
AI事業本部 アドテクカンパニー Dynalystに所属している平田聡一朗と申します。本記事ではStrimziを用いてKubernetes上でKafkaを構築し、MySQLからSnowflakeへのデータ連携を実現したCDC(Change Data Capture)基盤の導入事例を共有します。
1.背景
DynalystではアプリケーションログをSnowflakeに送信し分析業務で活用していましたが、Aurora MySQLに保存されたデータも分析に使いたい要望がありました。これまでは下図のようにSnowflakeのExternal Function経由でAWS Lambdaを読み出し、Aurora MySQLのデータを取得する構成でした。この構成ではSnowflakeのViewからAurora MySQLのデータをTableのように扱うことができました。しかしAurora MySQL側のデータ量が多いテーブルではLambdaのレスポンスサイズ制限(6MB)に引っかかり、データを取得できない問題が発生しました。この問題を解決するため、リアルタイムに近い形でデータ量が多いテーブルをSnowflakeに同期するCDC基盤の構築が必要となりました。

2.技術選定
2-1.判断軸と要件
- コスト: CDC基盤は常時稼働が前提となるため、定常的なコストを抑えられる構成を要件としました。
- 運用負荷: リソースが限られているため、運用作業の負担が少ないことを要件としました。
- 同期頻度の制御性: テーブルごとに同期頻度の要件が異なるため、テーブル単位で制御できることを要件としました。
- データ整合性: INSERT/UPDATE/DELETEのすべての操作をSnowflakeに正確に反映できることを要件としました。
2-2.検討したソリューション
AWS DMS + S3 + Snowpipe
AWSのフルマネージドで完結できるため運用負荷は低く、コミュニティでの実績事例で参考になる情報が多いです。しかしレプリケーションインスタンスの料金は同等スペックのEC2インスタンスの料金と比較して割高な料金体系であり、CDC基盤において常時稼働のコストがかかり円安の影響を受けやすいと判断し、採用を見送りました。
Amazon MSK + MSK Connect + Debezium
AWSが提供するマネージドKafkaサービスであるAmazon MSKとMSK Connectを組み合わせることで、Debeziumをコネクタープラグインとして利用し、Aurora MySQLのバイナリログを読み取るCDC基盤を構築できます(参考)。しかしMSKプロビジョンドのブローカーインスタンスとMSK ConnectのMCU(MSK Connect Unit)単位の課金が常時発生するため、AWS DMS同様に常時稼働のコストがかかり円安の影響を受けやすいと判断し、採用を見送りました。
Snowflake Openflow(BYOC/SPCS)
Snowflake OpenflowとはSnowflakeが提供するCDC機能で、BYOC(Bring Your Own Cloud)とSPCS(Snowpark Container Services)の方式があります。Snowflakeの機能だけでCDC基盤を構築できる点は魅力ですが常時稼働のコストがかかります。具体的にBYOCはSnowflakeが用意したCloudFormationを利用して自身のAWS環境にEKSを構築し、そこからAurora MySQL等のデータソースに接続する方式ですが、EKSやNAT Gatewayなどのリソースは自前で管理する必要があり、データ量が少ない場合でも起動時間に応じたコストが発生してしまいます(参考)。 SPCSはそのインフラ管理をSnowflakeに委ねる方式で運用負荷はさらに低くなりますが、Openflow制御プール(Openflowのデプロイメントの管理を担うリソース)がアクティブな間はコストが発生し、ランタイム(コネクタが実際に動作してデータを処理する実行環境)利用時にはその分のコストも加算されてしまいます(参考)。また、Aurora MySQLをプライベートサブネットに配置している場合はNLBやプロキシサーバーのコストも発生します(参考)。以上の理由からどちらの方式でもコストがかかりやすいと判断し採用を見送りました。
SaaS(Fivetran・Airbyte・Troccoなど)
環境構築が不要でサポートも充実していますが、いずれも利用規模や必要機能に応じてコストが増加しやすいです(Fivetran料金・Airbyte料金・Trocco料金)。また標準プランでも基本的なスケジュール設定は可能ですが、Fivetranは1分間隔の同期にEnterprise以上のプランが必要(参考)、AirbyteのCloud版は最短1時間が下限(参考)、TroccoはCRON式のような時刻指定ができず4パターンに限定されるなど(参考)、細かい制御には制約が生じてしまうため採用を見送りました。
Debezium + Kafka on Kubernetes(Strimzi)
管理するコンポーネントが多く構成の理解にキャッチアップが必要ですが、今回検討したどのソリューションもチームにとって新規導入となるため、キャッチアップコストに大きな差はないと判断しました。コストに関して、bidやadサーバーなどの主要アプリケーションはサイバーエージェントのプライベートクラウドであるCycloudが提供するKubernetes環境(AKE)でデプロイされており、そのインフラをそのまま活用できるためインフラコストを最小限に抑えられます。運用負荷に関して、KafkaをCNCFのIncubatingプロジェクトであるStrimziを利用することで、Kubernetesのマニフェストで宣言的に管理できるため、バージョンアップや設定変更もマニフェストで対応でき、運用がシンプルに保つことができます。同期頻度の制御性に関して、DebeziumがDBのバイナリログを読み取ることで変更を検知しKafkaトピックに配信し、SnowflakeではテーブルごとにTaskのスケジュールを設定できるため、同期頻度をテーブル単位で制御できます。データ整合性に関して、DebeziumはINSERT/UPDATE/DELETEの操作を変更イベントとしてKafkaトピックに配信し、SnowflakeではStream + TaskによるMERGE INTO処理でこれらの操作を正確に反映できます。
このように4つの判断軸において要件を満たしていることに加え、OSSによるベンダー非依存、円安の影響を受けにくい、将来的にpub/subアーキテクチャへ横展開できる拡張性を総合的に評価し、Debezium + Kafka on Kubernetesを採用しました。
3.アーキテクチャ
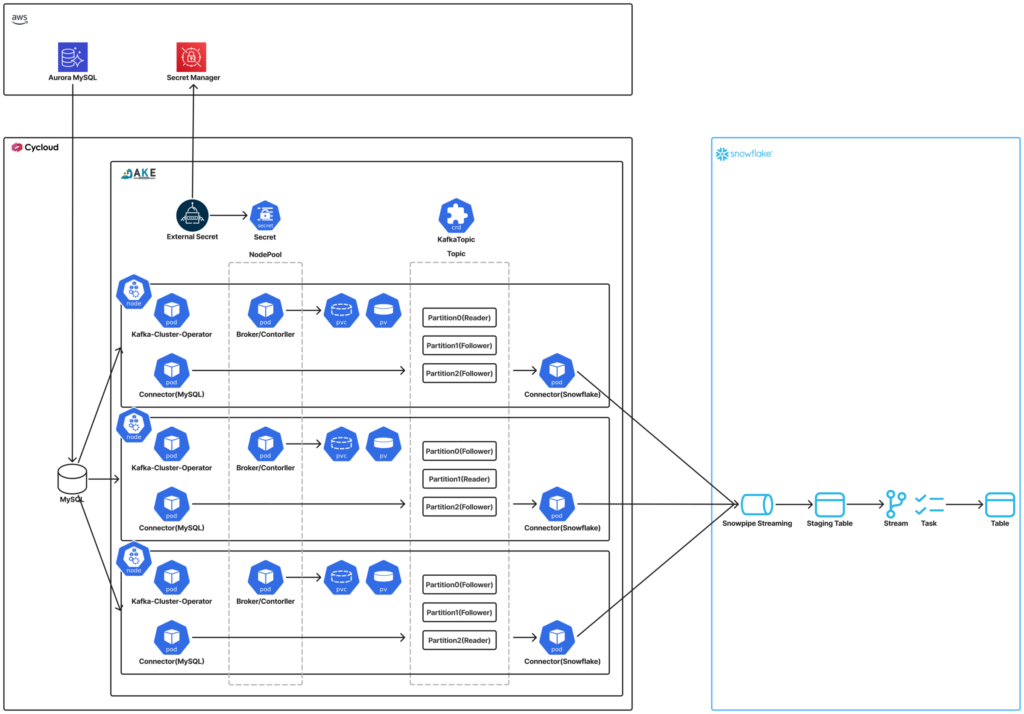
今回構築したアーキテクチャは下図のようにDebeziumがMySQLのバイナリログを読み取り、KafkaとSnowflake Kafka Connectorを経由してSnowflakeにデータを同期する構成です。
- シークレット管理: AWS Secrets ManagerにMySQL・Snowflakeの認証情報を保管し、External SecretsがKubernetesのSecretとして同期します。これによりマニフェストに認証情報を記述することなく管理しています。
- MySQL構成: Aurora MySQLをプライマリ、Cycloud上のMySQLをレプリカとしたレプリケーション構成を組んでいます。KafkaはAKE上で動作しているため、Cycloud内のMySQLのバイナリログを参照する構成としています。
- Kafka構成: KafkaはStrimziによってAKE上で構築します。主なコンポーネントは以下の通りです。
- Kafka: Kafkaクラスター全体を管理する中心的なリソースです。レプリケーション係数やリスナー設定などクラスター全体の設定を定義します。
- KafkaNodePool: ノードグループを定義するリソースです。各ノードはBroker(メッセージの受け渡し)とController(クラスターのメタデータ管理)を共存させており、Affinityにより異なるノードに分散配置することで耐障害性を確保しています。
- KafkaConnect: MySQLおよびSnowflakeとの接続を担うプラグインの実行環境です。Debezium MySQL ConnectorとSnowflake Sink Connectorをビルド機能でカスタムイメージに組み込みPod上で動作させています。
- KafkaConnector: Kafka Connect上で動作するコネクタの設定を定義するリソースです。Debezium MySQL Connectorはバイナリログから読み取ったイベントをKafkaトピックに配信し、Snowflake Sink ConnectorはそのイベントをSnowflakeのステージングテーブルに書き込みます。
- KafkaTopic: トピックを定義するリソースです。パーティション数・レプリカ数・保持期間などの設定を管理します。CDCデータトピックのほか、Connectorのオフセットやステータスなど内部管理に必要なトピックもすべてマニフェストで管理しています。
- Snowflake側構成: Snowflake Sink ConnectorはトピックのメッセージをそのままSnowflakeテーブルに追記するのみで、更新・削除の反映には対応していません(参考)。そこでステージングテーブルでイベントをいったん受け取り、Stream + TaskによるMERGE INTO処理でINSERT/UPDATE/DELETEを本テーブルに反映する構成としています。Taskのスケジュールはテーブルごとに設定できるため、同期タイミングをテーブル単位で制御できます。
4.構築手順
4-1.AWS設定
KafkaConnectのビルド機能でカスタムイメージをプッシュするためのECRリポジトリ(kafka-connect-debezium)をTerraformで作成します。あわせてKafkaConnectがイメージをプッシュ・プルできるよう、ECRへの権限を持つIAMユーザーを作成します。このIAMユーザーのアクセスキーとシークレットキーは4-4のSecret設定でSecrets Managerに登録します。
resource "aws_ecr_repository" "kafka_connect_debezium" {
name = "kafka-connect-debezium"
image_scanning_configuration {
scan_on_push = true
}
}4-2.MySQL設定
Debezium専用ユーザー作成
Debezium用ユーザーを作成します。SELECT, RELOAD, SHOW DATABASESは初期スナップショット取得に必要な権限で、REPLICATION SLAVE, REPLICATION CLIENTはバイナリログの読み取りに必要な権限です(参考)。
-- ユーザー作成
CREATE USER 'debezium'@'%' IDENTIFIED BY '<password>';
-- 必須権限の付与
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium'@'%';バイナリログ有効化
Debeziumはバイナリログを読み取る必要があるため、log_binパラメータでバイナリログの有効化、Debeziumが行レベルのイベントのみサポートしているためbinlog_format = ROW、変更前後の全カラム値を取得するためにbinlog_row_image = FULLの設定が必要になります(参考)。
SHOW VARIABLES LIKE 'log_bin'; -- ON
SHOW VARIABLES LIKE 'binlog_format'; -- ROW
SHOW VARIABLES LIKE 'binlog_row_image'; -- FULLGTID有効化
GTIDも有効化しておきます。Debeziumにおいて必要な設定ではありませんが、動作確認の項目で説明するIncremental Snapshotの実行で必要になります(参考)。
SHOW VARIABLES LIKE 'gtid_mode'; -- ON
SHOW VARIABLES LIKE 'enforce_gtid_consistency'; -- ON4-3.Snowflake設定
Snowflake Sink ConnectorはKafkaトピックへの追記のみ対応しており、更新・削除をSnowflakeテーブルに直接反映できません。そのためステージングテーブルでイベントをいったん受け取り、Stream + TaskによるMERGE INTO処理でINSERT/UPDATE/DELETEを本テーブルに反映する構成としています。ステージングテーブルのカラム構成やVARIANT型を採用した理由については後述のSnowflake Sink Connectorの設定箇所で説明します。各リソースはTerraformで管理しています。
ステージングテーブルと本テーブルはKafkaConnector起動前に事前作成する必要があります。Streamはソーステーブルへの変更をオフセットで管理しており、Streamの作成時点以降に発生した変更のみを検知します(参考)。そのためKafkaConnectorでステージングテーブルを自動作成した場合、テーブル作成後にStreamを作成することになり、KafkaConnector起動直後に実行される初回スナップショットのINSERTがStreamに検知されず、本テーブルへ反映できません。これを防ぐためにConnector起動前にステージングテーブルとStreamを事前作成しています。
ステージングテーブルにはRECORD_METADATAとRECORD_CONTENTの2カラムを定義します。本テーブルにはMySQLに対応したカラムを定義します。
resource "snowflake_table" "sample_table_staging" {
database = var.database
schema = var.schema
name = "SAMPLE_TABLE_STAGING"
change_tracking = true # Streamの作成に必要
column {
name = "RECORD_METADATA"
type = "VARIANT"
nullable = true
}
column {
name = "RECORD_CONTENT"
type = "VARIANT"
nullable = true
}
}
resource "snowflake_table" "sample_table" {
database = var.database
schema = var.schema
name = "SAMPLE_TABLE"
column {
name = "ID"
type = "NUMBER(38,0)"
nullable = false
}
column {
name = "NAME"
type = "VARCHAR(100)"
nullable = true
}
column {
name = "CREATED_AT"
type = "TIMESTAMP_NTZ"
nullable = true
}
column {
name = "UPDATED_AT"
type = "TIMESTAMP_NTZ"
nullable = true
}
}
resource "snowflake_stream_on_table" "sample_table_stream" {
database = var.database
schema = var.schema
name = "SAMPLE_TABLE_STREAM"
table = snowflake_table.sample_table_staging.fully_qualified_name
append_only = true # ステージングテーブルへの書き込みはINSERTのみのためappend_onlyモードで効率化
}
resource "snowflake_task" "sync_sample_table" {
database = var.database
schema = var.schema
name = "SYNC_SAMPLE_TABLE"
user_task_managed_initial_warehouse_size = "XSMALL" # サーバーレスTaskとして動作
started = true
schedule {
minutes = 5
}
when = "SYSTEM$STREAM_HAS_DATA('${snowflake_stream_on_table.sample_table_stream.name}')"
sql_statement = templatefile("${path.module}/task/sync_sample_table.sql.tpl", {
target_table = snowflake_table.sample_table.fully_qualified_name
stream_name = snowflake_stream_on_table.sample_table_stream.fully_qualified_name
})
}MERGE処理ではDebeziumのイベントに含まれるopフィールドの値に応じてINSERT・UPDATE・DELETEを切り替えます。opフィールドには操作種別としてc(INSERT)・u(UPDATE)・d(DELETE)・r(スナップショット取得時の既存レコード読み取り)が格納されます。イベントのJSONの具体的構造は動作確認のセクションで確認します。c・u・rをUPSERT対象としているのは、スナップショット取得時のREADイベントも本テーブルへの反映対象に含める必要があるためです。DELETEイベントではafterフィールドがnullになるためCOALESCE(after:id, before:id)でIDを取得しています。タイムスタンプはDebeziumがエポックミリ秒で出力するためTO_TIMESTAMP_NTZ(... / 1000)で変換しています。なおこの変換はMySQLカラムがDATETIME型であることを前提としています(参考)。TaskのスケジュールとKafkaへの書き込みタイミングによっては同一レコードへの複数イベントが含まれる場合があるため、QUALIFY ROW_NUMBER()で最新イベントのみを抽出しています。
-- sync_sample_table.sql.tpl
MERGE INTO ${target_table} target
USING (
SELECT
COALESCE(RECORD_CONTENT:after:id, RECORD_CONTENT:before:id)::NUMBER(38,0) AS ID,
RECORD_CONTENT:after:name::VARCHAR(100) AS NAME,
TO_TIMESTAMP_NTZ(RECORD_CONTENT:after:created_at::NUMBER / 1000) AS CREATED_AT,
TO_TIMESTAMP_NTZ(RECORD_CONTENT:after:updated_at::NUMBER / 1000) AS UPDATED_AT,
RECORD_CONTENT:op::VARCHAR(1) AS OP,
RECORD_CONTENT:ts_ms::NUMBER AS TS_MS,
RECORD_CONTENT:source:pos::NUMBER AS BINLOG_POS
FROM ${stream_name}
QUALIFY ROW_NUMBER() OVER (
PARTITION BY COALESCE(RECORD_CONTENT:after:id, RECORD_CONTENT:before:id)
ORDER BY RECORD_CONTENT:ts_ms DESC, RECORD_CONTENT:source:pos DESC
) = 1 ) source
ON target.ID = source.ID
WHEN MATCHED AND source.OP = 'd' THEN DELETE
WHEN MATCHED AND source.OP IN ('c', 'u', 'r') THEN UPDATE SET
target.NAME = source.NAME,
target.CREATED_AT = source.CREATED_AT,
target.UPDATED_AT = source.UPDATED_AT
WHEN NOT MATCHED AND source.OP IN ('c', 'u', 'r') THEN INSERT (
ID, NAME, CREATED_AT, UPDATED_AT
) VALUES (
source.ID, source.NAME, source.CREATED_AT, source.UPDATED_AT
);4-4.Secret設定
ECR認証情報
4-1で作成したECRへの権限を付与したIAMユーザーのアクセスキーとシークレットキーをSecrets Managerに登録し、ExternalSecretでKubernetesのSecretとして同期します。ECRの認証トークンは12時間で失効するため、トークンを5分ごとに再生成するCronJobを設定しています。CronJobのマニフェストは詳細を割愛しますが、ここで作成されるSecret(ecr-token)はKafkaConnectの設定で参照します。
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: ecr-aws-secret
spec:
secretStoreRef:
kind: ClusterSecretStore
name: aws-secret-store
data:
- remoteRef:
key: ecr-aws-access-keys # Secrets ManagerのキーID
property: access-key-id # 取得するプロパティ
secretKey: AWS_ACCESS_KEY_ID # Kubernetes Secret上のキー名
# AWS_SECRET_ACCESS_KEYも同様に同期MySQL・Snowflake認証情報
MySQLはホスト・ポート・ユーザー名・パスワード、Snowflakeは接続URL・ユーザー名・秘密鍵・パスフレーズ・データベース・スキーマ・ロールをそれぞれSecrets Managerに登録しています。ECR認証情報と同様にExternalSecretでKubernetes Secretとして同期しており、それぞれmysql-credentials・snowflake-credentialsという名前でSecretを作成します。これらはKafka Connectorの設定で参照します。
4-5.Kafka設定
Strimzi Kafka Operatorのインストール
Kafkaクラスターを構築する前にStrimzi Kafka Operatorをインストールする必要があります。チームではすでにArgoCDを導入しているため、OperatorもArgoCDのApplicationリソースとして管理しています。Helmチャートからデプロイするように定義しており、watchNamespacesでOperatorがKafkaリソースを監視する対象のNamespaceを指定しています。事前にdebezium-kafka Namespaceを作成しておきます。
kubectl create namespace debezium-kafka次にArgoCDのApplicationリソースを作成してOperatorをデプロイします。必要に応じてspec.source.helm.valuesObjectでOperatorのレプリカ数やリソースを設定できます(設定項目)。
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: strimzi-kafka-operator
namespace: argocd
spec:
source:
repoURL: https://strimzi.io/charts/
chart: strimzi-kafka-operator
targetRevision: 0.50.1
helm:
valuesObject:
watchNamespaces:
- debezium-kafka
replicas: 3
destination:
server: https://kubernetes.default.svc
namespace: debezium-kafka以下コマンドでoperatorが起動したことを確認します。
$ kubectl get pods -l name=strimzi-cluster-operator
NAME READY STATUS RESTARTS AGE
strimzi-cluster-operator-7668c9b9bb-5tvnf 3/3 Running 0 16dConfigMap作成
Strimziではロギング設定やメトリクス設定などをConfigMapで管理できます。今回はその中でもメトリクス設定をConfigMapで管理しており、KafkaおよびKafka ConnectリソースからこのConfigMapを参照することでPrometheus JMX Exporterによるメトリクス収集を有効化しています。収集対象のメトリクスの詳細は後述の監視設定の項目で説明します。
apiVersion: v1
kind: ConfigMap
metadata:
name: kafka-metrics
namespace: debezium-kafka
data:
kafka-metrics-config.yml: |
lowercaseOutputName: true
rules:
# 収集するメトリクスを定義Kafka作成
KafkaリソースはStrimziがKafkaクラスター全体を管理するための中心的なリソースで、ブローカーの設定やリスナー、メトリクス設定などを定義します。replication.factorでパーティションを3台に複製し、min.insync.replicasで書き込み成功に最低2台の同期確認を要求しているため、1台のブローカーが停止しても残り2台で書き込みを継続できます。
KafkaTopicリソースで全トピックの設定をマニフェストで管理できます。Topic OperatorがKafkaTopicリソースとKafka内部のトピック状態を常に同期するため、マニフェスト以外での自動作成を防止するためにauto.create.topics.enable: falseに設定しています。
なおKafka 4.0以降はZooKeeperが廃止されKRaftモードのみがサポートされています。後述のKafkaNodePoolでbrokerとcontrollerのロールを定義することでクラスターが構成されます。
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: debezium-kafka
namespace: debezium-kafka
spec:
kafka:
version: 4.1.1
jmxOptions: {}
listeners:
- name: plain
port: 9092
type: internal # クラスター内部からのみアクセス可能なリスナー
tls: false
config:
default.replication.factor: 3 # トピック作成時のデフォルトレプリカ数
min.insync.replicas: 2 # 書き込み成功に必要な最低同期レプリカ数
auto.create.topics.enable: false
metricsConfig: # Prometheus JMX ExporterによるメトリクスのConfigMapを参照
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-metrics
key: kafka-metrics-config.yml
entityOperator:
topicOperator: {} # KafkaTopicリソースとKafka内部トピックの状態を同期KafkaNodePoolの作成
KafkaNodePoolはKafkaクラスターを構成するノードグループを定義するリソースで、各ノードのロール・ストレージ・配置ルールを設定します。KafkaNodePoolで定義されていない設定はKafkaリソースから継承され、KafkaNodePool側で上書き可能です。
brokerとcontrollerは同一ノードに共存させています。本来は別ノードへの分離が推奨されますが、現時点ではCDC対象のテーブル数が限られているため同一ノードへの共存で問題ないと判断しています。Kafkaのメッセージデータを永続化するためPersistentVolumeClaimを使用しています。
nodeAffinityとpodAntiAffinityの2つを組み合わせてPodの配置を制御しています。nodeAffinityで専用ノードプールにのみPodがスケジュールされるよう制御し、podAntiAffinityでPodが同一のノードに重複配置されないようにしています。これにより1台のノードが停止しても残り2台でクラスターを維持できます。
チームの監視ツールにはDatadogを利用しており、Prometheus JMX Exporterが9404番ポートでメトリクスを公開し、Datadog Agentはannotationsに設定したエンドポイントからメトリクスを収集します。これにより上記のConfigMapで定義したメトリクスをDatadogで収集できます。
apiVersion: kafka.strimzi.io/v1
kind: KafkaNodePool
metadata:
name: kafka-pool
namespace: debezium-kafka
labels:
strimzi.io/cluster: debezium-kafka
spec:
replicas: 3
roles:
- broker
- controller
storage:
type: persistent-claim
class: {storageclass name}
size: 30Gi
deleteClaim: false
resources: # KafkaNodePoolのリソース設定
requests:
memory: 6Gi
cpu: "3"
limits:
memory: 8Gi
template:
pod:
metadata:
annotations:
ad.datadoghq.com/kafka.check_names: '["openmetrics"]'
ad.datadoghq.com/kafka.init_configs: '[{}]'
ad.datadoghq.com/kafka.instances: |
[{
"openmetrics_endpoint": "http://%%host%%:9404/metrics",
"namespace": "kafka",
"metrics": [".*"]
}]
affinity:
nodeAffinity: # Kafka専用ノードプールへのスケジューリングを制御
...
podAntiAffinity: # 同一物理ノードへの重複配置を禁止
...以下コマンドでKafkaとKafkaNodePoolが起動したことを確認します。
$ kubectl get kafka debezium-kafka
NAME READY WARNINGS KAFKA VERSION METADATA VERSION
debezium-kafka True 4.1.1 4.1-IV1
$ kubectl get pods -l app.kubernetes.io/name=kafka
NAME READY STATUS RESTARTS AGE
debezium-kafka-kafka-pool-az01-0 1/1 Running 0 16d
debezium-kafka-kafka-pool-az02-1 1/1 Running 0 16d
debezium-kafka-kafka-pool-az03-2 1/1 Running 0 16dKafkaTopicの作成
KafkaTopicリソースはトピックを管理するリソースです。今回の構成では以下の用途ごとにトピックを作成しています。
- Kafka Connect内部管理トピック:
connect-configs・connect-offsets・connect-statusはKafka Connectで必要な内部トピックです。コネクタの設定情報・ソースコネクタのオフセット情報・ステータス情報をそれぞれ保存します。いずれも最新状態のみ必要なためcleanup.policy: compactを設定しています(参考)。 - シグナルトピック:
debezium-signalはDebeziumへのシグナル送信用トピックで、動作確認の項目で詳細は説明しますがIncremental Snapshotなどの操作をトリガーする際に使用します。シグナルは処理後に不要となるためretention.ms: 86400000(1日)で短期間のみ保持しています(参考)。 - DLQトピック:
dlq-snowflakeはSnowflake Connectorが処理に失敗したメッセージを送るデッドレターキューです。トラブルシューティング用にretention.ms: 2592000000(30日間)で長めに保持しています(参考)。 - スキーマ変更履歴トピック:
schema-changes.<mysql schema name>はKafkaConnectorのschema.history.internal.kafka.topicで指定するコネクタ内部用のトピックです。バイナリログには「どの行が変わったか」しか記録されておらず、「そのとき列の型が何だったか」は含まれません。Debeziumはバイナリログの各イベントを正しくデコードするために、イベントが発生した時点のテーブル構造を把握する必要があります。そこでDDL文とバイナリログ上の位置をこのトピックに記録しておき、コネクタ再起動時に「どの時点でどのスキーマだったか」を再現します。コネクタ再起動時のスキーマ再構築に使用するため永久保存が必要であり、retention.ms: -1を設定しています(参考)。 - CDCデータトピック:
mysql-server.<mysql schema name>.*はDebeziumが各テーブルの変更イベントを配信するトピックで、CDC対象テーブルごとに1つ作成しています。cleanup.policy: compact,deleteで各レコードの最新状態を保持しつつ、7日間経過した古いセグメントを削除してディスク使用量を抑制しています(参考)。
KafkaTopicリソースの設定例を以下に示します。他トピックも同様の構造で、用途に応じて上述のパーティション数などを変更しています。
apiVersion: kafka.strimzi.io/v1
kind: KafkaTopic
metadata:
name: connect-configs
namespace: debezium-kafka
labels:
strimzi.io/cluster: debezium-kafka
app.kubernetes.io/name: kafka-topic
app.kubernetes.io/part-of: debezium-kafka
spec:
topicName: connect-configs
partitions: 1
replicas: 3
config:
min.insync.replicas: 2
cleanup.policy: compact 以下コマンドでKafkaTopicが作成されたことを確認します。
$ kubectl get kafkatopic
NAME CLUSTER PARTITIONS REPLICATION FACTOR READY
connect-configs debezium-kafka 1 3 TrueKafkaConnectの作成
KafkaConnectリソースはKafkaと外部システム間の連携を担うプラグインを動作させるための実行環境を定義します。これらのプラグインはKafka Connect Podの起動時にあらかじめPod内に含める必要があるため、ビルド機能を使うことでプラグインを含むカスタムイメージを自動ビルドしECRにプッシュ、それをKafka Connect Podのイメージとして使用できます。今回は以下の3つのプラグインを含むイメージをビルドしています。利用可能なプラグインはConfluent Hubで検索でき、各プラグインのJARのダウンロードURLはMaven Centralで確認できます。
debezium-mysql-connector:MySQLのバイナリログを読み取りCDCイベントをKafkaに送信snowflake-kafka-connector:KafkaのメッセージをSnowflakeに書き込むkafka-connect-secret-provider:Kubernetes Secretから設定値を読み込む
exactly.once.source.support: enabledはKafka Connectワーカー全体のソースコネクタに対してExactly-Onceを有効にする設定です。これによりDebeziumがKafkaにイベントを書き込む際にトランザクションを使用し、コネクタ再起動時のメッセージ重複書き込みを防止します。なおこの設定はソースコネクタ専用でありSnowflake Sink Connectorには作用しません。
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnect
metadata:
name: debezium-kafka-connect
namespace: debezium-kafka
annotations:
strimzi.io/use-connector-resources: "true" # KafkaConnectorリソースでコネクタを管理
spec:
version: 4.1.1
replicas: 3
bootstrapServers: debezium-kafka-kafka-bootstrap:9092 # Kafkaクラスターへの接続先のDNS名
offsetStorageTopic: connect-offsets # KafkaTopicリソースで作成したリソースを定義
configStorageTopic: connect-configs
statusStorageTopic: connect-status
build:
output:
type: docker
image: 118102704242.dkr.ecr.ap-northeast-1.amazonaws.com/kafka-connect-debezium:latest
pushSecret: ecr-token # ECR認証トークンが格納されたSecret名
plugins:
- name: debezium-mysql-connector
artifacts:
- type: tgz
url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/3.4.1.Final/debezium-connector-mysql-3.4.1.Final-plugin.tar.gz
- name: snowflake-kafka-connector
artifacts:
- type: jar
url: https://repo1.maven.org/maven2/com/snowflake/snowflake-kafka-connector/3.5.3/snowflake-kafka-connector-3.5.3.jar
- type: jar
url: https://repo1.maven.org/maven2/org/bouncycastle/bc-fips/2.1.2/bc-fips-2.1.2.jar # 秘密鍵認証に必要
- type: jar
url: https://repo1.maven.org/maven2/org/bouncycastle/bcpkix-fips/2.1.9/bcpkix-fips-2.1.9.jar # 秘密鍵認証に必要
- name: kafka-connect-secret-provider
artifacts:
- type: jar
url: https://repo1.maven.org/maven2/io/strimzi/kafka-kubernetes-config-provider/1.2.2/kafka-kubernetes-config-provider-1.2.2.jar
config:
exactly.once.source.support: enabled # DebeziumソースコネクタのExactly-Onceを有効化
config.providers: secrets
config.providers.secrets.class: io.strimzi.kafka.KubernetesSecretConfigProvider # KubernetesシークレットからConnector設定を読み込む
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-connect-metrics
key: kafka-connect-metrics-config.yml
template:
pod:
metadata:
annotations: # メトリクス収集設定
ad.datadoghq.com/debezium-kafka-connect-connect.check_names: '["openmetrics"]'
ad.datadoghq.com/debezium-kafka-connect-connect.init_configs: '[{}]'
ad.datadoghq.com/debezium-kafka-connect-connect.instances: |
[{
"openmetrics_endpoint": "http://%%host%%:9404/metrics",
"namespace": "kafka_connect",
"metrics": [".*"]
}]
affinity:
# KafkaNodePoolと同様に分散配置で耐障害性を確保
...
imagePullSecrets:
- name: ecr-token # ECR認証トークンが格納されたSecret名またKafkaConnectリソースをデプロイすると、StrimziはKafka Connect Podが使用するServiceAccount(debezium-kafka-connect-connect)を自動的に作成します(参考)。kafka-connect-secret-providerがKubernetes Secretにアクセスするために、以下のRole/RoleBindingを作成します。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: debezium-kafka-connect-secret-reader
namespace: debezium-kafka
labels:
app.kubernetes.io/name: kafka-connect
app.kubernetes.io/part-of: debezium-kafka
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: debezium-kafka-connect-secret-reader
namespace: debezium-kafka
labels:
app.kubernetes.io/name: kafka-connect
app.kubernetes.io/part-of: debezium-kafka
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: debezium-kafka-connect-secret-reader
subjects:
- kind: ServiceAccount
name: debezium-kafka-connect-connect
namespace: debezium-kafka以下のコマンドでKafka Connect Podが起動していることを確認します。
$ kubectl get pods -l strimzi.io/cluster=debezium-kafka-connect
NAME READY STATUS RESTARTS AGE
debezium-kafka-connect-connect-0 1/1 Running 0 16d
debezium-kafka-connect-connect-1 1/1 Running 0 16d
debezium-kafka-connect-connect-2 1/1 Running 0 16dDebezium MySQL Connectorの作成
KafkaConnectorリソースはKafka Connect上で動作するコネクタの設定を定義します。Debezium MySQL Connectorはバイナリログを読み取り、変更イベントをKafkaトピックに配信します。topic.prefix・database.include.list・table.include.listでCDC対象のトピック名プレフィックスおよびデータベース・テーブルを指定します。schema.history.internal.kafka.topicにはKafkaTopicセクションで作成したスキーマ変更履歴トピックを指定します。read.only: "true"を設定することでテーブルロックを使わずGTIDベースでスナップショットを取得するため、本番環境への影響を最小限に抑えられます。read.onlyとシグナル関連の設定はテーブル追加時のIncremental Snapshotに関わる設定で詳細は後述します。
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnector
metadata:
name: debezium-mysql-connector
namespace: debezium-kafka
labels:
strimzi.io/cluster: debezium-kafka-connect
spec:
class: io.debezium.connector.mysql.MySqlConnector # 使用するコネクタプラグインのJavaクラス名
config:
# MySQL接続設定(Kubernetes Secret参照)
database.hostname: ${secrets:debezium-kafka/mysql-credentials:host}
database.port: ${secrets:debezium-kafka/mysql-credentials:port}
database.user: ${secrets:debezium-kafka/mysql-credentials:username}
database.password: ${secrets:debezium-kafka/mysql-credentials:password}
database.server.id: "1001"
read.only: "true" # テーブルロックを使わずGTIDベースでスナップショットを取得
# CDC対象の設定
topic.prefix: mysql-server
database.include.list: sample_db
table.include.list: sample_db.sample_table_1,sample_db.sample_table_2
# スキーマ履歴の保存設定
schema.history.internal.kafka.bootstrap.servers: debezium-kafka-kafka-bootstrap:9092
schema.history.internal.kafka.topic: schema-changes.sample_db
include.schema.changes: "false" # DDL変更イベント配信の無効化
# Incremental Snapshot用シグナル設定
signal.enabled.channels: kafka
signal.kafka.topic: debezium-signal
signal.kafka.bootstrap.servers: debezium-kafka-kafka-bootstrap:9092
signal.kafka.groupId: debezium-mysql-signal-consumer Snowflake Sink Connectorの作成
Snowflake Sink Connectorは4-3で作成したステージングテーブルに対してKafkaトピックをマッピングしメッセージを書き込みます。メッセージはステージングテーブルのRECORD_METADATAとRECORD_CONTENTの2カラムに格納されます。RECORD_METADATAにはトピック名などのメタ情報が、RECORD_CONTENTにはDebeziumのイベント本体が格納されます。これはSnowflake Sink Connectorが書き込む際のデフォルトのスキーマです。
snowflake.enable.schematizationはKafkaメッセージのフィールドをSnowflakeのカラムとして自動展開する機能です。有効にするとメッセージ構造がそのままテーブルのカラムに対応しますが、この機能はフラットなJSON({"id": 1, "name": "foo"}のような単純な構造)を前提としています。一方Debeziumのイベントはネストした複雑な構造のため、そのままカラムに展開できません。そのためsnowflake.enable.schematization: falseに設定し、メッセージをVARIANT型のままステージングテーブルに格納した上で、Stream + TaskのMERGE処理で必要なフィールドを抽出する構成としています。key.converter・value.converterにJsonConverterを指定しているのはDebeziumがKafkaに書き込むメッセージがJSON形式であるためで、snowflake.enable.schematization: falseとセットの設定です。
snowflake.ingestion.methodにはSnowpipeとSnowpipe Streamingのどちらかを選択できます。Snowpipe Streamingはステージングにバッファリングする必要がないためレイテンシーが低く、今回のようなリアルタイムに近い同期に適していると判断し採用しております。
apiVersion: kafka.strimzi.io/v1
kind: KafkaConnector
metadata:
name: snowflake-sink-connector
namespace: debezium-kafka
labels:
strimzi.io/cluster: debezium-kafka-connect
spec:
class: com.snowflake.kafka.connector.SnowflakeSinkConnector # 使用するコネクタプラグインのJavaクラス名
tasksMax: 3 # Kafka Connectのreplicas数およびパーティション数に合わせている
config:
# Snowflake接続設定(Kubernetes Secret参照)
snowflake.url.name: ${secrets:debezium-kafka/snowflake-credentials:url}
snowflake.user.name: ${secrets:debezium-kafka/snowflake-credentials:user}
snowflake.private.key: ${secrets:debezium-kafka/snowflake-credentials:private_key}
snowflake.private.key.passphrase: ${secrets:debezium-kafka/snowflake-credentials:private_key_passphrase}
snowflake.database.name: ${secrets:debezium-kafka/snowflake-credentials:database}
snowflake.schema.name: ${secrets:debezium-kafka/snowflake-credentials:schema}
snowflake.role.name: ${secrets:debezium-kafka/snowflake-credentials:role}
# データ転送の設定
topics.regex: "mysql-server\\.sample_db\\..*" # 転送対象トピックを正規表現で指定
snowflake.topic2table.map: "mysql-server.sample_db.sample_table_1:SAMPLE_TABLE_1_STAGING,..." # トピックとSnowflakeテーブルのマッピング
snowflake.ingestion.method: SNOWPIPE_STREAMING
snowflake.enable.schematization: false # CDCイベントをVARIANT型のままステージングテーブルに格納
# メッセージのkey/valueのシリアライズ形式を指定
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
# エラーハンドリング
errors.tolerance: all
errors.log.enable: true
errors.log.include.messages: true
errors.deadletterqueue.topic.name: dlq-snowflake # DLQトピックの指定
errors.deadletterqueue.context.headers.enable: true以下のコマンドでKafkaConnectorのステータスを確認します。
$ kubectl get kafkaconnector
NAME CLUSTER CONNECTOR CLASS MAX TASKS READY
debezium-mysql-connector debezium-kafka-connect io.debezium.connector.mysql.MySqlConnector True
snowflake-sink-connector debezium-kafka-connect com.snowflake.kafka.connector.SnowflakeSinkConnector 3 True5.動作確認
5-1.データ変更の反映確認
構築した環境でMySQLへの変更がSnowflakeに反映されることを確認します。
INSERT
MySQLでレコードを挿入します。
INSERT INTO sample_table (id, name) VALUES (1, 'test');ステージングテーブルのRECORD_CONTENTカラムには、以下のjson形式のデータが格納されます(主要なキーと値以外は省略)。INSERTイベントではbeforeがnullになります。
{
"after": {
"created_at": null,
"id": 1,
"name": "test",
"updated_at": null
},
"before": null,
"op": "c",
"source": {
"connector": "mysql",
...
},
...
}Snowflakeのステージングテーブルにレコードが挿入されタスクの実行が完了すると、本テーブルにもレコードが挿入されていることが確認できます。

UPDATE
MySQLでレコードを更新します。
UPDATE sample_table SET name = 'test_updated' WHERE id = 1;ステージングテーブルのRECORD_CONTENTカラムには、以下のjson形式のデータが格納されます。UPDATEイベントではbeforeとafterの両方に値が入ります。
{
"after": {
"created_at": null,
"id": 1,
"name": "test_updated",
"updated_at": null
},
"before": {
"created_at": null,
"id": 1,
"name": "test",
"updated_at": null
},
"op": "u",
"source": {
"connector": "mysql",
...
},
...
}Snowflakeのステージングテーブルにレコードが挿入されタスクの実行が完了すると、本テーブルのレコードが更新されていることが確認できます。

DELETE
MySQLでレコードを削除します。
DELETE FROM sample_table WHERE id = 1;ステージングテーブルのRECORD_CONTENTカラムには、以下のjson形式のデータが格納されます。DELETEイベントではafterがnullになります。MERGE処理でCOALESCE(RECORD_CONTENT:after:id, RECORD_CONTENT:before:id)としてIDを取得しているのはこのためです。
{
"after": null,
"before": {
"created_at": null,
"id": 1,
"name": "test_updated",
"updated_at": null
},
"op": "d",
"source": {
"connector": "mysql",
...
},
...
}Snowflakeのステージングテーブルにレコードが挿入されタスクの実行が完了すると、本テーブルのレコードが削除されていることが確認できます。

INSERT・UPDATE・DELETEがすべて正しく本テーブルに反映されていれば動作確認完了です。なおTaskはStreamにデータが存在する場合のみ実行されるため、Taskに設定したスケジュール間隔分の遅延が発生します。
5-2.テーブル追加手順
CDC対象テーブルを追加する手順を説明します。新たにsample_table_newを追加する場合を例に説明します。
Incremental Snapshotについて
テーブルを追加する際にはIncremental Snapshotの実行が必要です。DebeziumのInitial SnapshotはConnectorの初回起動時に一度だけ実行される仕組みのため、後からtable.include.listに追加したテーブルは現在のバイナリログのポジション以降の変更イベントのみが取得され、追加時点より前の既存データは同期されません。Incremental Snapshotを使ってスナップショットを実行することで、ストリーミングを止めることなく既存テーブルに影響を与えずに新しいテーブルの全データを取得できます(参考)。なお初回構築時はConnector起動時にInitial Snapshotが自動で実行されるため、このコマンドを実行する必要はありません。
Incremental Snapshotのトリガーには構築手順で設定した以下の3点が関わっています。
- GTID有効化: 通常のIncremental SnapshotはDBへの書き込み権限を必要とします。
read.only: "true"を設定すると、DBへの書き込みの代わりにGTIDを利用する実装に切り替わるため、GTIDが有効になっている必要があります。 - KafkaConnectorのシグナル関連設定: Incremental SnapshotはKafkaのシグナルトピックにメッセージを送ることでトリガーします。
signal.enabled.channels: kafkaでKafkaをシグナルチャネルとして有効化し、signal.kafka.topic: debezium-signalで送信先のトピックを指定しています。 - シグナルトピック:KafkaTopicで作成した
debezium-signalがシグナルの送信先です。
Snowflakeリソースの作成
構築手順のSnowflake設定と同様に、ステージングテーブル・Stream・Task・本テーブルをTerraformで追加します。
KafkaConnectorの更新
新テーブル用のKafkaTopicリソースを追加します。あわせてDebezium MySQL ConnectorのKafkaConnectorリソースのtable.include.listに新テーブルを追加します。
table.include.list: sample_db.sample_table_1,sample_db.sample_table_2,sample_db.sample_table_newSnowflake Sink ConnectorのKafkaConnectorリソースのsnowflake.topic2table.mapに新テーブルのマッピングを追加します。
snowflake.topic2table.map: "mysql-server.sample_db.sample_table_1:SAMPLE_TABLE_1_STAGING,...,mysql-server.sample_db.sample_table_new:SAMPLE_TABLE_NEW_STAGING"Incremental Snapshotの実行
以下のコマンドでシグナルトピックにメッセージを送信してIncremental Snapshotをトリガーします。なおメッセージのキーはtopic.prefixの値(mysql-server)と一致させる必要があります。キーが一致しない場合、コネクタはシグナルを無視します。
kubectl exec -it debezium-kafka-kafka-0 -n debezium-kafka -- \
bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic debezium-signal \
--property "parse.key=true" \
--property "key.separator=:" <<EOF
mysql-server:{"type":"execute-snapshot","data":{"data-collections":["sample_db.sample_table_new"],"type":"incremental"}}
EOFシグナル送信後、Kafkaトピックにスナップショットイベントが流れ始めたこと、Snowflakeの本テーブルにレコードが挿入されたことを確認します。
6.監視設定
監視ツールにはDatadogを使用しており、収集するメトリクスはこちらを参考に選定しました。各メトリクスのMBean名はApache Kafka公式ドキュメントを参照しています。異常が発生した際に即時対応が必要なメトリクスのみアラートを設定し、その他はDatadogのダッシュボードを作成して定期的に確認する運用としています。
Kafkaブローカーの監視
以下の4つのメトリクスにアラートを設定しています。
kafka_controller_active_controller_count: クラスター全体で常に合計1である必要があり、1以外の値が発生した場合にアラートを設定しています。kafka_controller_offline_partitions_count: パーティションリーダーが存在しない状態はそのパーティションへの読み書きが完全に停止することを意味するため、0より大きい値でアラートを設定しています。kafka_controller_unclean_leader_elections_total: 同期が完了していないレプリカからリーダーが選出されたことを意味しデータ損失に直結するため、1以上でアラートを設定しています。kafka_server_dlq_messages_in_total: Snowflakeへの書き込みに失敗したメッセージはDLQトピック(dlq-snowflake)に送られるため、このメトリクスが増加した場合にアラートを設定しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: kafka-metrics
namespace: debezium-kafka
data:
kafka-metrics-config.yml: |
lowercaseOutputName: true
rules:
# クラスタ内のアクティブなコントローラー数。合計値が常に1である必要がある
- pattern: kafka.controller<type=KafkaController, name=ActiveControllerCount><>Value
name: kafka_controller_active_controller_count
type: GAUGE
# アクティブなリーダーが存在しないパーティション数
- pattern: kafka.controller<type=KafkaController, name=OfflinePartitionsCount><>Value
name: kafka_controller_offline_partitions_count
type: GAUGE
# データ損失を伴うリーダー選出の発生回数
- pattern: kafka.controller<type=ControllerStats, name=UncleanLeaderElectionsPerSec><>Count
name: kafka_controller_unclean_leader_elections_total
type: COUNTER
# DLQトピックへの受信メッセージ数
- pattern: kafka.server<type=BrokerTopicMetrics, name=MessagesInPerSec, topic=dlq-snowflake><>Count
name: kafka_server_dlq_messages_in_total
type: COUNTER
# 以下省略
...Kafka Connectの監視
以下の2つのメトリクスにアラートを設定しています。
kafka_connect_connector_status: コネクターの稼働状態を示すメトリクスです。値は常に1で、statusラベルにコネクターの状態が格納されます。RUNNING以外の状態になるとCDC基盤全体が止まるため、statusラベルがrunning以外の場合にアラートを設定しています。kafka_connect_connector_task_status:タスク単位の稼働状態を示すメトリクスです。値は常に1で、statusラベルにタスクの状態が格納されます。タスクが失敗するとデータの取りこぼしが発生するため、statusラベルがrunning以外の場合にアラートを設定しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: kafka-connect-metrics
namespace: debezium-kafka
data:
kafka-connect-metrics-config.yml: |
lowercaseOutputName: true
rules:
# コネクターの稼働状態
- pattern: 'kafka.connect<type=connector-metrics, connector=(.+)><>status: (.+)'
name: kafka_connect_connector_status
value: 1
labels:
connector: "$1"
status: "$2"
type: GAUGE
# タスク単位の稼働状態
- pattern: 'kafka.connect<type=connector-task-metrics, connector=(.+), task=(.+)><>status: ([a-z-]+)'
name: kafka_connect_connector_task_status
value: 1
labels:
connector: "$1"
task: "$2"
status: "$3"
type: GAUGE
# 以下省略
...ホストレベルの監視
KafkaブローカーのJMXメトリクスに加え、CPU使用率・ディスク使用率・ネットワーク転送量といったホストレベルのメトリクスも監視する必要があります。CPU使用率・ディスク使用率については一定の閾値を超えた場合にアラートを設定し、リソース枯渇による障害を未然に防ぐ運用としています。
7.まとめ
本記事ではStrimziを用いてKubernetes上にKafkaクラスターを構築し、DebeziumとSnowflake Kafka ConnectorによるMySQLからSnowflakeへのCDC基盤の導入事例を紹介しました。これによりMySQLのデータをSnowflakeに同期できるようになり、当初の課題であったLambdaのレスポンスサイズ制限の問題を解消できました。
今後CDC対象テーブルが増えていく中でKafkaのパラメータチューニングやバージョンアップなど運用面での知見も蓄積されていくと思うので、そのあたりは別途記事にまとめられればと考えています。またSnowflake Intelligenceの活用も進めており、MySQLのデータをリアルタイムでSnowflakeに同期できるこのCDC基盤によって、これまで以上に幅広い分析が可能になることを期待しています。