
はじめに
こんにちは。AmebaLIFE事業本部エンジニアのsatominです。
この記事では、ビジネス要求を起点に、要求レビューと横断設計を自律化した仕組みを紹介します。
横断設計とは、フロントエンド・バックエンド・インフラなど、複数リポジトリ・複数職種をまたぐ設計です。
AI活用が盛んな現在、単一リポジトリや職種単位での設計・実装・テストの自動化が各所で進んでいます。その中で上流工程の質が出力精度に大きく影響することも見えてきましたが、要求や横断設計に向き合っている人は身近にはまだいない状態でした。
1. 課題
要求レビューやリポジトリを横断する設計は、明確な指標がなく担当者の知識・経験・勘に依存しがちでした。暗黙知が属人化しており、状況によって考慮の深さにばらつきが生まれるため、安定した品質を出し続けることが難しい状態でした。
フェーズごとにも、具体的な課題がありました。
要求フェーズ – 要求精度/事前見積り
要求に未定義の項目が多く、設計段階での確認・ヒアリングが増え、要求の品質を高めるプロセス自体に多くの工数がかかっていました。たとえば成功時の期待値は書かれていても、失敗時の振る舞いや境界条件が未定義のまま設計に持ち込まれる、といった状況が続いていました。
また、要求が固まる前に見積りを求められることがあり、不確かな前提のもとで仮の設計を組み立てる必要がありました。こうした仮設計は実現確度とのズレが大きく、見積りの精度も下がっていました。
横断設計フェーズ – 全体像の把握不足
横断設計の際、関わる全員がサービスのアーキテクチャ全体を完璧に把握しているわけではなく、「できる」という前提で議論が進み、後工程で詳細を詰めると実現できないことが判明して上流工程に戻る、ということがありました。
運用フェーズ – ドキュメントの陳腐化/属人化と再現性
開発が進むにつれてドキュメントと実装の間に差分が生まれることは多く、既に運用されているシステムに改修が入った場合はそもそも更新されないこともよくありました。
本取り組みは、これらの課題に向き合いつつ、要求書や設計書をきちんと残す文化の醸成、レビューや設計の暗黙知の明文化による属人化の解消と組織資産化、要求・設計の品質と再現性の確保を目指して実施しました。
2. 作成した仕組みの全体像

人間(要求者)の要求起票を起点に、AIがレビューを実施します。NGなら修正を促し、要求者が修正して再レビューのサイクルを繰り返します。AIがOKと判断したら続けて横断設計PRを作成します。
人間(エンジニア)のPRレビューを受けてAIが再設計したり、要求フェーズに差し戻して要求者に修正を促したりします。エンジニアがPRを承認すると、要求書と横断設計がセットでリポジトリ管理されます。横断設計には影響するリポジトリごとの実装指示・実装順序・概算工数などが含まれます。
AIの呼び出しはGitHub Actionsのワークフローで実施しています(Claude Sonnetを使用)。
人間の関与は要求の起票・修正、設計のレビュー・承認です。
なぜ人間の承認を必要としたのか
AIが自律的に生成したものであっても、有事の際の責任は人間が負う必要があると考えています。そのため、生成物は一定の制約・品質基準を満たす必要があり、その判断のため人間の承認フローを設けています。
概算見積りの自動算出
横断設計に概算見積りの自動算出を加えました。経験値をもとにパターン別の工数対応表を用意し、職種間の並列可能処理やバッファも含めて現実に近い見積りとなるようにしました。
次章以降では、フローのポイントとなる箇所を順に説明します。
3. 要求レビューの評価ステップ
よい要求はよい設計に通ずる、ということで要求書の質向上、暗黙知の明文化、レビュー品質の再現性に向き合い、要求レビューの自動化に取り組みました。以下は、そのプロセスです。
前段1: 要求の粒度評価と分割提案
要求の規模を評価し、複数の機能が混在した大きな要求の場合は分割を提案します。
粒度が細かいと各工程で考える対象が小さくなり、レビュー・設計それぞれのアウトプット精度が上がります。また、問題のある部分を切り分けて残りを先行して進められるため、プロジェクト全体の進行速度が上がります。
前段2: 要求書の正規化
要求の内容を指定フォーマットに正規化します。
起点となるGitHub Issueにはテンプレートを用意していますが、これまで要求書を書く習慣がなかった人にいきなり全項目記載してもらうのは大変です。使い慣れたドキュメントツールで作成した文書でも音声入力でも、テキストであれば形式は問わず自由に入力してもらうことで要求書を書くハードルを下げる狙いがあります。
レイヤー1: 一般的品質チェック
背景・課題・目的・達成条件などの必要項目が揃っているか、書かれた内容をチェックリスト形式で評価します。
「なぜ?」を繰り返し、要求の根幹にある課題や背景(Why)を引き出します。要求が手段(How)で伝わってくることがありますが、課題を深掘りすることで、より効果が高かったり効率の良い別の解決手段を提案できる余地があるためです。
レイヤー2: 開発者視点レビュー
このまま実装を始めたら判断に迷うことは何か、書かれていないことを検知します。
ポイントは視点の切り替えです。要求者には自明でも、実装者には自明でないことがあります。「これを実装するならば、手を動かす前に何を確認しなければならないか」という立場で読み直すことで、その問いを引き出します。
たとえば、処理の実行タイミングによって設計が大きく異なる場合があります。しかし、要求書に書かれていることは少なく、書かれていなければ設計者が都度確認を取ったり推測で決めることになり、推測で決めた箇所は後から認識のズレにつながります。
達成手段を設計者に任せたい場合もあると思うので、その場合はその旨を記載するよう促します。一言も言及していない状態を作らないことがこのレイヤーの目的です。
人間がレビューを繰り返すと「きっとそういうことね」と内容を補完してしまいますが、常に要求書を初めて見た状態を再現出来るAIはレビュアーとしてとても相性がよいです。
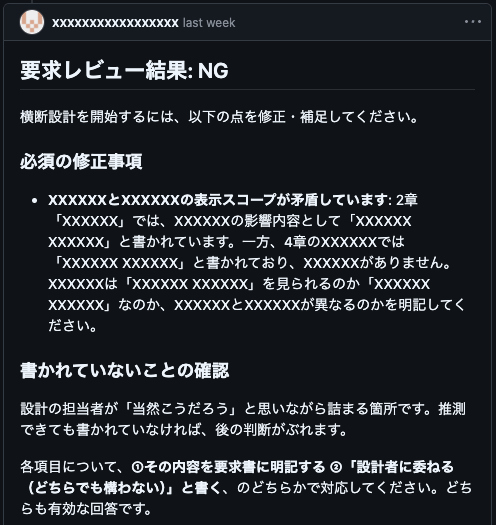

レイヤー3: アーキテクチャ整合性チェック
今のシステム構造で実現できるか、コードベースの固有チェックをします。
サービス間の通信制約・インターフェース定義・既存アーキテクチャのルールに照らし合わせて、このサービスで実現できるかを評価します。
一般的な品質基準に現在のシステム構成への適合チェックを加えることで、設計フェーズに進んでから「この前提は成立しない」と判明する手戻りを要求段階で防ぐことができます。
このレイヤーの土台となるのが、次章で説明するコードと同期したドキュメントです。
4. コードと同期したドキュメントの自動生成
要求レビューと横断設計の精度向上を支えるのがこの仕組みです。
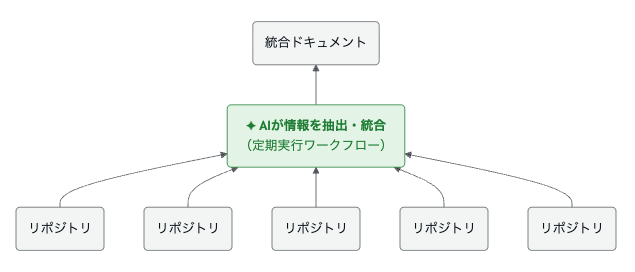
AIが対象サービスに関わるリポジトリを特定し、以下を抽出して統合ドキュメントとして更新します。
- サービス全体のアーキテクチャ構成・通信経路・リポジトリ依存関係
- リポジトリ間の通信制約・インターフェース定義・禁止事項
- 各システムの基本設計書・画面仕様書・機能仕様書
現在はGitHub Actionsのワークフローで定期実行しています。コードの変更にドキュメントが追従するため、常に最新の情報を保てます。
要求レビューのレイヤー3はこのドキュメントを根拠として「今のシステムで実現できるか」を評価します。また、横断設計もこのドキュメントを参照することで、現在のシステム構造に根ざした設計を生成します。
ドキュメントが存在しない場合も、アーキテクチャ整合性チェックをスキップして一般的なレビューと設計として動作するため、仕組み自体は他のサービスへもそのまま流用できます。
5. プロンプト構築プロセスの反復サイクル
仕組み化における具体作業のサイクルです。
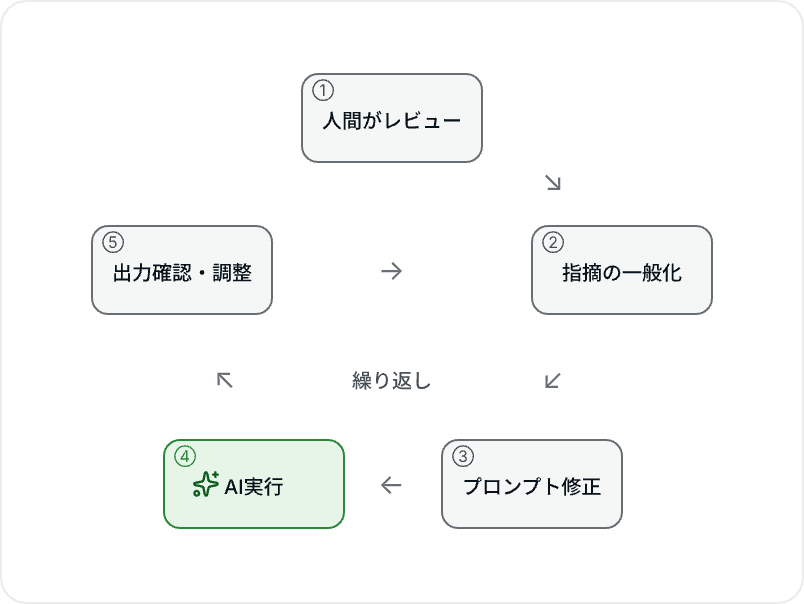
実案件の要求書を用いました。まずはいつも通り人間がレビューします。そこで出た指摘を「なぜこれを指摘したか」の観点で一般化して要求レビューのプロンプトに組み込んで実行し、自分の気付きと同じ内容が出力されるまで調整を繰り返します。要求者にも協力いただき実際のフローを試してもらい、フィードバックをもとに修正を重ねました。
たとえば「0件のときの表示が書かれていない」「エラー時の振る舞いが未定義」という指摘は、「正常系は書かれているが境界値・異常系の振る舞いが未定義」というパターンに一般化します。これが要求レビューにおけるレイヤー2の検知ルールになります。
横断設計においてはAIに仮実行させ、不足情報や的外れな設計が出たら横断設計のプロンプトを修正し、場合によっては要求レビューのプロンプトに戻るサイクルを繰り返しました。人間がこれまでやってきた要求レビューと横断設計のフローに、プロンプト調整サイクルを追加した形です。個人の暗黙知をパターンに落とし込み、システムに転写していく作業でもありました。
6. 変わったこと
仕組みを実現したことで、複数の変化が生まれました。
要求書の初期レビューをAIに完全移譲できた
初期レビューが要求者とAIの間で完結するようになったためエッジケースや境界値・異常系の網羅性が高くなり、要求書初稿の質が上がりました。その結果、エンジニアがレビューに要する時間が減り、最初から込み入った観点でレビューに臨めるようにもなりました。
要求書作成スキルをAIと共に伸ばせる仕組みができた
同一品質のAIフィードバックを繰り返し受けることで、要求者が考慮すべき観点を能動的に深められるようになりました。
横断設計を自動生成できた
ゼロから設計草案を書き起こす作業時間が短縮され、方針が変わった場合の再作成も容易になりました。また、レビューにおいても指摘の矛先がAI自動生成物になるため、フラットに「違うよ」と言えるなどレビュアー間の議論がポジティブにもなりました。
設計作業前に概算工数を掴めるようになった
横断設計がこれまでの仮設計にあたるため、開発規模を事前把握しやすくなりました。
レビュー品質が安定し、再現性が生まれた
レビュー観点がプロンプトに転写・蓄積されることで、属人化の解消と品質の安定化が実現できました。
決定の経緯まで遡れるようになった
要求・設計レビューの過程が記録として残るため、第三者があとから背景や判断の理由といった経緯を把握できるようになりました。
ドキュメントが常に最新の状態を保てるようになった
コードの変更に自動追従するため、実装との乖離が生まれなくなり、長年の課題だったドキュメントの陳腐化が解消されました。また、ドキュメントとして概要が整備されたことで、専門分野以外も含めたサービス全体像の把握がしやすくなりました。
7. 今後の展望
具体実装を含めた全工程の自動化
単一リポジトリではすでに、詳細設計・実装・テスト・PRレビューの自動化が進んでいます。横断設計のリポジトリ別指示を上手く伝達できれば、全工程の自動化が現実的になります。エンジニアの役割は「要求・横断設計の承認」と「各リポジトリのPR承認」に絞られます。
精度向上と利用拡大
AIによる出力内容はまだまだチューニングの余地があります。今回は著者一人のノウハウを詰め込みましたが、他メンバーの知見や今後の実案件での経験値を取り込み、その精度を更に高められると考えています。
普及と展開
現在はGitHubでの入力が前提なので、SlackやNotionなどを入口として他職種メンバーが参加しやすい形への拡張も進めていきたいと考えています。また、他サービスへの導入も併せて進めていければと思っています。
他にも、まだ構想段階ですが取り組んでみたいことがあります。
ひとつは、会議の自動文字起こしを要求の発足起点にすることです。「誰かが話したことを、本人すら覚えていないまま案件化する」という、これまでにない要件定義の入口が生まれるかもしれません。
もうひとつは、蓄積したアーキテクチャデータの活用です。非技術者の問いかけに、集約ドキュメントから仕様を答えてくれる仕組みを実現してみたいと思っています。さらに、複数サービスへの展開が進んでデータが蓄積されれば、新規サービス立ち上げ時にサービス特性に応じたアーキテクチャ構成を提案できるようにもなるかもしれません。
この仕組みを起点に、次々と活用のアイデアが出てきており、拡大の可能性を感じています。
8. おわりに
横断設計を自律化したいという想いから始まりましたが、満足する出力を実現するには要求レビューとドキュメント生成の自律化にも取り組むことになりました。
全体フローとしては作り切ることができました。しかし、現時点では「初期」レビューや横断設計の「草案」で、そのまま無条件に採用できる品質ではありません。それでも、この仕組みが動き始めただけで既に大きな恩恵がありました。
もしこの記事が、同じ領域や課題に向き合っている方の参考になれば幸いです。