
技術本部の柘植です。今回は技術本部サービスリライアビリティグループで1ヶ月間インターン生として参加してくれた漆田さんの記事になります。
はじめに
はじめまして。技術本部サービスリライアビリティグループ(以下SRG)の漆田と申します。SRGは大きく4つのチームに分かれており、その中のWIGというチームに、インターン生として1ヶ月間お世話になりました。
唐突に話が変わりますが、ちょうど私がインターンに来た頃に、AWSがNVMeストレージを備えたI3というインスタンスをリリースしました。このようにNVMeを提供するクラウドサービスが増えてくると、各社のディスクの性能やその特徴を基に適切なものを選択したい、という希望がわいてきます。
これに伴い、AWS、GCP、プライベートクラウドの3通りでNVMeストレージの性能を比較することにしました。今回の記事ではその検証結果を報告します。
NVMeって?
NVMeとはNVM Expressの略称であり、PCIeを通してストレージデバイスを接続できるインターフェース規格です。SSDの能力を最大限活用するために設計されており、SATA接続のものとは比べ物にならないくらいの速度を発揮することが出来ます。SATAの実効転送速度(ボトルネック)は600MB/sですが、PCIe(Gen3)の4レーンだと4GB/sであるため、相応のストレージを使用すれば良い感じの性能が出ます。
気になるストレージの速度ですが、今回検証に使用したプライベートクラウドのNVMeディスクではランダムアクセスでおよそReadが3GB/s, Writeが2GB/sという結果でした。速すぎますね…。RAID0を組めばさらに…。
個人には縁のないものだと思っていましたが、手元のMacbook Proのシステムレポートを覗くとNVMExpressとの記述がありました。こんな身近にあったんですね。
検証
以下検証についてまとめていきます。
早く結論を知りたい方向けにこちらのアンカーリンクを用意しておきました。
検証概要
この検証ではAWS, GCP, プライベートクラウドの対象VMに対して、次の点を調査しています。
- ディスクベンチマーク(IOPS, スループット)
- 平常状態
- 飽和状態
- とあるサービスのI/Oワークロード下での検証
また、使用したインスタンスの詳細は次の表にまとめました。
| プライベートクラウド | AWS | GCP | |
|---|---|---|---|
| InstanceType | nvme-A | i3.8xlarge | n1-highcpu-32 |
| OS | CentOS 7.3 | RHEL 7.3 | CentOS 7.3 |
| vCPU | 32 | 32 | 32 |
| RAM | 125 GB | 244 GB | 28.8 GB |
| NVMe Disk | 1600 GB | 1900 GB x 4 | 403 GB (375 GiB) |
AWSが用意しているCentOSイメージにI3を利用できるものがなかったため、RHELを使用していますが、カーネルのバージョンは全体で統一しています。また、このインスタンスにはあらかじめ4台のディスクが搭載されていますが、ベンチマークを測定する際には1台のみを使用しています。
ディスクベンチマークツールの紹介
ディスクのベンチマークにはaxboe/fioを利用しました。このツールは結構有名で様々なところで使われており、GCPのディスクベンチスクリプトでも使われていたりします。最初はddやhdparmなども考えましたが、fioではI/Oを細かく設定できたり、情報も豊富なため今回はこのツールを選びました。
fioでベンチマークを計測する際に使ったコマンドと重要なオプションを次に挙げます。以降の検証で変動する値は1行目のみで、他は固定になります。
$ fio -readwrite=randwrite -blocksize=4k -numjobs=8 \
-ioengine=libaio -direct=1 -runtime=15 -time_based \
-filename=/path/to/bench_target -name=testbench -group_reporting
| Option | Description |
|---|---|
-readwrite |
I/Oパターンの指定(Sequential Read、Random Writeなど) |
-blocksize |
I/O単位(サイズ)の指定 |
-numjobs |
I/Oを発行するプロセス数の指定 |
-ioengine |
どのようにI/Oを発行するかの指定(同期、非同期など) |
-direct |
ダイレクトI/Oを使用するかどうか |
-runtime |
ベンチマーク終了までの時間の指定(-timebasedにより指定時間分実行できる) |
今回の検証では、できるだけ大量のI/Oを処理してもらいたいため、I/O方式には非同期I/Oを採用しました。また、ディスク自体の性能を測りたいため、ファイルシステムキャッシュなどを通さないようにダイレクトI/OでI/Oを発行するようにしました。
平常時でのディスク性能比較
では、各クラウドのディスク性能を見ていきます。ベンチマークの条件は次のようになっています。
- fioの実行: ディスクと同じマシン
- I/Oサイズ(
-blocksize):4k
I/Oサイズを4kとしているのは、使用しているファイルシステム(ext4とxfs)の最小I/O単位であるブロックサイズが4kであるためです。
この条件で-numjobsを徐々に増やしていき、どのくらいIOPSが出るのか見ていきます。次のグラフはxfsでRadnom Read/Writeを発行したときのものです。
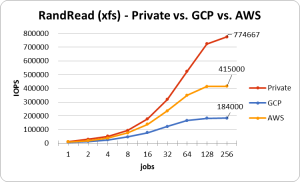
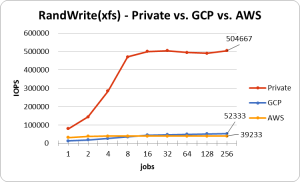
プライベートクラウドで使用しているディスクが全体的に速いですね。とはいえ、これはプライベートクラウドに使用しているディスク依るため、一概にパブリッククラウドが遅いとは言えないため注意してください。
GCP(のWrite以外)とAWSは、下記の公式が提示しているIOPSと同程度のパフォーマンスを発揮しています。AWSのReadはGCPの2倍程度出ているため優秀ですね。一方Writeの方ではGCPの方が少し高いことがわかります。両者のWriteの値は悪くは無いのですが、市販のSSDとあまり変わらないような気もします。公式で提示されているものが、RAID0の複数台構成でのIOPS値であると推測されるため、複数を束ねて扱えという暗示なのでしょうか。
| Cloud | IOPS(Read) | IOPS(Write) |
|---|---|---|
| GCP | 170,000 | 90,000 |
| AWS | 412,500 | 37,500 |
ディスク数の関係で公式のIOPSが高くなっていますが、今回は単一ディスクでのベンチマークを取るため、ディスク1つあたりのIOPSを記載しています。
GCP公式とAWS公式
GCPのWriteですが、公式通りのIOPSを発揮してくれるファイルシステムがありました。
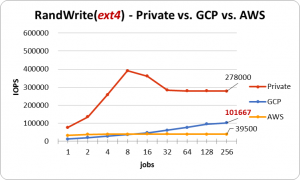
このグラフはファイルシステムがext4のときのものです。ext4の場合、プライベートクラウドやAWSは総じてパフォーマンスが落ちるのですが、GCPに関してはext4のときに良いパフォーマンスを発揮していました。ディスク飽和状態での検証でも同じ傾向が現れていたため、検証ミスということはなさそうですが、結局原因はわからずじまいでした…。
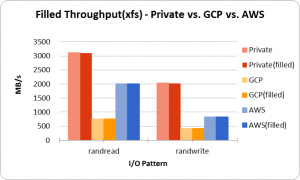
次にスループットの計測を行いました。この計測には、I/Oサイズを32mといったI/O命令発行のオーバーヘッドを無視できる程度のサイズにすることで計測しています。
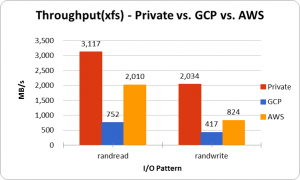
IOPS(Write)ではGCP > AWSだった一方、スループットではAWS > GCPとなる面白い結果になりました。大容量ファイルなどの書込時にはスループットが指標となるため、AWSはそういった書込みに対しては強いということがわかりました。
飽和時でのディスク性能比較
Random Writeによりストレージ使用率を99%まで飽和させたときのベンチマークも計測しました。その他条件は先ほどの検証と変わりません。
次のグラフはxfsでRadnom Writeを発行したときのものです。
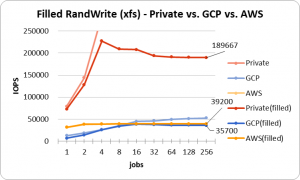
Readは読み込むだけであるためパフォーマンスには影響ありませんが、WriteではNAND型フラッシュメモリの上書きができないという性質があるためか上記のような性能劣化が見られました。こんなにストレージがカツカツな状態で運用することはあまりないと思いますが、こういう仕組みだから遅くなるんだろうなあ、などと考察ができることがとても楽しいですね。
プライベートクラウドとGCPのストレージは書込IOPSが低下したわけですが、AWSは平常時と全く変わらない結果となっています。以前社員の方から、「SSDはパフォーマンスのためにOSから見える領域以上に、余分な領域を確保していることがある」と伺ったので、もしかしたらそのおかげで性能の劣化を抑えているのかもしれません。AWSの中の人ではないため完全な推測ですが。
また、スループットはRead/Writeどちらも平常時と変わりませんでした。
特定I/Oワークロード下でのディスク性能比較
この比較では細かいI/Oを発行するDBを想定して、そのI/Oに対してどのくらいの速度で捌けるかを検証します。
とあるサービスのメトリクスから1リクエストあたりのストレージI/Oを求め、それをfioが発行するI/Oサイズとしました。リクエストによりデータのサイズは変動するため、I/Oサイズは範囲指定しています。
- Read I/Oサイズ(
-blocksize_range):4k - 32k - Write I/Oサイズ(
-blocksize_range):8k - 32k
ベンチマーク結果は次のようになりました。
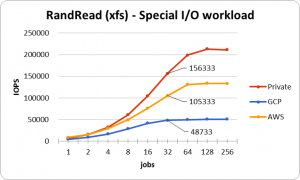
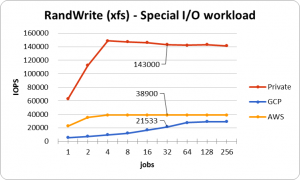
実際に扱われているものはSQLの処理などにより実際のIOPSは低くなりますが、これを許容できるリクエスト数とみなすことにします。仮に、使用しているDBの待機プロセス/スレッド数が32だった場合、このグラフのjobsが32のときの値が許容できるリクエスト数になります。今回参考にしたサービスは6000 Request/sec程度だったため、ストレージ的にはどこでも余裕があることがわかりました。
ここのグラフで気になる点はAWSのWrite IOPSです。通常IOPSというものはI/Oサイズが大きくなるほど低下するものです。これはそのI/Oサイズを読込/書込することに伴うレイテンシが増加するためです。そのためプライベートクラウドとGCPは数値が低下していますが、その一方でAWSは平常時とほとんど同じの性能を出しています。IOPS単位で制限をかけているとしたら納得がいきますが、これについては実際にどうなっているかはわかりません。
その他トラブルなど
検証中に起きた出来事を一部まとめておきます。
- ベンチをかけた後OSが起動しなくなる
インターン開始数日のLinuxのストレージの扱いにあまり慣れていなかったときに起きたトラブルです。これはfioのベンチマークターゲットに/dev/vdaを指定したことが原因でした。実はこの/dev/vdaは操作しているVMのルートディスクであり、ベンチをかけることで見事にファイルシステムが蹂躙されてしまいました。今思えばそんなことするやついるかとツッコミたくなりますが、当時の私はやってしまったようです。
- GCPインスタンスシャットダウン後、起動できない
これはGCPのLocal SSDの特性を理解していなかったために起きたトラブルです。GCPのLocal SSDのページには次のように書いてあります。
ローカル SSD を使用するインスタンスを停止し、再起動することはできません。ゲスト オペレーティング システムを介して、ローカル SSD を使用するインスタンスをシャットダウンすると、インスタンスを再起動することはできまず、ローカル SSD 上のデータは失われます。
このようにGCPのLocal SSDはインスタンスを落とすと再度起動することはできません。実運用で使用する際には大事故につながるため、しっかりと気をつけたいところです。さらに詳しい条件はここに書いてあります。
これについてはおそらくAWSのI3も似たような仕組みになっており、こちらも一度インスタンスを落とすとデータが失われて正常に起動しないことがありました。
まとめ
今回の検証をまとめると次のようになります。
- ファイルシステム
基本的にext4よりxfsの方が良い性能を出した(OSにRHEL7系を選択したことも多少影響しているかも知れない)。プライベートクラウドとAWSはxfsの方がIOPSが高いが、GCPに関してはext4で良い性能を発揮した。
- Read
公式通りAWSが高い性能を発揮した。
- Write
xfsで使用する場合はAWS、GCPどちらも同じ程度だったが、ext4を使用した場合、GCPはAWSの2倍以上の性能が出た。しかしその一方で、4kより大きいI/OサイズだとIOPS、スループット共にAWSの方が高い性能を発揮した。
このように簡単にまとめましたが、各社のクラウド提供にはそれぞれ違いがあり、上記のようなストレージ性能のみでクラウドを選択することは難しいと思われます。例えばGCPのローカルSSDは拡張しやすいですが、AWSはインスタンスタイプにストレージが紐付いているため、ストレージが4台欲しい場合は32コアのi3.8xlargeを選択する必要があります。また、GCPではインスタンス1台が保持できる最大ストレージ容量が3000GiBですが、AWSだと15200GB使えたりなど。他にも、コスト面ではGCPが自動割引が適用されたりなど、考慮すべきポイントがたくさんあります。
それらを考慮した上で、この検証がクラウド選択の1つの指標になれば幸いです。
おわりに
この1ヶ月強のインターンを通して、知識はもちろんのこと、しっかりとした仕事の進め方を身につけることが出来ました。例えば検証作業において、事前準備や検証方法の策定が難しく行き詰まったことも多々あったのですが、そういったときに検証というタスクを適度に分割してTODOを洗い出したり、その筋に詳しい人に聞くなどして何とかやり遂げることができました。
また、チームWIGで週に一度ミーティングがあるため、そこで「こういう方針、やり方で進めようとしている」という話をすると直接レビューを頂けたりしました。これはすごくありがたいことですし、たくさんのノウハウなどを聞くことができて気分が高まったのを覚えています。
あと意外とSRGにはグルメな人が多く、期間中のランチはほぼ毎日違うお店に連れて行ってもらっていました。そこで会社の話や、その他いろいろな話などをして、社内の雰囲気も詳しく知られたのでとても良かったです。
そんな感じで楽しくあっという間に過ぎてしまった1ヶ月間でした。
検証が軌道に乗るようにたくさんの指導をしてくださったメンターの柘植さんをはじめ、WIGを含むSRGのみなさん、その他助けていただいた方々にはとても感謝しています。
1ヶ月間本当にありがとうございました!