
1. はじめに
こんにちは!AI事業本部の協業リテールメディアdiv.において小売アプリ向けの広告サービスの開発をしている25新卒エンジニアの藤本隆晟(@fujiryu0202)です! CyberAgentでは、職種を問わずAI活用を推進する文化があり、開発エージェント導入への年間4億円の投資や、社内でのAI活用状況の可視化などが積極的に行われています。ちなみに、私は先日この社内ランキングで、Claude Codeの利用実績が社内2位となりました(分母はマスクしてます)。この記事では、エンジニア2人体制でもエンジニア6人分くらいのアウトプットの量を出すための AI開発基盤の構築についてと、その活用法についてお話しします。
2. 私たちの運用しているサービスと課題について
まず、私たちのサービスについて軽く紹介します。近年、リテールメディアという言葉がよく聞かれるようになりましたが、私たちは、小売メディア(小売がもつアプリ)において、商品理解をした上で購買に繋げるためのリワード型広告サービスを開発・運用しています。下記に過去に掲載されたサッポロドラッグストアとヤマダデンキに導入した際のプレスリリースを載せます。


このサービスでは、広告を配信するための配信サーバはもちろん、各小売のトンマナに合わせた広告を表示するアプリ内Webビュー、アプリに導入をするためのSDK実装、広告入稿するための管理画面、配信実績や小売POSデータを分析するための分析基盤、等々、バックエンド、フロントエンド、ネイティブ、データサイエンス領域 … と、とても多くの技術だったり、もっというと小売に対するドメイン知識だったりが求められるサービスになっています。
このサービスはリリース時はエンジニア6名、ビジネス3名でエンジニアのチーム体制だったのですが、現在ではエンジニア2名、ビジネス1名体制でサービスを運用しています。エンジニアに関しては僕と開発責任者の2人です。しかし、人数が減ったからといって実施する広告案件や施策が待ってくれるということもなく、開発速度は維持(なんなら現在立ち上げ期なのでもっと向上)していかないといけない状況をぶつけられました。そこで僕らが決断したのは、AIを単なる「補助ツール」として使うのをやめることでした。AIエージェントを自律的な「チームメンバー」として大量生産し、AI駆動の次世代開発基盤を構築する。 まだ誰も正解を持っていないこの領域で、僕たちが先導的に開拓してきた「2人で6人分実装する」ための戦術の過程を解説します。
ちなみに、今回の記事では主にClaude Codeでの話をするのですが、昨年12月初旬では 私たちの開発基盤はAI駆動?なにそれ?程度でした。しかし、1月末現在、リポジトリ内にはAIエージェントで利用する、Skillが37個、SubAgentが24個 と用途や担当領域別にAIが専門的な知識をつけるための仕組みを整えることができています。
3. みなさんAI活用できてますか?
みなさんは、AIを使った開発でどのくらい効率が上がっていると感じていますか?僕自身、最初はAIを会話相手として利用することで簡単な修正をしてもらったり、少し煩雑な実装も依頼して違う部分を見つけたらまた依頼して… (N回ループ)みたいなことをやっていました。でも、今は開発のプロセスのほとんどをAIでやってもらうようになりました。自分たちのチームでは、AIを「主導者」そして人間は「監督」とする開発フローにすることで、AIを補助ツールとする開発からAIをフル活用した開発にシフトさせました。
導入と活用の壁
僕は、AIを補助ツールとして使っていた頃から思っていたことがあり、それが
「AI使うことで自分でやるべき作業は減ったけど、これって効率化できてるんだっけ … ?」
ということです。おそらく世の中的に思われているAIを使った開発イメージは
- 実装タスクに対して、仕事が早く終わるようになる
- ほとんど全部AIにやらせられるから人間の仕事が楽になる
という感じなのではないでしょうか。でも、それって本当でしょうか?僕自身は
実装タスクに対して、仕事が早く終わるようになる
→ 利用方法によっては業務効率は悪化ほとんど全部AIにやらせられるから人間の仕事が楽になる
→ 実装効率を上げるには、むしろ集中力やコンテキストスイッチを頻繁に行う能力が求められるため楽になるわけではない
と考えています。僕自身、今回AI駆動開発に切り替える際に下記のような体験をしました …

今のAIを使った開発の社会的な現在地
読者の中には、AIを入れることで逆に仕事効率が落ちたと感じている人も少なくないと思います。
これは僕の感想なのですが、技術に特化して強いエンジニアほど、最初AIを使うまでのハードルとして、「自分でやるより効率が悪くなる」というのが浮かぶのではないかと思っています。たしかに、AIがプログラミング初学者の書くような意味のわからないコードを生成してこられても、それを修正する方が工数ですし、この気持ちもわかります。
大半のエンジニアはこの例に挙げたこと以外でも、さまざまな要因によって、AIはあくまで「補助ツール」のような使い方が現状多くなっているのではないでしょうか?この補助ツールに留まっている理由としては、2, 3年前と比較すると、当時では考えられないくらいAIが進歩し、日々のアップデートに追いつけてないというのももしかしたら要因に挙げられるかもしれません。(僕もまだまだAIど素人だと思っています)
最近ではSkillやSubAgent、さらには直近ではAgent Teamsなども登場し、まだこの開発業態にベストプラクティスがない中で、利用方法を模索している状況という方も多いと思います。それが故に、とりあえずAIの出してくる答えの精度を上げるためにSkillやSubAgentを導入まではいくものの、主導者は人間 の状態になっているプロダクトが多いのだと僕自身は考えています。
僕の考える AIを “活用” するための方法
では、どうやったら、AIを補助的なツールではなく、活用した開発にできるのか?僕自身の答えとしては下記の2点だと考えています。

前者については、今まで話してきたようなAIの補助ツール的な使い方においては、主導者はあくまで人間であり、方向性を途中途中で操作しているのは人間です。しかし、AIを活用させるためには、人間がするタスクは2つで 「意思決定」と「確認」となり、主導者ではなく監督的役割にシフトさせていく必要があると考えています。人間がやることは、「AIに最初インプットさせる情報・方向性の決定」、「AIが出す選択肢の中からの決定」、「AIが出すアウトプットの最終確認」といった、ネクストアクションに繋げるための決定と確認になります。具体的には下記のようなものが人間が行うものに該当すると思っています。
- ビジネス要件の概略記入
- AIによるアウトプット生成過程での質問回答(意思決定)
- AI出力物の簡単な確認 / 修正
- 要件定義書(ビジネス/技術)の確認
- 検証環境デプロイ前の最終PR確認
では逆にAIはというと、もともと人間がやっていた主導者となり、skillやsubagentを起動させて、監督が求めるアウトプットを出力するためのリーダを担います。これは、単に出力物を出すという補助的な使い方ではなく、生成過程での軌道修正も含めて、AIが主導するということです。最終形態としては、ここに人間は関与しないのが完全理想状態です。私が今回実装したAIを主導者とした開発ワークフローについては次章で説明します。
次に後者についてです。これはやることは難しいかもしれませんが考え方は単純で、人間が監督的な役割になることでいくつかのタスクを並列することができるようになるため、そこで業務効率をあげようという話です。AIが主導して実装することで、2章の内容で説明したように人間の仕事はもしかしたら楽になるかもしれませんが、現状のAIでは単一タスクでの実装効率は、多くの場合むしろ低下します。これは、実装するためのコンテキストをAIはあまり知らないため過去の実装内容だったり、ドキュメントだったりを調査するところからAIは開始し、実装計画をたて、ビジネス要件との整合性を確認して軌道修正し … のようにAIにやらせることでその過程が多くなってしまうため、1つ1つは人間より早いかもしれませんが、合計すると単純な実装ほど実装効率は悪くなっていきます。そのため、
- いくつかの実装タスクを並列的に監督する
- 会議中に実装させる
- ランチ行っている間に実装させる
…というように、人間が別のことで動いている前提 が効率をあげるために必須になってきます。
もしかしたら今後のAI技術の進歩でまるでコンパイラでコードをコンパイルする感覚で実装したいものが実装できるような社会になるかもしれません。しかし、そのような時代になったとしても、AIがあるということに胡座をかかず、人間は監督としてAIを動かし、空いている時間で別のタスク・用事をこなすというAI活用スキルとしてずっと必要になると考えています。
4. AI駆動開発ワークフロー
私たちの開発フローの全体像について
前章で「AIを主導者、人間を監督」にするという話をしました。では実際に、私たちはどのような開発フローを構築したのでしょうか?
まず、AI導入前後の変化を端的に示します。
[AI導入前]
- 人間がバックログに積まれたIssueを読み、具体の要件を頭の中で整理
- → 特に影響範囲が大きかったり実装コストが高いものだったりはDesign Docに詳細をまとめる
- Claude Codeに「〇〇を実装して」と会話ベースで依頼
- 出力が微妙なら修正を指示して…(N回ループ)
- 人間がPRを作成し、人間がレビュー
[AI導入後(現在)]
- 人間はIssueの概要として要件の概略を書くだけ(曖昧表現でOK)
- AIが要件深掘り → 技術設計 → タスク分割 → 実装 → レビューまでを主導
- 人間は各フェーズの「確認」と「意思決定」のみ
このフローを支えているのが、SkillとSubAgentという2つの仕組みです。Claude Codeを使ったことがある方なら、CLAUDE.mdやカスタムスラッシュコマンドはご存知かもしれません。私たちはその先にある、AIがAIを起動・管理し、オーケストレーションする構造を構築しました。
- Skill: AIがもつ専門性もしくは従うべき振る舞いを定義。「どの順番で何をすべきか」「品質基準は何点以上か」「失敗したらどうするか」を明文化したもの。
- SubAgent: 特定の領域に特化した専門AIエージェント。Go実装担当、TypeScript実装担当、技術レビュー担当…など、人間のチームメンバーのように役割分担をしたもの。Skillを利用することも可能。
メインエージェントがSkillを用いてオーケストレーター(指揮者)としてSubAgentを起動・制御する構造になっており、これらを組み合わせることで「要件定義 → 技術設計 → タスク分割 → 実装 → レビュー」という開発フロー全体を自動化しています。以下、各フローを順番に解説していきます。
開発フロー1: ビジネス要件詳細の生成
すべての開発は「何を作るか」を明確にするところから始まります。従来であれば、エンジニアがIssueを読み解き、要件を整理し、設計を考え…という作業が必要でした。私たちのフローでは、この最初の一歩をAIに任せるところからスタートさせます。
私たちのプロダクトではバックログをLinearで管理しており、LinearのIssueを起点に実装を行います。そして、このフローで人間がやるのは、Linearに以下のテンプレートで要件の概略を記入することだけです。
# [機能名]
## オーナー
<!-- 誰がこの機能に責任を持つのかを記載 -->
@名前
## 背景
<!-- 1-3文で課題と目的を記述 -->
## やりたいこと
| 機能概要 | 優先度(Must/Should/Could) | 備考 |
|----------|---------------------------|------|
## やらないこと
| 機能概要 | 除外理由 |
|----------|----------|
## 誰が使うか
<!-- 主要ユーザー -->
## As Is と To Be
As Is: <!-- 1-3文で現状を記述 -->
To Be: <!-- 1-3文で目指すべき状態を記述 -->
## 受け入れテスト項目
| テストID | シナリオ | Given(前提) | When(操作) | Then(結果) | 優先度 |
|----------|---------|--------------|-------------|-------------|--------|
| AC-001 | 正常系:〇〇 | ... | ... | ... | Must |
| AC-002 | 異常系:〇〇 | ... | ... | ... | Must |
## 制約・前提条件
<!-- あれば -->
このテンプレートは「完璧に埋める」必要はありません。背景・やりたいこと・As Is/To Be あたりを数行書けば、AIが残りを深掘りしてくれます。受け入れテスト項目も、書けるところだけ書いておけば、AIが網羅的に補完します。
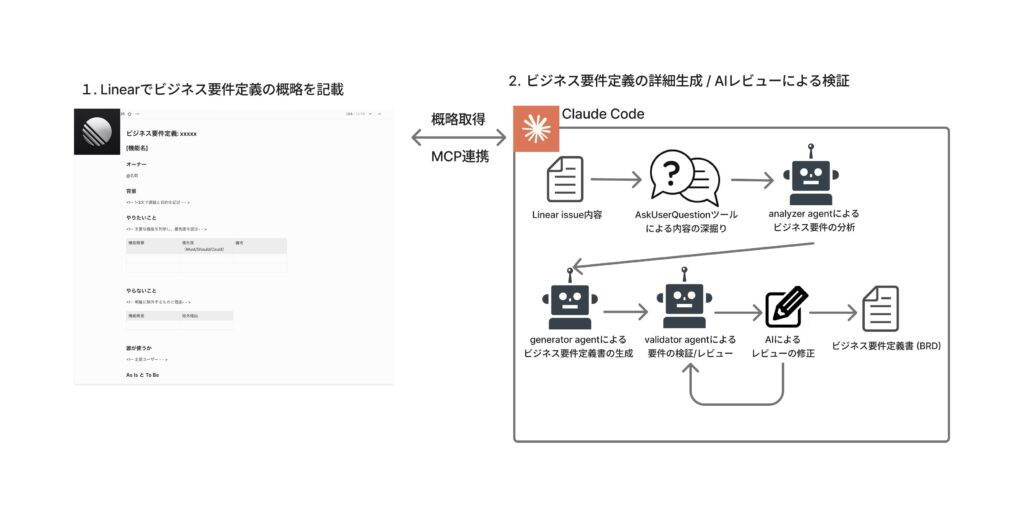
このLinear Issueを起点に、AIが以下のステップでビジネス要件定義書(BRD)を生成します。
- Linear Issue取得: MCP連携でIssueの内容を自動取得
- 分析・深掘り: analyzer agentが要件を分析し、曖昧な点を人間に質問
- BRD生成: generator agentが分析結果から要件定義書を生成
- 品質検証: validator agentがスコアリングし、基準未満なら自動修復
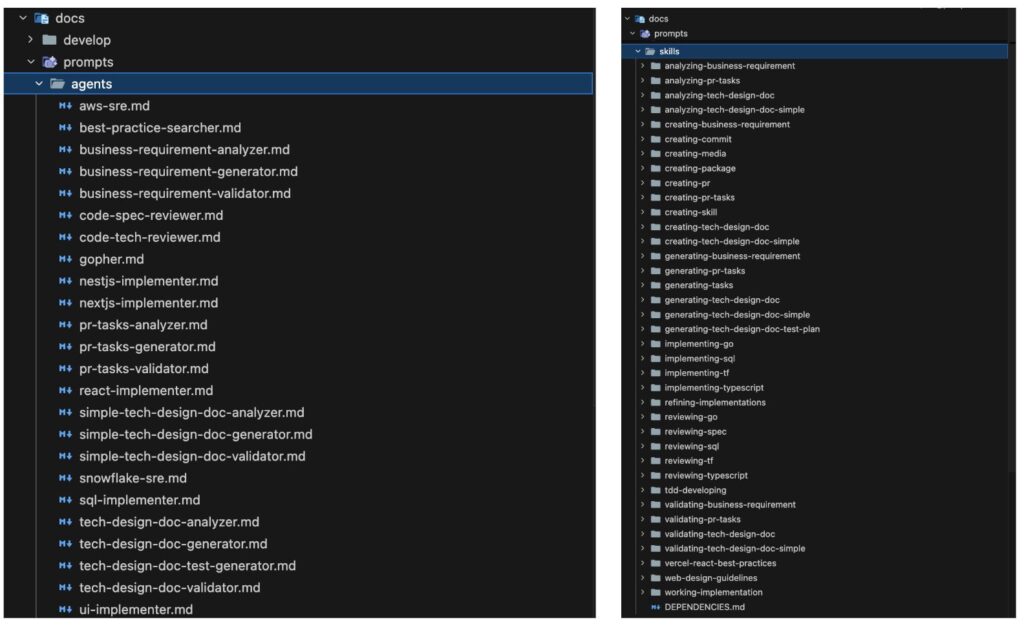
Skill・SubAgentの構成
このフローでは、1つのオーケストレーターSkillが3つの専門SubAgentを順次起動します。
Skill: creating-business-requirement(オーケストレーター) │ ├─ 1. SubAgent: business-requirement-analyzer │ 役割: Linear Issueの取得、要件の曖昧さ検出、質問ループ │ 出力: analysis_result.md(分析結果) │ ├─ 2. SubAgent: business-requirement-generator │ 役割: 分析結果からBRD生成、ユーザーレビュー │ 出力: business_requirements_definition.md(BRD) │ └─ 3. SubAgent: business-requirement-validator 役割: 10観点でスコアリング、80点未満なら自動修復(最大3回) 出力: validation_report.md(検証レポート)
「なぜ1つのAgentで全部やらせないのか?」と思う方もいるかもしれません。理由はコンテキスト分離です。1つのエージェントに全てやらせるとコンテキストが膨張してパフォーマンスが落ちます。専門エージェントに分割することで出力品質が安定し、途中で失敗しても該当フェーズだけやり直せます。
質問ループ — AskUserQuestionでAIが「聞いてくる」仕組み
analyzer agentの最大の特徴は質問ループです。これを実現しているのがClaude CodeのAskUserQuestionツールで、AIが処理の途中で人間に選択肢付きの質問を投げかけることができます。
analyzer agentは要件の曖昧な部分を検出すると、このツールで人間に質問を投げてきます。「このエッジケースの挙動はどうしますか?(A: エラーを返す / B: デフォルト値で処理)」「優先度が未指定の項目があります」「スコープ外とする機能はありますか?」 といったように、 不明点がなくなるまでループが継続します。
このAskUserQuestionツールの存在が、私たちのフローの根幹を支えています。AIは「言われたことをやる」だけでなく、「足りないことを聞いてくる」のです。人間がLinearに書いた概略(曖昧な状態)を、この質問ループを通じて詳細な仕様レベルまで詰めていきます。人間が「後で考えよう」と先送りしがちな部分を、AIが容赦なく突いてくるので、結果として網羅的で具体的な要件定義書が生成されます。
Linearで何を詰めるべきか — 「概要」から「仕様」へ
テンプレートは「完璧に埋めなくてよい」と書きましたが、以下の4点は意識的に詰めておくと後工程の品質が大きく変わります。
- やりたいこと / やらないこと: Must/Should/Couldの優先度を必ず記入し、曖昧な表現を排除。Scope / Out of Scopeを明確にしておくことで、AIが「親切心」でスコープを広げてしまうのを防ぐ
- 受け入れテスト項目: Given-When-Then形式で正常系・異常系・境界値を網羅。タスクの完了条件はここで確定させる
- As Is / To Be: 「現状:手動でCSVアップロード → 目標:APIで自動連携」のように差分が明確なレベルで記述
BRDはこの後のすべてのフェーズの入力データです。特に受け入れテスト項目はBRD → Design Doc → タスクファイル → TDD実装まで一気通貫で引き継がれるため、ここでの具体性がフロー全体の品質を左右します。最初の10分で要件を詰めることが、後の作業での手戻りを防ぎます。
このフローでの効果
要件整理にかかる人間の実作業が数時間 → 約10〜20分(質問回答+確認のみ)に短縮。要件の網羅性・具体性は人間だけで書くより向上し、フロー全体の手戻りが激減しました。
開発フロー2: 技術要件の生成 ~ PR粒度でのタスク分割
ビジネス要件が固まったら、次は「どう作るか」のフェーズです。ここでは、AIが実際のコードベースを読み込んだ上で技術設計を行い、さらにPR粒度の実装タスクに分割するところまで自動で進みます。
Design Doc生成のステップ
- BRD解析 + コードベース分析(既存コードの調査・影響範囲特定)
- モジュール別テスト計画の生成(TDD前提)
- Design Doc生成(Mermaid図を含むアーキテクチャ設計)
- 品質検証(ビジネス要件充足・テスト項目・技術要件を重点レビュー)
PR粒度タスク分割のステップ
- Design DocのTODOセクション解析・依存関係分析
- モジュール単位でPRタスク生成(Backend / Frontend等) // タスク分解粒度は調整可能にしている
- 品質検証 → 検証PASS後にLinear sub-issue自動作成
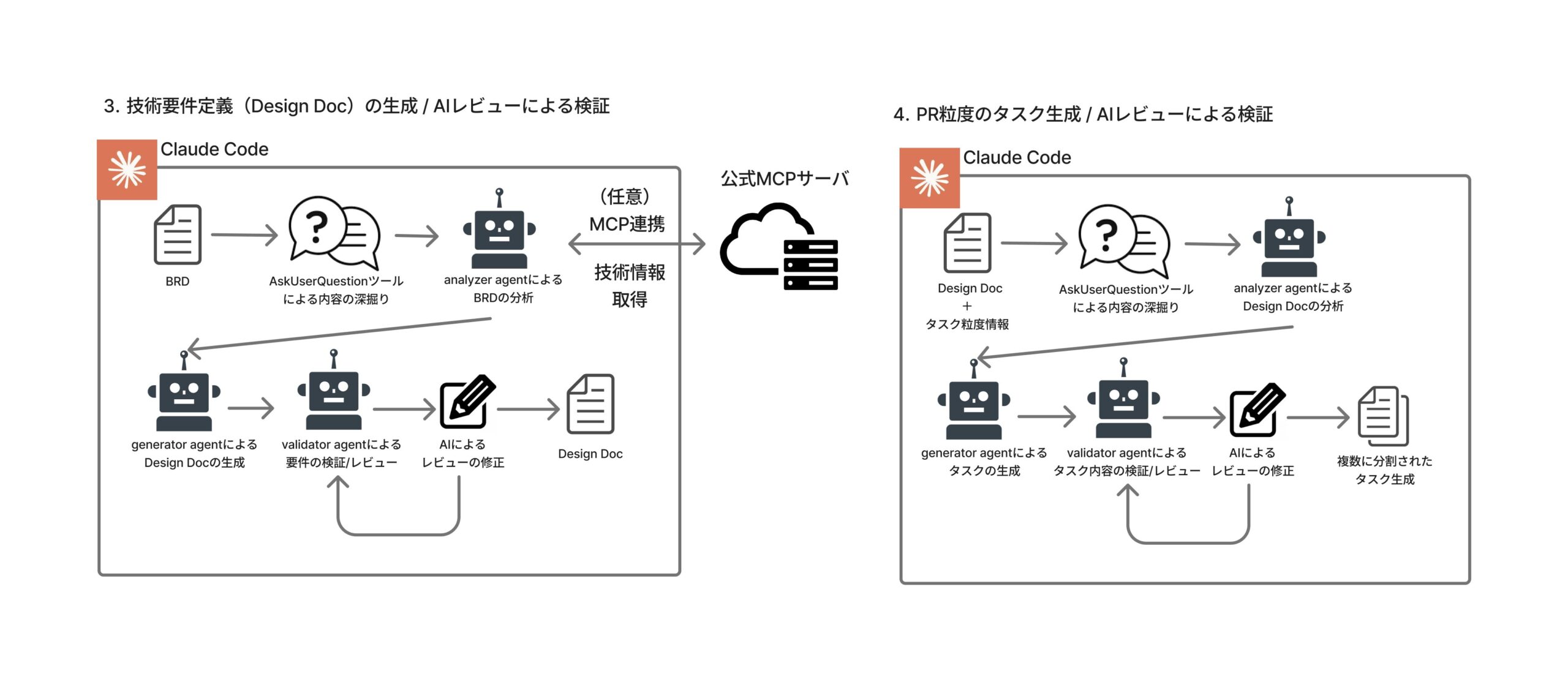
Skill・SubAgentの構成
このフェーズでは合計7つのSubAgentが動きます。Design Doc生成で4つ、タスク分割で3つです。
Skill: creating-tech-design-doc(オーケストレータースキル) │ ├─ 1. SubAgent: tech-design-doc-analyzer │ 役割: BRD解析 + コードベース分析 + 技術スタック特定 │ 特徴: リポジトリの実コードを読み込んで既存パターンを把握 │ ├─ 2. SubAgent: tech-design-doc-test-generator │ 役割: 影響モジュール別のTDDテスト計画を作成 │ ├─ 3. SubAgent: tech-design-doc-generator │ 役割: 分析結果 + テスト計画から Design Doc を生成 │ └─ 4. SubAgent: tech-design-doc-validator 役割: 10観点スコアリング + BRDとの整合性チェック + 自動修復 Skill: creating-pr-tasks(オーケストレータースキル) │ ├─ 1. SubAgent: pr-tasks-analyzer → Design Doc解析・依存関係分析 ├─ 2. SubAgent: pr-tasks-generator → タスクファイル生成 └─ 3. SubAgent: pr-tasks-validator → 9観点スコアリング + Linear sub-issue作成
コードベース分析 — AIが「コードを読んで設計する」
このフローで最も強力なのは、AIが既存のコードベースを実際に読み込んだ上で設計を行う点です。analyzer agentはリポジトリ内のコードを走査し、既存のアーキテクチャパターン・使用ライブラリ・命名規則を理解してから設計します。人間のエンジニアが「今のコードがどうなっているか」を調べてから設計するのと同じことを、AIが自動でやってくれるわけです。
タスクの自己完結性 — ファイルをインターフェースにする
PR粒度のタスク分割で最も重視したのは自己完結性です。各タスクファイルには、タスク概要・As is / To be・スキーマ定義・API仕様・テスト項目(Given-When-Then全文)・依存関係がすべて含まれます。Design Docを参照しなくても実装に着手できる状態です。
この「ファイルをインターフェースにする」という設計思想は、こちらの記事の考え方を参考にしています。エージェント間の連携を会話ではなくファイルの入出力で行うことで、各フェーズが疎結合になり、途中からのやり直しや並列実行が容易になります。
なぜここまで情報を詰め込むのか?次のフロー(実装フェーズ)で複数のタスクを別々のAIセッションが並列実行するからです。タスク間のコンテキスト依存をゼロにすることで、並列実装が成立します。
このフローでの効果
AIがコードベースを分析した上で設計するため、既存コードとの整合性が担保されます。またタスクの自己完結性により、並列実装がスムーズに回るようになります。
開発フロー3: ローカルでの実装 / レビューフロー
では、いよいよ実装フェーズです。ここが私たちのフローで最もエージェントが活躍するパートで、タスクファイルとDesign Docを入力に、AIがTDD(テスト駆動開発)で実装し、CIを通し、コードレビューまでを自動で完走します。
- 言語判定・エージェント選択(Go / Next.js / NestJS / Terraform等を自動判定)
- TDD実装(RED→GREEN→REFACTOR)
- CI実行(ローカルでCIが通るまで自動修正)
- コード簡素化(code-simplifier agentの起動 → 再CI)
- Tech Review + Spec Review(レビューエージェントの並列実行)
- 指摘対応ループ(両方80点以上かつCritical/Highレベルのレビューがなくなるまで修正→再レビュー)
- PR作成
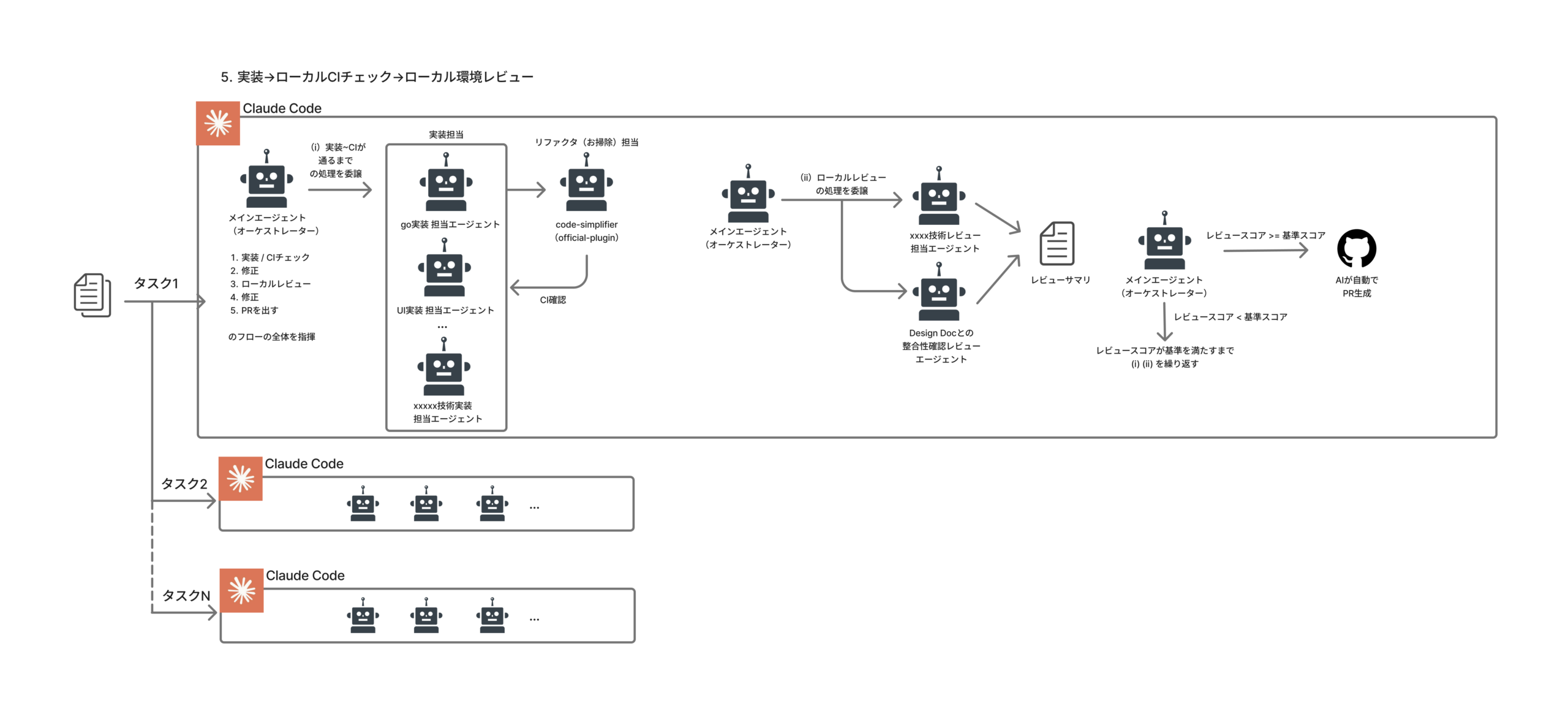
Skill・SubAgentの構成
このフローの心臓部である working-implementation Skillは、最も多くのSubAgentを統括するオーケストレーターSkillです。まさに「開発チームのリーダー」のような存在で、タスク内容に応じて適切な専門エージェントを選び、起動し、結果を評価し、必要なら修正を指示します。
Skill: working-implementation(オーケストレーター) │ ├─ 【PHASE 1: 実装】技術スタックに応じた実装SubAgentを自動選択 │ ├─ gopher (Go実装担当) │ ├─ nextjs-implementer (Next.js担当) │ ├─ nestjs-implementer (NestJS担当) │ ├─ react-implementer (React担当) │ ├─ aws-sre (Terraform/AWS担当) │ ├─ snowflake-sre (Terraform/Snowflake担当) │ ├─ sql-implementer (Snowflake SQL担当) │ └─ ui-implementer (UI実装担当) │ ├─ 【PHASE 1.5: リファクタ】CI成功後に必ず実行 │ └─ code-simplifier (コード簡素化担当) │ └─ 【PHASE 2: レビュー】2つのレビューを並列実行 ├─ code-tech-reviewer → 8観点でスコアリング └─ code-spec-reviewer → Design Docとの整合性を6観点で評価
開発原則をルール・スキルで定義する
AIに「いいコードを書け」と言っても、「いいコード」の基準は人によって異なります。私たちはこの曖昧さを排除するために、開発原則とその優先度をルールファイルやスキル定義に明文化しています。
# 開発原則の優先度体系(rules/cording.md より) P0(必須): オッカムの剃刀 — 必要なしに存在を増やさない P1(デフォルト): リーダブルコード、DRY原則 P2(推奨): プログレッシブエンハンスメント P3(状況依存): TDD/ベイビーステップ、デメテルの法則 # テストケース生成にはペアワイズ法を採用 # → 全組み合わせ(N×M)ではなく、2因子間の組み合わせで効率的にカバー
これらの原則がSkillやSubAgentの中で参照されることで、AIが「シンプルさを最優先にしつつ、読みやすいコードを書く」という判断を自律的に行えるようになります。
リファクタフェーズ — code-simplifierの重要性
実装フローの中で見落としがちですが、PHASE 1.5のリファクタフェーズは品質維持の要です。CIが通った後、code-simplifier agentが必ず実行されます。
code-simplifierは「機能を一切変えずに、コードの書き方だけを改善する」専門エージェントです。核となる原則は:
- 機能の保全: コードが何をするかは変えない。どうやるかだけを改善する
- 明確さの追求: 不要な複雑さ・冗長なコード・過度な抽象化を排除し、可読性を向上
- バランスの維持: 行数を減らすことよりも読みやすさを優先。過度な簡素化はしない
AIが生成するコードは、機能的に正しくても冗長だったり、ネストが深かったりすることがあります。code-simplifierがこれを上記の開発原則に基づいて整理することで、レビューに回る前にコード品質のベースラインが担保されます。
技術面 × ビジネス面の二軸レビュー
PHASE 2のレビューでは、技術レビュー(Tech Review)と仕様レビュー(Spec Review)を並列実行します。
- Tech Review(code-tech-reviewer): Go / TypeScript / Terraform / SQL等、言語ごとの専門レビュー。8観点でスコアリング
- Spec Review(code-spec-reviewer): Design Docとタスクファイルを根拠に、ビジネス要件に沿った実装ができているかを6観点で評価
両方で80点以上かつCritical/Highの指摘なしがクリア条件です。ここで重要なのは、BRD生成やDesign Doc生成と同様にゴールデンファイル(理想的な出力の参照ファイル)を用意している点です。レビュー時にゴールデンファイルと比較することで、正解/不正解を厳密にチェックでき、レビューの一貫性が保たれます。
# working-implementation Skill のパラメータ
MAX_IMPL_ITERATIONS: 4 # 実装ループ最大回数
MAX_REVIEW_ITERATIONS: 3 # レビューループ最大回数
TECH_QUALITY_THRESHOLD: 80 # 技術レビュー最低スコア
SPEC_QUALITY_THRESHOLD: 80 # 仕様レビュー最低スコア条件を満たさない場合、オーケストレーターが指摘を優先度順にソートし、適切な実装SubAgentに修正を委譲 → code-simplifier → CI → 再レビューという自動修正ループが回ります。「実装して終わり」ではなく、「レビューが通るまで自分で直す」ところまでAIがやります。
並列実装 — 人間は実行して最終出力を待つだけ
各タスクファイルが自己完結しているため、git worktreeを使って複数タスクを並列実行できます。
# epic ブランチをベースに、タスクごとにworktreeを作成
git worktree add ../task-1 -b feature/task-1 epic/CA-1234
git worktree add ../task-2 -b feature/task-2 epic/CA-1234
# 各worktreeで別々のClaude Codeセッションが実装〜レビューまで実行 3章で述べた「人間が別の作業をしている前提」をまさに実現した形です。人間はタスクを実行した後、会議に出たり別の意思決定をしたり、もっと言えばランチに行っている間に、AIが自律的に実装〜レビューまで完走します。
なお、この並列実装の考え方は、Claude Codeの開発者であるBoris Cherny氏が公開した「Claude Codeを最大限活用するための10のtips」とも共通する部分が多く、git worktreeによる並列作業、CLAUDE.mdへの投資、カスタムスキル、サブエージェント活用といったプラクティスを私たちも実践しています。興味のある方はぜひ原文を読んでみてください。
このフローでの効果
1タスクあたりの人間の介入がほぼゼロに。3〜4タスクを同時に走らせ、完了通知を待つスタイルがこのフローにより実現化できました。また、AI活用前と比較して、修復を何回も依頼するということがなくなりAI自身が自己修復を行えるようになったことでその分の人間の作業もなくなりました。自己修復においては私は特に言語特有のLinterだったり、自分で定義可能なカスタムLintを的確に利用することで、タスク完了後の確認事項も少なくなると感じています。
開発フロー4: Github上でのレビューと修正フロー
ローカルでの実装・レビューが完了してPRがGitHubにpushされると、今度はGitHub Actions上でAIコードレビューが自動実行されます。ここまでが「ローカルでAIが頑張る」フェーズだったのに対し、このフローはCI/CDパイプラインの中でAIが動くフェーズです。私たちのチームではGithub上ではローカルで利用していたようなSkill, SubAgentを利用するのですが、Claude Codeではなく、Codexを利用しています。これは別のエージェントを利用することでより多角的視点からのレビューを得るためです。
レビューフェーズ
- 変更ファイルからGo / TypeScript / Terraform / SQL変更を自動検出
- 検出された言語ごとに専門レビューを並列実行 + 仕様適合性レビュー
- 全スコアを集約 → 全て80点以上なら自動Approve
- 修正すべき項目をfix_suggestionsとしてコメント


自動修正フェーズ
- /fix-codex-review をfix_suggestionsのうちの修正したい項目IDと一緒にPR上でコメント
- コメントをトリガーにGithub Actionsを起動
- Codex CLIで自動修正 → commit & push
- 修正ワークフローの中でレビューワークフローを起動して再レビュー
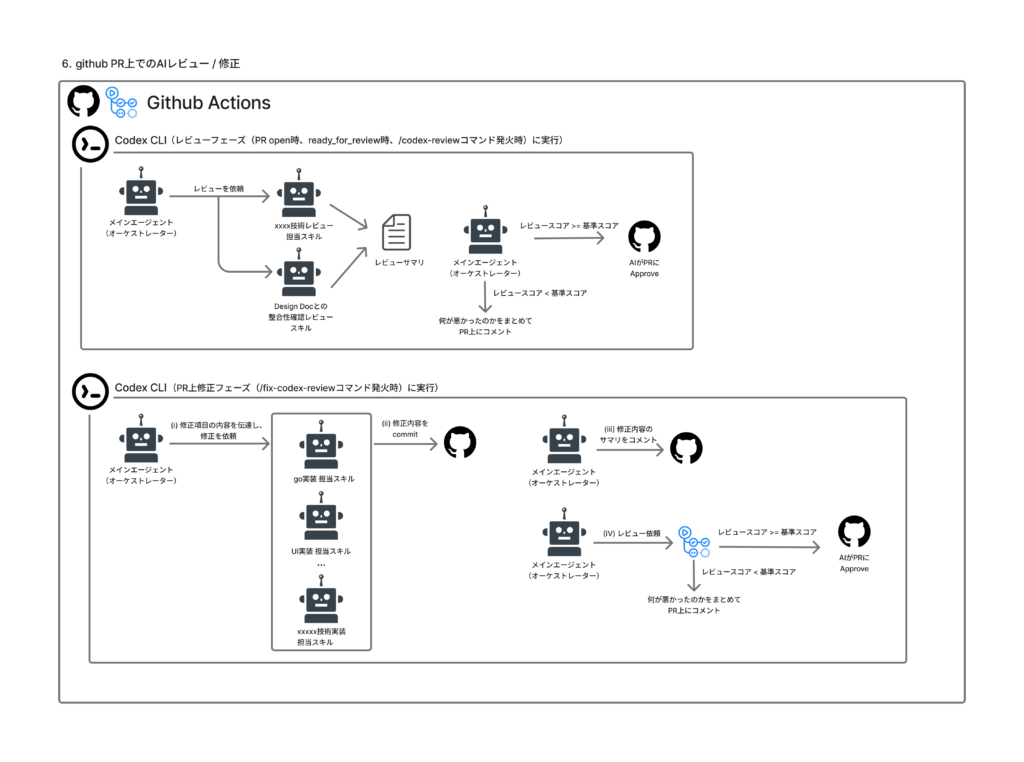
変更検出と並列レビュー
orchestrator workflowの核心は、PRの変更ファイルパスからレビュー対象の言語を自動検出し、必要なレビューだけを並列実行する点です。
# orchestrator.yml(簡略化)
detect-changes:
steps:
- run: |
CHANGED_FILES=$(gh pr diff "$PR_NUMBER" --name-only)
echo "$CHANGED_FILES" | grep -q "^app/" && echo "has_go_changes=true"
echo "$CHANGED_FILES" | grep -qE "^(wall|console)/" && echo "has_ts_changes=true"
review-go:
if: needs.detect-changes.outputs.has_go_changes == 'true'
# Go専門のレビューエージェントを実行
review-typescript:
if: needs.detect-changes.outputs.has_ts_changes == 'true'
# TypeScript専門のレビューエージェントを実行
review-spec:
# 仕様適合性レビューは常に実行(Design Docとの整合性チェック)スコア集約と自動Approve
全レビュー完了後、スコアを集約して80点以上(またはconclusionがapprove)ならgh pr review --approveで自動的にPRをApproveします。
# aggregate-results(簡略化)
- name: Auto-approve if all passed
run: |
if [ "$ALL_PASSED" = "true" ]; then
gh pr review "$PR_NUMBER" --approve \
--body "全てのレビューが80点以上で完了。自動承認します。"
fi自動修正ループ
レビューでApproveにならなかった場合、PRコメントで /fix-codex-review と打つだけで自動修正ワークフローが起動します。fix_suggestionsをもとにCodex CLIが修正 → commit & push → レビューワークフローを再トリガーする完全自動ループです。
# fix-codex-review.yml(簡略化)
on:
issue_comment:
types: [created] # /fix-codex-review で発火
auto-fix:
steps:
- name: Run auto-fix # レビュー指摘をもとにCodex CLIが修正
- name: Commit and push # 自動commit & push
re-trigger-orchestrator: # 修正後にレビューを再トリガー
steps:
- run: gh workflow run orchestrator.yml -f pr_number="$PR_NUMBER"ブランチ戦略
私たちはブランチ戦略としてタスクごとのfeatureブランチからepicブランチに向けたPRを作成するようにしており、featureブランチではAI ApproveがついたらマージをOKしています。epicブランチではfeatureブランチがマージされるごとに再度レビューが走ります。そして、すべてのfeatureブランチがepicブランチにマージされた段階で、AIがApproveを出して初めて人間がレビューするフローにしています。こうすることにより、各featureブランチではAIによるレビューは完了している、つまり80点以上でクリティカルな問題はない状態ができており、その集まりとなったepicブランチで最終AI Approveがつくことで全体の要件との整合性もとれる状態を作ることができます。
もっというとブランチごとのテスト環境でのE2Eテスト戦略も組み合わせるとより良いと思っておりますが、まだそれは現在構築段階です。(現状はCIでのユニット・インテグレーション・E2Eテストのみ)
このフローでの効果
人間がPRを確認する頃にはAI Approveが付いている状態で、人間はビジネスロジックの正しさだけをチェックすれば済むようになりました。
ここまで構築してみての成果
この開発基盤を12月初旬から約1ヶ月半かけて構築・運用してきた結果、以下のような成果が得られました。
- Skill 37個、SubAgent 24個を用途・領域別に整備
- 要件定義〜PR作成まで、一連のフローをコマンド1つで起動可能に
- エンジニア2人体制でも、以前の6人体制と同等以上のアウトプット量を維持
- AIレビューによるPR品質の向上(レビュー待ち時間の削減、指摘の網羅性向上)
- 人間の作業が「意思決定」と「確認」に集約され、並列タスクの監督が可能に
ただし、この仕組みの構築自体にかなりの工数をかけているのも事実です。「AIに働いてもらうための投資」は小さくありませんが、一度構築すれば繰り返し使えるため、中長期では確実にペイすると考えています。
これからの将来像
現在の開発フローは要件定義〜PRレビューまでをカバーしていますが、まだ自動化できていない領域があります。今後は以下の拡張を進めていきます。
- E2Eテスト環境の構築: ユニットテストだけでなく、E2Eレベルでの動作保証を自動化する
- リリース対象の自動判定: PRの変更内容からリリース対象モジュールを自動検出し、リリース計画を生成する
- リリース自動化: 検証環境へのデプロイ〜本番リリースまでをAIが主導するワークフローの構築
- エラー監視 → 自動修正PR作成: リリース中/リリース後のエラーログを監視し、問題を検出したらAIが原因分析〜修正PR作成まで自動で行う
- 活用方法の汎用化 / 他チームへの知見共有: 自チーム特化のSkill/SubAgentを汎用化し、社内の他チームでも活用できる形に整備する
最終的には「Linearにissueを書いたら、本番リリースまでAIが主導する」という世界を目指しています。
5. 開発でAIをより活用するためには … !!
ここまで、AIを主導者にした開発フローの全体像を解説してきました。では、このフローをさらに “ワークさせる” ために何が必要なのか?僕が日々の運用で感じている2つの課題について深掘りしていきます。
課題1: 暗黙知の壁 — AIはコンテキストを読み取ってくれない
AIは「書かれていること」だけを信じて忠実に動きます。 人間同士なら暗黙的に共有している知識——パートナーごとのビジネスルール、既存コードに埋まった制約、チーム固有の「いいコード」の基準——これらが明文化されていないと、AIは存在しないものとして扱います。
特に危険なのが仕様の「穴」がそのまま実装されるケースです。例えば「ユーザーにポイントを付与する」とだけ書いた仕様書に対して、人間なら「A社は上限500ポイントだったよな」と加味しますが、AIは汎用的な実装をします。AIが忠実だからこそ、仕様の穴がそのまま本番コードに反映される。 analyzer agentの質問ループはこの安全網の一つですが、そもそも仕様に存在しない情報は質問のしようがありません。
そこで僕たちは、暗黙知を以下の5層の階層構造でコードベースに埋め込んでいます。
| 層 | 役割 | 具体例 |
|---|---|---|
| 1. プロダクト文脈 | 何を作っているか(ドメインルール、ビジネス制約) | プロダクト内容をまとめたproduct.md |
| 2. コーディング規約 | どう書くか(優先度付きの原則) | 全体のコーディングルールや開発原則をまとめた cording.md |
| 3. 品質基準 | 何が「良い」か(自己評価の基準) | Golden Files(BRD, Design Doc等の理想例) |
| 4. リファレンス | 具体的にどうやるか(手順・パターン集) | 実装・テストパターンをモジュールごとのrules/ に定義 |
| 5. ワークフロー | いつ何を適用するか | Skill定義, SubAgent定義 |
AIはこの階層をトップダウンで辿ることで、人間の新しいチームメンバーと同じように情報を理解できます。日々の開発で「あ、この情報はAIが知らないな」と気づくたびにドキュメントを追加する——この「暗黙知の発見 → 形式知への変換」のサイクルを回し続けることが、AI活用度を上げる最も確実な方法だと考えています。
課題2: 人間の限界 — AIのアウトプット量に追いつけない
もう一つの課題は、AIの出力量に人間の認知が追いつかなくなることです。3〜4タスクの並列監督はできても、10タスクが同時に走ったら?特にコードレビューで顕著で、並列実装による大量のPRを2人体制で全て読むのは物理的に不可能です。
だからこそフロー3・4で紹介した80点自動Approveが効いてきます。AIレビューで問題なしと判定されたPRは自動承認し、人間は「本当に人間の判断が必要なもの」だけを見る。加えて、過去の失敗事例をドキュメントに蓄積することで、新しいAIセッションが同じミスを繰り返すリスクも下げています。
最終的に目指すのは、AIが「このPRのこの3行だけ人間の判断が必要です。理由はこのトレードオフです」とピンポイントで提示する世界です。そのために必要な次のステップは以下です。
| 施策 | 内容 |
|---|---|
| 品質ゲートの多層化 | レビュースコア + E2Eテスト + セキュリティスキャンの組み合わせ |
| 異常検知 | 「いつもと異なるパターン」を検出して人間にアラート |
| ナレッジの自動蓄積 | CI失敗やレビュー傾向から自動的にルールを学習・更新 |
結局のところ、AIをより活用するためには「人間側の変化」が必要です。暗黙知をドキュメント化・コードに落とし込むようにする文化、レビューを自動化に任せる信頼、失敗を仕組みで防ぐ発想 … 等、これらは技術の話というよりチームの開発文化の話です。この仕組みさえ整えれば、AIの進化をそのまま自分たちの開発速度に変換できるようになると思います。
6. さいごに
今回は、私たちが直面した課題から実現したAI駆動開発基盤の構築の話や、それをワークさせるための活用術についてお話ししました。AIの性能や機能、またそれを活躍させるための仕組みが日々登場していく中で、今ベストプラクティスだと思われている内容はいつの間にか廃れているのなんて状況がざらな時代になっているでしょう。
僕自身まだまだ程遠い話ではありますが「AIの変化には人間も変化で対応」これが日常的にできるようになってこそ、AI時代を生き抜けるエンジニアになると僕は思っています。そうなるためにも、この記事が少しでもAIを活用するために役立ってくれると嬉しいです。
また、将来像の部分でお話ししましたが、自分たちのAI活用もまだ止めるつもりはありません。よりAIを活用できるように日々キャッチアップと検証を行っていこうと思っています。この構築の続きが検証・実装できたらまた記事を書こうと思うので、その際はまた読んでいただけると嬉しいです。
長文となってしまいましたが、最後まで読んでいただき、ありがとうございました!