
AIがコードを書く時代、QAはどう変わるべきか?
Claude Code、Devin、Cursorといったコーディングエージェントの登場により、コードを書く速度は劇的に向上しました。しかし、その変化はQAにも大きな影響を与えています。AIが高速にコードを生み出す一方で、それを検証するQAのプロセスが従来のままでは、品質担保がボトルネックになりかねません。
この記事では、マッチングアプリ「タップル」のネイティブチーム(iOS/Android)が直面したこの課題と、それをどう乗り越えたかをお伝えします。
この記事で伝えたいこと
- 課題: 手動リグレッション216項目の限界と、AIコーディング時代の新たな負荷
- 解決策: E2E自動化(Maestro)× AIエージェント(Devin)× Playbookの組み合わせ
- 成果: Hotfix件数の削減と、QAチームがより本質的な品質評価に集中できる体制の構築
タップルのリリースサイクル
タップルでは毎週iOS/Androidの両プラットフォームをリリースしています。
毎週リリースするため、毎週リグレッションテストが必要です。216項目のテストケースを、リーダー1人 + テスター4人の体制で、リリース前に毎回実施していました。週次リリースを維持しながら品質を担保する——この両立は決して簡単ではありません。
想定読者
この記事は以下のような方を想定しています:
- ネイティブアプリのQAに課題を感じているエンジニア・QA担当者
- E2E自動化を検討しているが、どこから始めればいいかわからないチーム
- AIエージェントをQAプロセスに活用したいと考えている方
それでは、私たちが直面した課題から見ていきましょう。
2. 私たちが直面した課題
2.1 タップルの背景と手動依存の課題
前述の通り、タップルでは毎週リリースを行っており、そのたびにリグレッションテストが必要です。
問題は、216項目すべてを手動で行っていたことでした。
リリース条件 = 手動リグレッション全項目通過 + 重要Issue解消
1項目あたり数分かかるものもあり、チーム全体でかなりの工数を費やしていました。
この手動依存には以下の課題がありました:
- 属人化: テスト実施者によって確認の粒度が異なる
- 品質のばらつき: スキル差や体調によって見落としが発生
- スケーラビリティの限界: 項目数が増えても人的リソースは有限
2.2 網羅性の課題
さらに深刻だったのはOS網羅性の問題です。
iOSの場合、サポート対象はiOS 17、18、26のメジャー3バージョン。つまり:
216項目 × 3 OS = 648項目/週
これを毎週手動で実施するのは現実的ではありません。
実際には「OSローテーション」と呼ばれる運用で、週ごとに異なるOSで検証していました。結果として毎週全OSの30%程度しか検証できず、OS依存の不具合を見逃す構造的なリスクを抱えていました。実際に「iOS 17.5でだけ発生する」といった不具合がリリース後に報告されるケースもありました。
2.3 AIコーディング時代の新たな課題
2025年以降、開発現場では大きな変化が起きました。
Claude Code、Devin、CursorといったAIコーディングエージェントの導入により、PR(プルリクエスト)の作成速度が大幅に向上したのです。これ自体は生産性向上として歓迎すべきことですが、QAにとっては新たな課題が生じました。
- コード変更の頻度・量が増加 → QA対象が爆発的に増える
- 従来の手動QAでは追いつけない構造的問題が顕在化
- 「AIが速くコードを書く → 人間がテストする」というボトルネック
特に問題だったのはフリーテスト(探索的テスト)の時間が確保できないことでした。リグレッションテストに追われ、本来重要な「想定外の不具合を発見するテスト」に時間を割けない状況が続いていました。
開発速度が上がっても、QAの品質担保の確度が追いつかなければ、結局は品質リスクを抱えたままリリースすることになります。このギャップを埋める必要がありました。
2.4 データで見る課題
当時の状況を振り返ると、以下のような課題が数字として見えていました。
フリーテスト開始時刻とIssue繰越率の相関
リグレッションテストの完了時刻が遅れることで、フリーテストに割ける時間が減少し、結果として修正が間に合わずリリースに持ち越されるIssueが増加していました。
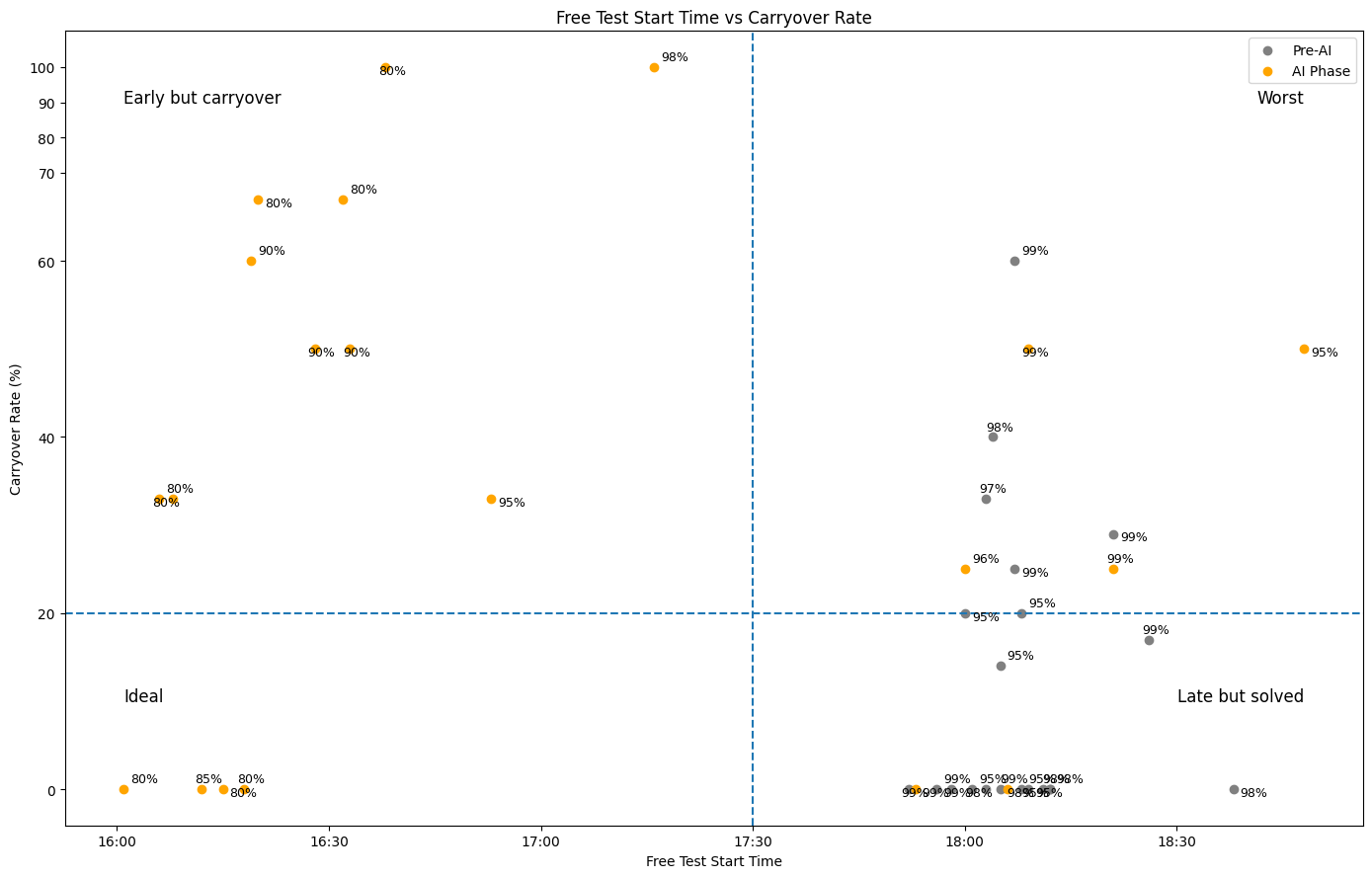
上記は、フリーテスト開始時刻とIssue繰越率の関係を示しています。3つのフェーズを比較すると:
- Pre-AI & QASE導入前: 厳密なテスト内容で属人化が少ない一方、項目消化に時間がかかっていました。おおよそ17:30以降に完了し、繰越率は低めでした。
- QASE導入 & AIコーディング時代(2025年〜): 項目数や内容が見直され、項目消化が早くなりました。一方で、当日に解決できず繰越すIssueが増加しました。おおよそ16時台に完了していますが、常に20%以上の繰越率となっており、1Issueあたりの修正コストが高いことが示唆されました。
- 目標(E2E Phase): 「左下(早く終わる × 繰越が少ない)」の状態を目指す
これらの時刻がなぜ重要なのかを理解するため、前提条件を整理します。当時のチーム体制はiOS 8人、Android 7人程度で、実績ピークはiOS 9件、Android 7件のIssue報告でした。定時は19:00で、1Issueあたり平均1.5時間の調査・修正時間が必要でした。
この前提のもとで、リグレッション完了時刻と確保できる時間の関係をシミュレーションすると:
- 17:30 終了(当時の現状): Issue対応に追われ、フリーテストに割ける時間が不足
- 16:00 終了(改善目標): 調査・修正に約2時間確保でき、19:00定時までに対応可能
- 15:00 終了(理想状態): 約4時間の余裕が生まれ、生産的な探索や改善活動に集中できる
つまり、E2E自動化によってリグレッション完了時刻を早めることで、QAチームが本来の価値を発揮できる時間を確保することが目標でした。
目標とする改善指標
これらの課題を解決するため、私たちは段階的なE2E自動化の目標を設定しました。
まず前提として、リグレッション216項目のうち、1項目あたりの検証時間は等価として試算しました。実際には項目ごとに難易度は異なりますが、投資対効果を見積もるための簡易的なモデルとして採用しています。この前提のもとで、段階的にE2E化する割合を決定しました。
Phase 1(リグレッション項目の40%をE2E化):
- リグレッション繰越率: 30%前後→安定化
- 項目消化完了時刻: 70%の確率で16:30以前
Phase 2(リグレッション項目の60%をE2E化):
- リグレッション繰越率: 20%未満
- 項目消化完了時刻: 70%の確率で15:59以前
これらの目標を達成することで、QAチームがより本質的な品質評価(フリーテスト)に集中できる体制を構築することを目指しました。次のセクションでは、その解決策について詳しく説明します。
3. 課題をどう解決したか
3.1 解決アプローチ
前セクションで述べた課題を解決するため、私たちは以下のようなアプローチを構築しました。
毎日深夜 E2E実行 → 失敗時 Devin自動調査 → GitHub Issue起票 → 当番対応
課題と解決策の対応を整理すると、以下のようになります:
- 手動依存 → E2E自動化(Maestro)
- 網羅性不足 → 毎日全OS実行 + OS傾向分析
- AIコーディング時代の負荷増大 → AIエージェントによる調査自動化
- フリーテスト時間不足 → リグ項目の自動決定で手動を最小化
以下、それぞれの解決策について詳しく説明します。
3.2 手動依存 → E2E自動化(Maestro)
なぜMaestroか
E2Eテストフレームワークの選定にあたり、いくつかの選択肢を検討しました。最終的にMaestroを選んだ理由は以下の通りです:
- iOS/Android両対応: モノレポで両プラットフォームを開発している私たちにとって、統一したテストフレームワークは必須でした
- YAMLベースの宣言的記述: テストコードの可読性が高く、非エンジニアでも理解しやすい
- セットアップの簡便さ: 既存のCI/CDパイプライン(GitHub Actions)との統合が容易
Maestroの詳細については、公式ドキュメントをご参照ください。
# Maestroテストの例
- launchApp
- tapOn: "ホームタブ"
- assertVisible: "いいかも!"
QASEテストケースからのYAML自動生成
QASEに登録されているテストケースから、Maestro YAMLファイルを自動生成する仕組みを構築しました。
変換ツール構築: QASEからエクスポートしたテストケースをもとに、Claudeとの対話を通じて自然言語のアクション表現(「〜を押下」「〜をタップ」など)とMaestroコマンド(tapOn, swipeなど)の対応関係を整理し、変換ツールを作成しました。
日々の運用: 毎日15時にGitHub Actionsのworkflowが実行され、最新のQASEテストケースからMaestro YAMLファイルを自動生成(コメントアウト状態)したPRが作成されます。現状は完全な自動変換が難しいため、エンジニアは必要なテストを選んでコメントを解除し、有効化します。
この仕組みにより、QASEを唯一の情報源(Single Source of Truth)として、テストケースの一元管理を実現しています。
Claude Codeによる品質チェック
E2E自動化において、Claude Codeも重要な役割を果たしています:
例えば、エンジニアがMaestroテストを追加・修正した際、Claude Codeは以下のようなチェックを自動実行します:
- QASEテストケースとの整合性確認(欠落や不一致の検出)
- Maestro YAML構文の妥当性検証
- テストステップの論理的な妥当性確認
- 共通パターンからの逸脱の検出
この自動チェックにより、レビュー時の見落としを防ぎ、テスト品質の均質化を実現しています。

iOS/Android共通化と棲み分け
iOS/Androidの共通テストと各OS固有テストを効率的に管理するため、ID管理システムを構築しました。
maestro_ids.jsonによる一元管理:
- 中央で管理する
maestro_ids.jsonから各プラットフォームのコードを自動生成 - YAMLテスト定義(Maestro)、Swift(iOS実装)、Kotlin(Android実装)の3つに対応
- IDの追加・変更が全プラットフォームに自動反映される
要素指定の方針:
- iOSとAndroidで必ずしも同じView構造をしているわけではなく、コンポーネントの粒度も揃っていない
- そのため、textで判別できるものはtext指定を使用(テキスト内容はプラットフォーム間で共通)
- ボタンや画像など、textがない要素はID管理システムを使用
この運用により、重複を最小限に抑えながら、OSごとの差異にも柔軟に対応できています。
3.3 網羅性不足 → 毎日全OS実行
E2E実行戦略
前述のOS網羅性の問題を、E2E自動化により毎日全OSで実行する形で解決しました。
- iOS: 毎日 02:00 JST に実行
- Android: 毎日 03:00 JST に実行
- 対象OS: サポート対象の全バージョン(iOS 17.5, 18.x, 26.0 / Android各バージョン)
- 最新OSバージョン: 週3回重点検証(不具合が出やすいため)
E2Eテストの結果から、OS依存の不具合かどうかを自動判定する仕組みも構築しました。
3.4 E2E結果分析レポート
毎日深夜に実行されるE2Eテストの結果を、Devin が自動分析します。
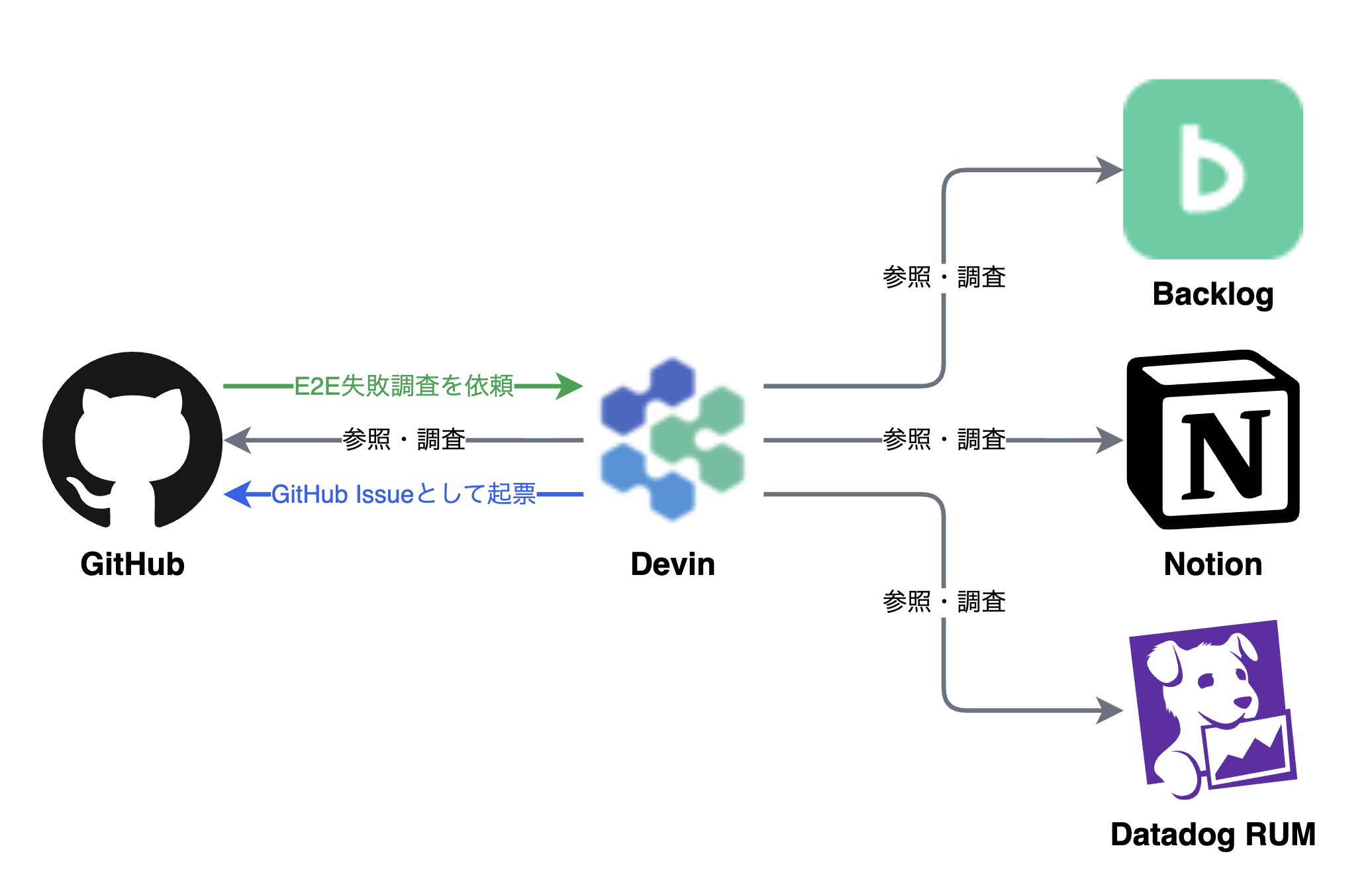
分析に用いるPlaybookには調査手順を記載しており、E2Eの結果を分析します:
調査内容:
- OS傾向分析: 直近7回の実行結果を集計し、OS依存の不具合かどうかを判定(7回 = 週次リリースサイクル1週間分のデータで判断)
- 「iOS 17.5だけで失敗」→ OS依存の可能性が高い
- 「全OSで同様に失敗」→ OS非依存のバグ
- フレーキー判定: 失敗頻度から不安定なテストを特定
- 1/7回失敗 = 要監視(新規不具合またはフレーキーの初期兆候)
- 2-4/7回失敗 = フレーキー(不安定)
- 5/7回以上失敗 = 修正要検討
- 関連PRの特定: 失敗と関連するコード変更を特定
- 推奨対応の提案: 修正すべきファイルや対応方針を提示
Devinが生成するレポートには、以下の情報が含まれます:
- エグゼクティブサマリ: 失敗したテストの概要と影響範囲
- OS別実行結果テーブル: iOS 17.5、18.0、18.2などバージョンごとの直近7回の成功/失敗状況を一覧表示
- Datadog RUM連携分析: パフォーマンス指標(App Launch Time、Error Rate、Crash Rateなど)との相関を分析
- 優先度付きアクションアイテム: 「即座に対応」「要監視」「後回し可」などの優先度と具体的な対応方針
このレポートにより、エンジニアはどのOSで、どの程度深刻か、何をすべきかを即座に判断できます。
出力: GitHub Issueとして自動起票され、当番エンジニアが対応します。
3.5 フリーテスト時間不足 → リグ項目の自動決定
最後に、フリーテスト時間の確保についてです。
従来はリグレッション項目すべてを手動で確認していましたが、現在は以下の計算式で手動確認の対象を最小化しています:
リグレッション項目 − E2E通過項目 = 確認すべき手動項目
E2Eテストが安定して通過する項目は自動化に任せ、QAチームは以下に集中できるようになりました:
- E2Eでカバーできない項目の手動確認
- フリーテストによる想定外の不具合発見
- ユーザビリティ観点での品質チェック
この仕組みにより、リグレッションテストの効率化とフリーテスト時間の確保を両立しています。
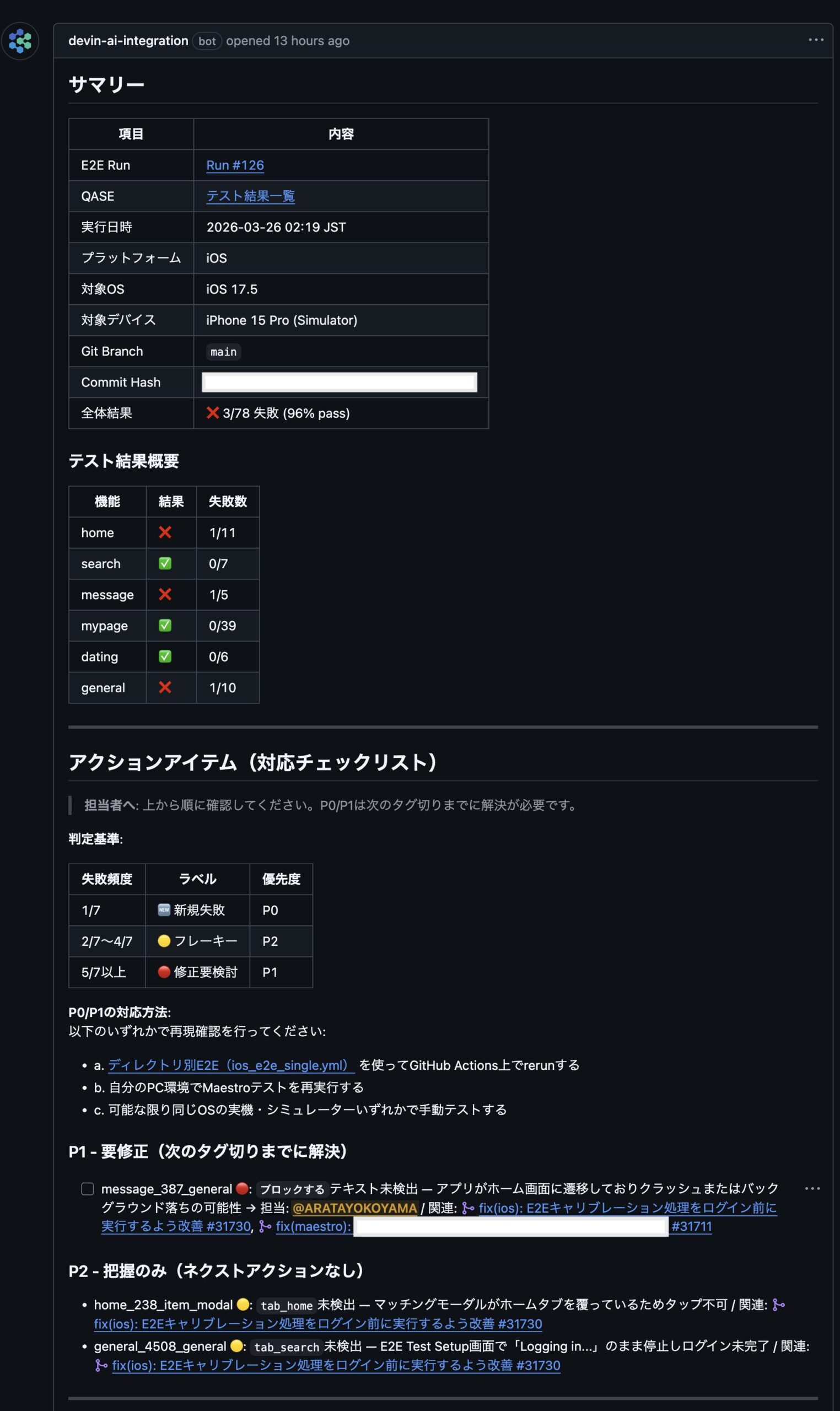
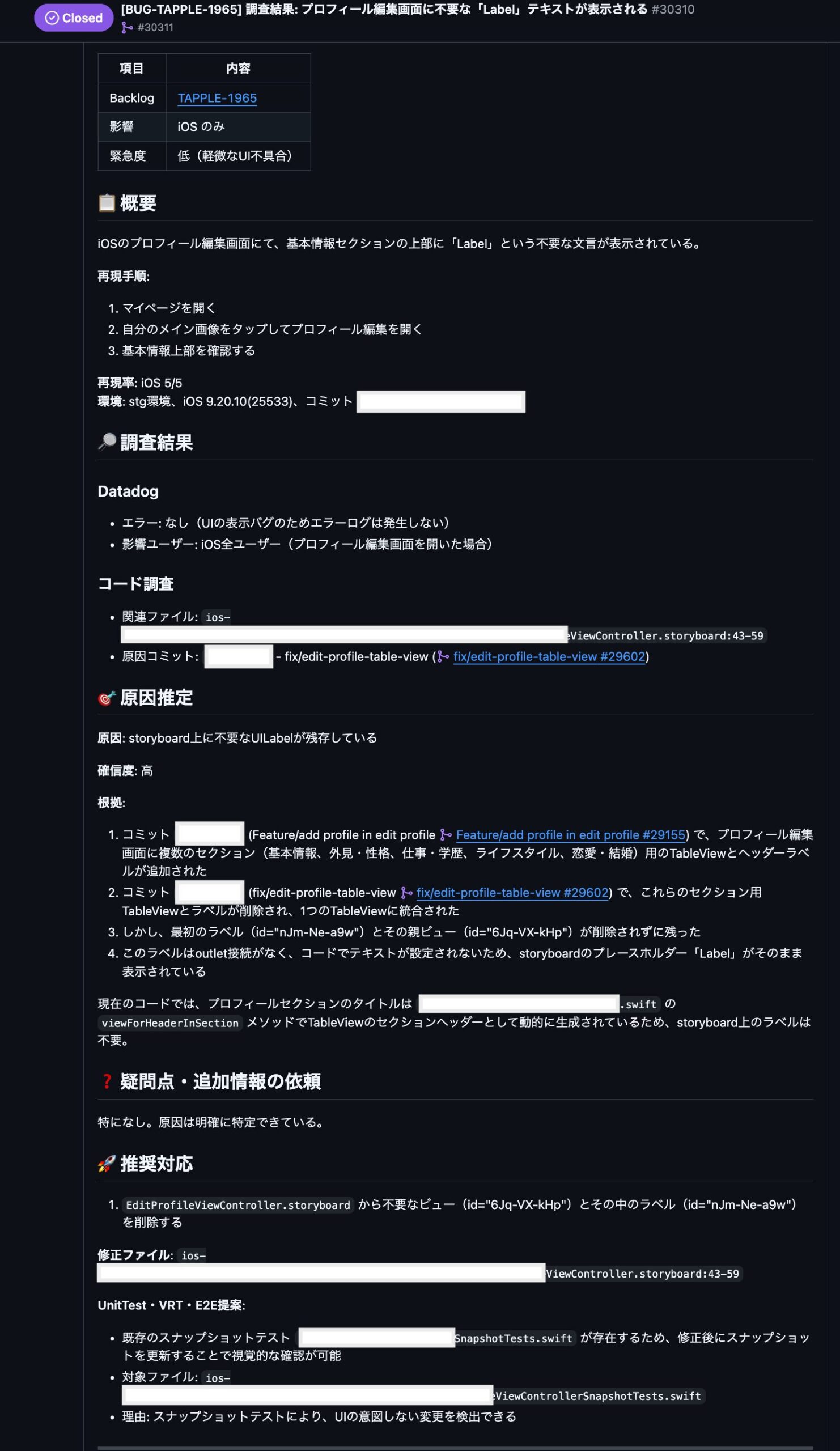
3.6 Backlog issue調査
QAがBacklogにフリーテストや施策テスト中の不具合を報告すると、Devinが自動的に調査を開始します。
Backlogからの情報取得
QAが報告する不具合には、以下の情報が構造化されて記載されています:
- タイトル: 不具合の概要
- 再現手順: ステップバイステップの操作手順
- 期待される動作: 本来どうあるべきか
- 実際の動作: 何が起きているか
- 発生環境: OS、バージョン、デバイス情報
Devinの横断調査
Devinは、Backlogの情報を起点に以下を自動調査します:
- Backlog: 不具合の詳細情報、再現手順
- Datadog RUM: パフォーマンス指標、クラッシュログ
- コードベース: 関連するPRやコミット履歴
調査結果はGitHub Issueとして起票され、以下のセクションで構成されます:
- 概要: 不具合の要約と影響範囲
- 調査結果: Backlog/Datadog/コードベースの調査結果を統合
- コード変更箇所: 修正が必要なファイルと具体的な変更内容
- 関連PR: 不具合に関連する可能性のあるPR一覧
- 修正提案: 推奨される対応方針と実装方針 可能ならテストの追加まで
Copilotによる半自動修正
調査結果が妥当であれば、GitHub Copilotをアサインすることで修正PRを半自動的に作成できます:
- Devinが起票したIssueの分析内容を確認
- 内容が妥当であればCopilotをアサイン
- Copilotが修正PRを自動生成
- エンジニアがレビュー・マージ
この仕組みにより、「調査→修正」までのプロセスがAIによって加速されます。実際に、修正対応だけでなく、不足しているユニットテストまで自動追加できたケースもあります。こうした事例は、AIエージェント活用が「調査の効率化」にとどまらず、「テストカバレッジの向上」といった品質改善にまで貢献できる可能性を示しています。
3.7 リリース品質評価
週次リリース前の手動リグレッションテスト完了後、Devinが自動的に品質評価を実行します。
評価内容
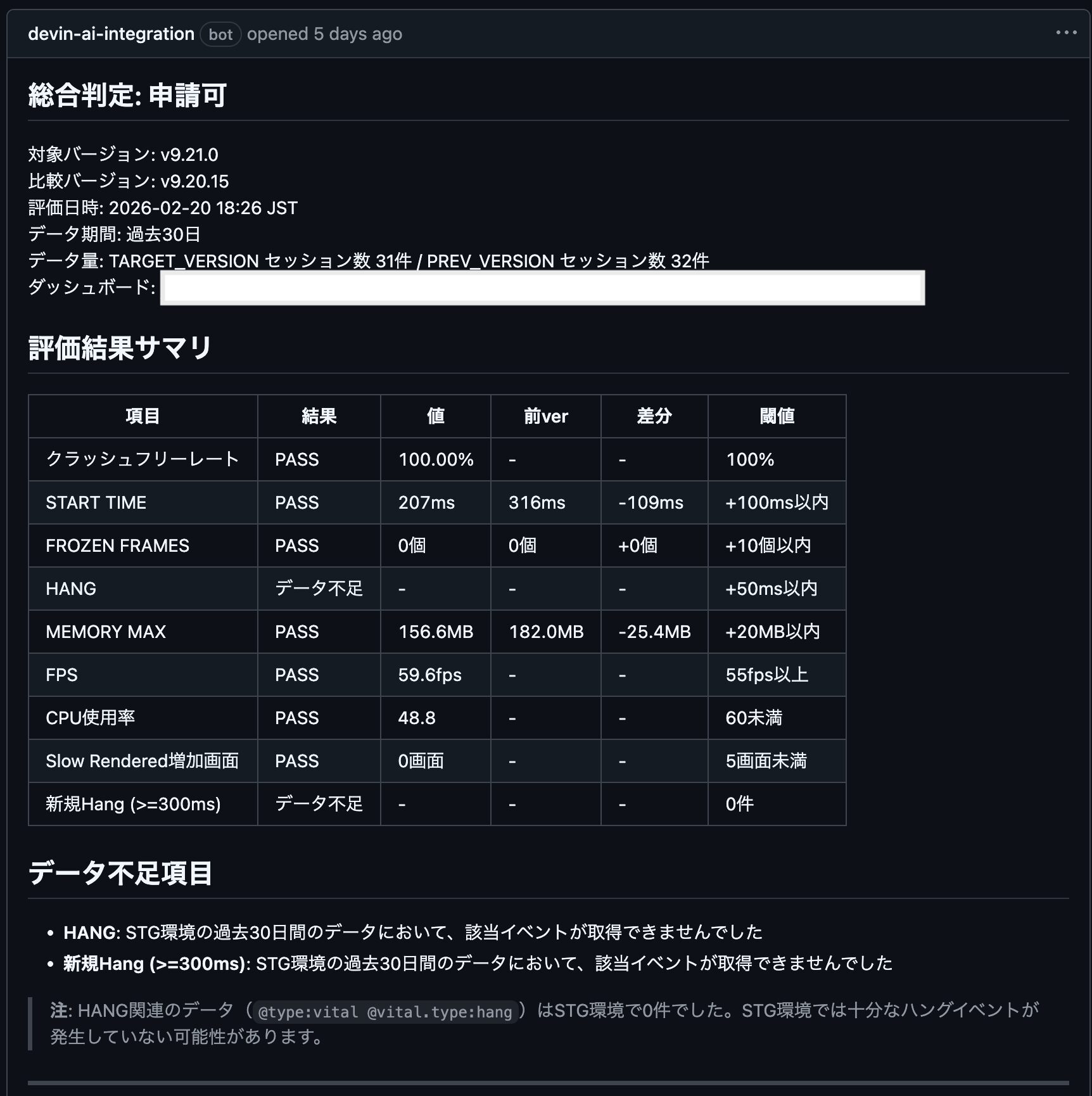
Datadog RUMの9つの指標を自動評価し、リリース可否の判断材料を提供します:
- クラッシュフリーレート: 100%
- START TIME(起動時間): 前バージョン比 +100ms以内
- FROZEN FRAMES: 前バージョン比 +10個以内
- HANG(ハング時間): 前バージョン比 +50ms以内
- MEMORY MAX: 前バージョン比 +20MB以内
- FPS: 55fps以上
- CPU使用率: 60未満
- Slow Rendered増加画面: 5画面未満
- 新規Hang (>=300ms): 0件
Devinが生成するレポートには、各指標に対して以下の情報が含まれます:
- PASS/FAIL判定: 閾値を満たしているかの明確な判定
- 現在の値: 前バージョンと今回リリース版の具体的な数値
- 差分: 前バージョンからの増減量
- 評価コメント: 「閾値内に収まっている」「要注意」などの補足
例えば、起動時間が「前バージョン: 1,200ms → 今回: 1,250ms(+50ms)」のように表示され、+100ms以内であればPASS判定となります。
このレポートにより、リリース責任者は客観的な数値に基づいてリリース可否を判断できます。
出力: GitHub Issueとして自動出力され、PASS/FAILが一目でわかります。リリース責任者が最終判断を行います。
AIエージェントの活用により、「コードを書く」「テストを書く」「調査する」までの一連のフローでAIが人間をサポートする体制が整いました。Devinの投資対効果については、セクション4.2で詳しく説明します。
4. 成果と現在地
4.1 定量的な成果
E2Eテストカバレッジと検証頻度
リグレッション項目のE2E化も着実に進んでいます。
- リグレッションテスト項目数: 214項目(iOS)
- 2026年3月27日時点: iOS 79/214項目(37%)、Android 55/214項目(26%)
推移:
- 2026年1月29日: iOS 36/210項目(17%)
- 2026年2月27日: iOS 48/210項目(23%)
- 2026年3月27日: iOS 79/214項目(37%)
※開始時期: 2025年11月中旬
重要なのは、リグレッションテスト項目の37%(iOS)を毎日検証・評価できるようになったことです。さらに、サポート対象のOSを網羅的にカバーできるようになり、OS網羅性の課題も解消されました。
E2E通過項目割合とフリーテスト開始時刻の関係
E2E自動化により、手動リグレッション項目が着実に代替されています。
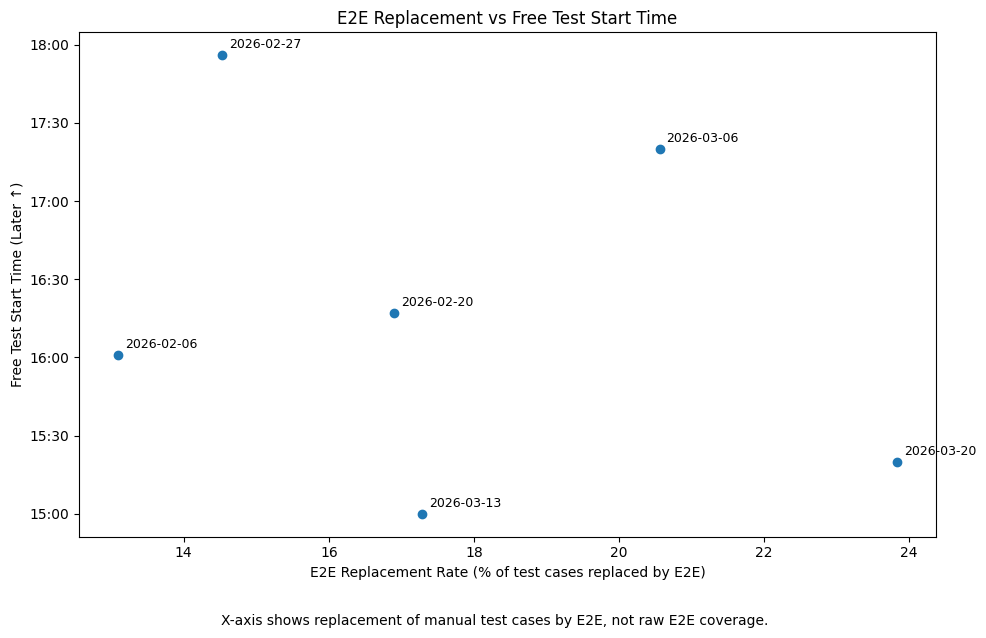
上記のグラフは、E2Eによって手動テストが代替された割合(iOS+Android合算)とフリーテスト開始時刻の関係を示しています。
注意: X軸は「E2Eカバレッジ(E2E化された項目数)」ではなく、「E2Eが実際に成功して手動テストを代替した割合」を示しています。
推移:
- 2026年2月6日: E2E代替率 約13%, フリーテスト開始 16:00
- 2026年3月20日: E2E代替率 約24%, フリーテスト開始 15:20
E2E代替率が向上するにつれて、フリーテスト開始時刻が早まる傾向が見られます。これにより、フリーテストにより多くの時間を割けるようになりました。
フリーテスト開始時刻と繰り越し率の改善
リグレッションテストの効率化により、フリーテストに着手できる時刻も大幅に早まりました。
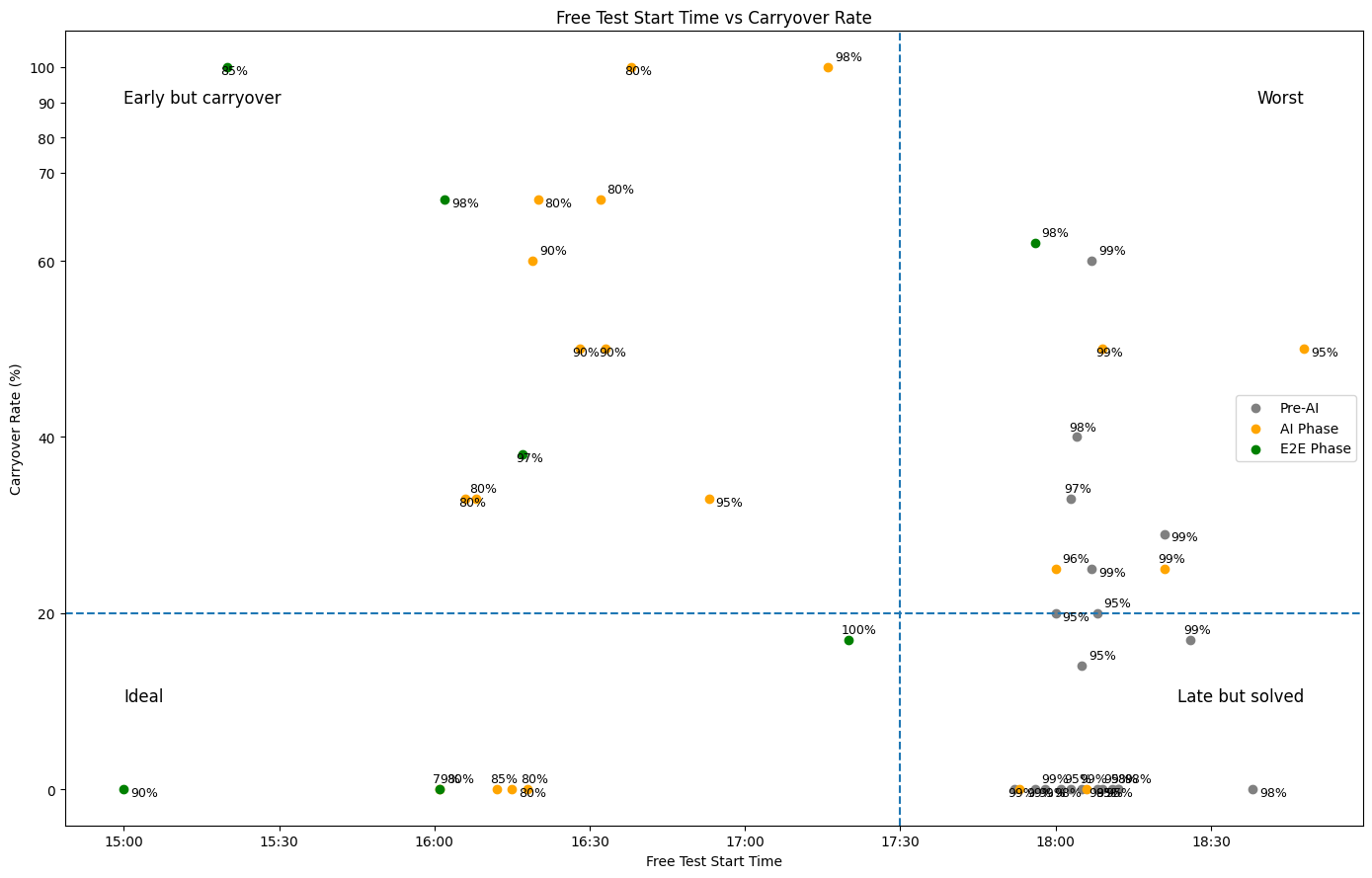
上記のグラフは、フリーテスト開始時刻とIssue繰越率の関係を3つのフェーズで比較したものです:
- Pre-AIフェーズ: 17:30〜18:00頃にフリーテスト開始
- E2Eフェーズ(現在): 15:00〜16:30頃にフリーテスト開始
- 改善効果: 約2時間の前倒し
グラフの理想的な状態(Ideal)は左下(早く終わる × 繰越が少ない)です。E2Eフェーズでこの目標に近づいており、フリーテストにより多くの時間を割けるようになりました。
4.2 Devinの投資対効果
Devinの利用にはコストがかかりますが、その投資対効果を整理します。
月間コスト
Devinの利用コストをACU(Agent Compute Unit)ベースで示します:
- E2E調査 1回: 約4 ACU
- 品質Check 1回: 約2.5 ACU
- Issue調査 1回: 約3 ACU
- 月間消費量: 約180〜200 ACU
料金の詳細はプランによって異なります。詳しくはDevin公式価格ページをご参照ください。
調査プロセスの効率化と品質への再投資
Devinの導入により、調査プロセスが効率化されました:
- E2E失敗の原因分析: Devinが自動分析し、ネクストアクションを決めるまで約5分
- Backlog issue調査: コード調査等が半自動化され、メンバースキルに依存せず調査の初動が早くなった
重要なのは、この投資により確保された時間を「工数削減」ではなく「品質向上への再投資」として活用している点です。
調査にかかっていた時間をフリーテストに充てることで、リグレッション項目には含まれない潜在的なissueの発見につながっています。結果として、総工数は変わらずとも、品質担保の確度が向上しました。
今後、リグレッションテスト中のissue報告から収束までがさらに高速化し、繰り越し率が減少していくことを期待しています。
4.3 各Playbookの効果分析
3つのPlaybookがそれぞれどのように成果に貢献したかを分析します。
E2E失敗分析Playbookの効果
OS依存不具合の早期発見
毎日全OSでE2Eを実行することで、「iOS 17.5でだけ発生する」といったOS依存の不具合を、リリース前に検出できるようになりました。以前はOSローテーション運用により、このような不具合がリリース後に報告されるケースがありましたが、現在はE2E失敗分析PlaybookがOS傾向を自動分析することで、早期検知が可能です。
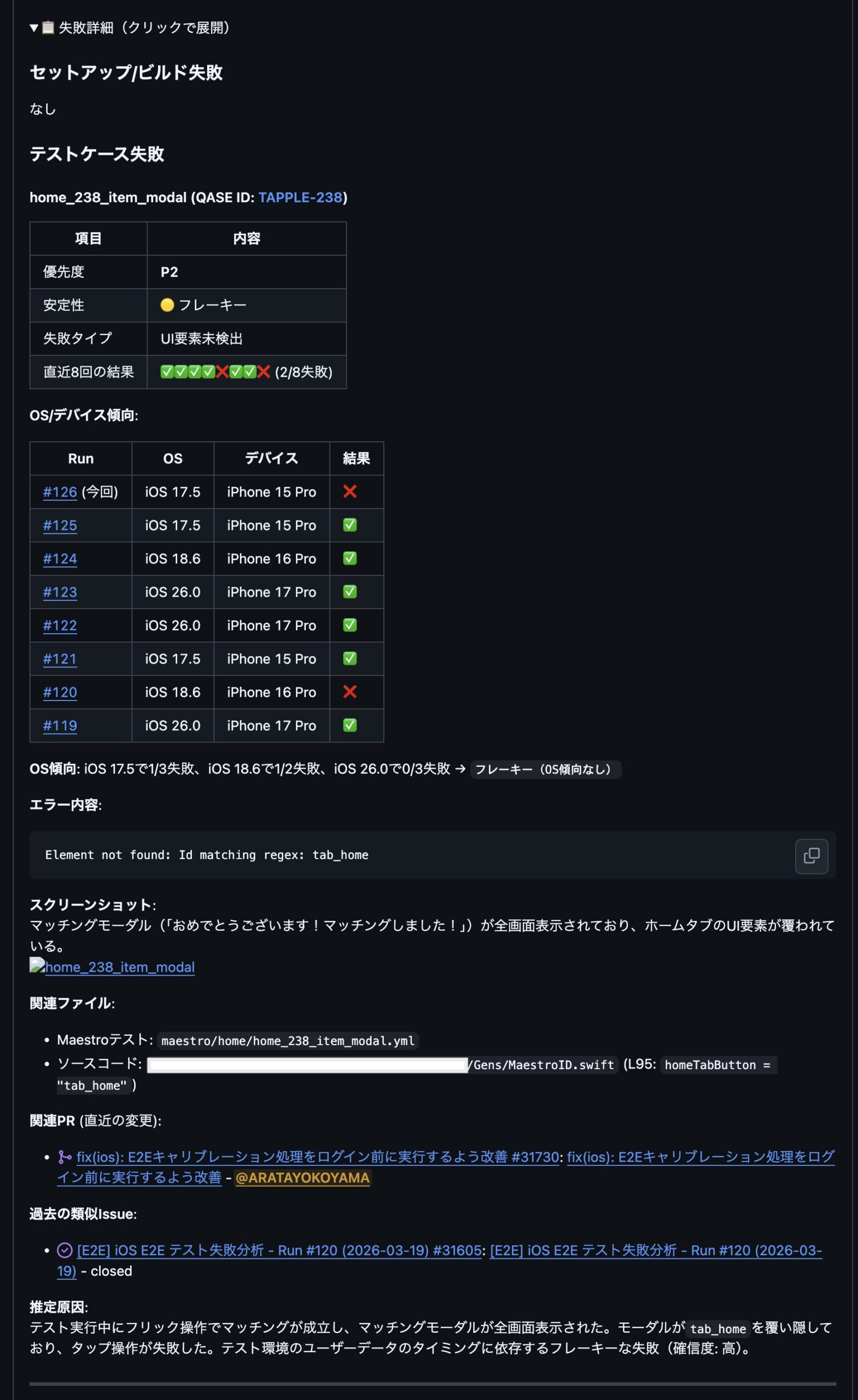
フレーキーテストの可視化
直近7回の失敗履歴から自動判定することで、「たまたま失敗したテスト」と「本当に修正が必要なテスト」を区別できるようになりました。これにより、調査すべきissueの優先順位付けが明確になり、エンジニアの工数を効率的に配分できています。
リリース品質評価Playbookの効果
パフォーマンス劣化の防止
Datadog RUM 9指標の自動評価により、リリース前にパフォーマンス劣化を検知できるようになりました。特に起動時間やメモリ使用量の増加を見逃さないことで、ユーザー体験の悪化を未然に防いでいます。
このPlaybookの導入によって、パフォーマンス関連のHotfixが減少することを期待しています。
Backlog issue調査Playbookの効果
調査工数の削減とフリーテストへの再配分
QAが報告した不具合をDevinが自動調査することで、エンジニアの調査時間が削減されました。さらに、Copilot連携により修正PRの作成も半自動化され、「調査→修正」の一連のプロセスが加速されました。
削減された調査時間はフリーテストに再配分しており、リグレッション項目には含まれない潜在的なissueの発見につながっています。
4.4 現在の課題と今後の展望
成果がある一方で、次の段階への課題も見えてきました。
レポート情報の最大活用
3つのPlaybook(E2E失敗分析、リリース品質評価、Backlog issue調査)により、Notion、Datadog RUM、コードベース、コミット履歴、issue本体などさまざまな観点から膨大な情報を即座にレポーティングできるようになりました。
一方で、それらの情報から取捨選択して次の行動に移すという点については課題が多くあります。
Playbookの進化(v1 → v2 → v3)
Playbookは段階的に改良を重ねてきました:
- v1: 調査手順とIssue起票の基本形(レポーティングと初動分析)
- v2: ファーストビューの情報量を削減し、ネクストアクションの視認性向上。フレーキー判定とチェックボックスを導入
- v3(現在): OS/デバイス傾向分析を追加。再現確認の具体的な方法(GitHub Actions rerun、ローカル実行、手動テスト)を明確化
自動化と人間の判断の境界
現状でもPR自体は自動生成可能ですが、レポーティング内容の確からしさに課題があります。無造作にPRを乱立されても誤ってそのままマージされる方が問題だと考えています。
初動調査結果から修正対応に進むトリガーについては、まだ人間が持っていたほうが良いと考えています。自動化と人間の判断の適切なバランスを見極めながら、段階的に進化させていく方針です。
5. おわりに
本記事では、タップルのネイティブチームが取り組んできたQA戦略についてお伝えしました。
破壊を早期に検知し、早期に収束できる構造を作る
私たちの取り組みの根底にある考え方は、「破壊を早期に検知し、早期に収束できる構造を作る」ことです。
E2E自動化により「検知」を早め、AIエージェント + Playbookにより「調査・判断・対応」のサイクルを高速化する。この構造により、開発速度が上がっても品質を維持できるようになりました。
完全自動化ではなく、人とAIの協働
私たちが目指しているのは「完全自動化」ではありません。
AIと人間がそれぞれの強みを活かし、協働することで品質を担保する。それが私たちの考え方です。
3つのPlaybookにおける役割分担
具体的に、各Playbookでの人とAIの役割分担を見てみましょう:
E2E失敗分析Playbook
- AIが担うこと: E2E失敗の原因調査、OS傾向分析、フレーキー判定、関連PR特定
- 人が担うこと: P0/P1/P2の優先度の最終決定、修正方針の判断、リリーススケジュールへの影響評価
リリース品質評価Playbook
- AIが担うこと: Datadog RUM 9指標の自動評価、閾値判定、PASS/FAILの機械的判断
- 人が担うこと: リリース可否の最終判断、トレードオフの評価(例: 軽微なパフォーマンス劣化でもリリースを優先すべきか)
Backlog issue調査Playbook
- AIが担うこと: 不具合の原因調査、Datadog/コードベースの横断分析、Copilotによる修正PR自動生成
- 人が担うこと: 修正PRのレビュー・承認、ユーザー影響の評価、リリースノートへの記載判断
このように、AIは「調査・分析・提案」を担い、人間は「判断・決定・評価」を担うことで、それぞれの強みを活かした品質担保が可能になります。
AIによって自動化されるのは「時間がかかるが判断の余地が少ない作業」であり、「最終的な判断が必要な作業」は人間が担います。この棲み分けにより、QAチームはより本質的な品質評価に集中できるようになりました。
導入を検討する方へ
最後に、同様の取り組みを検討されている方へのメッセージです。
まずは主要導線だけE2E化から始めてみてはいかがでしょうか。
最初から全項目を自動化しようとすると、導入のハードルが高くなります。私たちも、まずはログイン→ホーム表示といった主要導線から始め、徐々にカバレッジを拡大していきました。
小さく始めて、成功体験を積み重ねながら拡大していく。このアプローチが、持続可能なQA改善につながると考えています。
本記事が、ネイティブアプリのQAに課題を感じている皆様の参考になれば幸いです。