
はじめに
こんにちは、奈良先端科学技術大学院大学 修士 1 年 の 東迎健太郎 です。
2025年 12月 2日 〜 12月 26日の 1ヶ月間、CyberAgent (CA) が主催するインターンシップ「CA Tech JOB」に参加しました。
私は バックエンドエンジニア として CA の 広告配信サービス を運用している AJA の Supply Side Platform (SSP) チームに配属していただきました。
目次
- インターンシップに参加した目的
- SSP の広告配信システムについて
- タスク背景
- 技術選定
- Argo Rollouts
- 取り組みプロセス
- テスト用の環境を構築
- 使用可能メトリクス選定
- 設計
- テスト環境で試す
- 今後の本格導入に向けて
- まとめ
インターンシップに参加した目的
今回、以下の目的でインターンシップに参加しました。
- 開発現場を知るため
私は同年9月に CA で開催された「Universe」というハッカソンに参加しました。そこで、CA の社風を知り、実際の開発現場の雰囲気や文化も知りたいと思っていました。 - 高トラフィック環境におけるシステムの開発
これまで高トラフィックをさばくシステムの開発経験がなかったため、このような環境での開発に関わり自己解決力をさらに高めたいと思っていました。
また、スケーラビリティや可用性を意識した開発をしたかったので、Kubernetes の参考書を読んだ程度の知識しかなかったのですが、自分から Kubernetes 周辺のタスクを求めました。
SSP の広告配信システムについて
取り組んだタスクについて触れる前に、私が配属された AJA が提供している SSP サービスについて簡単に説明します。
広告配信はまずストリーミングプラットフォームやテレビなどの メディア から広告のリクエストを受け、DSP と呼ばれる広告主・代理店が広告の入札をするためのシステムへ ビッド(入札)リクエスト をします。そして、取得した入札から最適なものをセレクションし、選ばれた広告をメディアに送信します。この一連のフローの仲介的役割を担っているのがSSPです。
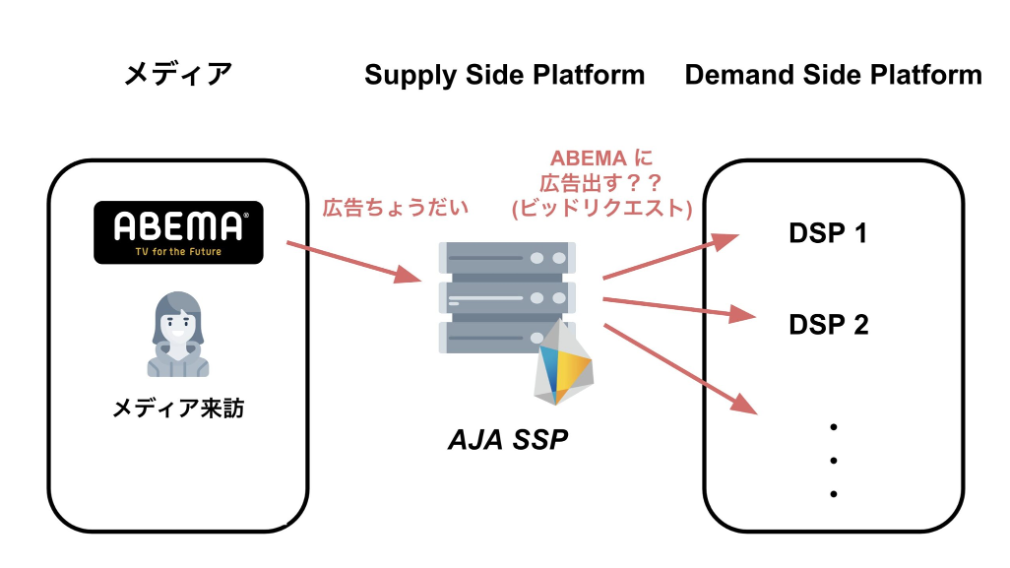 出典: 新卒が挑む、数万 QPS をさばく広告配信サーバのリクエスト制御
出典: 新卒が挑む、数万 QPS をさばく広告配信サーバのリクエスト制御
タスク背景
SSPの広告配信サーバ(アドサーバ)では新バージョンのリリース方式としてローリングアップデートを採用しています。理由は Kubernetes の Deployment リソースがサポートしているリリース方式であるため実装が容易であったことが挙げられます。
ローリングアップデート
ローリングアップデートは以下のように Pod を一つずつ旧バージョンから新バージョンに移行させることができます。
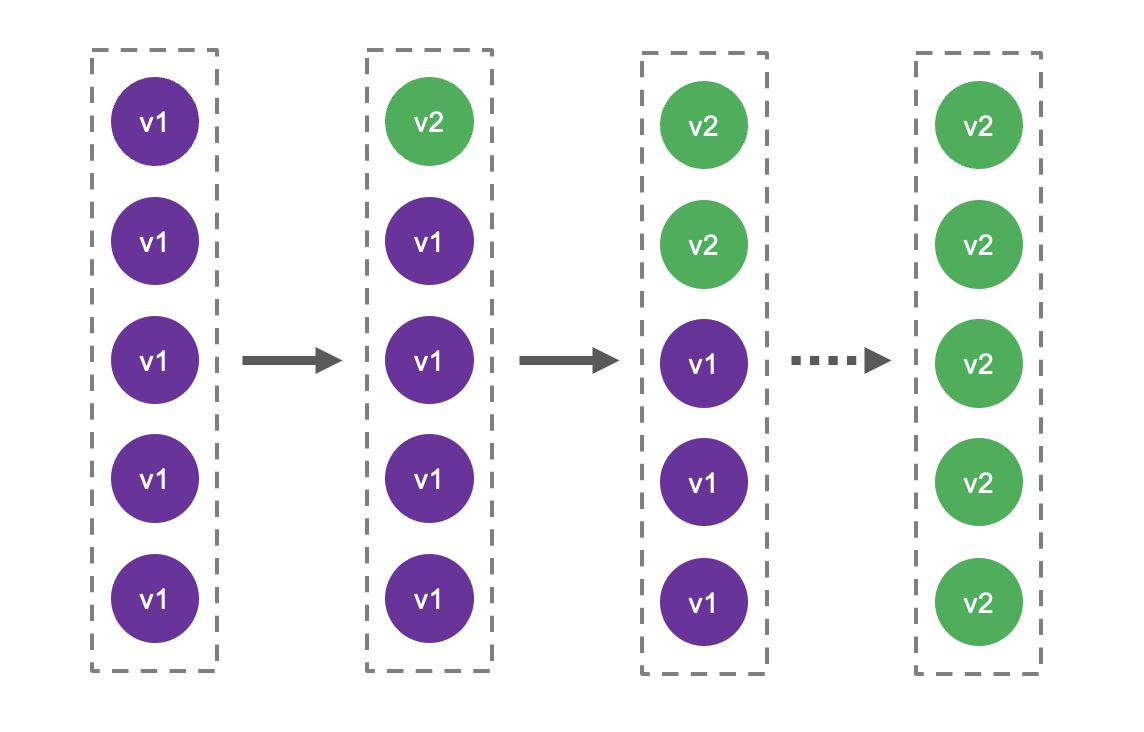
これはローリングアップデートを説明する一般的な図ですが、実際の動きは少し異なります。以下はモニタリングツール(New Relic)での実際のPod数遷移グラフです。
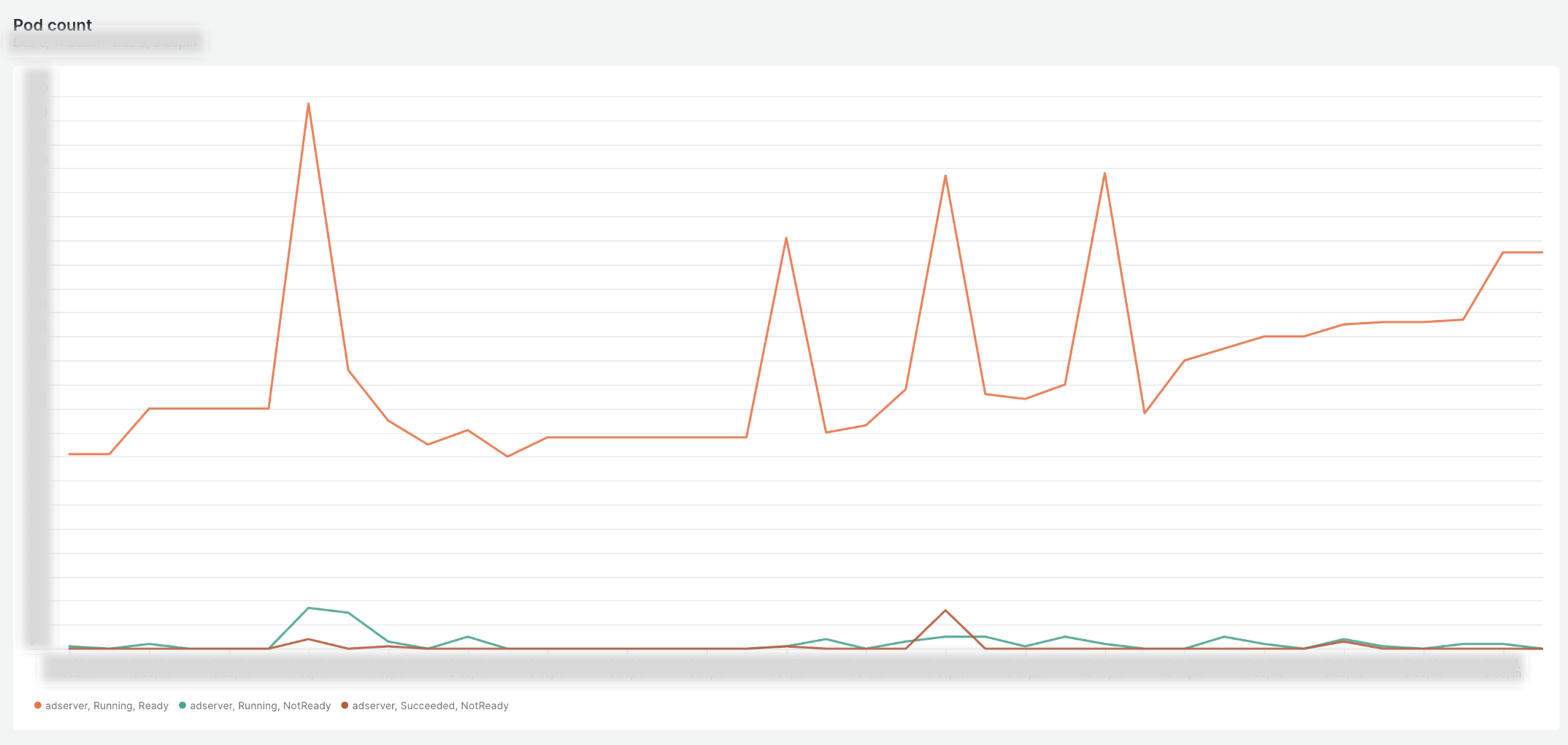
これを見るとリリース時にポッド数が倍増しながらほぼ同時に新バージョンの Pod に置き換わっていることがわかります。
したがってリリース後に本番環境特有の問題が発生した場合、ロールバック(旧バージョンに戻すこと)するまでに全てのクライアントに影響を与えることになってしまいます。
これを解決するとともに更なる恩恵を受けるためにカナリアリリースの導入を検討しました。
カナリアリリース
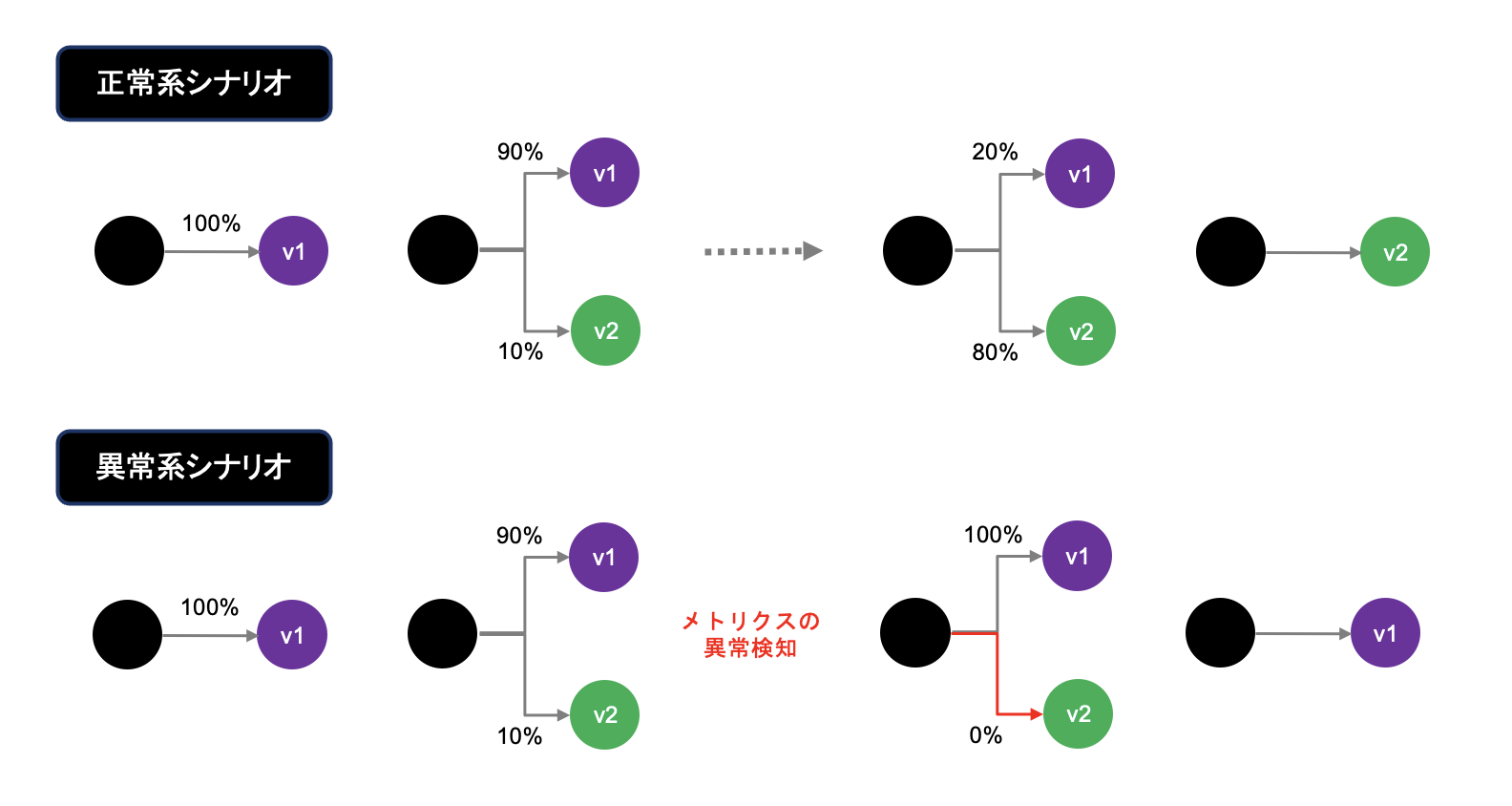
カナリアリリースは、新バージョンをいきなり全ユーザに反映するのではなく、まずは一部のトラフィック(例:10%)だけを新バージョンに流し、問題がないことを確認しながら段階的に比率を上げていくリリース方式です。
段階的に流すことで、もし本番環境特有の問題(特定のリクエストパターンでのエラー、レイテンシ悪化、依存サービスとの相性など)が発生しても、影響範囲を小さく保ったまま検知し、ロールバック(旧バージョンに戻すこと)できます。特に、数万RPSのような高トラフィック環境では「気づいてから戻すまで」の短時間でも影響が大きくなりやすいため、影響範囲を限定できる点が重要になります。
一方で、カナリアリリースを成立させるには「どのトラフィックが新旧どちらに流れているか」を制御できること、そして「問題が起きた/起きていない」を判断できる観測(監視・ログ・トレース)と、判定に使えるメトリクスが必要です。
技術選定
今回のゴールは「ローリングアップデートのまま全配信されてしまうリスクを減らしつつ、段階的なリリースを安全に運用できる状態を作ること」でした。そのため、技術選定では以下を重視しました。
- Kubernetesネイティブに扱える(マニフェストで管理でき、既存運用に載せやすい)
- 段階的なトラフィック配分(10%→20%→…)を表現できる
- メトリクスに基づく判定(分析)や、手動判断を挟む運用に対応できる
- 導入・運用コストが過度に高くない(学習コスト、依存コンポーネント、変更影響)
- 将来的に GitOps(例:Argo CD)と組み合わせやすい
候補としては、段階的リリースを自動化する Flagger、より包括的なCD基盤としての Spinnaker なども検討しました。ただし、今回のスコープでは「1. 既存のKubernetes運用に最小限の追加で載せられること」「2. 手動操作と分析の両方を柔軟に組み合わせられること」を優先し、Argo Rollouts を採用しました。Argo Rollouts と比較したときに、Flagger は 2 の面で劣り、Spinnaker は 1 がネックとなったというのが理由です。
Argo Rollouts は Rollout リソースで段階的なリリース手順(steps)と分析(analysis)を明示でき、さらに Dashboard から Promote / Undo の手動操作もできるため、まずは半自動の形で安全に導入し、将来的な自動化へ段階的に移行する方針に合っていました。
外部サービス連携については、SSP の分析基盤である Prometheus と New Relic の両方にも対応しています。
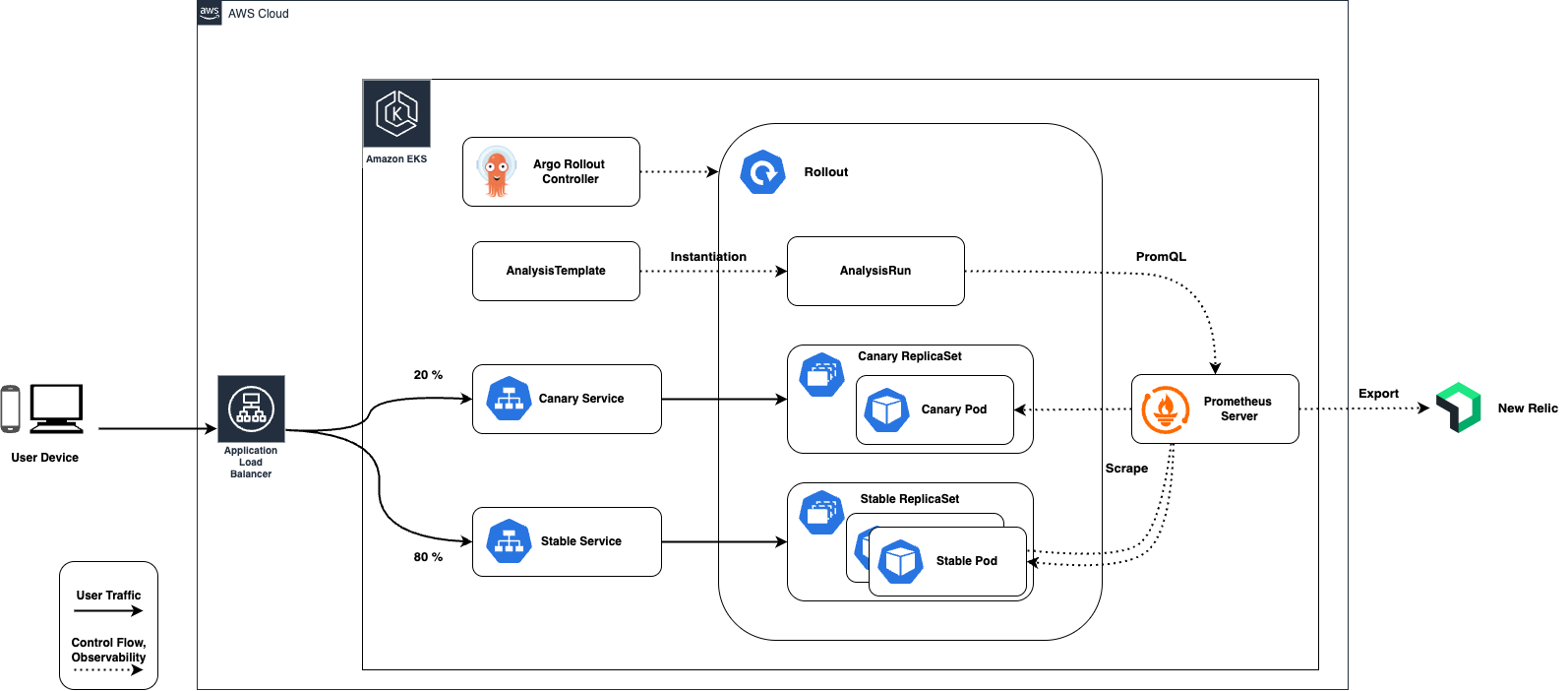
また、Kubernetes のコアオブジェクトでは厳密なトラフィック管理を行う機能は備わっていないため Argo Rollouts に合わせてトラフィックプロバイダーの操作も必要になります。Istio の VirtualService を使用すれば実現可能ですがカナリアリリースをするためだけに Istio の導入をするのは過剰であるため、他の手段として ALB のターゲットグループを制御することで実現します。
Argo Rollouts
Argo Rolloutsは、Kubernetes上で高度なデプロイ戦略(カナリアリリースやブルーグリーンデプロイ)を実現するためのコントローラーです。 これにより、段階的なリリースや自動分析、トラフィックの制御が可能になります。
主な設定項目として以下の3つがあります。
- steps
デプロイの進行を細かく制御するための手順。
例:10%→30%→100%と段階的にリリース。インターバルを入れる。 - analysis
各ステップでメトリクス(例:エラー率、レスポンスタイム)を自動で分析し、問題があればロールバック。 - trafficRouting
ALBやIstioなどと連携し、トラフィックの一部を新バージョンに振り分ける制御が可能。
また、Argo RolloutsにはWeb UI(Argo Rollouts Dashboard)があり、進行状況の可視化や手動操作(Pause/Resume/Rollbackなど)ができます。
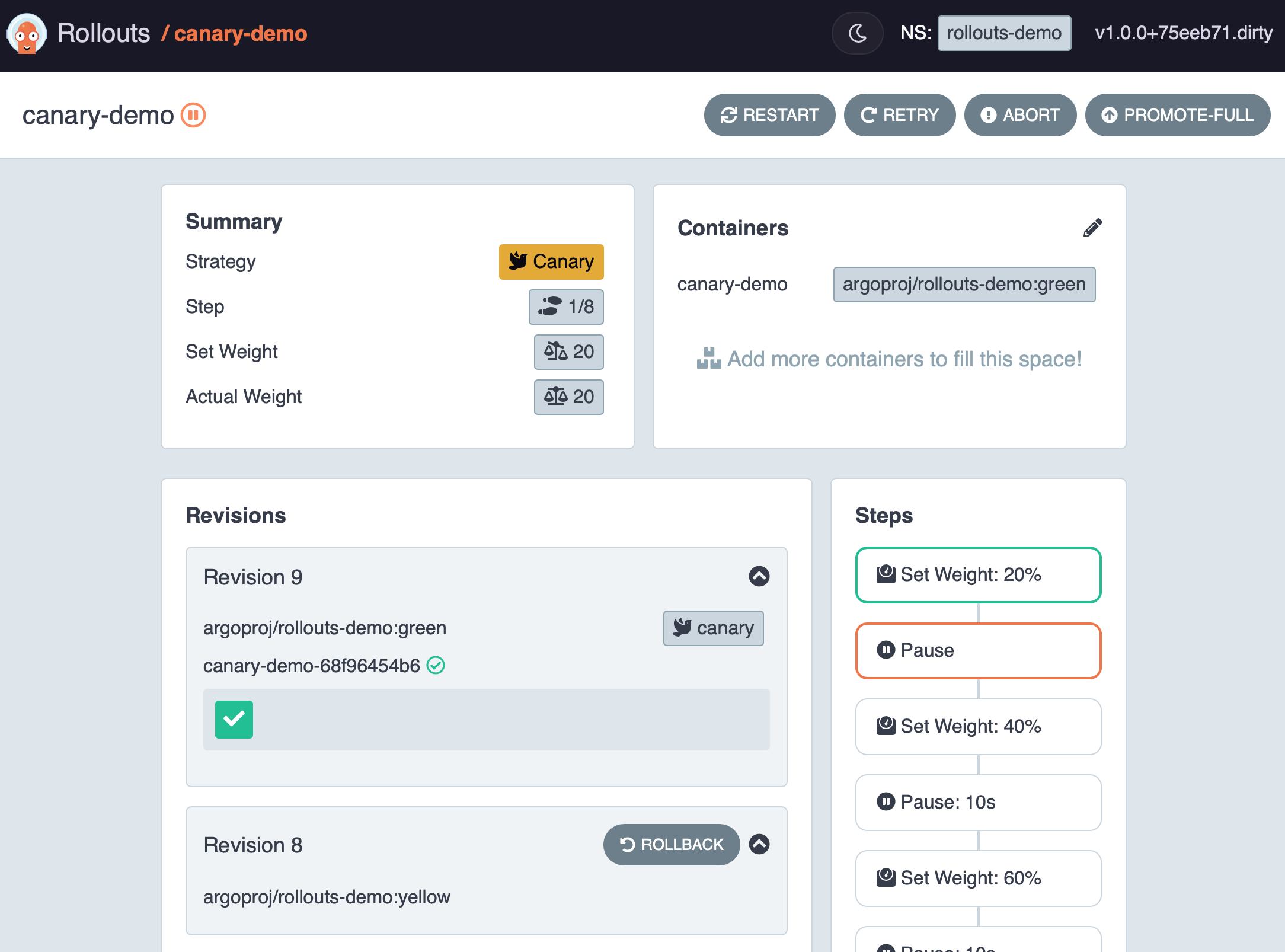 出典:
出典:
手動操作(Promote / Undo)
Promote(進める)
- UI: Argo Rollouts Dashboard で対象 Rollout を選択し、
Promoteを実行 - コマンド:
kubectl argo rollouts promote canary-rollout
Undo(戻す)
- UI: Argo Rollouts Dashboard で対象 Rollout を選択し、
Undo(Rollback)を実行 - コマンド:
kubectl argo rollouts undo canary-rollout
取り組みプロセス
テスト用の環境を構築
Argo Rollouts の動作を確認したり、マニフェストファイルに細かな設定をしながら設計を考えていきたかったので、他のメンバーの開発に影響を与えないようなテスト環境を構築しました。
使用可能メトリクス選定
New Relic で収集しているメトリクスの一覧を見たところ、以下の特徴を一つ以上持つものがほとんどでした。
- グラフの波形が安定していない
- 例)リクエスト数、ポッド数など
- 実装や最適化によって変化が容易
- 例)CPUやメモリ使用率、WarnやErrorログ数、レイテンシ
- ビジネスによって変化が容易、外部依存など
- 例)各DSPが設定しているBidリクエスト数制限の影響を受けているなど
これらのメトリクスを用いると分析結果を判定するための閾値を決めづらい又は頻繁な修正が必要になるため、適さないと判断しました。
他のブログ記事には 5XX エラーレスポンス率などを使用していることが多かったが、アドサーバの実装では 5XX エラーが起きる確率はほぼ0%であり分析で問題を発見できるメトリクスではないと判断しました。
このようにメトリクス単体だと分析しづらいことが分かったため、「canary と stable で比較する」という要素も加えることにしました。
結局、ad_return_rate というメトリクスを使用することにしました。 $$ \text{ad_return_rate}=\frac{\text{ad_return_total}\quad\quad}{\text{ad_request_total}\quad\quad} $$ このメトリクスは、メディアからの広告リクエストに対して広告を返した割合を意味します。 広告リクエストはいくつかのリクエストパスに分かれているため全て分析に使用します。
選んだ理由は、このメトリクスは割合であるため canary と stable それぞれの ad_return_rate を比較することが可能な点にあります。カナリアリリースでは canary と stable の各トラフィック量が変化したり、それぞれにアタッチされた HPA リソースによりポッド数も変化するので、それに影響しないので適すると思いました。
また、ad_return_rate は先ほど挙げた「分析に適さないメトリクスの特徴 3 つ」について、以下のように対処することができます。
- グラフの波形が安定していない
✓ ad_return_rate の波形は安定していないが、canary と stable で比較するので波形は影響しなくなる。 - 実装や最適化によって変化が容易
✓ 実装によって canary の ad_return_rate が stable より良くなる分(または同程度)には許容し、大きく低下する場合は分析失敗と見なすことができる。 - ビジネスによって変化が容易、外部依存など
✓ メディアからの広告リクエスト数増減などが起きても ad_return_rate は変化しない。
ad_return_rate のグラフ(リクエストパスごとに色分け)
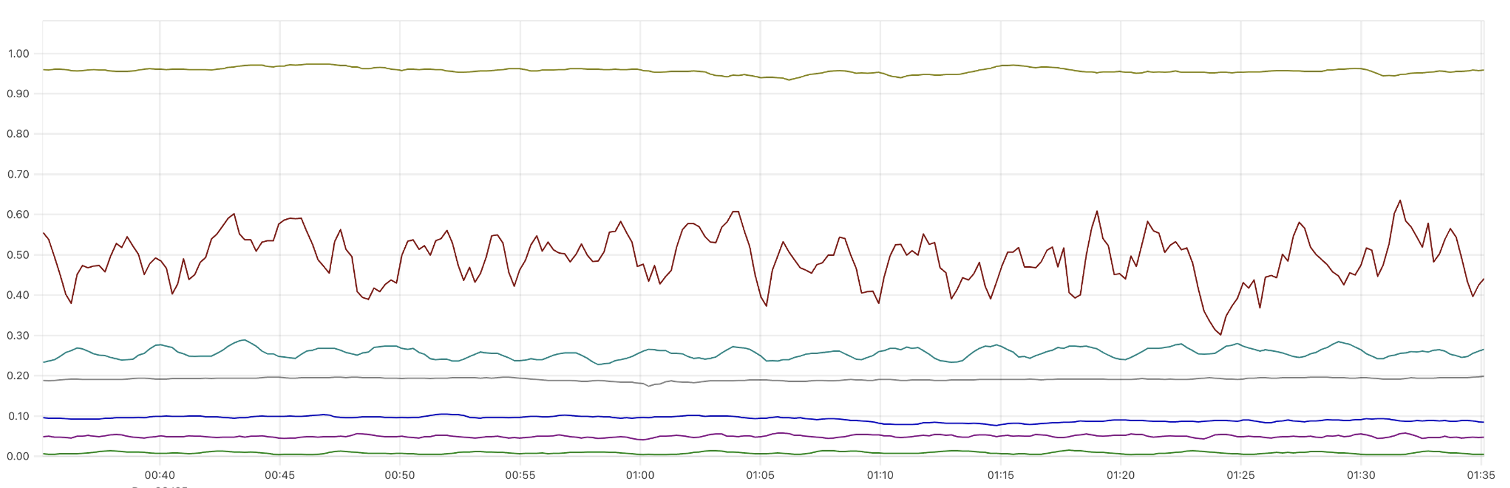
分析の判定式はこのようになります。式の範囲によって $\text{ad_return_rate}\hspace{1pt}_{canary}$ と $\text{ad_return_rate}\hspace{1pt}_{stable}$ が同程度の値になることを期待しています。
$$ \frac{\text{ad_return_rate}\hspace{1pt}_{canary}\quad}{\text{ad_return_rate}\hspace{1pt}_{stable}\quad} =\frac{\frac{\text{ad_return_total}\hspace{1pt}_{canary}}{\text{ad_request_total}\hspace{1pt}_{canary}}} {\frac{\text{ad_return_total}\hspace{1pt}_{stable}}{\text{ad_request_total}\hspace{1pt}_{stable}}} \quad ( \ge 0.95,\ \le 1.05 ) $$
設計
チームメンバーからの要望もあり、これまで同様にデプロイ時に担当者が目視でメトリクスを確認してその後は手動操作でロールアウトまたはロールバックする方式にしました。つまり、半自動的なカナリアリリースになります。理由としては、全自動のカナリアリリース導入を行うとこれまでのデプロイフローと差が大きくなってしまうため慎重になりたいためです。私も同じ考えで、もし全自動カナリアリリースを Production 環境で本格導入した後に分析が適切に機能していなかったことが判明すると、毎回デプロイ中にロールバックされてしまいます。そのため、今回は一時停止のステップを設けてその後段階的リリースをできるだけでも大きな貢献になると考えました。
しかし、実際に Production 環境で分析も含めて長期間運用しないと本当にメトリクスが正しいのか、パラメータチューニングが上手くいっているのかは分からないため、たとえ分析が失敗してもリリースには影響を与えない(ロールバックさせない)方法はないのか調査したところ、Argo Rollouts では分析を Dry Run モードで実行するとこの要求を満たせるようです。
これらを元に、カナリアリリースにおける各ステップのトラフィック割合とインターバルを以下のように設定しました。
| ステップ | トラフィック割合 (%) | インターバル (分) | 分析(有無) |
|---|---|---|---|
| start-1 | stable 90, canary 10 | 無限 | 無 |
| 2-3 | stable 80, canary 20 | 2 | 有 |
| 4-5 | stable 60, canary 40 | 2 | 有 |
| 6-7 | stable 40, canary 60 | 2 | 有 |
| 8-9 | stable 20, canary 80 | 2 | 有 |
| end | stable 100, canary 0 | – | – |
概要
- ステップ 1 ではロールアウトを一時停止することによりリリース担当者が New Relic でメトリクスを確認できる。そして問題がなければ Rollout(Promote) 、問題があれば Rollback(Undo) を手動操作で行う。
- ステップ 2 以降は canary サービスへのトラフィックを 20% ごと増やしていく。
- 各ステップ(3 5 7 9)はインターバル 2 分間で、その間 30 秒間隔で分析を繰り返す。
- 各ステップでの分析の最大失敗数は 2 回である。(Dry Run モードであるため最大に達してもロールバックは発生しないが、全自動方式を本格導入した際の目安として設定している)
マニフェストファイルでの Rollout リソース定義と AnalysisTemplate リソース定義を以下に示します。
Rolloutリソース定義
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: test-adserver-canary-rollout
spec:
selector:
matchLabels:
app: adserver
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: adserver-deployment
strategy:
canary:
canaryService: adserver-canary-svc
stableService: adserver-stable-svc
trafficRouting:
alb:
ingress: adserver-ingress
rootService: adserver-root-svc
stableMetadata:
labels:
rolloutRole: stable
canaryMetadata:
labels:
rolloutRole: canary
analysis:
templates:
- templateName: dryrun-analysis
startingStep: 2
steps:
- setWeight: 10
- pause: {}
- setWeight: 20
- pause: {duration: 2m}
- setWeight: 40
- pause: {duration: 2m}
- setWeight: 60
- pause: {duration: 2m}
- setWeight: 80
- pause: {duration: 2m}
Rolloutリソースを定義するときの注意点
- Deployment は既存のものを参照すれば良い。
- Service は既存のものに加えて Canary 用と Stable 用を用意する必要がある。ただし、スペック定義は同じで良い。
- HPA や VPA を Deployment にアタッチしていた場合は Rollout にアタッチし直す必要がある。
AnalysisTemplateリソース定義
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: dryrun-analysis
spec:
dryRun:
- metricName: ad_return_rate
metrics:
- name: ad_return_rate
interval: 30s
successCondition: "all(result, # >= 0.95 && # <= 1.05)"
failureLimit: 2
provider:
prometheus:
address: PROMETHEUS_ADDRESS
query: |
sum by (ad_request_path) (
rate(ad_return_total{rollout_role="canary"}[30s])
)
/
sum by (ad_request_path) (
rate(ad_request_total{rollout_role="canary"}[30s])
)
/
(
sum by (ad_request_path) (
rate(ad_return_total{rollout_role="stable"}[30s])
)
/
sum by (ad_request_path) (
rate(ad_request_total{rollout_role="stable"}[30s])
)
)
AnalysisTemplateリソースを定義するときの注意点
- 分析は interval の時間間隔で繰り返し行われ、同一ステップ中に分析失敗が failureLimit に達すると通常はロールバックされる(全てのポッドが stable バージョンに戻る)。
- query のレスポンスが配列であり全ての要素に対して判定したい場合は
"all(result, # >= 閾値)"と表記する。- dryRun モードにするとたとえ分析失敗した場合でもロールアウトに影響を与えない(ロールバックされない)。分析結果は AnalysisRun に残される。
AnalysisTemplate リソース定義では PromQL で Canary ポッド(rollout_role="canary")または Stable ポッド(rollout_role="stable") のメトリクスを指定しているが、これを可能にするために PodMonitor サービスに以下の記述を加えた。
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
...
...
podMetricsEndpoints:
- port: prometheus
path: /metrics
interval: 10s
scrapeTimeout: 5s
+ relabelings:
+ - sourceLabels: [__meta_kubernetes_pod_label_rolloutRole]
+ targetLabel: rollout_role
既存のモニタリング環境と構成したカナリアリリース環境
テスト環境で試す
今回のインターンシップ期間の半ばあたりでコードフリーズがありました(年末ということで)。よって Production 環境で試すことはできなかったため、Staging 環境内に構築したテスト環境で設計したカナリアリリースの動作確認を行なった。
以下のような簡易的なリクエストパターンを作成して、実環境を模した形で試してみました。Staging 環境では実際の広告トラフィックが流れていないので通常はアドサーバポッドは 1 個ですが、カナリアリリースによって Canary と Stable のポッド数が遷移するのが分かるように 10 個に設定しました。
- テスト用のリクエストパラメータでテスト用の広告を取得するリクエスト
- 0 ~ 10 RPS のランダム性(Production 環境では数万 RPS ですがその規模は不要であるため)
結果:期待したカナリアリリースの動作を確認できました。
上:Ingress詳細画面 下:ロールアウト状況モニタリング画面
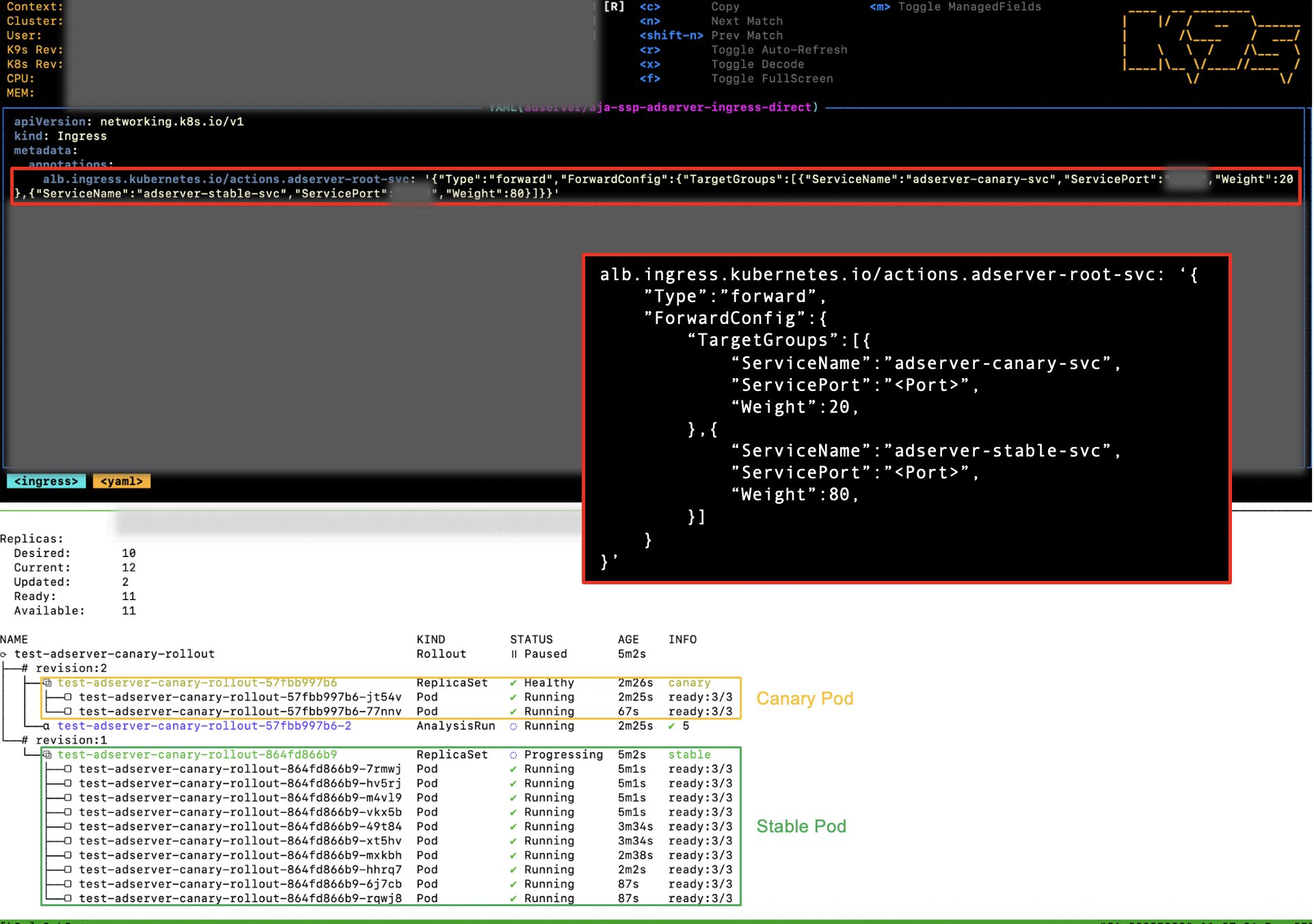
Canary および Stable 用の各サービスへのトラフィック割合は ALB のターゲットグループの Weight として設定されていることが分かります。
Canary ポッドが徐々に増えており、AnalysisRun も実行されていることが分かります。
Argo Rollouts ダッシュボード
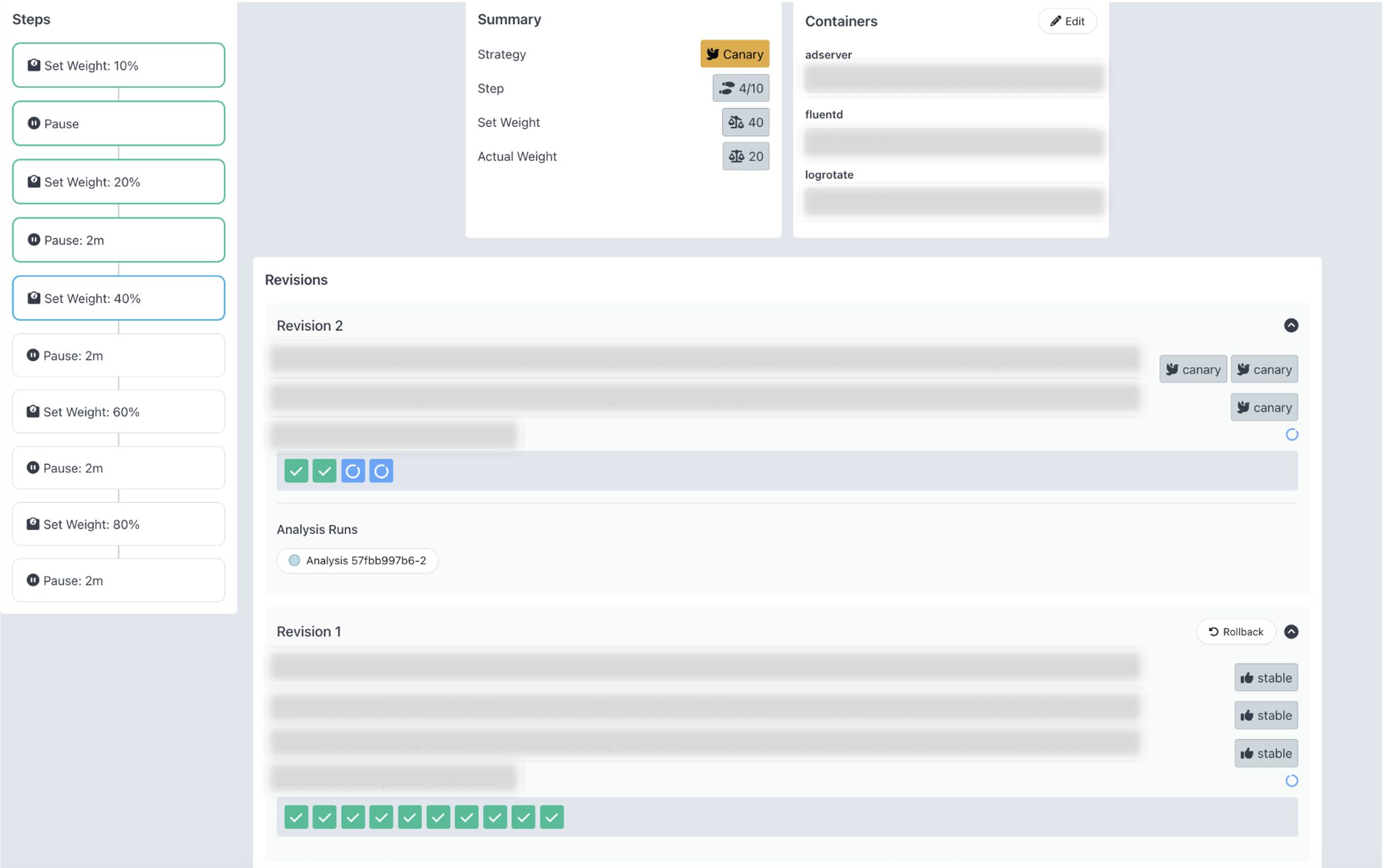
ダッシュボードでも Canary ポッドが徐々に増えていく様子を確認できました。
Pause 後、UI からロールアウトを再開する流れを確認できました。
今後の本格導入に向けて
まず、分析のパラメータチューニングがさらに行う必要があります。設定可能なパラメータについては Dry Run モードによって得た分析結果などから最適な値を見つけていくことができます。そしてある程度固まった設定で長期的に運用し、動作実績を作った上で一番理想的な全自動カナリアリリースを検討していくことができれば良いと思います。また今回はシステムメトリクス(CPU・メモリ使用率、レイテンシなど)での分析は含みませんでしたが、余裕を持った閾値に設定すると「未達であれば明らかに問題がある」というような補助的な分析は行えるので、このような追加の分析項目の検討も有効だと思います。
学んだこと
- 「なぜそうしたか」を説明できるようにすることが重要な文化なので、これまで以上に情報収集にかける時間を多くして、理由にこだわる開発ができたのが成長に繋がりました。
- 広告配信サーバの大規模トラフィックの中でエンジニアとして成長できる要素が多い開発現場だと感じた。
- 広告系サービスは他の Web サービスと比較して、開発した機能が会社の売り上げに直結しやすいことが分かりました。
- Kubernetes の機能やマニフェストの設定項目だけを見るのではなく、実装レベルでどう動いているかを考えれるようになりたいと思いました。
まとめ
今回のインターンシップではメインのタスクとして「カナリアリリースの導入」というテーマで、要件定義 – 技術選定 – 設計 – 構築 – 動作確認 という流れで取り組みました。特にチームの意思を尊重した上で自分なりの考えを持ってタスクを遂行できたことが良かったと思います。今回は Production 環境での動作を見ることは叶いませんでしたが、Argo Rollouts の仕様を詳細に調査しチームに共有したり、現状の SSP のインフラ構成にカナリアリリースのための要素を組み込むところまでを行えたのが貢献になったと思っております。
最後に、JOBインターンシップを受け入れてくださった AJA の皆さま、一緒に開発のサポートをしていただいた SSP 開発チームの皆さま、大変お世話にならせていただきました。ありがとうございました。