
はじめに
こんにちは!愛知工業大学大学院修士1年の杉原充稀です。
2026年1月の約1ヶ月間、「CA Tech JOB」という就業型インターンシップに参加させていただきました。
今回参加させていただいたチームは、タップルの SRE チームで、タップルのサービス群の設計・構築・運用を担当しています。本記事では、私がインターン中に取り組んだタップルにおけるインフラリソースの最適化手法と、そこから得た学びについてご紹介します。
背景・目的
タップルのサービス本体のインフラ構成は、図に示すようなマイクロサービスであり、メインコンポーネントとして、AWS ECS の Fargate が多数稼働しています。また、本番環境をはじめとする複数の環境が存在するため、同時に多数のサービスが稼働している状況です。そのため、Fargate に焦点を当てただけでも、現状、多くのコストがかかっており、今後のサービス成長に伴い、このコストがさらに増加していくことが容易に推測されます。

このような背景から、メインコンポーネントの最適化として、ECS のプロセッサを現在稼働している x86 から単価の安い ARM64 へ移行することで、約20%のコスト削減*1 を実現することが今回の取り組みの目的でした。
*1 https://aws.amazon.com/jp/fargate/pricing による値段から算出
タスクの軸
プロセッサの移行にあたり、以下の3点を軸に進めました。
- ARM64 の移行に伴う互換性調査
タップルのサービスは、Node.js で稼働しています。そのため、プロセッサの移行にあたり、パッケージに互換性がなければ、そもそも施策を実行できないため、検証は不可欠です。また、Fargate から Managed Instance など、インフラの刷新も進行しているため、Fargate のみならず Managed Instance との互換性も考慮する必要がありました。
- ARM64 イメージの管理と運用手法
ARM64 で稼働させる上で、ARM64 イメージをどのように管理するかは検討事項として必須です。単に ARM64 イメージをビルドしてレジストリにプッシュすれば終わりではなく、移行期間中に ARM64 のみを保持するのか、あるいは x86 と ARM64 の両アーキテクチャを併存させるのか、といった運用方針を、実際のサービス稼働を前提に設計する必要があります。
- CI / CD の安定性
今回は dev 環境を中心とした移行であったため本番環境より柔軟性が利く状況でしたが、本番環境で活用できる移行計画の策定は必須です。タップルの SRE チームでは開発者の生産性を重要視しており、CI におけるビルド時間の増加など、開発者体験に影響を与える可能性がある点については、十分に配慮したうえで検討する必要があります。
タスク概要
互換性調査
タップルには、開発環境としてナンバリング環境が用意されています。今回の調査では、開発メンバーに影響が出ないよう、ナンバリング環境の1つを一時的に占有して検証を実施しました。その結果、検索サービスのみ、使用しているパッケージの Release Package に ARM64 のネイティブビルドが存在しないことが判明しました。
このため、ビルドを手動で行うことによる時間的コストや、動作保証がないことによるリスクを考慮し、今回は検索サービスを対象外とする方針としました。最終的に、Fargate と Managed Instance の両方で APM の指標から稼働を確認できたため、検索サービス以外の移行を進めました。
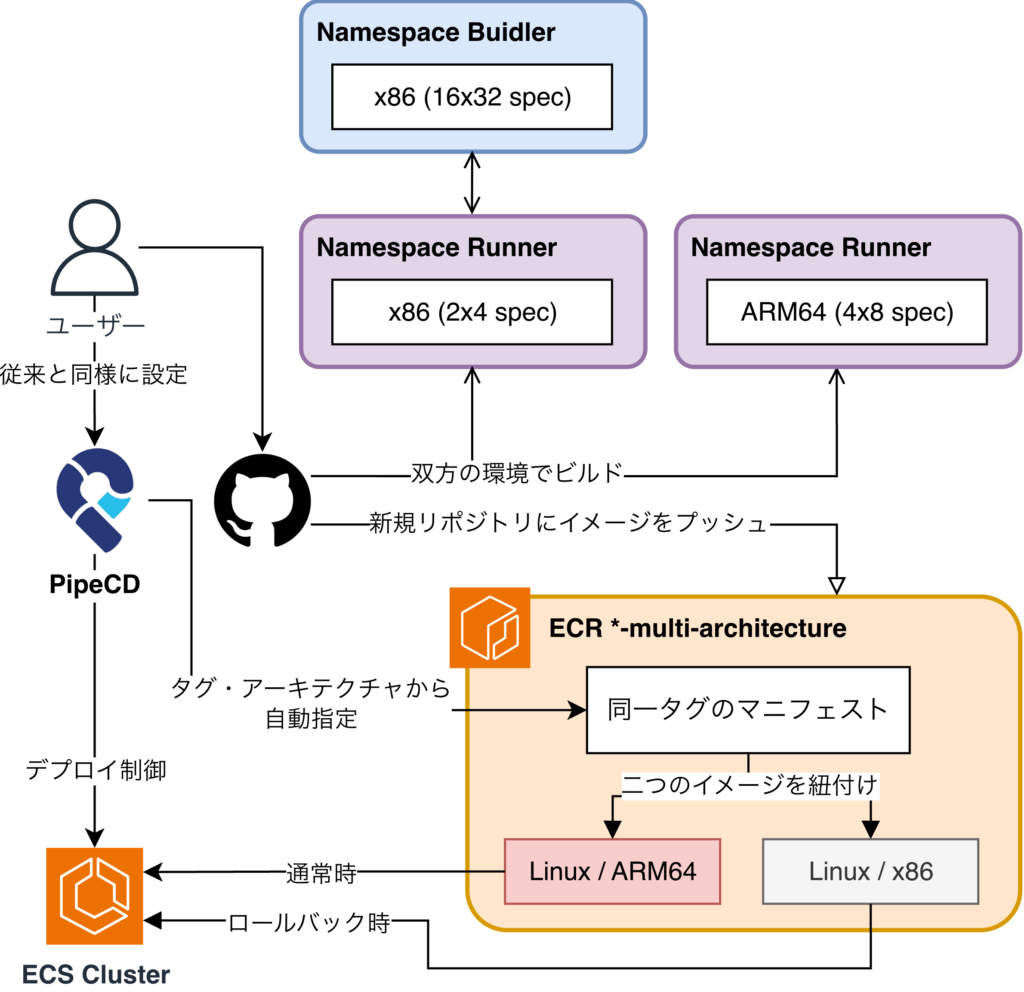
ARM64 イメージ管理戦略
ARM64 移行中のイメージの扱いとしては、マルチプラットフォームイメージを採用することに決めました。これは、1つのマニフェスト(どの実体イメージを使うかを定義するメタデータ)で複数のアーキテクチャイメージを紐付けて管理できる概念です。ユーザーはアプリケーションのタグを変更することなく、タスク定義のアーキテクチャを変更するだけで柔軟に対応できます。
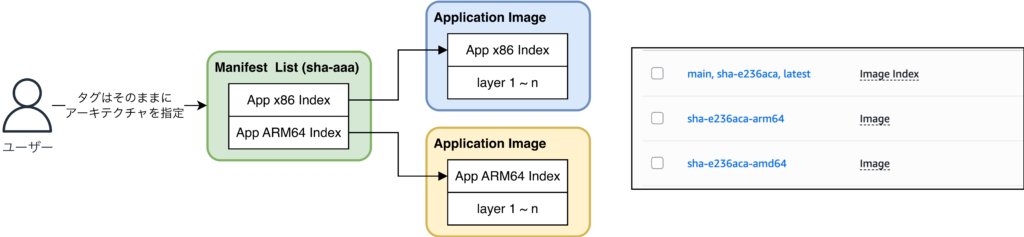
タップルの文脈では、PipeCD で管理している ECS のタスク定義のアーキテクチャ指定を変更するだけで、アプリケーションはそのままにプロセッサを変更できます。移行を進める上で、動作が検証できていたとはいえ、ARM64 に起因する未知の障害が出るリスクを意識していました。顧客を大きく抱えているからこそ、トラブル時には即座に対応できる戦略として、この方式を採用しました。
なお、マルチプラットフォーム化により2つの実体イメージとマニフェストを持ちますが、ECR はレイヤ単位で課金され、多くの共通レイヤは重複課金されないため、ECR コストの増加も削減額と比べて誤差範囲でした。
このマルチプラットフォームイメージを導入するにあたり、docker に標準搭載されている buildx という機能を採用して実装していきました。アーキテクチャを変更するのみでロールバックの容易さ・速さを確認でき、その有効性を確認しました。しかし、画像のようにビルド時間に大幅な遅延を観測し、開発者の生産性を下げる結果になりました。

移行中のリスクを考慮すると、ロールバックの容易さは不可欠です。今回の移行で、マルチプラットフォームイメージの方針の有用性は確認できましたが、ビルド時間が高速化できれば、開発者体験とコストの双方を含めた事業として移行の意義があると定め、次にこの短縮を目指すことにしました。
ビルド時間の増加にかかる検証
ビルド時間の短縮にあたり、まず焦点を当てたのは、CI 環境の見直しでした。タップルの SRE チームでは、CI を実行する環境として Namespace を採用しています。Namespace の Remote Runner で CI 全体を回し、イメージのビルドに関しては Runner とは別インスタンスの Remote Builder を用いています。
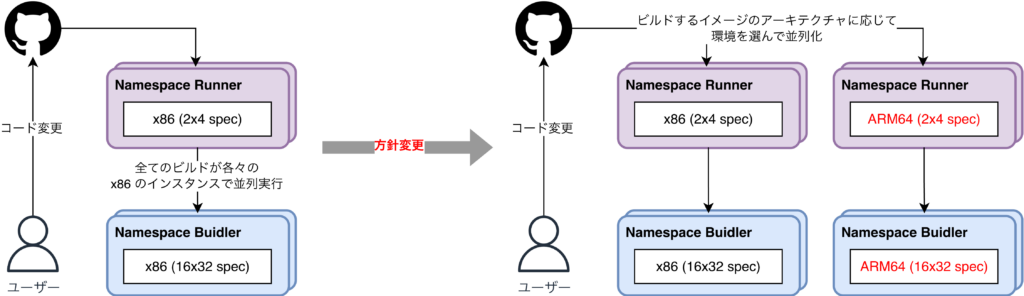
現状では、個々で並列に回しているものの、ARM64 のビルドは x86 のインスタンスで稼働していました。ビルド時間の増加はこのアーキテクチャの差異(ARM64 のビルドを x86 環境で実行している)によるものと仮定し、図のように環境ごとにビルドをする構成を組みました。実態としては、Github Actions の matrix を活用して分離させる、つまりは docker buildx のマルチプラットフォームビルドを手動で構築するような実装でした。
結果的には、根本的な解決策とはなりませんでしたが、わずかな改善は見られたため、生産性・コストの観点からも、今後は環境を分離して進めていく方針を立てました。
検証の結論
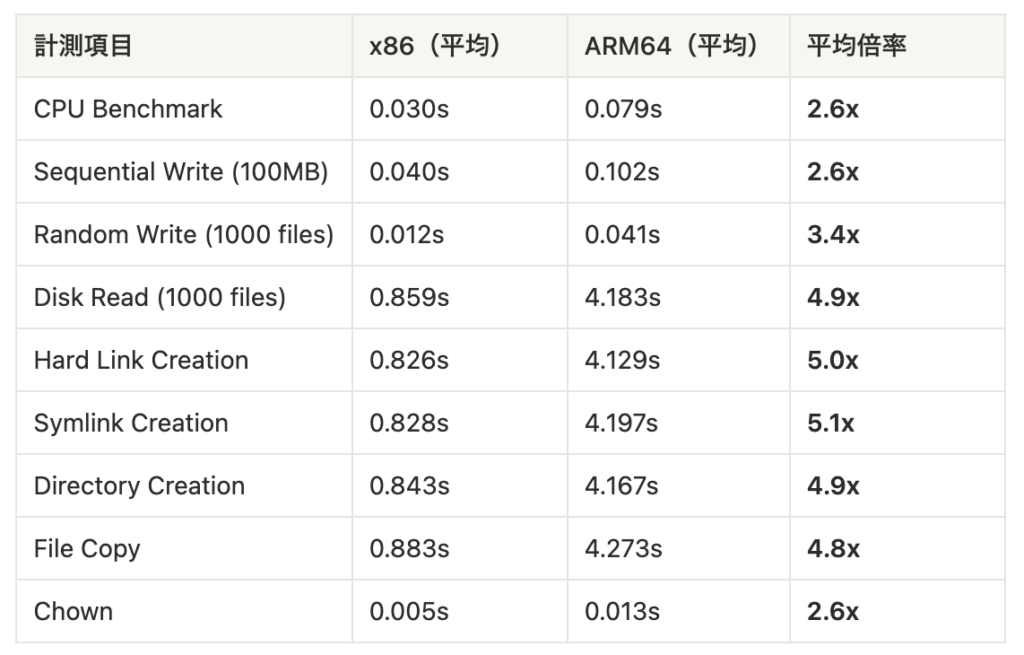
上述した以外にも検証を試みて切り分けをしていったのですが、結論を得るに至らず、難航しました。最終的に原因に直結した検証は、ARM64 の Remote Builder 自体の性能検証でした。重要だったのは、タップルのサービスの Dockerfile に近い処理を Linux のデフォルトコマンドで実施した結果、性能に違いがあったことです。下記の画像のように、Remote Builder 自体の性能が、x86 に比べて 2.5倍〜5倍程度劣ることが判明しました。そのため、ARM64 においては、Namespace の Remote Builder を採用しない方針のもと移行計画を進めるしかないと判断しました。
Remote Runner を活用した ARM64 移行
まず、ここまでの状況を総括し、ARM64 の移行では、Remote Runner による Local Build(Runner 内部でのビルド)を試み、もし ARM64 環境でのビルド時間が x86 と同等にならず、開発者の生産性が下がるようであれば、事業面・開発面の両方の観点から移行は見送る、という結論を事前に定めました。
Remote Runner の検証では、まず Github Actions の Runner に焦点を当てました。タップルが既にプランを契約しているという点に加え、新たな SaaS を導入する場合のコストや、その運用管理にかかる工数を考慮すると、ARM64 移行の工数に対して得られるリターンが薄くなると判断したためです。
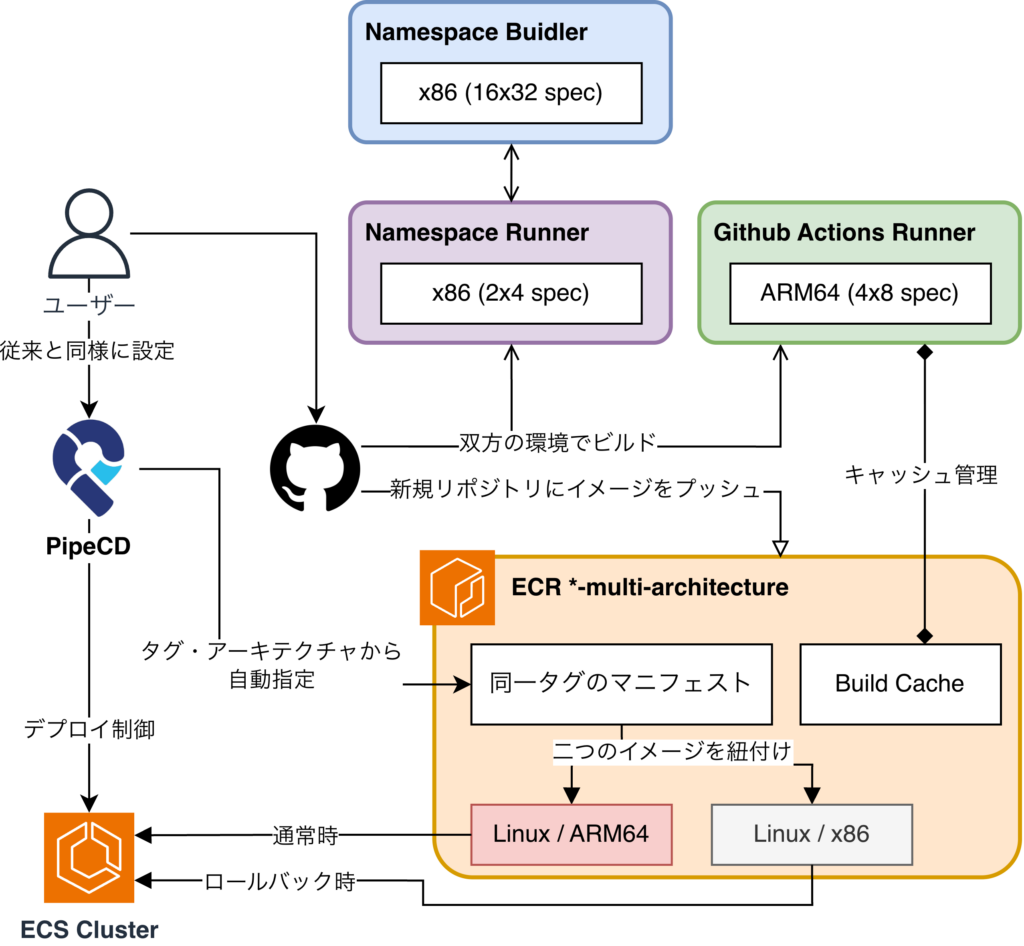
Github Runner を活用した構成では、ARM64 自体のスペックを Namespace Runner よりかは性能を少し上げたものの、Remote Builder よりかは大幅に小さいインスタンスでした。しかし、実際に計測してみると、x86 環境と同等、あるいはそれ以上のビルド性能が得られるという想定外に良い結果が得られました。
なお、Remote Runner で Local Build を成立させるには、Docker レイヤや依存関係のキャッシュが性能の鍵になります。Github 自体にもキャッシュ機能はありますが、費用面では ECR への配置が最適であり、その分の運用コストも若干増えますが、生産性という観点では極めて最適であると判断しています。
また、この結果を踏まえて Namespace Runner でも Local Build をやるとどうなるのだろうという期待感が持てたため、追加検証を開始しました。
GitHub Runner と近い構成で検証したところ、Namespace Runner でも x86 と同等、あるいはそれ以上のビルド性能が得られることが確認できました。さらに、CI として実行環境を統一できる運用面のメリットに加え、GitHub Runner で課題になりがちだったキャッシュ肥大化の管理が不要になる利点も存在していました。
これらを総合すると、ARM64 移行においては、Namespace Runner 上で Remote Runner による Local Build を行う構成が最適である、という結論に至りました。
コスト面においては、検証期間中は一時的に増加しますが、概算の結果からどの構成でも初期段階では避けられないものでした。実際には ARM64 へ移行してから 1〜2 か月程度で回収できる見込みが立っており、開発者の生産性を落とさずにインフラコストを最適化するという目的に対して、もっともバランスの取れたアプローチだと判断しています。
適用検証
ARM64 移行の方針が確定したため、dev 環境において、上述の設計を導入し一定期間稼働させました。下記は、とあるサービスのメトリクスを抜粋したものです。図にあるように、ARM64 で稼働した場合でも、x86 と同等の性能を発揮しており、パフォーマンス上の問題はないものと見受けられます。
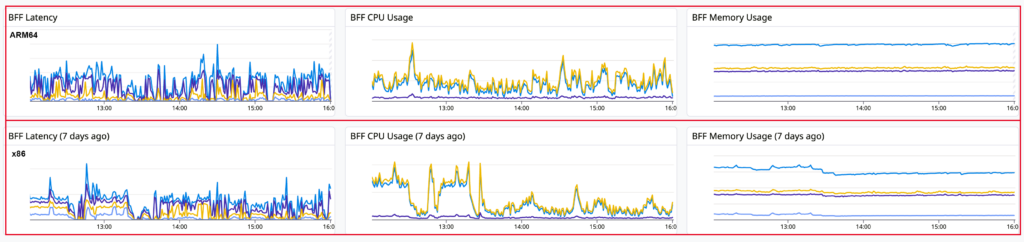
また、提案の大きな課題であった CI のビルド時間も、長期間に及ぶことはなく、x86 と同等の時間で完了していることからも、開発者への生産性が維持できていることが確認できました。
なお、 dev 環境では ECS サービスの設定で、デプロイ中、最大2倍までタスクを同時起動可能としていたため、旧 (x86) と新 (ARM64) を一時的に並行稼働させながら段階的に入れ替えるローリングアップデートにより、安定して実施できました。
まとめ
今回のインターンシップでは、タップルにおけるインフラリソースの最適化について取り組ませていただきました。コストの最適化という抽象的なタスクに対し、事業的なリスクとリターン、開発者体験を維持することを考慮した設計が提案できました。
コストの最適化という目的からも、事業的なリスク(サービス停止など)やリターン(コスト削減)を常に意識しながら、トレードオフを考慮して設計できたと考えています。
特に、CI に要する時間の原因調査には苦労しましたが、この経験は本番環境に適応する際には引っかかることなく円滑に進めるための、大きな糧になると確信しています。
今後は、本番環境を見据えた動きを想定しています。実際に出してみないと様子がわからないところがあるため、本設計を使いつつ、キャパシティプロバイダーによる Auto Scaling Group を活用したカナリアデプロイによる適用をしていくことで、リスクを抑えつつコスト削減に貢献すると考えています。
終わりに
今回のインターンを通じて、事業的なスパンや多角的な影響を考慮したエンジニアリングを行う視座を獲得できました。技術を手段として事業成長を実現する思考が身につき、自身の成長目標を達成できたと感じています。
また、タスクを遂行する上での挑戦を寛容に受け止めてくださり、伴走してくださる姿勢や、事業に真摯に向き合う皆さまの姿から、社風を知り、共感を得られる場面が多くありました。
設計に取り組む中では、技術を多様な観点から評価・選択する際のトレードオフの考え方や、信頼性をどのように技術で担保していくかについて学ぶことができました。インフラ技術を通じて事業にどう価値を届けるかを実感できたこの経験を糧に、今後もより一層精進していきたいと思います。
メンターの方を始め、タップルのサーバーチーム・SRE チームの皆さま、人事の皆さまには大変お世話になりました。技術面・思考面の双方で大きく成長できた1か月でした。本当にありがとうございました。