
はじめに
ABEMAのData Scienceチームで、2025年9月から半年間、ミッション型インターンに参加した田名部智也と申します。
東京大学電子情報工学科の4年生で、大学では音声情報処理の研究を行っています。
インターンでは、ABEMAのプロダクト上で行われるA/Bテストの分析や、A/Bテスト分析基盤の機能改善、LLMを活用した分析レポート要約のPoCなど、さまざまな業務に取り組みました。本記事では、その中でも「マルチエージェントシステムによる過去の施策の検索と示唆出し」についてお話しします。
Data Scienceチームの現状
ABEMAでは、データに基づいた意思決定を行うために、A/Bテストの結果を踏まえて判断する文化の醸成に注力してきました。A/Bテストの流れは下図の通りです。
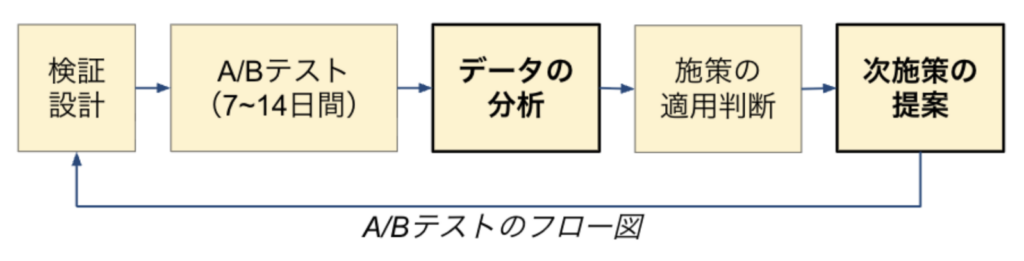
- 検証設計:検証したい施策について、元になった仮説や背景、そしてそれを検証するための評価指標や適用判断の軸などを施策実行者が設計して文書にまとめます。
- A/Bテスト:検証設計書に基づいて、A/Bテストを実行します。施策によりますが、検証期間はおよそ1〜2週間です。
- データの分析:A/Bテストの結果を分析します。A/Bテスト文化をスケールさせるために、A/Bテスト分析基盤である stargazer を開発しており、分析の大部分をシステム化しています。
- 施策の適用判断:検証設計書と分析結果を照らし合わせて、データサイエンティストが施策の適用可否を判断します。
- 次施策の提案:分析結果から得られた示唆をもとに、施策関係者が新しい施策を立案します。
直接的な原因として、分析が結果の確認に留まっている点が挙げられます。深掘りや示唆出しまで踏み込めていないため、A/Bテストが施策の評価で完結してしまっています。そのため、次の施策創出や構造的な学習につながっていません。加えて、施策の知見が属人化してしまっています。
さらに背景を深掘りすると、根本要因は2つあります。1つ目は、施策数の増加に対して、分析側のリソース・時間が相対的に不足していることです。2つ目は、過去施策の設計・結果・得られた示唆が分散していることです。そのため、検索・再利用しづらい状態になっています。
アプローチ
上記課題を解決するために、過去に行われた施策を横断的に検索し、結果を要約して参照できるようにすることを考えました。さらに、A/Bテストから示唆を抽出して次の施策に生かすための機能も必要だと考え、これらを実装することにしました。具体的には、以下の3点です。
- 過去施策を自然言語で横断検索できるようにする。
- 検索結果の要点を要約し、A/Bテストの結果から示唆を抽出できるようにする。
- 抽出した示唆に基づいて、追加の深掘り観点や次の打ち手を提案できるようにする。
ただし、上で列挙した機能はそれぞれ性質が異なる処理を必要とします。そのため、単一の処理フローにまとめると、拡張や改善が難しくなります。そこで、役割ごとにエージェントを分けて協調させる方針にしました。これにより、一連の作業を統合的に実行できる「マルチエージェント」アプローチを採用しました。
マルチエージェントの設計
上記の課題を踏まえて開発した「過去施策検索・示唆出しエージェント」の仕組みを説明します。本章ではまず、技術選定を整理した上で、マルチエージェントのワークフローとクラウドアーキテクチャの2つの観点から全体像を紹介します。
技術選定
検索機能
過去の施策の検索には、Googleが提供するVertex AI Searchを利用しました。Vertex AI Searchは、キーワードマッチングとセマンティック検索に基づいて、関連性の高いドキュメントやドキュメントの一部分を検索します。セマンティック検索とは、 エンべディングを使用した検索で、ユーザの検索意図や言葉の意味を理解して関連する情報を提示する技術です。
マルチエージェント
マルチエージェントとは、自律的に思考・行動する複数のAIエージェントが、互いに協調・役割分担しながら複雑なタスクを実行する仕組みです。今回の実装では、Google が提供する Agent Development Kit(ADK) を利用しました。Google ADKは、エージェントを効率的に構築・管理・評価・デプロイするためのオープンソースフレームワークです。コミュニティはまだ成熟途上ではあるものの、Vertex AI Search をはじめとする Google Cloud サービスとの親和性が高い点が採用理由です。
マルチエージェントのワークフロー
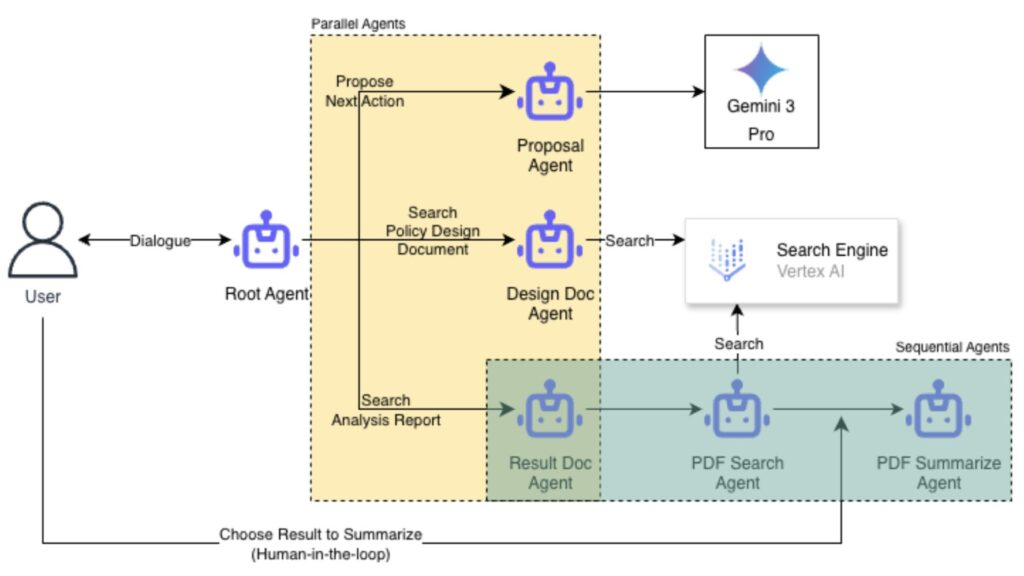
ユーザの入力を起点に、Root Agentが全体の進行を制御し、複数のエージェントを組み合わせて「過去施策の検索」と「要約・示唆出し」までを行います。以下は、各エージェントの説明です。
- Root Agent
- ユーザが直接相互にやり取りするエージェントで、以降のエージェント呼び出しと結果の統合を担当します。
- Parallel Agents
- Design Doc Agent: 検証設計書を検索し、施策の意図や前提条件を押さえるための候補を集めます。
- Result Doc Agent: 分析結果レポートを検索し、結果・指標・差分が載っている文書候補を集めます。
- Proposal Agent: 次に取るべきアクション案(深掘り方針や新施策)を提案します。
- Sequential Agents
- PDF Search Agent: ユーザの要求に応じて、必要としている分析結果レポートを探索し候補を提示します。
- PDF Summarize Agent: 検索された候補のうち、どれを要約対象にするかをユーザが選び、選択された分析結果レポートのPDF内容を根拠として、要点整理と示唆出しを行います。
GCPアーキテクチャ
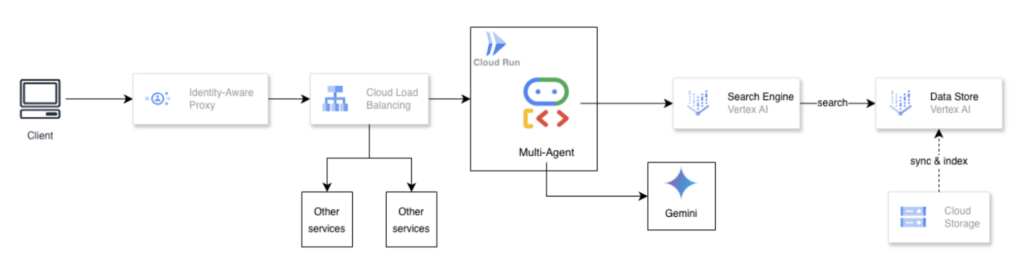
今回開発したマルチエージェントシステムは、Data Science チームで運用している A/Bテスト分析基盤 stargazer 上の機能として導入しました。以下は、主要なコンポーネントの説明です。
- Cloud Run(Multi-Agent)
- サービス本体はCloud Run上で稼働します。
- Vertex AI
- 文書検索はVertex AI Search Engineが担当し、検索対象のインデックスはData Storeで管理されます。
- Cloud Storage
- 検索対象となる検証設計書や分析結果レポート等のデータはCloud Storageに置かれ、Data Store側で同期・インデックス化されます。
試行錯誤
開発を進める中で最初に大きな壁になったのは、Vertex AI Searchは検索精度が高い一方で、要約精度にばらつきがある点でした。Vertex AI Searchは検索に加えて要約機能も提供しています。しかし、この要約機能をそのまま使うと、要約や示唆出しの段階でハルシネーションが発生したり、別施策の内容が混在したりしました。その結果、実務で使える品質になりませんでした。
そこで、まずは検索機能だけを用いて施策候補を絞り込みます。そのうえで、ユーザが望む施策を自ら選択し、その施策の分析結果レポートは全体をLLMに要約させる形式にしました。このように、プロセスの重要箇所や判断に人間が介在し、監督する仕組みはHuman in the loopと呼びます。これにより、要約の根拠がより確実になりました。あわせて、文脈の取り違えや抜け漏れを減らす方向で改善しました。
評価
概要
開発したエージェントが実務で使えるかどうかを判断するために、評価は大きく2つに分けて実施しました。1つ目は、ユーザの質問から目的の施策に辿り着けるかという「検索の評価」です。2つ目は、見つかった文書を根拠に、誤りなく要点をまとめられるかという「要約の評価」です。
検索の評価
検証設計書の検索精度
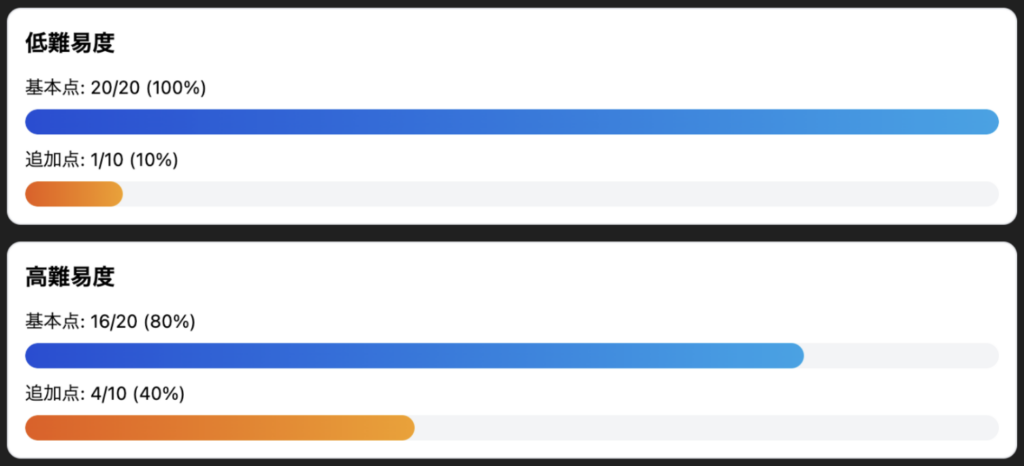
検証設計書については、ユーザが自然言語で施策概要を尋ねたときに、該当施策を正しく引用して要約できるかを確認しました。10施策それぞれについて、キーワードが直接含まれる「低難易度」と、状況説明から施策を特定させる「高難易度」の2段階の評価用プロンプトを用意しました。
採点は、各プロンプトに対して以下のルールで0〜2点(基本点)を付与しました。
- 0点: 求めていた施策が引用されていない(別施策が出てくる、施策を特定できていない)
- 1点: 求めていた施策は引用されているが、概要のまとめが不正確(主要な前提や目的がズレている、誤りが目立つ)
- 2点: 求めていた施策が引用され、検証設計書の内容に沿って正確に概要をまとめられている
また、基本点とは別に、関連性の高い施策を複数提示し、それらも正確に説明できた場合は、加点枠として1点の追加点を付与しました。
検証設計書検索の評価結果は以下の通りです。
今回開発したマルチエージェントシステムは、Data Science チームで運用している A/Bテスト分析基盤 stargazer 上の機能として導入しました。以下は、主要なコンポーネントの説明です。
- Cloud Run(Multi-Agent)
- サービス本体はCloud Run上で稼働します。
- Vertex AI
- 文書検索はVertex AI Search Engineが担当し、検索対象のインデックスはData Storeで管理されます。
- Cloud Storage
- 検索対象となる検証設計書や分析結果レポート等のデータはCloud Storageに置かれ、Data Store側で同期・インデックス化されます。
分析結果レポートの検索精度
分析結果については、目的の施策に対応する分析結果レポートが検索上位に入るかを評価しました。こちらも低難易度・高難易度の2段階のプロンプトで確認しました。
採点は、各プロンプトに対して以下のルールで0〜2点を付与しました。
- 0点: 検索上位の候補に目的のPDFが含まれていない
- 1点: 検索上位の候補に目的のPDFが含まれている
- 2点: 目的のPDFが検索結果の最上位にある
分析結果レポート検索の評価結果は以下の通りです。

結果として、キーワードが明確な質問では高い精度で上位にヒットしましたが、抽象的な質問では精度が落ちやすい傾向がありました。検索候補を提示してユーザに正しいPDFを選択してもらう設計にすることの必要性が、ここでも確認されました。
要約の評価
要約・示唆出しは、複数の観点を満たして初めて実務利用に耐えるため、評価軸を事前に設計してから開発を進めました。10施策を対象に、Data Scienceチーム内の複数名が評価者となり、各施策を複数人で採点する形でレビューしました。
具体的には、正確性・網羅性・中立性の3点です。提案の質については、事例ベースで補足します。Data Scienceチームとして「実務で使える」「次の検討につながる」と判断できるアウトプットが得られたことを報告します。
評価項目は以下の3つです。
- 正確性: 元のPDFレポートの事実・数値と整合しているか(数値の取り違え、指標名の誤り、p値の不用意な言及などを減点)
- 網羅性: 施策概要、primary metrics, guardrail metrics, secondary metricsの結果、最終結論が抜けなく含まれているか
- 中立性: 感情的・断定的な表現が混ざらず、事実記述として読めるか
要約の評価結果は以下の通りです。
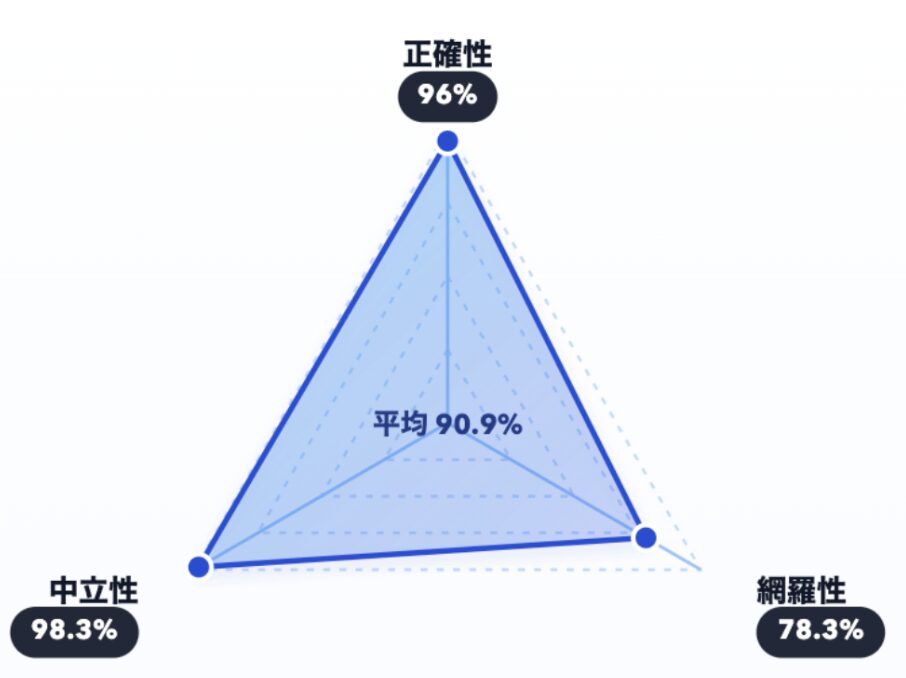
評価の結果、正確性と中立性は高い水準を達成できた一方、網羅性が相対的に弱いことが確認されました。具体的には、施策の介入前後で指標は変化しなかったが、文脈上重要な結果を報告しないケースが見受けられました。ただし、今回は1ターンでどの程度の情報を返せるかを評価しているため、実運用では複数ターンで情報を聞き出すことで網羅性を補える可能性があります。
示唆出し・新施策提案の評価
本来は、「示唆出し」「新施策提案」「深掘り分析提案」といった次のアクションにつながる提案の質も、定量的に評価して示したいと考えていました。しかしこれらは、施策や状況に依存して「何が正解か」を一意に定義することが難しく、採点基準を固定すると現場の納得感とズレるリスクがありました。そこで今回は、事例ベースでデータサイエンティストが妥当と納得できる提案が得られることを確認しました。
以下に具体例を示します。コンテンツ推薦機能で「ユーザが既に視聴したコンテンツを除外し、未視聴コンテンツのみを推薦する」施策を検証しました。結果、総視聴時間は変化しなかったが、推薦機能経由の視聴時間は減少していることが確認されました。
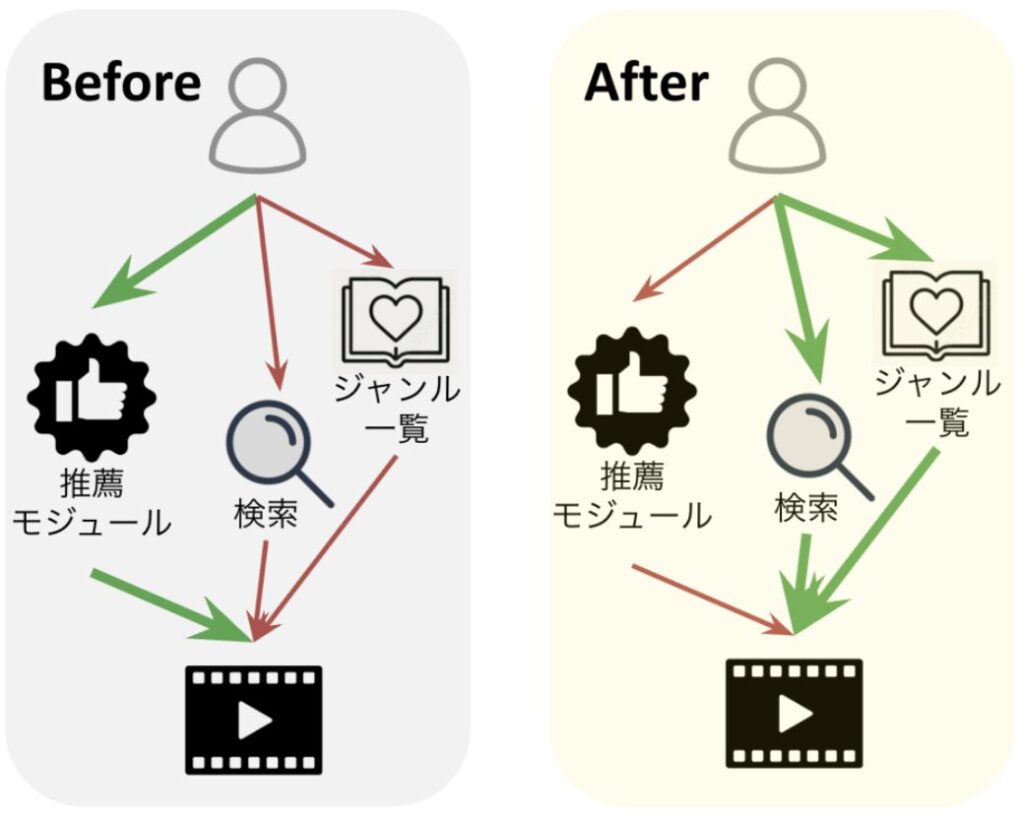
この結果を受け、マルチエージェントシステムは「既存の視聴経路が別の経路に置き換わった可能性」を示唆しました。さらに、下図のように、検索画面やジャンル一覧など視聴時間が増加している可能性のある経路を候補として提示し、深掘り分析を提案しました。
提案に従って検証したところ、実際に「視聴中の作品」画面を経由した視聴時間が増加していることが確認され、経路置換の仮説が支持されました。加えて、この示唆を踏まえ、繰り返し視聴されやすいコンテンツと一度きりの視聴に留まりやすいコンテンツで推薦ロジックを切り替えるといった新たな施策案も提案できました。
学び
ハードスキル
IaCによるインフラ管理
Cloud Runや周辺リソースを、後から再現・変更できる形で管理する重要性を学びました。特に、CI/CDのワークフローとIaCがどのように接続されると「組織として運用できる状態」になるかの理解が深まりました。個人開発だと後回しになりがちな、環境差分の吸収、変更のレビュー、デプロイの手順化といった観点が、大規模な組織での運用には欠かせないということを実感しました。
ADKを用いたマルチエージェント開発
単体のLLM呼び出しではなく、検索・候補提示・選択・要約という一連の流れをエージェントとして分割し、責務を明確にすることで改善が回しやすくなると実感しました。ワークフローも、sequential(依存関係が強い処理の直列化)、parallel(探索や候補列挙などの並列化)、loop(ユーザ選択や追加質問を含む反復)を使い分けることで、流れをコントロールできることが分かりました。
ソフトスキル
課題に対するアプローチ
先に評価軸を決めることで実装の迷いが減り、改善の議論を具体化でき、PDCAループをより高速に回せました。
ドキュメンテーションの重要性
試行錯誤の過程、判断の根拠、評価結果を都度ドキュメントに残すことで、後からの振り返りやチーム内共有がスムーズになりました。ドキュメンテーションから先に入ることで、やるべき細かいタスクが分解され、自分自身の次の行動が明確になります。結果として「次に何をするか」で迷う時間が減り、作業の切り替えコストも下げられることを学びました。
人を巻き込むことの重要性と難しさ
アウトプットの品質を上げるには、早い段階から関係者を巻き込み、フィードバックループを回すことが不可欠だと学びました。具体的には、Data Scienceチーム内のメンバーに評価を依頼して観点のズレを早期に潰すことができました。加えて、開発チームに分析結果を報告し、次に提案する施策の妥当性について議論しました。さらに、社内で技術的に近い事例に取り組んでいる方と学びを共有したりもしました。
とはいえ、実際に関係者を巻き込むのは容易ではありませんでした。関係者のスケジュールや優先順位が異なるため、タイミングを合わせるだけでも手間がかかります。さらに、立場や専門性が違うと観点や期待値にズレが生じやすく、その差を埋めながら議論を前に進めることは難しいと感じました。
おまけ(AI Fes)
年に一度、サイバーエージェント全体で開催されるAI Fesにて、Data Scienceチームを代表して、上記の取り組みについてポスター発表を行う機会をいただきました。サイバーエージェントの事業は非常に幅広く、AI Labの研究から各事業部のAI活用事例まで、さまざまな取り組みに触れられて大きな刺激を受けました。当日は足を止めて真剣に聞いてくださる方が多く、議論やフィードバックもいただけてありがたかったです。少しでも知見の共有を通じて、社内コミュニティに還元できていたら嬉しいなと思います。
