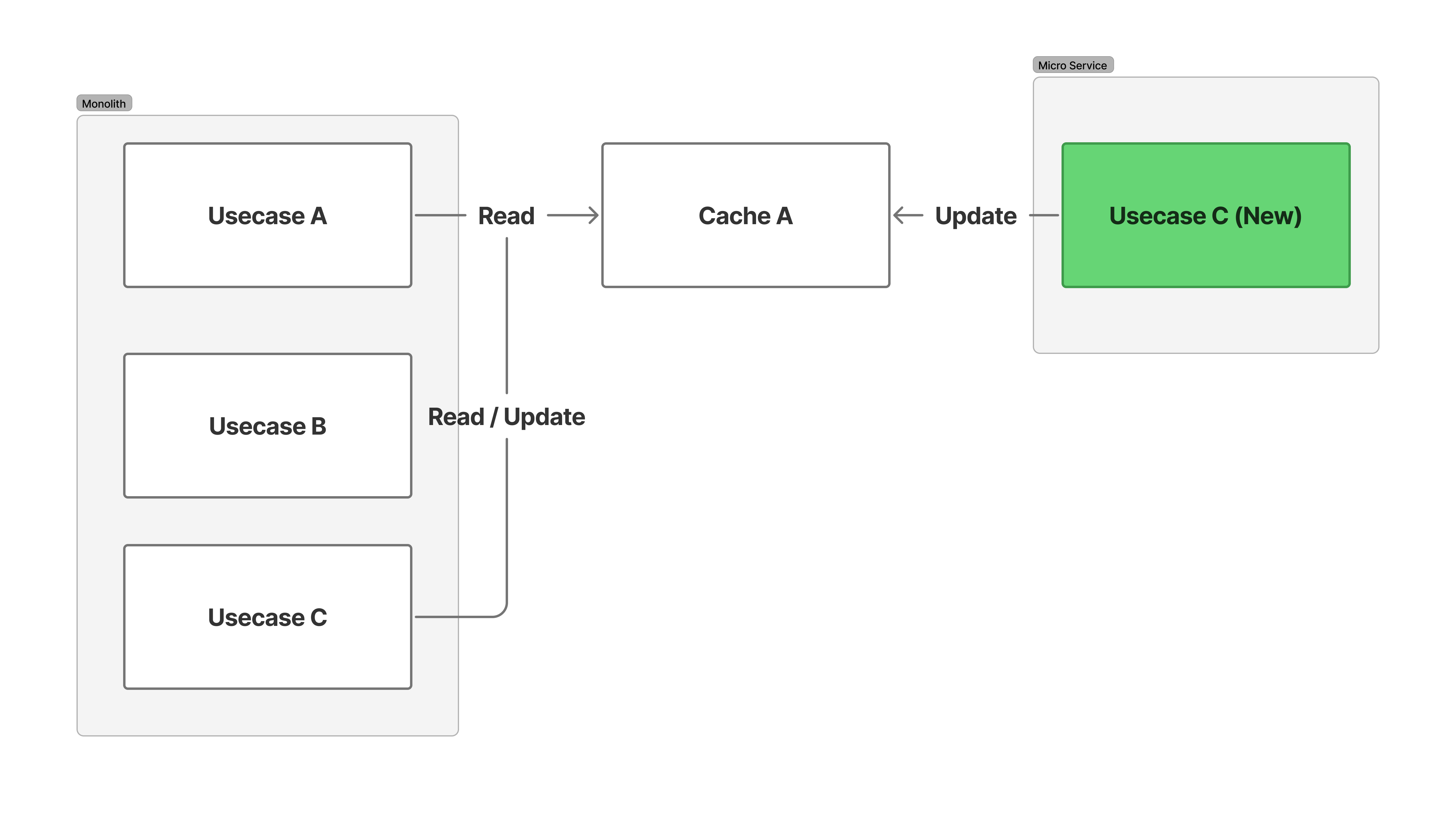
前提として、今回の移行は API 単位(ほぼユースケースの単位と一致)で段階的に行っています。さらに、リリース自体も段階的(カナリアリリース)です。そのため、「この API は移行したけど別の API はまだ移行してない状態」や「この API は移行中で、50% のユーザーが移行先 API にリクエストしている」と言うのが発生します。この状況下で、以下のように作業を進めると問題が発生してしまいます。
- モノリス側の Usecase C のロジックを綺麗にして、キャッシュに依存しない Usecase C (New) をマイクロサービス側に実装する
- Usecase C を段階的に移行する
- Cache A が適切に更新されず、Usecase A / B、モノリス側の Usecase C にアクセスした一部ユーザーへのレスポンスに不整合が生じる
一般論ではこのようなケースでは「Usecase A / B から移行して Usecase C を移行」します。つまり、先にキャッシュの参照を無くしたら更新する必要もないじゃん、と言う話です。しかし、今回は Usecase C 自体も段階的にリリースしていたため、どうしても Usecase C (New) の方でキャッシュの更新を辞めるとモノリス側の Usecase C にアクセスしたユーザーの結果はおかしくなってしまう状態でした。
2 のケースは単純にクライアントの調整が必要なパターンです。例えば、DB から取得するとかなり時間がかかるのでキャッシュを使っているが、そもそもクライアントでは利用されていない(でもスキーマ的に必須)ケースです。これは無駄な処理のため消したい気持ちはありましたが、
- タップルはネイティブアプリであり、全ユーザーに対してレスポンススキーマを変えるのは時間もかかるし大変であること(強制アップデート必須)
- 一部のユーザーに対してだけ変えた場合はクライアントのパースエラーになる
といった理由があり、これらに対してもこれまで通りキャッシュを使う方針にしています。
SRE 的にはこれで Redis クラスタのメモリ使用量が下がったらスペック下げてコストカットできるな〜とかも考えていたのですが、結論から言うとメモリ使用量は大して下がりませんでした。上記の理由から消すのを断念したキャッシュもあったこと、そもそも元々キャッシュデータ自体のデータサイズは小さかったことなどが理由かなと考えています。とはいえ、だいぶロジックの見通しが良くなったこと、キャッシュが落ちた場合のユーザー影響は確実に小さくなったことなどの明確なリターンもあったため、やって良かったと考えています。
パフォーマンス改善
元々遅い API はこれを機に速くできたらな〜と言う気持ちは結構ありました。そこで、最も直すのが大変そうな API に目をつけて、これを速くすることに挑戦しました。
この API はユーザーに対してツリー構造のデータを返すもので、データ構造(左)と DB 側のスキーマ(右)は以下のようになっています。実際はもっと大きいです。
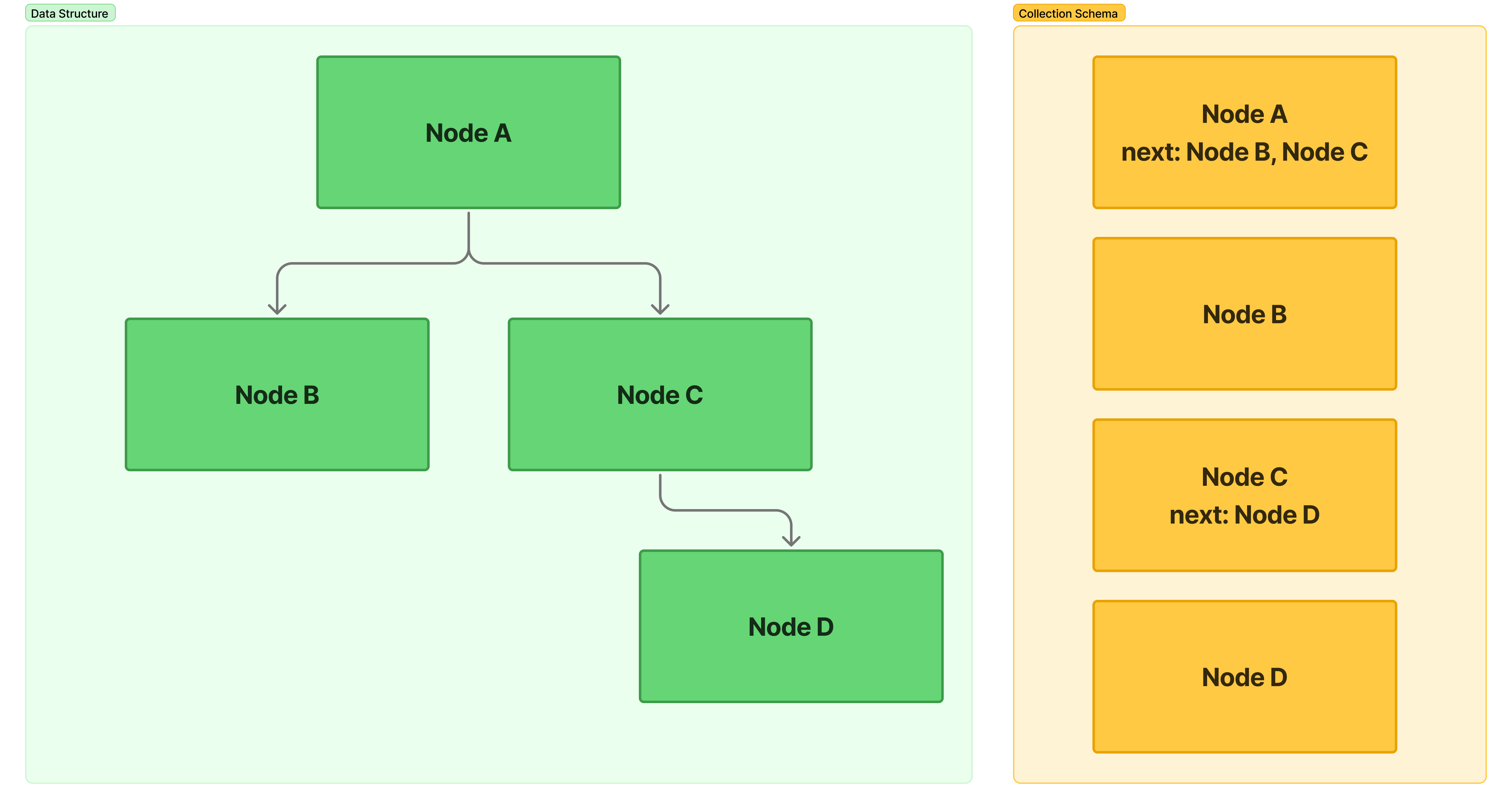
ツリーを格納するためのデータ構造は色々ありますが、スキーマ自体はシンプルに各ノードが子ノードへの参照(MongoDB なので _id)を持つ実装になっています。これ自体は MongoDB の公式ドキュメントでも典型的なパターンの一つとして紹介されており特に悪いものではありません。ではどうして遅いのか?と実装を追ってみると、単純にアプリケーションからのアクセス方法が良くなさそうでした。具体的には、単純にノードの回数だけループを回していました。このようなアクセスパターンだと 1 回の各クエリ自体は小さいですが DB へのクエリ発行回数が(我々のケースだと)数百回になってしまい、レイテンシ悪化を招いてしまいます。解決方法はシンプルでクエリの回数を減らすことです。例えば、以下のようなアクセスパターンも可能です。
- Node A を取得する
- Node B, Node C
- Node B, Node C の子ノードを全て取得する
- Node D
- Node D の子ノードを全て取得する
- 無し
この具体例だとアクセス回数は大して変わりませんが、一般化するとノードの各階層ごとに 1 回の DB アクセスで済むため高々数回程度です。MongoDB の場合、ある階層における子ノード全ての取得は $in クエリを使うだけです。これでも十分に速いのですが、MongoDB にはグラフ構造を扱うための $graphLookup というクエリがあります。このクエリを使うと一発でツリーを取得できるため今回はこれを使いました。これを使うと、
- Node A をルートとしてツリー全体を取得する
だけで終わります。参考までに、$graphLookup を使うステージは以下のような実装になっています。maxDepth はアプリケーション側で指定しています。lookupStage と書いているように、クエリ全体としては aggregation パイプラインとして組んでおり、ツリーを取得した後にデータをフィルタしたりノード数で limit をかけたりしています。
const lookupStage: PipelineStageGraphLookup = {
$graphLookup: {
from: '<collection>',
startWith: 'nextIds',
connectFromField: 'nextIds',
connectToField: '_id',
as: 'tree',
maxDepth: maxDepth,
},
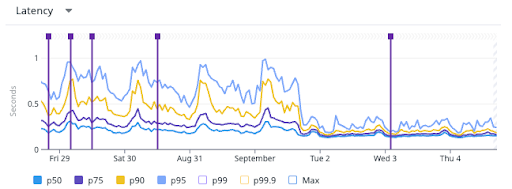
};ツリー構造は RDB と NoSQL で大きく設計が変わるデータ構造の一つだと思っており、この辺りの知見は中々ネットには落ちていませんでした。使う中で検証の必要な制約などもそれなりにあり、実際に本番のデータサイズと比較しながら将来的に制約がボトルネックになる可能性がないかなどを確認しながら進めました。結果として、P95 でパフォーマンスを 4 倍(レイテンシを 1/4)にできました。元々レイテンシの振れ幅が大きいのはおそらくキャッシュのせいで、上述したキャッシュ廃止によりレイテンシが安定してるのも読み取れます。
最後に
今回のプロジェクトは SRE としてガッツリ開発に携われる非常に貴重な経験でした。改めてロールにこだわるのではなく事業貢献のために個々人が何をやるか考えて動ける、そしてそれを受け入れる文化があるのはこの組織の好きなところだなと感じました。
タップルはサイバーエージェントの中でも特に知名度の高いサービスを提供しており、ECS をはじめとしたマネージドサービスや生成 AI を積極的に駆使することで少人数ながら高いレベルの実装とインフラを作ることができています。今後さらに事業を成長させていくために絶賛 We are hiring なので、興味のある方は是非ご応募頂けると嬉しいです!!