
目次
この記事で学べること
- 仕様書 AI 活用を組織に定着させるためのプロセス
- 理想の仕様書を言語化し AI に読み込ませる方法
- AI ツール導入時に「使われない」を防ぐ工夫
想定読者
- 仕様書作成に AI を活用したい人
- 組織への AI ツール導入・定着に興味がある人
はじめに
株式会社 WinTicket でエンジニアをしている長田卓馬(@ostk0069)です。
本記事では、WINTICKET における仕様書の AI 活用について紹介します。2025 年 12 月〜 2026 年 1 月の 2 ヶ月間で 36 件の仕様書が作成され、そのうち 33 件(92%)は AI と一緒に書かれたものです。WINTICKET では企画フェーズで作成する「要求仕様書」と設計・実装フェーズで作成する「開発仕様書」の 2 種類があり、詳細は後述します。
| 仕様書の種類 | AI活用率 |
|---|---|
| 要求仕様書 | 20/21 件(95%) |
| 開発仕様書 | 13/15 件(87%) |
本記事ではその取り組みの全体像と、定着に至るまでのプロセスを共有します。
仕様書AI活用の前提
仕様書の AI 活用で重要なのは、AI の精度ではないと考えています。
一定精度のモデルが使える状態があれば十分であり、成果を左右するのは以下の 2 点です。
| 重要な要素 | 内容 |
|---|---|
| 仕様書の言語化 | このプロダクトにとっての理想の仕様書を定義し、AI に読み込ませる |
| 利用者へのチューニング | 誰が書くのか、どんな課題があるのかを把握し、使いやすい形で提供する |
これにより、せっかく AI の土台を用意しても使われないという事象を防げます。
AI活用のゴール
この取り組みは 2025 年 9 月に開始しました。2026 年 2 月時点のゴールとしては、理想の仕様書を 100 点とした時、AI では 80 点までを保証できるようにすること、そして 80 点を出すスピードを人間がやるよりも圧倒的に早くできることをゴールとしています。
100%ではなく 80%をゴールとした理由は、仕様書領域において 100%の仕様書を AI が作る状態を目指すのは難易度が高いためです。具体的には以下のような課題があります。
- 開発時に必要なコンテキストが 100%データ化されておらず、AI 側がそのコンテキストにたどり着けない
- AI を活用する人間の AI への理解度にばらつきがある
- プロダクトの細かい仕様を理解し、AI に適切に伝える難易度が高い
このように様々な変数があるため、まずは 80 点を安定して出せる状態を目指しました。
組織状況の整理
仕様書を書くのは誰か
WINTICKET では誰もが施策を提案、遂行できます。そのため、仕様書をこれまで書いたことのないメンバーが仕様書を書くことはよくあります。またビジネス、エンジニア、デザイナーなどの職種を問いません。
一方で、「良い仕様書とは何か」を組織として明文化できておらず、オンボーディングの仕組みも整っていませんでした。そのため、仕様書の粒度や書き方が属人的になりやすい状況でした。
既存仕様書の課題
既存の仕様書運用には、大きく 2 つの課題がありました。
ドキュメント品質の課題
| 課題 | 具体例 |
|---|---|
| 情報が不足している | 開発時にエンジニアがソースコードレベルで既存仕様の調査が必要なことがあった |
| レビューガイドラインがない | 粒度や質が人により異なり、品質にばらつきがあった |
| 期待される内容が定義されていない | テンプレート構造はあるが、各セクションに何を書くべきかが明確でなかった |
プロセスの課題
| 課題 | 具体例 |
|---|---|
| 仕様変更時の更新フローがない | Design Doc やテスト仕様書など関連資料が連動更新されないことがあった |
これらの課題に対し、仕様書の情報が充実していればコミュニケーションコストを減らせ、事業としての開発効率が上がると考えました。
AI基盤を用意しても使われないリスク
仕様書を書くメンバーからすると、仕様書を書くために全く使ったことのないツールを使うのは学習コストが高いです。その場合、一部のメンバーしか使わないことや、オンボーディングが必要になり管理コストが結果的に高くなるなどの事象が考えられました。
一方で、前述のソースコードレベルの仕様調査についても、AI に仲介してもらうことで効率化できる余地があると考えました。仕様書作成だけでなく、調査のハードルを下げることも期待できます。
この懸念と期待を踏まえ、AI ツールの要件として以下を定めました。
| 要件 | 理由 |
|---|---|
| 学習コストがなるべく少ない | 全員が使えるようにするため |
| 対話可能(AI からも人間からも) | 最初のインプットから精度の高い仕様書を一発で出せないため |
| MCP(Model Context Protocol) で多種多様なデータソースにアクセス可能 | 既存の仕様やガイドラインを参照するため |
| GitHub のコードにアクセス可能 | 仕様の把握・確認のため |
理想の仕様書の定義
要求仕様書と開発仕様書
WINTICKET では要求仕様書と開発仕様書があり、それぞれ役割が異なります。
| フェーズ | 主な問い | ドキュメント | 作成主体 | 主な目的 |
|---|---|---|---|---|
| 企画・要件定義フェーズ | なぜこの開発を行うのか/何を解決するのか | 要求仕様書 | 誰でも | 事業判断に必要な情報を整理し、開発実施の可否を決定する |
| 設計・実装フェーズ | どのように実現するのか/どのように届けるのか | 開発仕様書 | 要求仕様書の作成者 + 開発・デザイン | 要件を実装可能な形に落とし込み、品質と再現性を担保する |
両者の棲み分けは以下の通りです。
| 観点 | 要求仕様書 | 開発仕様書 |
|---|---|---|
| 目的 | 「なぜ/何をつくるか」を定義し、事業判断を支援する | 「どうつくるか」を定義し、開発実行を支援する |
| 作成者 | 誰でも | 要求仕様書の作成者 + 開発・デザイン |
| 対象読者 | 事業責任者 | エンジニア・デザイナー |
| 粒度 | 判断できるレベル | 実装できるレベル |
| 終着点 | 開発 GO 判断 | 実装完了・リリース・振り返り |
今回の AI 活用は両方の仕様書が対象です。
仕様書のゴールを定義する
定義を作るために、まず仕様書のゴールを定義することから始めました。その結果、仕様書を読んだり、仕様書を元に何かをする人向けのものとして品質が高いことを定義としました。
具体的に仕様書を扱うのは以下のチームです。
- デザイナー
- エンジニア
- QA チーム(テスト仕様書・テスト項目書を作成)
- データマネジメントチーム(ログ設計・分析)
それぞれのチームにおいてどういうことが仕様書に書いてあると嬉しいかをヒアリングし、それらを満たせるようにすることが第一ステップでした。
各チームへのヒアリング結果
データマネジメントチーム
施策の振り返りのための指標が何になるか、この施策で改善したい KPI は何かを施策の初めに定義してほしいという声がありました。
サービスの特性上、ユーザーの行動は同時並行で行われており、開催中のレースやキャンペーンによって数字が変動するため、正しく分析するのが難しい傾向にあります。そのため機能作成時の振り返りや KPI の設計は難易度が上がります。結果として長い目で機能を分析するしかなく、明確な指標を置くのが難しい施策も一定数ありました。
QAチーム
その機能を QC する上で仕様以外に知っておくべき観点があれば追加してほしいとのことでした。例えば、アプリ固有やデバイス固有の差異が生まれるものであれば、その端末を用意して検証できるからです。
また、エラーハンドリングの網羅や、言語化が忘れられがちなエッジケースへの言及も必要とのことでした。
エンジニア・デザイナー
WINTICKET のプロダクトの性質上、状態による分岐が多く存在します。
| 分岐の種類 | 具体例 |
|---|---|
| ユーザーの状態 | 非ログイン、仮登録状態、本人確認済み状態などで使える機能が異なる |
| レースの状態 | 投票受付中、投票締め切り、発走中、レース終了、中止、順延など |
こうしたステータス分岐が多いため、分岐やエラーパターンとその時の挙動を網羅してほしいとのことでした。わかりやすさのために箇条書きではなく Markdown の Table で条件を MECE にまとめてほしい、仕様には必ず背景を記載してほしいという意見もありました。
要求仕様書の構成
ヒアリング結果を踏まえ、要求仕様書の構成を以下のように定義しました。各セクションには目的・記入例(GOOD/BAD)・チェック観点を定義し、品質を担保しやすい設計としました。
| セクション | 目的 |
|---|---|
| タイトル | 開発対象機能を簡潔に示し、チーム内での共通言語とする |
| 概要 | 要求内容の要点をまとめ、短時間で施策意図を把握できるようにする |
| 背景 | 開発が必要となった理由や、解決したいユーザー課題を明確化する |
| 要件 > ゴール | 施策成功の定義・理想状態の明確化 |
| 要件 > KPI | ゴールに対する評価指標を定義 |
| 要件 > 優先度 | 機能を 4 段階(P1 〜 P3、-)で評価 |
| 要件 > 工数 | 優先度毎に職種別で工数を見積もる |
| 仕様・画面イメージ | 具体的にどの画面をどう変更・開発するかを整理する |
| リスク | 想定されるリスクや課題を事前に洗い出し、検討・対策を促す |
| 関連資料 | 補足資料や関連ドキュメントを整理し、情報を一元管理する |
開発仕様書の構成
開発仕様書の構成は以下のように定義しました。開発仕様書では「仕様(What)」のみを記載し、実装詳細(How)は記載しないというルールを設けました。
| セクション | 目的 |
|---|---|
| タイトル | 施策名を明示し、ドキュメントの対象を特定する |
| 概要 | 要求仕様書へのリンクと目的の要約を記載する |
| 要件 > ゴール/KPI/優先度 | 要求仕様書と共通 |
| 仕様 > (画面名) | 各画面の目的・提供意図・挙動(エッジケース・エラー含む)を記載 |
| 仕様 > 仕様詳細 | UI 要素ごとの初期状態・操作・結果を記載 |
| 仕様 > エッジケース | 条件・挙動・備考を記載 |
| デザイン | 要件・仕様を満たすデザインデータを掲載 |
| 影響範囲 | リスクや懸念点を洗い出すために開発時に起きる影響を記載 |
| メンバーリスト | 担当領域と責任者を明確化 |
| 各種リンク/実装設計書 | 関連資料・仕様外コンテキストを整理 |
| 参考文献/関連資料 | 他施策・関連ドキュメントを明記し、横断的理解を促進 |
AIツールとインターフェースの構築
ツール選定
前述の要件を踏まえ、以下のツールを検証しました。
検証の結果、Devin を選択しました。選定理由は以下の通りです。
| 要件 | Devin での対応 |
|---|---|
| 学習コストが少ない | Slack から呼び出せるため、新しいツールを覚える必要がない |
| 対話可能 | Slack スレッドで対話しながら仕様書を作成できる |
| MCP でデータソースにアクセス | Kibela(RAG基盤経由)で類似仕様やガイドラインを参照可能 |
| GitHub コードにアクセス | DeepWiki でアプリ/Web/バックエンドのレポジトリ情報を把握可能。開発仕様書作成時にコードベースから既存仕様を読み取り、影響範囲の仕様も記載できる |
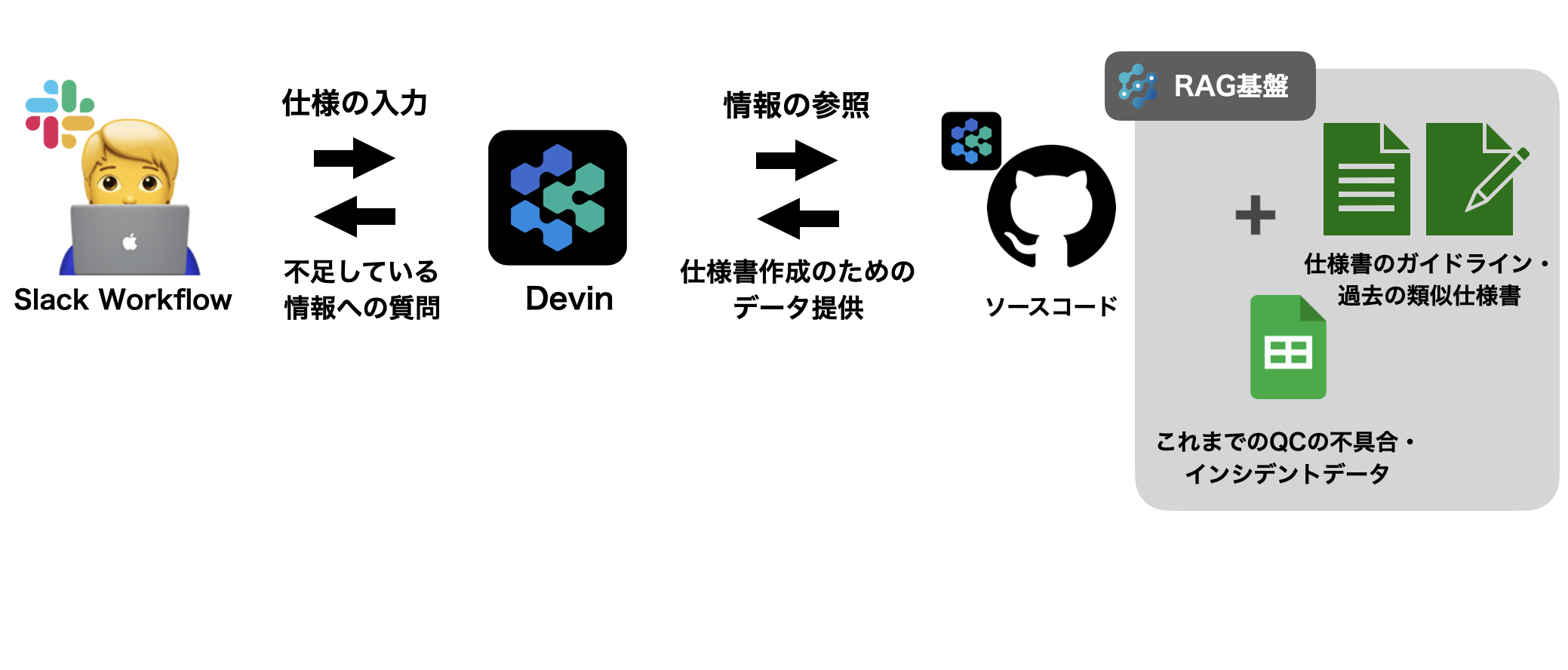
Slack Workflowによる起点設計
Slack の workflow を活用して、仕様書を書く際にまずは Slack 上でフォームを回答してもらう設計としました。フォームには以下の項目を設定し、回答しないと Devin が立ち上がらないようにしました。
要求仕様書を作成する際の入力項目
- 施策名
- 施策の概要
- この施策をやる背景
- この施策のゴールや KPI
- 影響のある既存箇所
- この施策でやらないこと
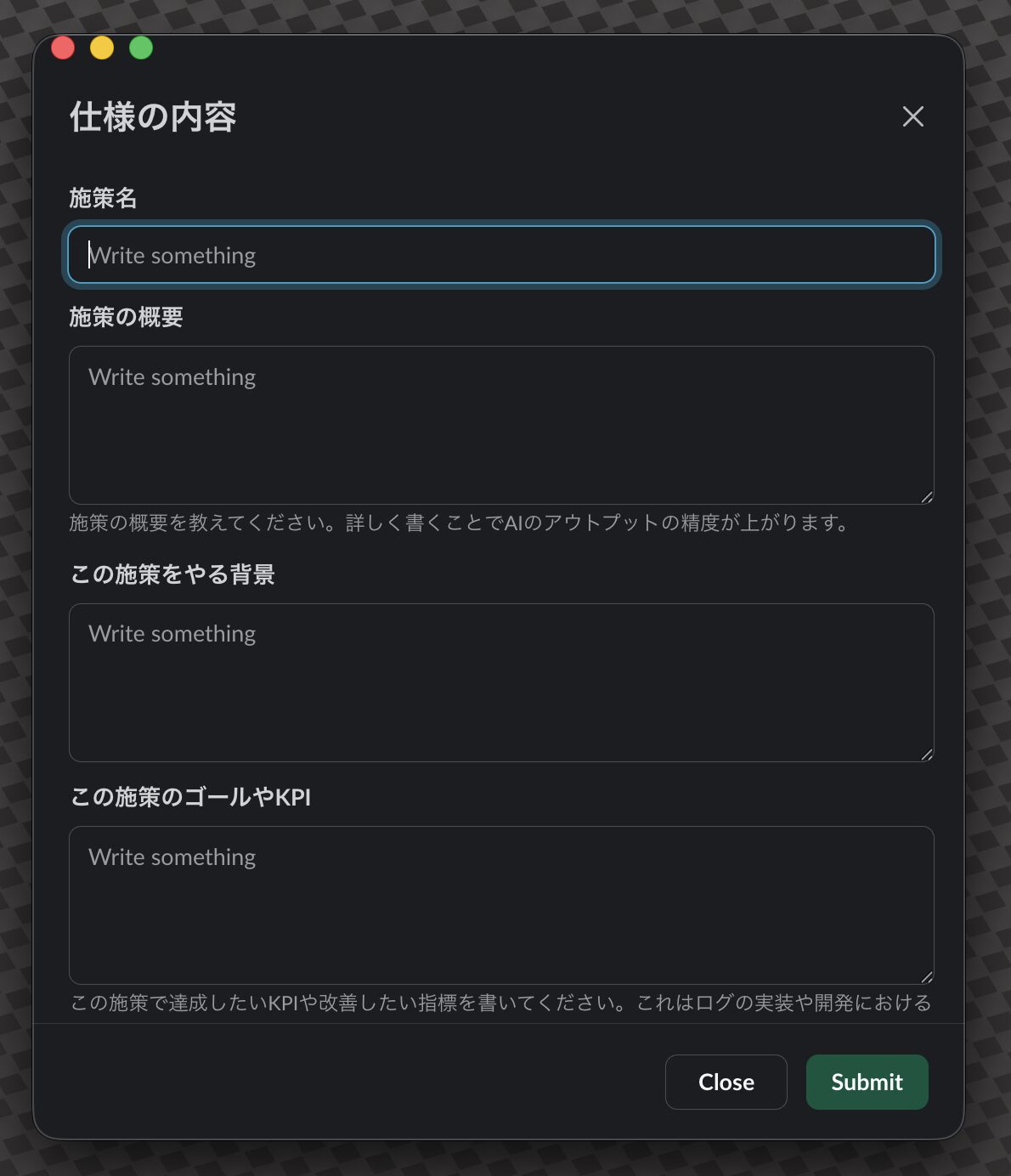
その後 Devin との Slack スレッドが立ち上がり、Devin からの質問に答えたり、指示を出したりしながら仕様書を作成します。

AIからの質問内容
Devin は入力された情報をもとに、不足している情報を対話形式で収集します。要求仕様書と開発仕様書では質問の観点が異なります。
要求仕様書作成時の質問例
| 観点 | 質問例 |
|---|---|
| 基本情報 | この施策の最重要ゴールは?対象ユーザーは誰か? |
| KPI・ゴール | KPI 目標値は?測定条件(期間・対象・母数)は? |
| スケジュール・優先度 | リリース期限は?優先度の根拠は? |
| 技術・実装 | 既存機能への影響範囲は?想定されるリスクと対応策は? |
| 工数対効果 | P2〜P3 で工数が大きい要素について、簡素化・延期・除外の選択肢を提示 |
開発仕様書作成時の質問例
| 観点 | 質問例 |
|---|---|
| ゴール・KPI | 要求仕様書のゴールとKPIの認識に齟齬がないか? |
| 優先度・機能要件 | 各機能の優先度に変更はないか?追加で「やらないこと」は発生していないか? |
| 画面仕様 | この画面で実現したいことは?ユーザーが行う主な操作は?エッジケースでの挙動は? |
| 非機能要件 | 利用が集中するタイミングはあるか?表示速度の要件は?エラー時の挙動で重視することは? |
| 影響範囲 | 調査結果に漏れはないか?追加で懸念される影響範囲は? |
このように対話を通じて情報を補完することで、抜け漏れのない仕様書を作成できます。
Playbookによる品質担保
Devin には Playbook(システム指示)を設定し、仕様書の品質を担保しています。要求仕様書と開発仕様書でそれぞれ異なる Playbook を用意しています。
要求仕様書のPlaybook
要求仕様書の Playbook は、フォームで入力された情報を起点に、自動で情報を収集・整理する設計です。
| フェーズ | 内容 |
|---|---|
| 情報収集 | ガイドライン取得、入力のパース、不足情報があればユーザーに質問 |
| 既存実装の調査 | RAGent MCP で Kibela 検索 + DeepWiki でコード調査 |
| 分析・整理 | テンプレートに沿って整理、各領域の工数を初期提案 |
| 工数対効果分析 | 優先度が中程度かつ一定の工数がある機能を抽出し、簡素化・延期・除外を提案 |
| 品質チェック | チェックリストで検証し、Kibela MCP で記事として投稿 |
開発仕様書のPlaybook
開発仕様書の Playbook は、対話形式で仕様を詳細化していく設計です。
| フェーズ | 内容 |
|---|---|
| 情報収集 | 要求仕様書の URL 取得、ガイドラインと「仕様書を書く上での心得」を読み込み |
| 既存実装の調査 | RAGent MCP で Kibela 検索 + DeepWiki でコード調査 |
| 対話による詳細化 | 画面ごとに対話テンプレートでヒアリングし、仕様を具体化 |
| 品質チェック | チェックリストで検証し、Kibela MCP で記事として投稿 |
開発仕様書では以下のルールを適用しています。
- 仕様(What)のみを記載し、実装詳細(How)は書かない
- 曖昧な日本語(「しばらく」「ある程度」「基本的には」等)を禁止
接続しているデータソース
| データソース | 接続方式 | 用途 |
|---|---|---|
| Kibela MCP | MCP | 仕様書の投稿・編集(仕様書は Kibela 上で管理) |
| RAGent MCP | MCP | 類似仕様の把握、ガイドラインの参照 |
| DeepWiki | Devin 組込 | アプリ/Web/バックエンドのレポジトリ情報、実装の把握 |
RAGent は CyberAgent の横断 SRE 組織である SRG によって開発された RAG 基盤です。Kibela、Slack、SpreadSheet などあらゆるツールをデータソースとしてベクトル検索可能にするもので、過去の仕様書や関連するナレッジを効率的に参照できます。
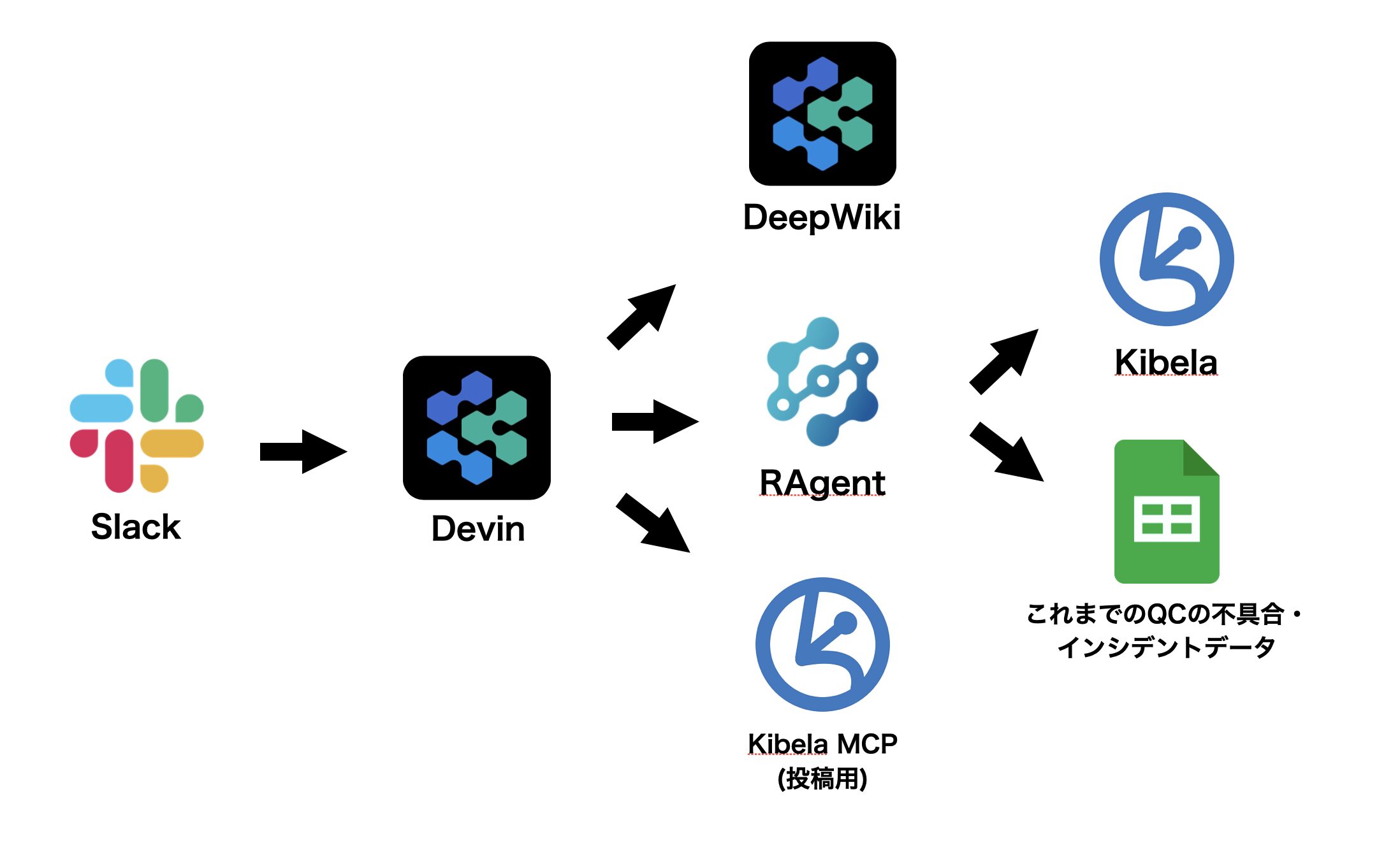
その結果、以下のフローによって仕様書が作成されます。
まとめ
WINTICKET では直近 2 ヶ月で 36 件の仕様書が作成され、そのうち 33 件(92%)は AI と一緒に書かれました。
この取り組みで重要だったポイントは以下の 3 点です。
- 理想の仕様書を言語化する: 各チームへのヒアリングを通じて「良い仕様書」を定義し、テンプレートとガイドラインに落とし込んだ
- 学習コストを最小化する: Slack から呼び出せる Devin を採用し、新しいツールを覚える負担を減らした
- 定着のための工夫: 事前に数人に触ってもらい先行ユーザーを作ったこと、Slack で feedback チャンネルを設けて継続的に Playbook を改善したことが定着につながった
仕様書の AI 活用において高度な技術は必要ありません。組織として理想の仕様書を言語化し、それを AI に読み込ませる体制を作ること、そして誰が仕様書を書くのかを把握し、その人たちが使いやすい形で AI を提供することが重要です。
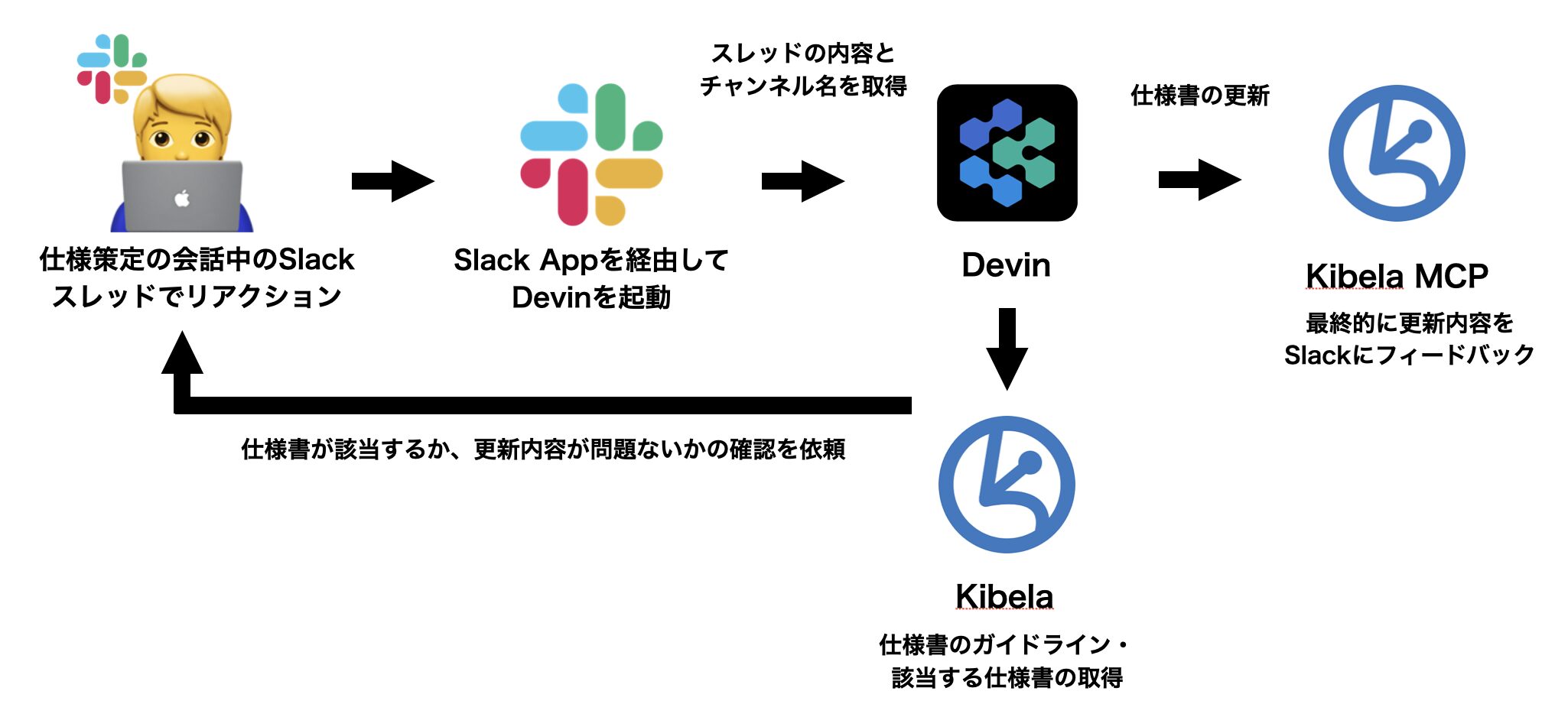
おまけ:Slackリアクションで仕様書を更新する仕組み
仕様書は作成して終わりではなく、開発中や運用中に更新が必要になることがあります。しかし、Slack で仕様に関する会話をしたことで満足してしまい、仕様書への反映を忘れてしまうことはよくある課題です。
この課題を解決するために、リアクションひとつで仕様書を更新できる仕組みを構築しました。
仕組みの概要
- 仕様に関する会話が行われた Slack スレッドに、特定のリアクション(絵文字)をつける
- Slack App がリアクションを検知し、Devin を起動するメッセージを投稿
- Devin が更新用の Playbook を起動
- チャンネル名や会話内容から対象の仕様書ファイルを特定
- Kibela MCP を利用して仕様書の更新作業を実行
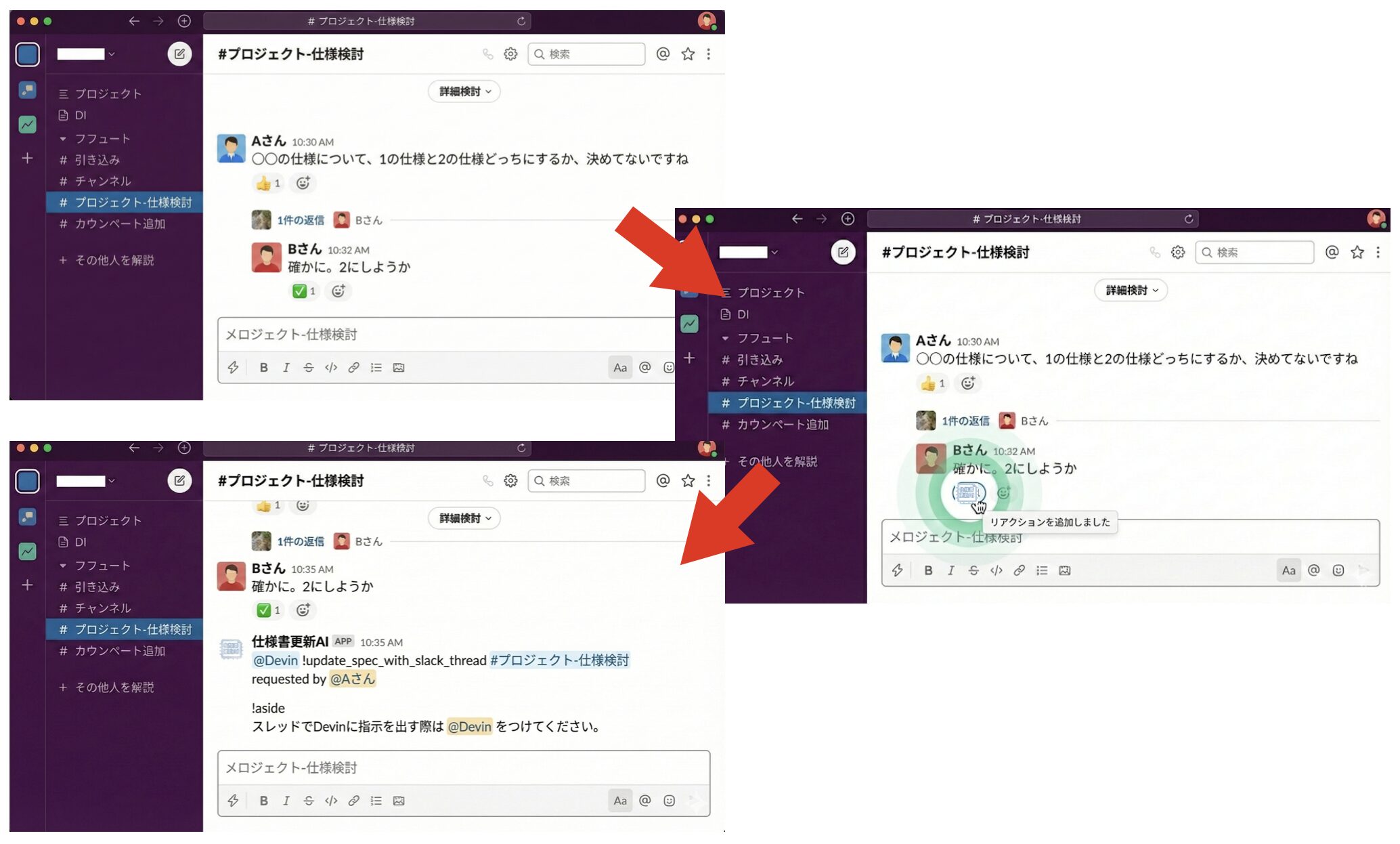
以下のフローで仕様書更新が行われます。
この仕組みのメリット
| 課題 | 解決策 |
|---|---|
| 会話で満足して仕様書への反映を忘れがち | リアクションという簡易な動作で更新を開始できる |
| 仕様書の場所を探すのが手間 | AI がチャンネル名や会話内容から自動で特定 |
| 更新作業自体が面倒で後回しになる | Devin が更新作業を代行 |
リアクションという日常的に使う簡易的な動作をトリガーにすることで、仕様書の更新漏れを防止できます。
参考リンク
- Devin – 本記事で採用した AI エージェント
- MCP(Model Context Protocol) – AI と外部データソースを接続するためのプロトコル
- RAGent – CyberAgent SRG による RAG 基盤(Kibela 検索に使用)
- Kibela – 仕様書の管理に使用しているドキュメントツール
- DeepWiki – GitHub リポジトリのコード調査に使用しているツール