
はじめに
こんにちは、26卒内定者でバックエンドエンジニアの相馬大和です!
本記事では、内定者バイト期間中の、Amebaブログのストレージ移行と、それに伴う周辺システム刷新の取り組みをご紹介します。
背景
Amebaブログは様々なコンポーネントから構成されており、その多くでDynamoDBを利用しています。
DynamoDBはスケーラビリティに優れたNoSQLデータベースであり、かつてのAmebaブログの要件には適していました。しかし、サービスの成長とともにデータの参照パターンが多様化した結果、現在の運用においてはRDBの方が適しているという判断に至りました。
その背景として、まず運用負荷の観点があります。DynamoDBのスループット制御はWCU(Write Capacity Unit)によって管理されますが、障害復旧時のリトライ処理においてWCUの調整が難しく、運用負荷となっていました。
次に、データの参照パターンの多様化への対応です。ブログのデータは多方面で活用されることが多く、アクセスパターンが増えるたびにGSIの追加を検討する必要がありました。RDBであれば、こうした柔軟なクエリへの対応がより低コストで実現できます。
三つ目はコスト面です。現在のアクセス規模においては、Aurora MySQLの課金モデルの方がより費用対効果が高く、既存の月額約285ドルから約2ドルへの大幅なコスト削減が見込まれます。
これらを踏まえ、Amebaブログ全体としてDynamoDBからRDBへの移行が計画されており、その第一歩目として、ハッシュタグ記事ランキングを管理するストレージを移行しました。
内定者バイトで行ったこと
Amebaブログでは記事ごとにハッシュタグをつけることができ、ハッシュタグのランキングを閲覧することが可能です。
Amebaブログのハッシュタグ記事ページ
今回の内定者バイトでは、このハッシュタグ記事のランキングデータを管理するDynamoDBをMySQLに置き換えると同時に、DynamoDBに依存するリード系APIや、データを書き込むバッチ処理も再実装しました。
まず既存実装の流れをご紹介します。
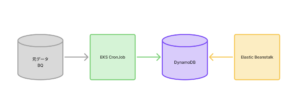
旧実装
DSC (Data Science Center)の方が管理してくださっている、BigQueryの元データを、Amebaブログ側のEKSのCronJobがstreamし、DynamoDBに書き込んでいます。そのDynamoDBを参照する、Goで書かれたAPIがElasticBeanstalkで動いており、ハッシュタグ記事ランキング関連のデータを返しています。
そして今回の新実装では、以下のような流れになります。
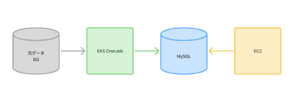
新実装
上記構成のように、ハッシュタグ記事ランキングのデータを管理するDynamoDBをMySQLに移行するためには、以下三つのタスクを行いました。
(ElasticBeanstalk → EC2の移行は後ほど解説します。)
- DynamoDBのデータ構造をもとに、RDB用のテーブルを設計する
- ハッシュタグ記事ランキングのデータをBigQueryからstreamし、MySQLに書き込むバッチを再実装し、EKSのCronjobで動かす
- 旧DynamoDBのテーブルを参照していたAPIをElasticBeanstalkからEC2に移行する
RDB用のデータモデル構築
まず最初に行ったのが、DynamoDBのデータ構造をもとに、RDB用のテーブルを設計し、構築することです。
DynamoDBでは、キーの検索効率を上げるために複数の属性を連結した複合文字列(例:ameba_entry_id_tag_name)をパーティションキーやソートキーにしていました。これはKey-Value的なアクセスには強い反面、データの正規化が崩れており、コードロジックが複雑化したり、非定型なクエリへの対応が困難でした。
MySQL移行にあたって、これらの複合キーを分解し、リレーショナルモデルとして適切に正規化した設計に刷新しました。
次にインデックスの再定義に関してです。GSIをもとに、RDBのインデックス設計を行いましたが、この対応でコスト面でメリットを享受できました。理由としては、DynamoDBのGSIは、メインテーブルへの書き込みのたびにGSI分の書き込みも独立して発生するため、インデックス数に比例してWCUを余分に消費する一方で、MySQLのセカンダリインデックスは、インデックス数に応じてコストが線形増加するような課金構造ではないためです。
最後にDB、テーブル構築に関しては、今回すでに利用されているRDSのクラスターの中に作成し、Batchでの書き込みはプライマリインスタンス、DBから読み込む際は、リードレプリカを参照するようにしました。
書き込みバッチの再実装
ハッシュタグ記事ランキングの元データはBigQueryに蓄積されており、ここから毎日1.5GBほどのデータを抽出し、MySQLへ反映させるバッチ処理の再実装を行いました。
BQからのstream処理では、1.5GBのデータを一度にメモリに載せると、アウトオブメモリでkillされてしまうため、Goの並列処理(ChannelとGoroutine)を利用して、「BigQueryからの読み出し」と「MySQLへの書き込み」をオーバーラップさせるパイプラインを構築しました。
func StreamHashtagEntryRankingFromBQ(ctx context.Context, bqClient *bigquery.Client) (<-chan *HashtagEntryRanking, <-chan error, error) {
err := WaitForTableActive(ctx, bqClient, "prj_hashtag_entry_ranking", "hashtag_ranking_similarity_normalized_pv")
if err != nil {
return nil, nil, fmt.Errorf("WaitForTableActive failed: %w", err)
}
q := bqClient.Query(HashtagEntryRankingListQuery)
job, err := q.Run(ctx)
if err != nil {
return nil, nil, fmt.Errorf("job run failed: %w", err)
}
status, err := job.Wait(ctx)
if err != nil {
return nil, nil, fmt.Errorf("job wait failed: %w", err)
}
if status.Err() != nil {
return nil, nil, fmt.Errorf("job execution error: %w", status.Err())
}
it, err := job.Read(ctx)
if err != nil {
return nil, nil, fmt.Errorf("job read failed: %w", err)
}
// 1ページあたり500行ずつ取得する
it.PageInfo().MaxSize = 500
// データを逐次的に返すチャネルを作成
outChan := make(chan *HashtagEntryRanking)
errChan := make(chan error, 1)
go func() {
defer close(outChan)
defer close(errChan)
for {
bqRanking := new(HashtagEntryRanking)
err := it.Next(bqRanking)
if errors.Is(err, iterator.Done) {
logger.Default().Info("Finished reading all BigQuery results")
break
}
if err != nil {
logger.Default().Error("Iterator Next failed", zap.Error(err))
errChan <- fmt.Errorf("it.Next: %w", err)
return
}
outChan <- bqRanking
}
}()
return outChan, errChan, nil
}
また、ハッシュタグ記事ランキングデータは直近5日間のデータのみを保管するという仕様があり、これまでは、DynamoDBのttlで自動削除していましたが、今回は、RDBに置き換えたため、バッチ処理のロジック側で対応しました。そして、一度に削除するデータ量が1.5GBほどで、一括削除するとCPU使用率が急上昇してしまうため、メトリクスを確認しながら、バッチサイズを調整し、逐次削除で対応しました。
ハッシュタグ記事ランキング取得APIの移行
CronJobのバッチ処理で書き込まれたハッシュタグ記事のランキングデータを、既存実装ではElasticBeanstalk上のAPIでクライアントに提供していましたが、ElasticBeanstalkを管理するawsアカウントは今後廃止する動きがあり、これらAPIも、Amebaブログのサブシステムが集まるEC2側に移行することが決まりました。
既存のDynamoDBに依存するハッシュタグ関連のAPIは全部で9個ほどありましたが、期間の都合上、今回は二つのAPIを移行しました。
実装に関しては、DynamoDBを利用したinfra層のロジックを理解した上で、Amebaブログで使われているbobというGoのORMを利用しましたが、従来のコードと比べると、シンプルかつ少ないコード量になることが実感できました。
下記はその中の一部関数です。
旧実装(DynamoDBから取得)
func (r *tagRankingRepositoryImplV2) listTagRankingEntriesByAmebaIDSimple(
ctx context.Context, dt string,
amebaID model.AmebaID,
limit int,
offsetRank *int,
offsetEntryID *model.EntryID,
offsetHashtag *model.HashtagID
) (es []blogtagRankingEntryV2, nextOffsetRank *int, nextOffsetEntryID *model.EntryID, nextOffsetHashtag *model.HashtagID, err error) {
key := fmt.Sprintf("%s_%s", amebaID.String(), dt)
var exclusiveStartKey map[string]types.AttributeValue
if offsetRank != nil && offsetEntryID != nil && offsetHashtag != nil {
exclusiveStartKey = map[string]types.AttributeValue{
"rank": &types.AttributeValueMemberN{
Value: fmt.Sprintf("%d", *offsetRank),
},
"ameba_id_dt": &types.AttributeValueMemberS{
Value: key,
},
"ameba_entry_id_tag_name": &types.AttributeValueMemberS{
Value: fmt.Sprintf("%s_%s_%s", amebaID.String(), offsetEntryID.String(), offsetHashtag.TagName()),
},
"dt": &types.AttributeValueMemberS{
Value: dt,
},
}
}
res, err := r.client.Query(ctx, &dynamodb.QueryInput{
TableName: &r.blogtagEntryRankingTable,
IndexName: aws.String("ameba_id_dt-rank-index"),
KeyConditionExpression: aws.String("ameba_id_dt = :ameba_id_dt"),
FilterExpression: aws.String("official_tag_flag = :official_tag_flag"),
ExpressionAttributeValues: map[string]types.AttributeValue{
":ameba_id_dt": &types.AttributeValueMemberS{
Value: key,
},
":official_tag_flag": &types.AttributeValueMemberN{
Value: "1",
},
},
Limit: aws.Int32(int32(limit)),
ScanIndexForward: aws.Bool(true),
ExclusiveStartKey: exclusiveStartKey,
})
if err != nil {
return nil, nil, nil, nil, fmt.Errorf("r.client.Query: %w", err)
}
if res.LastEvaluatedKey != nil {
lastEvaluatedKey := res.LastEvaluatedKey
var l blogtagRankingEntryV2
if err := attributevalue.UnmarshalMap(lastEvaluatedKey, &l); err != nil {
return nil, nil, nil, nil, fmt.Errorf("attributevalue.UnmarshalMap: %w", err)
}
nextOffsetRank = &l.Rank
eid := model.EntryID(l.EntryID())
nextOffsetEntryID = &eid
hid := model.NewHashtagID(l.TagName())
nextOffsetHashtag = &hid
}
var blogtagRankingEntries []blogtagRankingEntryV2
if err := attributevalue.UnmarshalListOfMaps(res.Items, &blogtagRankingEntries); err != nil {
return nil, nil, nil, nil, fmt.Errorf("attributevalue.UnmarshalListOfMaps: %w", err)
}
return blogtagRankingEntries, nextOffsetRank, nextOffsetEntryID, nextOffsetHashtag, nil
}
新実装(MySQLから取得)
func (r *hashtagEntryRankingRepositoryImpl) listTagRankingEntriesByAmebaIDSimple(
ctx context.Context,
dt civil.Date,
amebaID model.AmebaID,
limit int,
offsetRanking *int,
offsetEntryID *model.HashtagEntryID,
offsetHashtag *model.HashtagID,
) ([]hashtagdb.BlogHashtagEntryRanking, error) {
qb := mysql.Select(
sm.From(hashtagdb.BlogHashtagEntryRankings.Name()),
sm.Where(hashtagdb.BlogHashtagEntryRankings.Columns.AmebaID.EQ(mysql.Arg(amebaID.String()))),
sm.Where(hashtagdb.BlogHashtagEntryRankings.Columns.DT.EQ(mysql.Arg(dt.String()))),
sm.Where(hashtagdb.BlogHashtagEntryRankings.Columns.OfficialTagFlag.EQ(mysql.Arg(1))),
)
if offsetRanking != nil && offsetEntryID != nil && offsetHashtag != nil {
qb.Apply(sm.Where(mysql.Raw(
"(`rank`, entry_id, tag_name) > (?, ?, ?)",
mysql.Arg(*offsetRanking),
mysql.Arg(offsetEntryID.String()),
mysql.Arg(offsetHashtag.TagName()),
)))
}
qb.Apply(
sm.OrderBy(clause.OrderDef{
Expression: hashtagdb.BlogHashtagEntryRankings.Columns.Rank,
Direction: " ASC",
}),
sm.OrderBy(clause.OrderDef{
Expression: hashtagdb.BlogHashtagEntryRankings.Columns.EntryID,
Direction: " ASC",
}),
sm.OrderBy(clause.OrderDef{
Expression: hashtagdb.BlogHashtagEntryRankings.Columns.TagName,
Direction: " ASC",
}),
sm.Limit(int64(limit)),
)
rows, err := bob.All(ctx, r.replicaDBs.Next(), qb, scan.StructMapper[hashtagdb.BlogHashtagEntryRanking]())
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
return []hashtagdb.BlogHashtagEntryRanking{}, nil
}
return nil, fmt.Errorf("bob.All: %w", err)
}
return rows, nil
}
上記コードを比較すると、SQLでの実装が以下二つの観点で改善されている事がわかります。
キャッチアップコスト
SQLでの実装の方では、クエリの意図がコードから直接読み取れる一方で、DynamoDBはやや難解です。ExclusiveStartKey の組み立て方が暗黙的で、ameba_entry_id_tag_name というカラム名が amebaID_entryID_tagName の複合値であることはコードを読んでも分かりにくく、ScanIndexForward: true という引数がソート方向を制御していることも、DynamoDBを経験していないと理解が難しいはずです。
パフォーマンス
DynamoDB版の実装を追うと、コスト効率の観点で問題があった事がわかります。FilterExpressionはQueryがLimitで取得したアイテムに対して後段でフィルタする仕様であるため、official_tag_flag = 1に合致しないデータが多い場合、フィルタで弾かれたアイテム分のRead Capacityも消費されます。さらに、limitに達するまで再帰的にQueryを繰り返す実装になっているため、フィルタ条件に合致するデータが少ないほど余分なRead Capacity消費が積み重なる構造でした。
MySQLに置き換えたことにより、WHERE句とインデックスによって該当レコードのみを正確に読み取れるようになり、不要なレコードの読み取りが排除されました。これによりRead Capacityの無駄な消費がなくなり、コスト効率が改善されました。
まとめ
この記事では、Amebaブログのハッシュタグ記事ランキングのストレージ移行とシステム刷新について紹介しました。今回の刷新により、インフラコストの削減と運用効率化が期待されます。