
はじめに
GOODROIDでUnityエンジニアをしています、及川です。
普段は基盤領域や全体設計などを担当しており、直近はAI活用の推進も担当しています。
CyberAgentでは全社でAI活用を推し進めており、弊社でも積極的なAI活用を行っています。
今回はその一環として基盤領域でのコーディング作業のAI移行を行い、そこで得られた知見を共有できればと思います。
TL;DR
- 2つのUnityクライアント基盤でSDDへの移行を試み、人間によるコーディングをゼロに。コンテキスト肥大のアンチパターンを踏んだ例と改善例を比較
- アンチパターンの主因は巨大specによる肥大化ループ。コンテキストウィンドウの7割以上占有で即コンパクション、フロー抜け→ルール追加→さらに悪化の悪循環
- 改善例ではコンテキスト効率を改善、spec分割・常駐コンテキスト最小化・マルチモデルオーケストレーション(Claude+Codex)・決定論的品質ゲート・YOLO環境を導入し、並列度と自律性が向上
- 大量PRの取り回しが新たな課題
対象読者
- AIエージェントを活用した開発に興味があるUnity / C#エンジニア
- SDD(仕様駆動開発)の導入を検討しているチームリーダー・テックリード
- Claude Code・Codex CLIなどのAIコーディングツールを実務で使い始めている方
- AI主体の開発で「思ったより上手くいかない」と感じている方
前提知識と導入背景
SDDとは
2025年頃から、Kiro や Spec Kit などが “Spec-Driven Development” を掲げ、実務でも話題に上がる機会が増えました。いわゆるバイブコーディングとは異なり、設計フェーズと実装フェーズを明確に分離することが特徴です。
- 設計フェーズ : 人間がAIと協調して要件定義(requirements)・設計(design)・タスク分解(tasks)をMarkdownで策定する
- 実装フェーズ : 策定された仕様書をAIコーディングエージェントに渡し、仕様に基づいてコードを生成する
個々のコード変更をレビューする代わりに、構造化されたフェーズゲートでレビューすることで品質を維持しつつ実装速度を上げるアプローチです。
本記事ではcc-sdd(Claude Codeを使ったSDD実践ワークフロー)をベースとしたワークフローを使用しています。
基盤領域で試した理由
SDDをいきなりプロダクトに導入することには抵抗があったため、まずは基盤領域で試すことにしました。
基盤領域はほぼ一人で作成しており、コミュニケーションやチーム運用のコストが回避可能で、SDD活用に集中しやすい環境でした。
また、既存コードや実装経験から精度の高い仕様ドキュメントを生成できる見込みがあった点も採用の理由です。
アンチパターンを踏んだ例
SDD初採用の基盤案件として、社内の画面遷移基盤iScreenで検証を始めました。
成果としてAI主体の開発環境への移行は実現できましたが、巨大specに端を発するアンチパターンを踏み抜き、多くの課題に直面しました。
アンチパターン : コンテキスト肥大化ループ
巨大なspecと複雑なワークフローによりAI挙動の精度が低下し、改善するためさらにコンテキストを積み上げていく負のループが発生しました。
基盤と改修の概要
Unityタイトルでよく見られる画面遷移基盤です。
prefab/sceneをScreenという単位に隠蔽し、演出付きの遷移、バック、それに伴うイベント発火・固有データ受け渡し、どのScreenからでもAppが起動できるなどの機能を提供します。
今回は直近タイトルリリースのために積んだ技術的負債の返済と、テスタビリティの拡充、Unityレイヤーの切り離しなど実装主導をAIに委ねるための改修を行いました。
規模感は以下の通りです。
- ファイル数: 31ファイル
- 総行数: 4,040 行
- 型定義数: 48 型
SDD構成
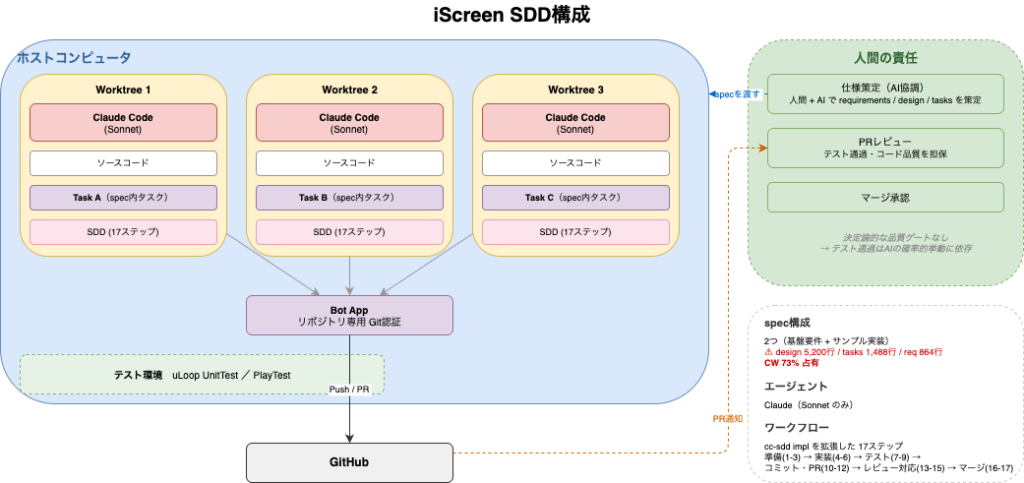
- ベースはcc-sddを使用しています
- spec-implを拡張し、実装後のセルフレビュー、MCPによるレビュー待機、レビュー対応などを追加しました
- 人の責任は、ドキュメントの策定と上がってくるPRをレビューし、テスト通過・コード品質を担保することです
ワークスペースの構成
- ホストコンピュータ上でgit worktreeを3つ作成しています
- gitはリポジトリ専用のbot Appを用意し、最小権限で操作しています
エージェント・テスト環境
- エージェントはClaude Code(Sonnetのみ)を使用しています
- テスト環境はuLoop接続でEditorTestを回しています。サンプルはPlayTestです
spec構成
- specは2つで、基盤要件とサンプル実装に分かれています
spec-implの拡張
17ステップに拡張して、コマンド実行後マージされるまで実装を委任する形にしています。
| # | ステップ | 概要 |
|---|---|---|
| 1 | Bot認証確認 & 開始時刻記録 | 認証チェックと作業開始の記録 |
| 2 | ブランチ作成 | タスク用の作業ブランチを作成 |
| 3 | 設計仕様レビュー | specの内容を確認・理解 |
| 4 | 実装 | specに基づくコード実装 |
| 5 | 自動検証 | 実装結果の自動チェック |
| 6 | セルフレビュー | AI自身による実装のレビュー |
| 7 | テスト作成 | ユニットテスト・結合テストの作成 |
| 8 | 新規テスト実行 | 作成したテストの実行 |
| 9 | リグレッションテスト実行 | 既存テストの回帰確認 |
| 10 | コミット | 変更のコミット |
| 11 | 監査実行 | コード品質・実行フローの監査 |
| 12 | PR作成 | Pull Requestの作成 |
| 13 | レビュー待機(MCP) | MCPで人間のレビューを待機 |
| 14 | レビューフィードバック対応 | レビュー指摘への修正対応 |
| 15 | 修正コミット & Push | 修正内容のコミットとプッシュ |
| 16 | マージ依頼 | マージの承認を依頼 |
| 17 | マージ待機 & 後処理 | マージ完了待ちと所要時間記録 |
発生した課題
課題 1 : コンテキストの肥大化ループ
単一specでの定義により元々精度が低下しやすい状態で、SDDフローを拡張したため挙動が安定しませんでした。
改善するためにコンテキストを積んでいくとさらに悪化していくという負のループを招きました。
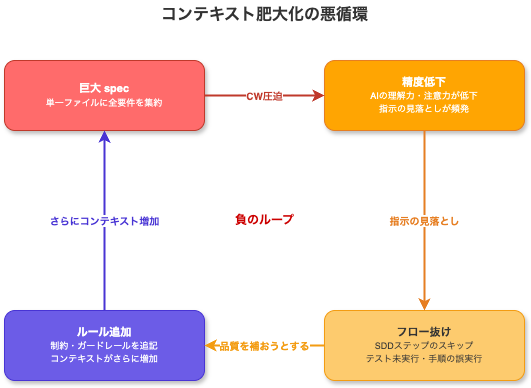
要因1 巨大spec
当時、基盤の要件をファイル分割して整合性を保てるイメージが湧かなかったことから選択しましたが、これが大きな問題となりました。
当時作成された巨大なspecの規模感は下記のとおりです。
20の機能要件が定義され、構成に必要な技術要件が網羅されている状態でした。
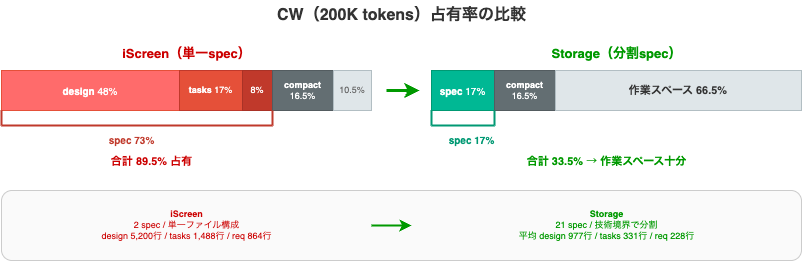
CW占有率は/contextで計測しています。
| ファイル | サイズ | 行数 | CW占有率 |
|---|---|---|---|
| tasks.md | 82KB | 1,488行 | 17% |
| design.md | 256KB | 5,200行 | 48% |
| requirements.md | 40KB | 864行 | 8% |
人間にとっては整合性の確認がしやすい形でしたが、AIが扱いやすい状態ではありませんでした。
AI側から見ると、ドキュメントだけで標準コンテキストウィンドウの73%を占有しており、auto compactionの16.5%を含めると9割近い占有率となります。
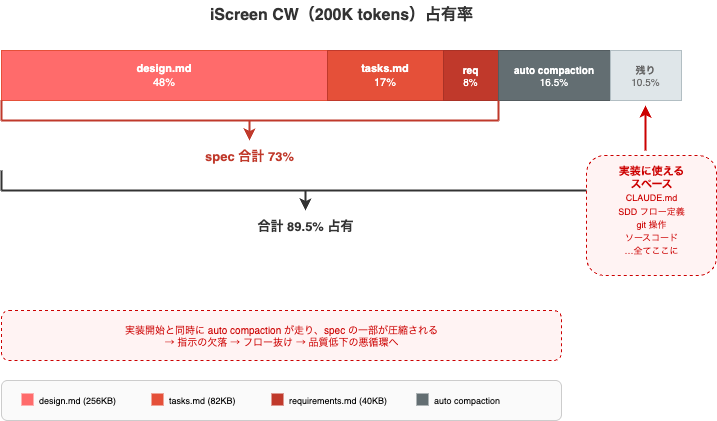
ここにrulesやCLAUDE.mdなどSDD関連のドキュメントやgit操作などのコンテキストが加わるため、実装を開始すると高頻度にコンパクションが走る状態になっていました。
要因2 過剰な実装フロー改修
前述したような高頻度なコンパクションが発生する環境でSDDのフローを実行するため、フローの抜け落ちが多発しました。
具体的には、テストの実行をスキップする、フロー途中で勝手に完了判定するなどの問題が発生しました。
その都度エージェントにフロー修正を依頼した結果、CLAUDE.mdやMEMORY、rulesが増えていく状態となりました。
開発への影響
単一責任のようなシンプルなクラスではそこまで問題になりませんでしたが、それらを結合するレイヤーでは実装品質やテストの品質が低下し、PR上で多くのコミュニケーションを必要としました。
また、体感ベースではありますが手放しでのワークフロー完遂率も低下し、並列数を増やせない要因の一つとなりました。
課題 2 : 人間のアイドルタイム
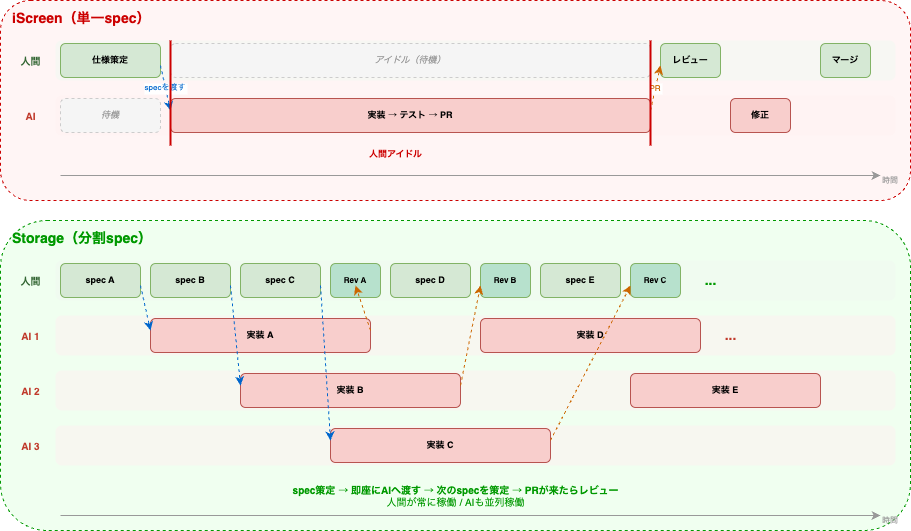
こちらも巨大specに起因しますが、仕様策定後の人間のアイドルタイムが顕著でした。
実装を待っている間にフローの改善などは行えますが限界がありました。

課題 3 : トークン消費量
コンテキストの肥大化ループが大きな要因ですが、1タスクで何度もコンパクションが発生するようなコンテキストウィンドウの状態で作業ラインを増やしたため、トークンの消費量が増大しました。
結果として、契約上のトークン消費量制約により並行数が頭打ちとなり、生産性向上へのボトルネックとなりました。
課題 4 : 品質保証の確率化
SDDのフローをカスタマイズし、実装後のリグレッションテスト工程を定義していました。
コンテキスト運用がうまくいっていない影響もありますが、フローが複雑になるほどテスト実行が確率論的な挙動となり、テストが通らないままマージされるなど実装と関係のない箇所のテストが失敗するケースが発生しました。
レビューでこれらの不整合を発見する必要があり、その工数も並行性を上げにくくする要因となりました。
課題 5 : 承認待ち
セキュリティの関係上、厳格なパーミッション設定を行っていました。
しかし、すべての必要権限を厳密な形で事前に把握することは難しく、許可待ちで作業が止まってしまうことが多々発生しました。
この課題は並列度を上げ始めてから顕著になり、こちらも並列度を上げにくくなる要因となりました。
改善した例
iScreen案件の直後に別の基盤のpure C#環境移行の案件がありましたので、
こちらでもSDDによる開発主体の移行を行い、iScreenで発生した課題の解決に取り組みました。
基盤の概要
移行した基盤はStorageというマスタデータなどを扱うデータ基盤です。
JSONからコードを生成したり、そのコードからSQLを生成してマスタデータをDBに保存したりします。
規模感は以下の通りです。
- ファイル数: 92ファイル
- 総行数: 8,145行
- 型定義数: 95型
基盤の詳細は趣旨とは異なるので省きますが、詳細はこちらを参考にして頂ければ。
SDD構成
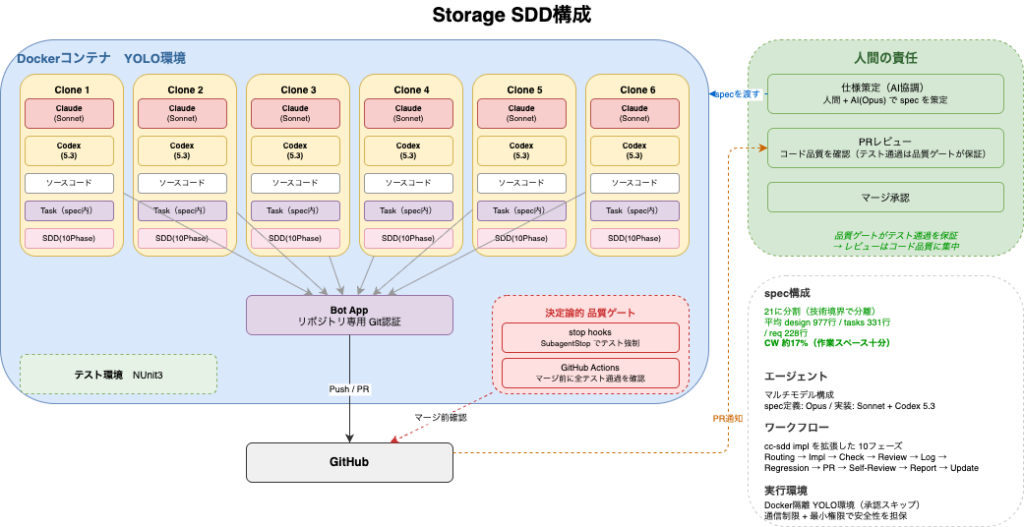
- ベースはcc-sddを使用しています
- 人の責任は、ドキュメントの策定と上がってくるPRのレビューです。テストの通過は品質ゲートによって保証されます
ワークスペースの構成
- ホストコンピュータでDockerコンテナを立てて作業ラインを6本のせています
- gitはリポジトリ専用のbot Appを用意し、最小権限で操作しています
エージェント・テスト環境
- エージェントはClaudeとCodexのマルチモデル構成で、spec定義はOpus、実行はSonnetとGPT-5.3-Codexを使用しています
- テスト環境はNUnit3です
spec構成
- specは21に分割しています
spec-implの拡張
- 拡張内容を精査して10ステップに留めています
| Phase | ステップ | 概要 |
|---|---|---|
| 1 | Task Loading & Routing | タスク読み込みとモデル振り分け |
| 2 | Implementation | Codex/Claudeによる実装 |
| 3 | Quick Design Check | 設計仕様との簡易照合 |
| 4 | Review (Quality Assurance) | 品質保証レビュー |
| 5 | Log Output | 実行ログ・状態・レビュー結果の出力 |
| 6 | Regression Test | リグレッションテスト実行 |
| 7 | PR Workflow | PR作成・FB対応 |
| 8 | Flow Self-Review | フロー自体の振り返り |
| 9 | Post-merge Report | マージ後レポート出力 |
| 10 | Task Checkbox Update | タスク完了チェック更新 |
課題に対する改善
課題 1 : コンテキストの肥大化ループ回避
まず巨大コンテキストをやめ、specを技術境界で分離しました。
合計で21のspecに分離され、平均サイズは下記のとおりとなりました。
| ファイル | 平均行数 | CW占有率 |
|---|---|---|
| design.md | 977行 | 8.9% |
| tasks.md | 331行 | 4.3% |
| requirements.md | 228行 | 4.1% |
1specセットを読んだとしても約17%の消費で、十分に作業スペースがある状態です。
また、フロー修正によるコンテキスト影響を最小化するため、常駐コンテキストの最小化も行いました。
CLAUDE.md、memory、rulesなどには原則として情報を置かず基本はplaybooksとして専用フォルダに切り出し、git-core/sdd-workflowなどのファイルを配置、作業に必要なコンテキストだけを動的に読み込むようにしています。
動的なコンテキスト生成の強制力を高めるために、プライマリルールを定義して命令強度を上げています。
プライマリルールの設定
前述したコンテキストの動的読み込みと、後述するマルチモデルオーケストレーションを活かしたCodexへの作業移譲のため、プロンプトの実行前にルーティングを行うようにしています。
プライマリルールを定義しただけでは無視されることがあるため、以下を使用して注目度を上げています。
- CLAUDE.md
- MEMORY.md
- hooks(PreCompact/UserPromptSubmit)
CLAUDE.md/MEMORY.mdにはこの30行程度のプライマリルールしか記載せずに、シンプルで守りやすいルールを構築しています。
Memoryは最初の200行だけシステムプロンプトに載る特性を利用するため活用しています。
具体的なルールは下記を定めています。
## P0-0: 実行前チェック(例外なし)
すべてのプロンプト受信時、最初に以下を確認:
- [ ] hookメッセージを確認した
- [ ] このPRIMARY_RULES.mdを読み終えた(全38行、10秒)
- [ ] 3ステップ実行の準備完了
## P0-1: ルーティングプロセス(3ステップ、例外なし)
すべてのプロンプトで例外なく必ず実行(単純な作業でも必須):
1. 作業種別判定(Git/SDD/その他)
2. Read(.claude/rules/work-routing.md) → ルーティング判断(委譲/Claude実行)
3. [Routing Check]出力 → 判定結果を明示
## P0-2: 作業種別とスコープ別ルール
SDD関連(/kiro:*)
→ Read(.claude/rules/sdd-core.md) ⚠️必須
→ 表示: ✓ スコープ別ルール読み込み: .claude/rules/sdd-core.md
Git操作(/cnb, /ccc, git commit, git push等)
→ Read(.claude/rules/git-core.md) ⚠️必須
→ 表示: ✓ スコープ別ルール読み込み: .claude/rules/git-core.md
その他
→ 追加ルールなし(PRIMARY_RULES.mdのみ適用)
→ 表示: ℹ スコープ別ルール該当なし: PRIMARY_RULES.mdのみ適用
## P0-3: 禁止事項
- 手順スキップ禁止(効率優先でのスキップも禁止)
- 早期完了報告禁止(該当スコープのルール完了前の報告禁止)これらの施策と後述するCodexへの実装・テスト移譲によりコンテキストを効率化し、先述したiScreenの例より実装タスク中のコンパクションを軽減することができました。
課題 2 : 人間のアイドルタイム
spec分割によるタイムラインの効率化を行いました。
後述するトークン消費の軽減による並行度の向上もありますが、specの単位縮小により人のアイドルタイムも軽減することができました。
課題 3 : トークン消費量
単一プロバイダによるトークン消費制限がネックだったため、複数のプロバイダを跨ぐマルチモデルオーケストレーションを導入しました。
Claudeを主体、Codexをサブとしたオーケストレーション環境を構築しています。
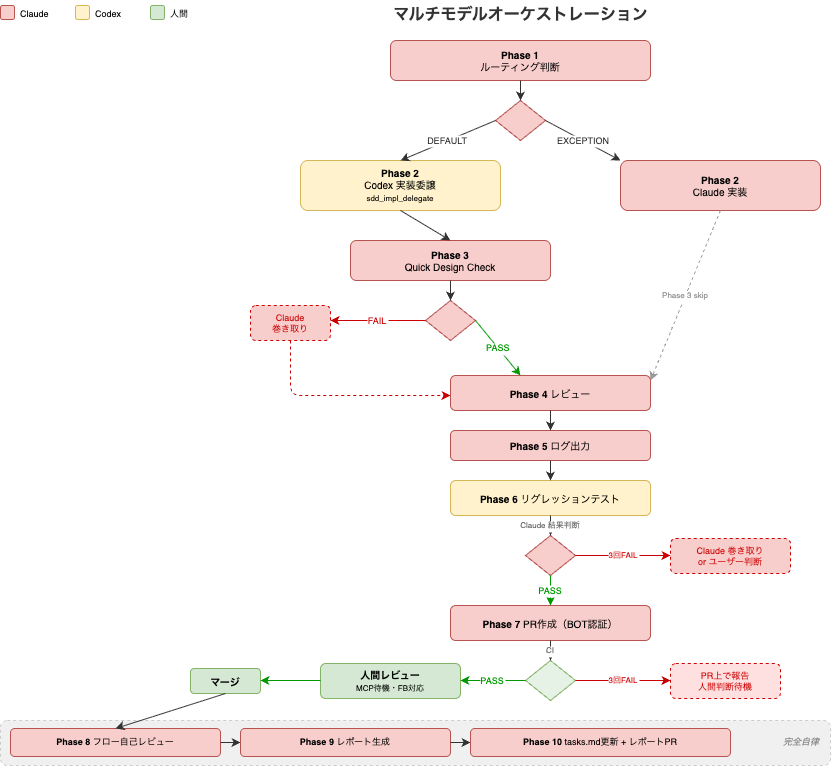
マルチモデルオーケストレーション
基本構成としてはClaude Codeをメイン、Codexをサブとして運用しています。
SDDの実装コマンドを拡張してSDDの実装や汎用作業はCodexに委譲し(実装・テスト作成フローを一括移譲)、実装後の仕様適合確認レビューはClaudeが担当します。
何度かCodexが実装失敗するかリグレッションテストが落ちるとClaude Codeが作業を巻き取り実装します。
連携方法
Codex CLIはshellからの呼び出しをskill化して使用しています。
成功時と失敗時は下記のようなjsonを返しています。
失敗時のみ再度Codexにリクエストを投げ、ログを元に修正方針をClaudeに返すようにしています。
成功時
result: タスク出力tokens.tokens_used: Codex API経由でCodexのモデルが使用したトークン数run_dir: ログディレクトリパス
失敗時
exit_code: 終了コードtokens.tokens_used: Codex API経由でCodexのモデルが使用したトークン数run_dir: ログディレクトリパスcodex_suggestion: Codexが提案する修正方法
マルチモデルならではの問題
コンテキストの分断が発生するため、specの内容からCodexに渡すプロンプトをClaude側で生成しています。
Claudeは比較的曖昧なニュアンスでも応答してくれますが、Codexは厳格な指示が必要な印象です。
そのため、特性を考慮したプロンプトを作成するSkillを作成して使用しています。
汎用作業の依頼用のSkillとspecやsteeringを巻き込んだSDD実装用のSkillがあり、
SDD用の方はkiro:implから指定して関連付けています。
Claude Codeの効率化バイアス
Claude自体が効率化のために様々な理由をつけてCodexへの移譲を避けて来ることがあり、この挙動は完全に抑えることはできていません。
トークンの使用量・タスクの移譲の判断、Codex出力コードへのレビュー結果など作業ログとして吐き出しておき、
並行作業枠が開き次第改善項目が無いかログベースの動向チェックを行なって都度改善していく形をとっています。
課題 4 : 品質保証の確率化、フローが複雑になるほどテストが漏れる
この課題の要因はコンテキストの品質もあるのですが、根本的な原因は品質の保証を確率論的な動きをするエージェントに任せたことです。
対応するため決定論的品質ゲートの設置で対応しました。
- stop フック
- GitHub Action
テスト項目をdesignで人と共に確定させた上で、hooksのSubagentStopとGitHub Actionによるマージ前確認ですべてのテストケースを通すことにより、決定論的な品質ゲートを構築しました。
これにより、テストが通過しているかをPR上のコードや実装ログで確認する必要がなくなり、レビューコストの削減につながりました。
課題 5 : 並列化に伴う承認待ち
隔離されたYOLO環境を導入することで、承認待ちを解消するとともに、開発環境からの情報漏洩リスクも軽減することができました。
DockerやClaude Codeから隔離環境は提供されていますが、マルチモデルに対応していなかったり独自に通信制限を行いたかったので環境は自前で整備しました。
YOLO環境の構築
コンテナ内に入って Claude Code を `–dangerously-skip-permissions` 付きで起動し、許可プロンプトによる待ちを最小化して作業します。
(本記事では便宜上、このような「隔離環境の上で、許可待ちを極力減らして自律性を上げる」運用を “YOLO環境” と呼びます。※Codex CLI の `–yolo` フラグとは別概念です)
- Claudeは
--dangerously-skip-permissions - Codexは
-a never -s danger-full-access
コンテナ内に入ってClaudeをYOLOモードで起動し作業を行います。
アカウント類はAI作業専用で用意し、権限を最小権限に絞っています。
コンテナ構成
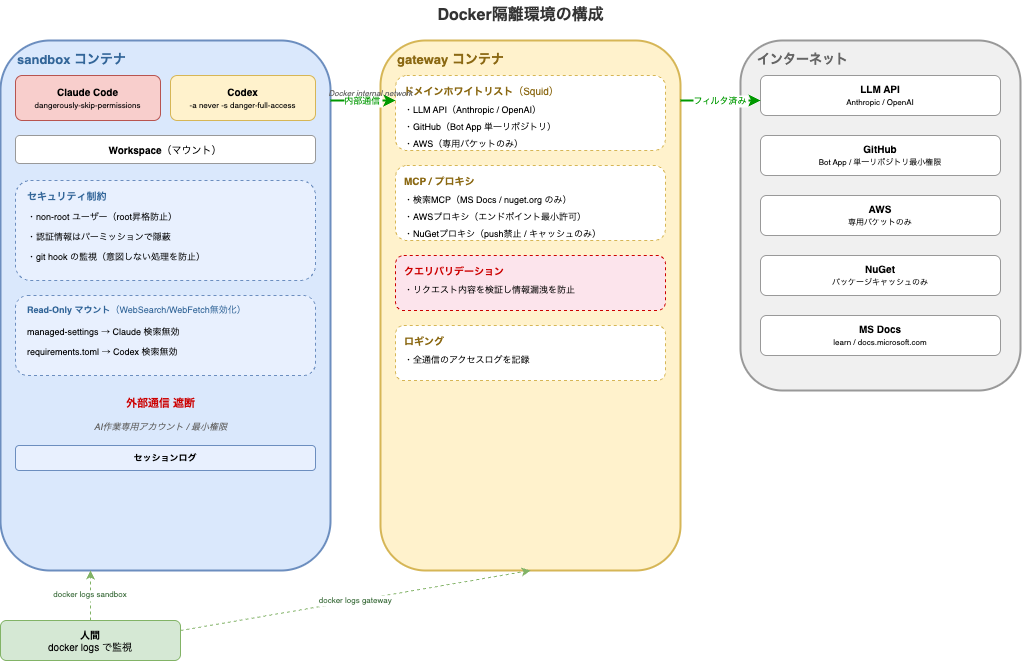
開発環境のsandboxコンテナと通信プロキシのgatewayによる二段構成です。
マウントしたワークスペースのgit hookに意図しない処理を仕込まれるなど、色々と警戒しつつ
root昇格を防いだ上で、認証情報等をパーミッションで隠す形で組んでいます。
通信制限
機密情報の漏洩を警戒して、sandboxは外部通信を遮断し、通信・検索の代行はgatewayが担当します。
sandbox上で実行するプロンプトに一般情報への置き換え指示を挟んではいますが、決定論的に防ぎたかったのでプロキシを介す形にしました。
最小限のドメインをSquid経由で許可
- LLM系のドメインはやむを得ず許可しています
- GitHubもドメイン単位で許可し、専用のAppを用意して単一リポジトリの最小権限に絞っています
組み込み検索系の無効化
Claude Code / Codex ともに、組み込みの WebSearch・WebFetch(または web_search)を利用すると外部情報を取り込めます。
本件では「意図しない外部送信や、プロンプトインジェクション経由のリスク」を嫌い、ツール側の検索機能を原則無効化しました。
各種設定ファイルで制約しています。
- Claude → managed-settingsで無効化
- Codex → requirements.tomlで無効化
ツールの設定によっては検索先のドメインを絞れるのですが、外部にどんなパラメータを送信するかという観点で確認したかった為無効化しています。
検索代用手段としてのMCP・プロキシ提供
作業効率を上げるための通信はプロキシ側でクエリバリデーションを行い、通信毎に都度実装して許容する仕組みを用意しています。
- 検索系MCP : learn.microsoft.com / docs.microsoft.com / nuget.orgのみ許可
- AWSプロキシ : 各サービスに対してエンドポイントベースで必要最小限の許可を設定
- NuGetプロキシ : push禁止、パッケージのキャッシュのみ許可
改善まとめ
| 課題 | iScreen(アンチパターン) | Storage(改善後) |
|---|---|---|
| 1. コンテキスト肥大化 | 巨大spec(単一design 5,200行)でCW73%占有、即コンパクション | spec21分割(平均design 977行)でCW約17%、作業スペース確保 |
| 2. 人間のアイドルタイム | 単一specで設計→実装完了まで長い待ち時間 | spec分割+並列度向上で、実装中に次のspec策定が可能 |
| 3. トークン消費 | 肥大CWで頻繁なコンパクション、並列数が頭打ち | マルチモデル(Claude+Codex)で実装トークン効率アップ、Opus利用も可能に |
| 4. 品質保証の確率化 | フロー複雑化でテスト漏れ、レビュー負荷増大 | stop hooks+GitHub Actionによる決定論的品質ゲート、レビューコスト削減 |
| 5. 承認待ち | 厳格パーミッションで実装停止、並列度が上げにくい | Docker隔離YOLO環境で承認スキップ、通信制限+最小権限で安全性を担保 |
新たな課題
開発インフラの導入・運用ハードルが高い
Dockerによる隔離環境の構築は、CIに関わらないUnityエンジニアにとってあまり馴染みのないスキルセットです。
そのためメンバー全員が適切な隔離環境を構築・運用できる状態にするのは多少ハードルがあるように感じました。
この領域はDocker公式で動きがあるため、解決は時間の問題かもしれません。
また、要件によっては公式提供のdevcontainerがあるのでそちらも検討です。
大量PRの取り回し
SDDだけという話ではないと思いますが、並行数や効率を上げるほど大量のPRが発生し、人間側のレビューがボトルネックになりました。
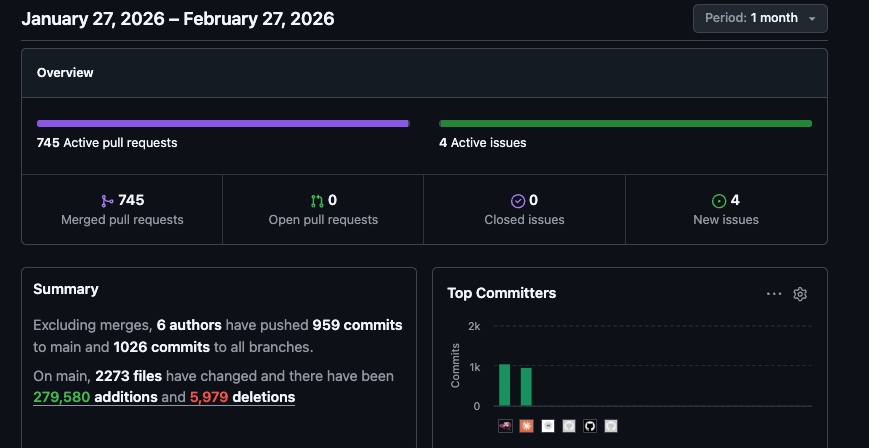
| カテゴリ | MERGED | CLOSED | 合計 | 割合 |
|---|---|---|---|---|
| タスクの実行 | 251 | 18 | 269 | 34.1% |
| ステータスの更新 | 364 | 10 | 374 | 47.3% |
| フローの改善 | 68 | 5 | 73 | 9.2% |
| その他 | 62 | 12 | 74 | 9.4% |
| 合計 | 745 | 45 | 790 | 100% |
※その他はSDD外での改修やリファクタリングなどが含まれます。
ステータス更新は自動マージなので、手動でレビュー・対応を行ったのは一ヶ月に426件(MERGED 381件 + CLOSED 45件)になります。
今回の改修案件では作業者が一人、元となるコードが存在する、改修要件が明確であるなどの条件が重なったため捌き切ることができましたが、AIによる仕分けなどうまく捌く方法が必要になって来そうです。
まとめ
両基盤における開発主体のAI移行で発生したアンチパターンとその改善についてご紹介しました。
改めて整理すると、今回の事例から得られたSDD活用における重要なポイントは以下のとおりです。
- specの粒度が最重要 : 巨大な単一specはコンテキスト肥大化の根本原因です。技術境界での分割が並列度・品質・コスト効率の全てに好影響をもたらします
- 品質保証は決定論的に : エージェントの確率論的な挙動に品質を委ねるのではなく、hooksやCIによるゲートで決定論的に担保することが重要です
- 常駐コンテキストは最小限に : CLAUDE.mdやrulesへの情報集積はコンテキストを圧迫します。動的読み込みの仕組みとセットで設計することを推奨します
- マルチモデルはスループット最適化の有効な手段 :モデル特性を踏まえた役割分担により、品質を落とさずに並列度と実行効率を引き上げられます。
- YOLO環境は“安全な権限最大化”のための基盤 :コンテナ隔離・最小権限・通信制限を前提に権限を広く委譲することで、AIの実行可能範囲を拡張しつつ、精査性と自律性を高められます。
今後は大量PRの取り回しを効率化し、チームへの展開も検討していきたいと考えています。
本記事がAIエージェントを活用した開発の一助となれば幸いです。