
こんにちは。
AI 事業本部 AI クリエイティブカンパニー BPO 事業部のエンジニアの佐藤 (@Rintarooo) です。
KAT-TUN サブスク解禁ということで、KAT-TUN を見習って『ギリギリでいつも生きていたい』をどうにかして実践していきたい所存です。
はじめに
TypeScript 製の AI エージェントフレームワークである Mastra を、バックエンド API と AI エージェントの両方を担う単一のサーバーとして本番運用しています。
Mastra は比較的新しいフレームワークで、本番運用の事例がまだ少ないのが現状です。
そこで本記事では、Mastra をモノリシックなサーバーとして開発した背景や運用を通して得られた知見を共有します。
なぜ Mastra か
プロダクトの立ち上げ・PoC フェーズで、ユーザーの嗜好やデータベースの情報に基づいて回答する高度なチャット機能をアプリの必須機能として要件に固め、AIエージェントフレームワークを検討することにしました。
静的型付け言語で型安全性があり、開発チームや個人としても慣れ親しんでいる Go または TypeScript で検討しました。
しかし当時、Go で実装されたAIエージェントフレームワークである Google の Agent Development Kit (ADK) for Go はまだ GA として提供されておらず、TypeScript 製の Mastra を選びました。
Mastra は Vercel AI SDK をベースに構築されており、複数の LLM プロバイダー(Anthropic、Google 等)を統一インターフェースで扱える点も魅力でした。
加えて、Mastra は Hono ベースの HTTP サーバーとしても動作するため、AI エージェントと API サーバーを単一のサーバーで提供できます。
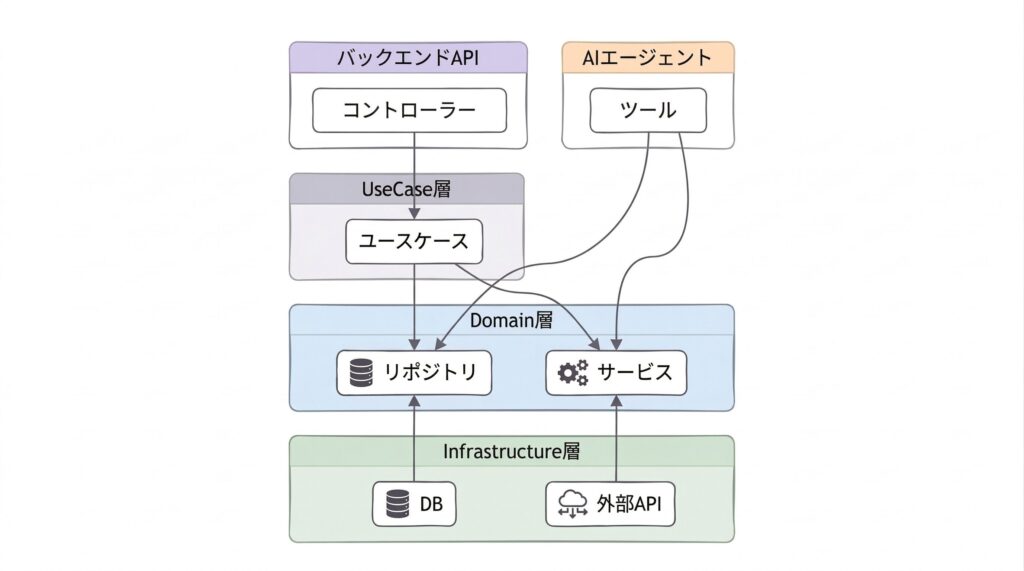
バックエンド + AI エージェントの構成
なぜ単一サーバーにしたか
Tool 実装におけるリポジトリ/サービスの再利用
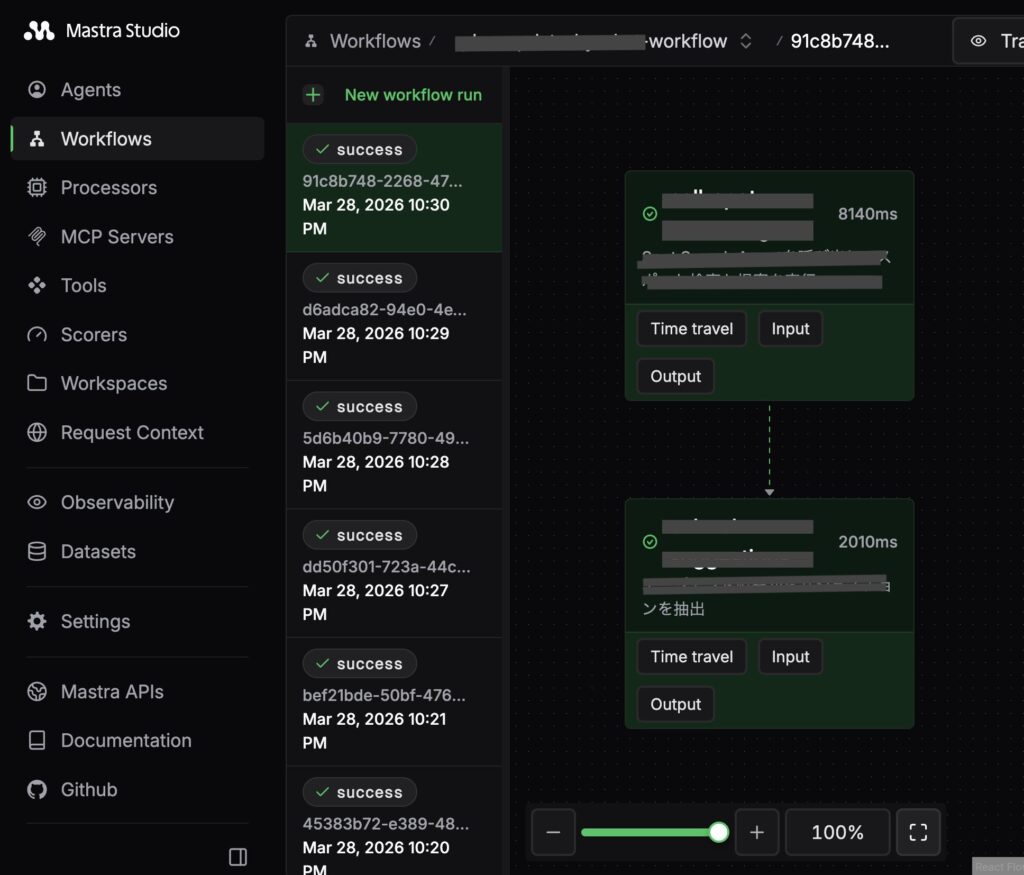
AI エージェントの可観測性
Mastra Studio
Langfuse
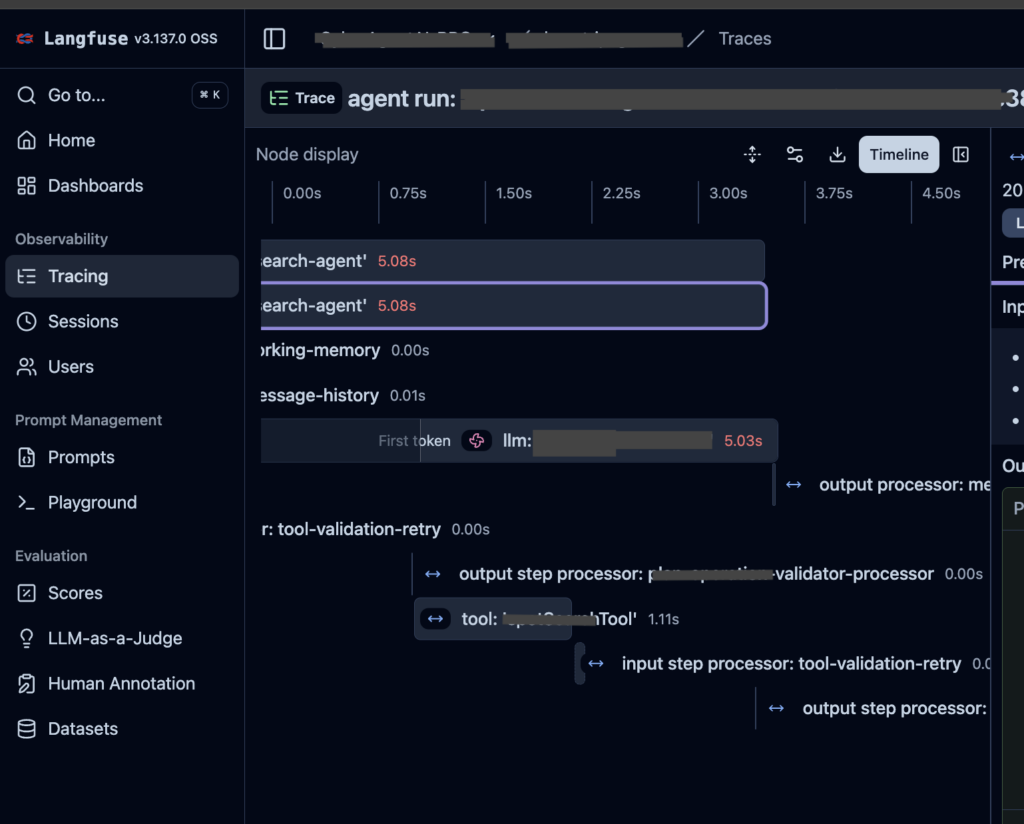
エージェントがネストして呼び出した Tool も、トレースツリーで構造的に可視化されます。また、会話の流れをスレッド単位で追跡できるほか、入出力・消費したトークン数やコストといった詳細情報も確認できます。
プロンプトをコードと分離
昨今、Claude Code をはじめとするコーディング AI を活用した開発が一般的になりつつあります。一方、コーディング AI がプロンプトとロジックを一度に編集してしまうことで、「エージェントの挙動が変わったのが、プロンプトの修正なのかロジックの変更によるものなのか」わからなくなってしまうことがありました。
また、プロンプトを 1 行変えるだけの微調整でも PR を作成してデプロイする必要があり、 手軽に調整できないもどかしさを感じてました。ほかに、PM からどんなプロンプトで動いているのか聞かれることもありました。
そこで、プロンプトは GitHub で管理しているコードと切り離し、Langfuse で管理しています。これにより、プロンプトの変更はアプリケーションのデプロイサイクルとは独立して即座に反映でき、変更の影響範囲が明確になります。また、プロンプトはバージョン管理されているため、変更前の状態にいつでも戻すことができ、安全にプロンプトの調整ができます。さらに、プロンプトにラベルを付与できるので、どのプロンプトがどの環境に反映されているかも一元管理でき、PM もプロンプトを確認しやすくなるというメリットもありました。加えて、Langfuse 公式が提供する MCP を介して、コーディング AI からもプロンプトの編集ができます。
おわりに
Mastra はバージョンアップが頻繁に行われるため、破壊的変更にキャッチアップしながら対応する必要があります。一方、エージェントの挙動を手軽に可視化・追跡できる開発体験の良さも感じています。
本記事の内容が、見てくださった方の AI エージェントを活用したプロダクト開発・運用や今後の設計や技術選定の参考になれば幸いです。