
はじめに
みなさんこんにちは、東京大学大学院工学系研究科修士1年の海野 大輔です。
2026年1月の約1ヶ月間、サイバーエージェントで「CA Tech JOB」という就業型インターンシップに参加させていただきました。私は株式会社AJA の DSP チームで、バックエンドエンジニアとして勤務させていただきました。
この記事では、インターンシップ期間中に私が取り組んだこととその成果についてご紹介します。
背景
AJA では Demand Side Platform (DSP) と呼ばれる、広告配信プラットフォームの開発・運用を行っています。大量のトラフィックをリアルタイムで処理することが求められ、高速かつ安定したシステムが非常に重要になります。
AJA DSP は、複数のコンポーネントに分割されたマイクロサービスアーキテクチャを採用しており、各サービスは Google Kubernetes Engine (GKE) 上で運用されています。これにより、各コンポーネントは独立にリリースを行うことができます。また、負荷分散や自動リトライ、Outlier Detection など高度なトラフィックコントロールを実現するために、Istio (Envoy サイドカー) サービスメッシュを導入しています。
課題
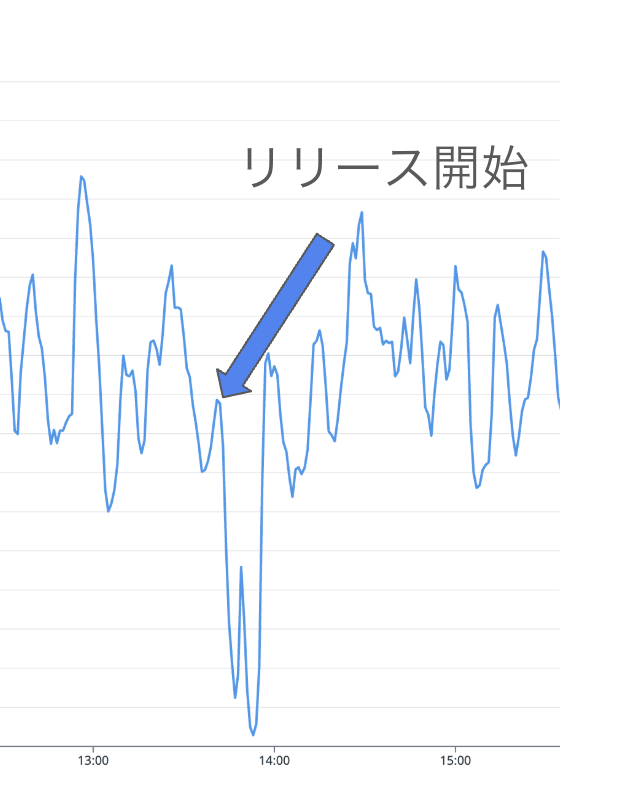
AJA DSP では、いずれかのコンポーネントをリリースした直後に応札率が大きく減少するという課題がありました。応札率とは、Supply Side Platform (SSP) から送られてくる入札リクエストのうち、DSP が実際に応札した割合を指します。システムエラーにより、応札を逃すとビジネス上の機会損失につながります。
原因の仮説とその対応 ①
原因を調査するため、まずはリリース時に終了する Pod のログを確認しました。
すると、下記のエラーが多数発生していることが確認できました。
response_details:"upstream_reset_before_response_started{remote_connection_failure,delayed_connect_error:_111}"
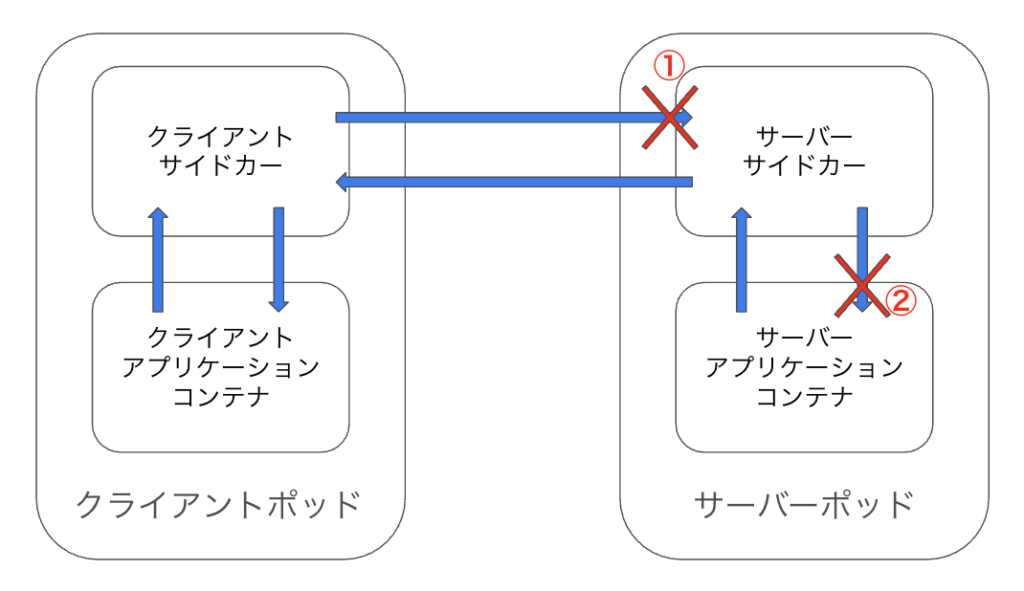
これは、指定された IP アドレスとポートの組み合わせで Listen しているプロセスがない場合に発生するネットワークエラーです。このエラーから、
① クライアントサイドカーからサーバーサイドカーへの通信
② サーバーサイドカーからサーバーアプリケーションへの通信
のいずれか、もしくは両方でエラーが発生していることが予想されます。
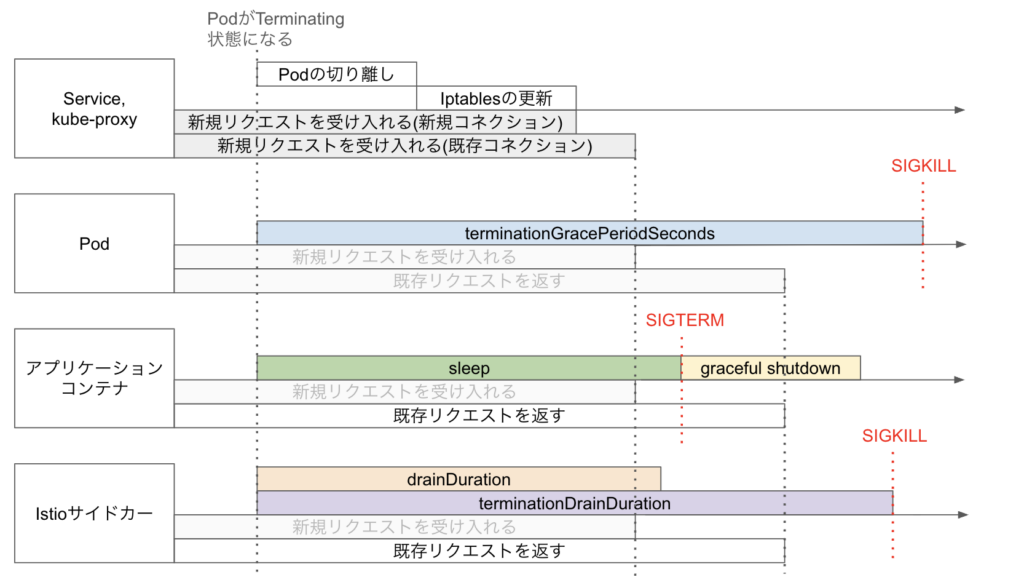
Pod が終了し、Terminating 状態になると、以下の3つの処理が互いに独立して並列に実行されます。
- アプリケーションコンテナの終了処理
- Service から Pod へのルーティングの除外
- Istio の Envoy サイドカーの終了処理
これらの終了タイミングが適切に制御されていない場合、一部のリクエストがネットワークエラーになる可能性があります。
Pod の終了処理に関連するパラメータを以下の表にまとめました。
| パラメータ | 種別 | 説明 |
| terminationGracePeriodSeconds | Pod | Pod が terminating 状態になってから graceful shutdown するための猶予時間。過ぎるとコンテナにSIGKILL が飛び強制終了させる |
| アプリケーションの sleep 時間 | アプリケーションコンテナ | 新規リクエストのルーティングがなくなるまで、アプリケーションの graceful shutdown をこの時間待たせる |
| graceful shutdown の timeout | アプリケーションコンテナ | アプリケーションが既存リクエストの処理を完了させた上で正常に終了する、graceful shutdown にかかる最大時間 |
| drainDuration | Istio | Envoy の drain 状態の時間 |
| terminationDrainDuration | Istio | Istio が Envoy を kill するまでの時間 |
これらのパラメータを下記の不等式を満たすように調整することで、リリース時に全てのリクエストが処理されるようにしました。

また、これらの関係性を図示すると下図のようになります。
参考: https://christina04.hatenablog.com/entry/k8s-graceful-stop-with-istio-proxy
結果 ①
上記の対応後にリリース時に終了する Pod のログを見ると、対応前にでていたネットワークエラーが現れなくなりました。よってこのエラー原因の仮説は正しかったと考えられます。
しかしながら、応札率自体は上記の対応後も改善しておらず、応札率低下の根本的な原因は別にあると考えました。
原因の仮説とその対応 ②
次に、今回リリースしたコンポーネントとは別に、リクエストの出入り口となるコンポーネントのログを確認しました。すると、下記のようなエラーが発生していることが分かりました。
rpc error: code = Canceled desc = context canceled
AJA DSP は Go 言語で実装されており、上記のような context のキャンセルに起因するエラーが多数確認されました。
リクエストの出入り口となるコンポーネントにアクセスしている上流コンポーネントで設定された deadline に到達した結果、下流では context のキャンセル (context canceled) としてエラーが観測された可能性が考えられます。
このようなタイムアウトに至る要因として、一連のリクエスト処理の中で時間を要している箇所に着目すると、データベースアクセスのレイテンシがボトルネックになっている可能性が浮かび上がりました。
今回リリースしたコンポーネントでは Cloud Spanner へのアクセスが発生しており、その負荷を軽減するために go-cache を用いたインメモリキャッシュを利用していました。
この構成では、リリース時にキャッシュが十分に溜まっている既存の Pod が終了し、キャッシュを持たない新しい Pod が起動します。
その結果、新しい Pod にルーティングされたリクエストはキャッシュミスを起こしやすくなり、Cloud Spanner へのアクセスが一時的に急増すると考えられます。
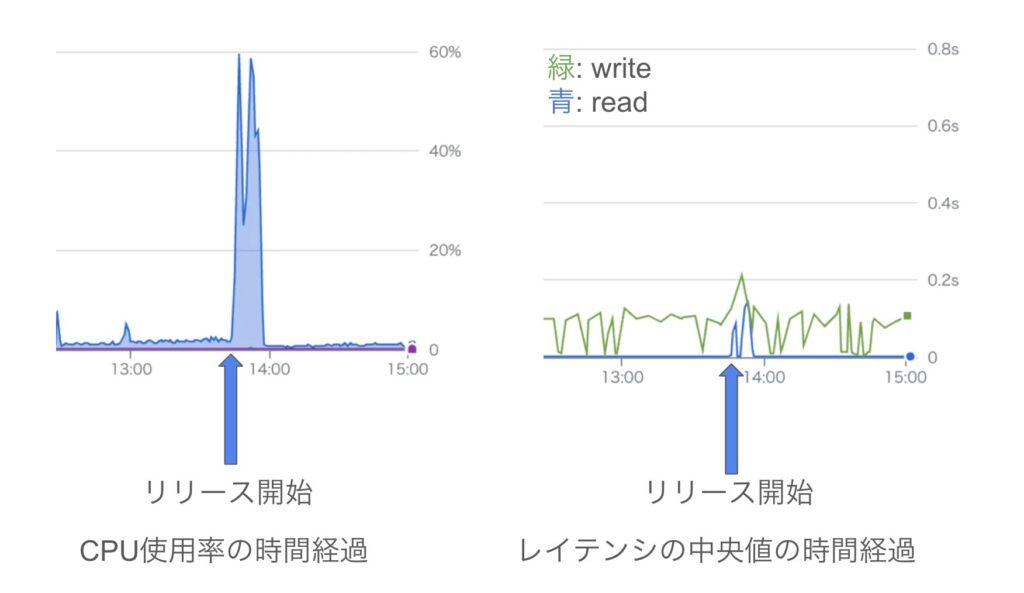
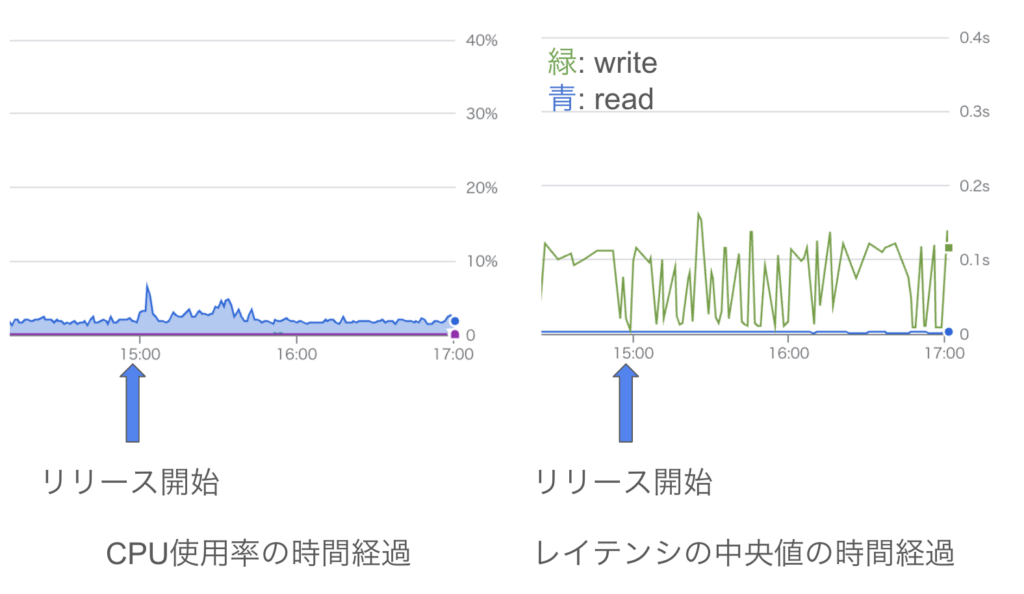
実際にリリース時の Cloud Spanner のメトリクスを確認すると、以下の画像のように CPU 使用率および 読み取りのレイテンシが大きく増加しており、この仮説を裏付ける結果となっていました。
この問題に対する解決策はいくつか考えられます。
例えば、Redis などを導入して外部にキャッシュを持たせることで、Pod の入れ替えによるキャッシュ消失を防ぐ方法があります。
しかし、今回のインターンシップは限られた期間の中での取り組みであったため、新たなサービスの導入は工数的な観点から現実的ではありませんでした。
そこで今回は、アプリケーションコードには手を加えず、Kubernetes のリリース戦略を見直すことで問題を緩和する方針を取りました。
AJA DSP では、Argo Rollouts を使用しています。rollout の設定を下記のように設定することで、Pod を一度に入れ替えるのではなく、1 Pod ずつ一定の間隔を空けてリリースが進むようにしました。
#既存の設定 spec: minReadySeconds: 0 #(デフォルト値) strategy: canary: maxSurge: 25% #(デフォルト値) maxUnavailable: 25% #(デフォルト値)
↓
#新しい設定 spec: minReadySeconds: 30 strategy: canary: maxSurge: 1 maxUnavailable: 0
maxSurge はリリース時に理想状態の Pod 数を超えて作成できる最大の Pod 数を表します。また、maxUnavailable はリリース時に利用不可となる最大の Pod 数を表します。maxSurge: 1, maxUnavailable: 0とすることで、必ず1つずつ Pod が起動するようになります。minReadySecondsは、Pod が作成されてから利用可能とみなされるまでの最小時間を表します。この値を指定することで、Pod の起動間隔を minReadySeconds 以上に制御することができます。
上記のリリースの流れを図示すると以下のようになります。
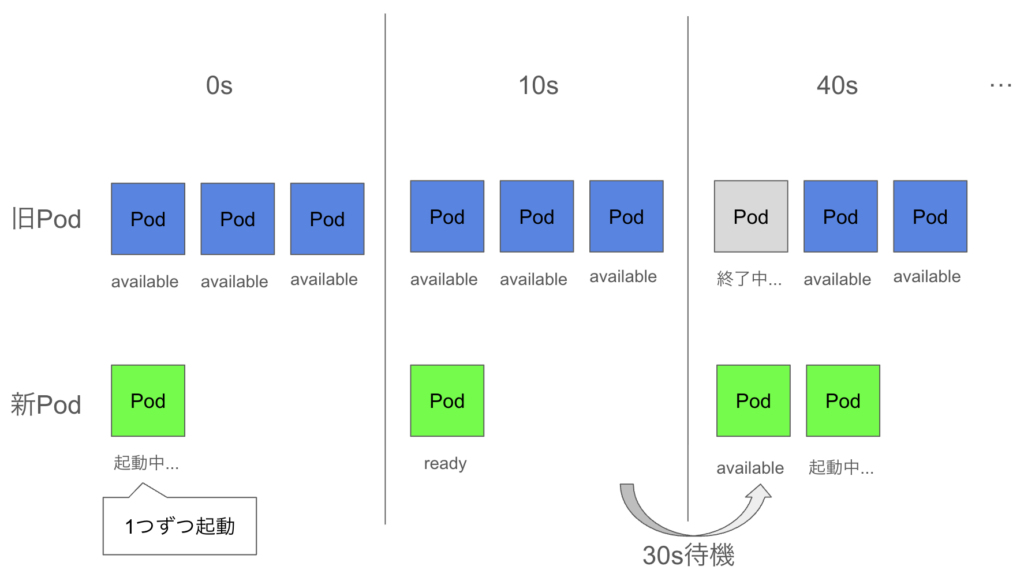
結果 ②
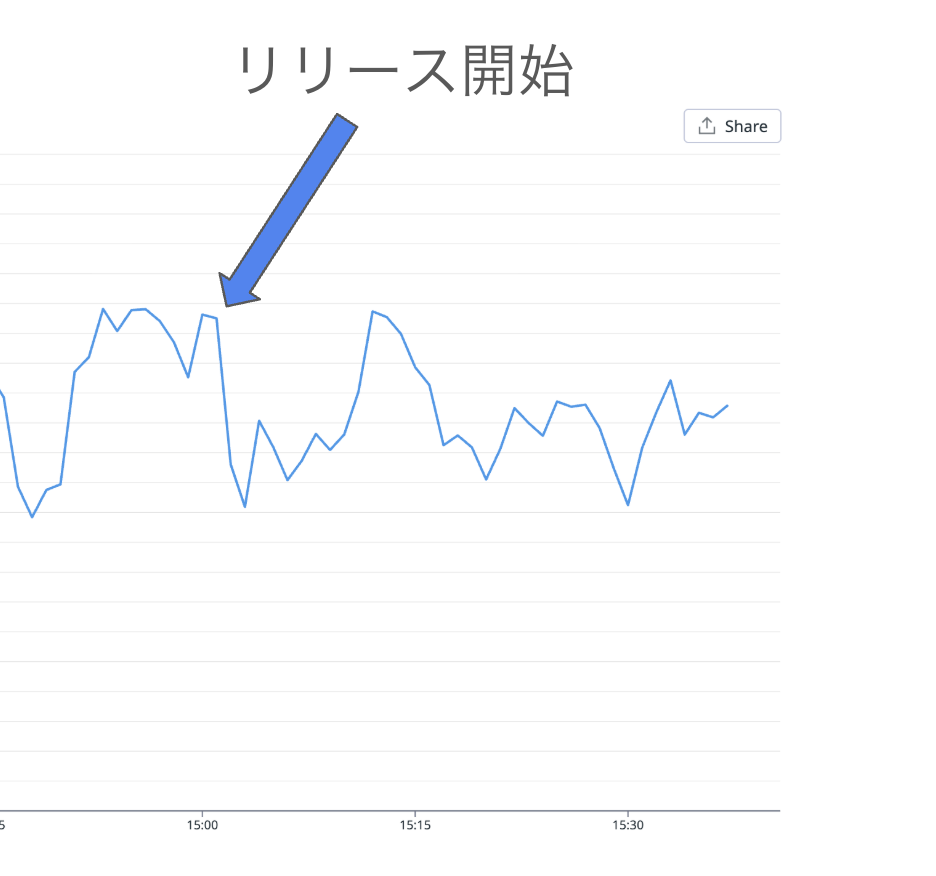
上記の対応後にリリースを行い、応札率の変化を確認したところ、下記の図のとおり、リリース時に大幅な応札率の低下は見られませんでした。
また、リリース時の Cloud Spanner のメトリクスを確認した結果、以下の画像に示すように、CPU 使用率および 読み取りのレイテンシのいずれについても大きな変化はなく、正常に処理されていることが確認できました。
今後の展望
今回の対応は、既存の構成を大きく変えることなく簡易的に実施できる点で有効でしたが、Pod を段階的に入れ替えるため、デプロイに要する時間が長くなるというデメリットもあります。
ただし、今回修正した rollout の設定値をチューニングすることで、エラーが発生しない範囲でデプロイ時間を短縮する余地はあると考えています。
しかしながら、このような調整を行ったとしても、デプロイ時間が従来より長くなることは避けられません。
そこで今後は、Redis などを導入して外部にキャッシュを持たせることで、Pod の入れ替えによるキャッシュ消失そのものを防ぐといった、より根本的な解決策についても検討していきたいと考えています。
また、今回の調査では、リクエストの出入口となるコンポーネントのログから context のエラーを確認することはできたものの、実際にどこでエラーが発生したのかを特定することは困難でした。
この課題に対しては、将来的に分散トレーシングを用いて、リクエストに一意な ID を付与し、各コンポーネントで context の状態をトレースに記録することで、context のエラーがどのリクエストのどこで発生したものなのかを特定しやすくなると考えています。
その他の活動
トレーナー/メンター制度について
CA Tech JOB では、各インターン生に対して、トレーナーとメンターが1人ずつつくサポート体制が整えられていました。
タスクの相談やキャリアの方向性についてまで、気軽に何でも相談できる環境が用意されており、安心して業務に取り組むことができました。
特に印象的だったのは、毎日のようにトレーナーとの 1on1 の機会が設けられていた点です。その中でこまめにフィードバックをいただくことができ、自分では気づけなかった課題や改善点を早い段階で認識できたことは、大きな成長につながったと感じています。
また、トレーナーやメンターに限らず、チーム内外のさまざまな方が相談に乗ってくださり、技術的な議論やキャリアに関するお話を通じて、多くの学びを得ることができました。
ランチについて
インターン期間中は、異なる事業部の方々と一緒にランチに連れて行っていただく機会がありました。
様々な部署の方とお話しする中で、事業部ごとの体制や採用されている技術について知ることができ、サイバーエージェントに対する解像度が大きく高まりました。
おわりに
今回のインターンに参加した背景には、高トラフィック環境におけるプロダクト開発を実践的に経験したいという思いがありました。
インターン期間を通じて、大量トラフィックを扱う DSP の開発や、リリース時に求められる手順・思考法を、実際の運用環境の中で学ぶことができたのは、非常に貴重な経験でした。特に、インターン参加前は Kubernetes に触れたことがありませんでしたが、理解を深めながら現行の運用を見直し、実際に改善につなげるところまで取り組むことができました。
このような経験ができたのも、トレーナーやメンターの方々をはじめ、AJA の開発チームの皆さまが親切にサポートしてくださったおかげだと感じています。この場を借りて、心より感謝申し上げます。