
コンピュータビジョンとパターン認識の国際会議CVPR 2017に、CyberAgentからアドテク本部AI Lab所属の山口、大田、谷口の3名が聴講参加してきました。CyberAgentアドテク本部ではエンジニア、リサーチ関連職の技術レベルの向上を目的に、学術会議への参加や論文投稿を行なっております。今回の記事では今年のCVPRでの研究の最新動向についてお伝えします。
CVPRについて
CVPRはICCV/ECCVとともにコンピュータビジョン研究のトップ会議で、世界中の研究者が毎年一堂に集まり研究討論を行います。学術関係者だけでなく、近年は企業向けにトレードショーのようなEXPOも併催されるようになっています。
CVPR 2017はワークショップやチュートリアル含め全体で6日間の日程で、今年はジカ熱流行による開催地変更の紆余曲折を経てホノルルのコンベンションセンターにて開催となりました。ここ数年のAI関連分野の拡大に沿って、2017年も800件近い発表と5000名近くの参加者と過去最大を更新しています。オープニングでは今年のアワードは深層学習モデルのアーキテクチャ、教師なし学習、データセットのアノテーション、物体検出、コンピュテーショナルフォトの各トピックから選ばれました。画像の意味理解、学習に関連した研究の強さが目立ちます。



研究動向
以下ではAI Labが注目する研究発表を研究テーマごとにピックアップして紹介します。
物体検出
画像のクラス分類に比べ、まだ性能改良の余地がある検出タスクであるが、ここ1-2年ほどで性能が高く速い手法が次々に提案されている。今回のCVPRでもYOLO9000は高速動作が印象的でした。
YOLO9000: Better, Faster, Stronger
Joseph Redmon, Ali Farhadi
https://arxiv.org/abs/1612.08242
プロジェクトサイト
2016年のCVPRで発表された物体検出アルゴリズムYOLOを改良したもの。動画にもある通り、検出精度を高めつつもとにかく高速なリアルタイム物体検出を目指し、クラスタリングによるアンカー位置の削減、複数解像度での学習、ラベルの階層構造を利用したクラス予測、などのチューニングが施されています。CVPRでは実機によるデモンストレーションを行い会場を沸かせました。Best paper honorable mention。
Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors
Jonathan Huang, Vivek Rathod, Chen Sun, Menglong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, Kevin Murphy
https://arxiv.org/abs/1611.10012
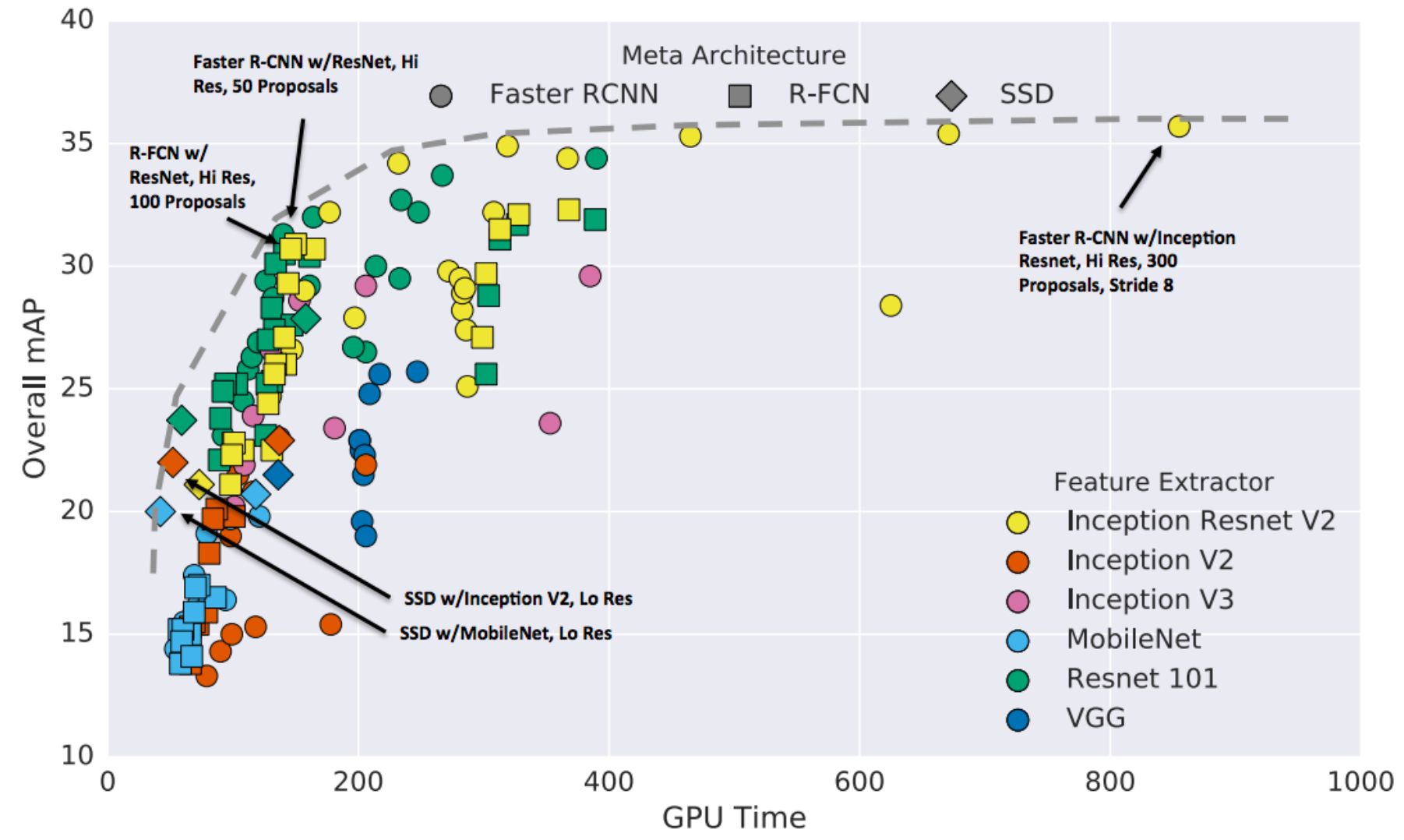
物体検出器について、使用する画像特徴抽出用のネットワーク、検出モデル(Faster RCNN, R-FCN, SSD)の組み合わせについて測度と検出性能を評価したサーベイ発表。これから物体検出を始める際にどのモデルを使用すると良いのか参考になると思われます。ちなみにYOLO9000は上の図2のどのモデルよりもぶっちぎりで速いという結果だったようです。
深層学習モデルの解釈
深層学習モデルは巨大なパラメータ数を持ち、内部の解釈が困難です。ともするとブラックボックスとして扱われることもありますが、その内部動作を理解するための取り組みもいくつか見られます。
Network Dissection: Quantifying Interpretability of Deep Visual Representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, Antonio Torralba
プロジェクトサイト
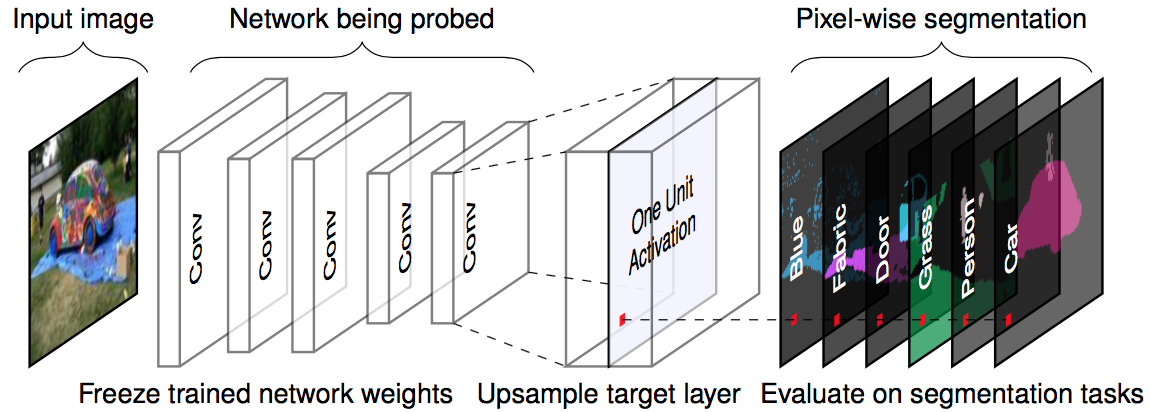
セマンティックセグメンテーションを使って深層学習モデルの内部発火が何に対応するのか解釈する提案。Bolei Zhouらは過去にもニューラルネットワークの内部発火の理解に取り組んできており、今回はセグメンテーションを取り入れてダイレクトに可視化できる点が新しい。セグメンテーション用のモデルの学習データセットに限りがありそうですが、直接的なユニットの解釈が可能です。
Neural Scene De-rendering
Jiajun Wu, Joshua B. Tenenbaum, Pushmeet Kohli
プロジェクトページ
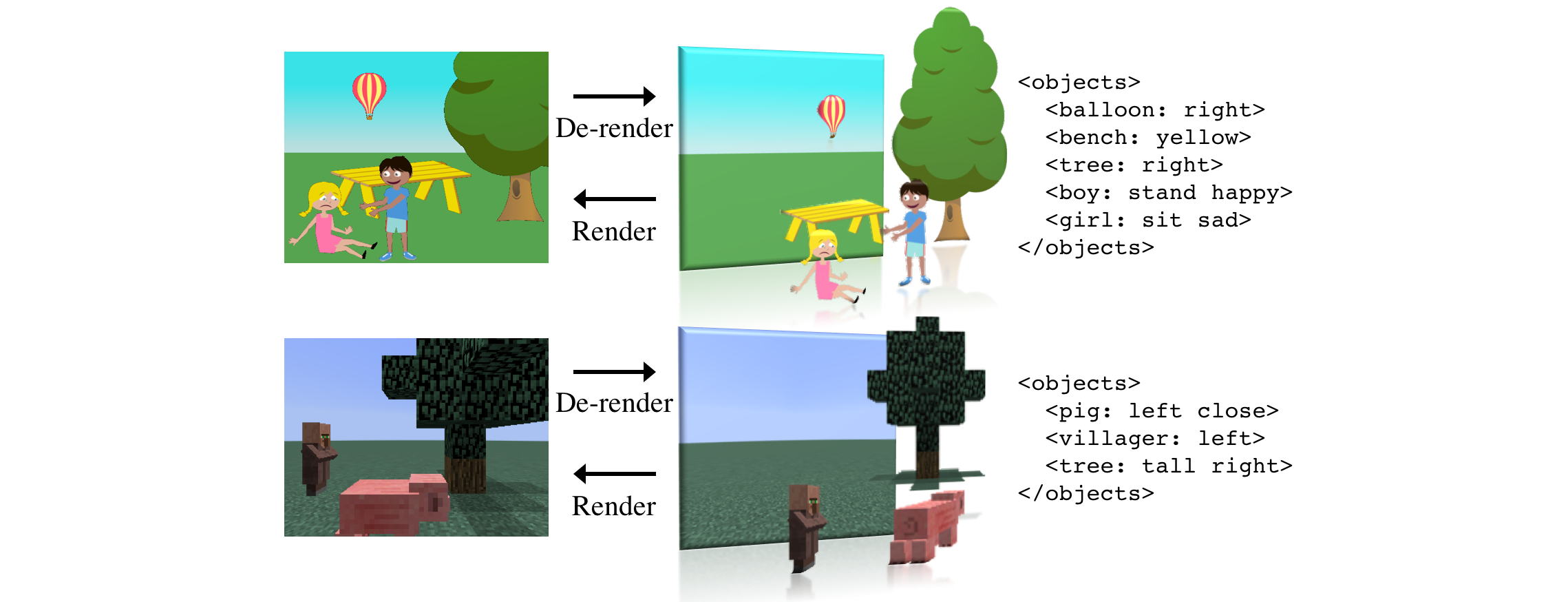
シーンの全体理解を表現するコンパクトで理解可能な表現として、XML形式の言語表記を提案し、その表現を推論するためのEncoder-Decoderモデルを構築した取り組み。Decoderには一般のグラフィクスエンジンを利用し、強化学習を利用してXMLによるパラメータ表現を学習している。解釈、再利用可能な表現方法は例えばクリエイティブ応用でも利用価値が高そうです。
マルチタスク学習
UberNet: Training a Universal Convolutional Neural Network for Low-, Mid-, and High-Level Vision Using Diverse Datasets and Limited Memory
Iasonas Kokkinos
https://arxiv.org/abs/1609.02132

予測タスク毎に巨大な深層モデルを学習するのは実利用上のボトルネックとなるため、ローレベルからハイレベルまで多数のタスクに共通の深層モデルを学習するという試み。全てのタスクに共通して使えるようなデータセットがないため、バッチ単位でバックプロパゲーションする箇所を切り替え、またメモリを圧迫しないように工夫して学習している。少数のタスクでは共通で学習した方が単一タスクより性能が上がったが、タスクが増えすぎると性能が下がるという実験結果は興味深い。
From Red Wine to Red Tomato: Composition With Context
Ishan Misra, Abhinav Gupta, Martial Hebert
http://www.cs.cmu.edu/~imisra/data/composing_cvpr17.pdf

「赤りんご」の「赤」と「赤ワイン」の「赤」はおそらく違う色を示しています。このように、形容詞のような属性、例えば、「赤」や「ふわふわ」と、物体カテゴリ、例えば「ワイン」や「りんご」の間には、コンテクスト依存性があります。このようにコンテクストを全て学習するのは非現実的なため、独立した識別器を合成するというアプローチを提案した研究です。多数の語を予測するような場面では、このようなコンテクスト依存性を明示的に考えて予測モデルを組み立てるのは有効に思われます。
広告応用
Automatic Understanding of Image and Video Advertisements
Zaeem Hussain, Mingda Zhang, Xiaozhong Zhang, Keren Ye, Christopher Thomas, Zuha Agha, Nathan Ong, Adriana Kovashka
プロジェクトサイト

広告画像から受ける印象やメッセージをいかに機械学習を用いて理解するか、データを収集して分析、方向性を調査した論文。広告を対象として画像認識モデルを使うには、物体そのものだけでなくそこに込められた隠喩などの深い意味を理解する必要がありますが、現在の物体認識システムではまだまだ自動で認識ができるレベルまでは到達していないことが基礎的な実験で示されています。この論文ではデータセットを収集、構築し、今後取り組むべき課題をいくつか提案しています。
クリエイティブ
画像を生成する試みはここ数年Generative Adversarial Networks (GAN)が流行していますが、ゼロからのピクセル単位の生成は今の所実応用に使えるレベルには達していないというのが正直な印象です。ただ、与えられた画像を編集したりより写実的にするような試みは以前からずっと研究が続いていて、例えばクリエイターの支援などにすぐに使える技術は見られます。
Learning From Simulated and Unsupervised Images Through Adversarial Training
Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Joshua Susskind, Wenda Wang, Russell Webb
https://arxiv.org/abs/1612.07828

あのアップルが学術論文を公開したということで昨年冬にarXivで話題になっていた論文。なんとCVPRのベストペーパーを受賞。内容は、実画像ではなくCGを使って生成した画像に、実画像っぽい効果をつけるAdversarial trainingの手法について。データそのものは実用性があまりなさそうな実験内容ですが、昨今の深層学習に使うデータセット構築コストを解決する一つの方法ではありそうです。
Neural Face Editing With Intrinsic Image Disentangling
Zhixin Shu, Ersin Yumer, Sunil Hadap, Kalyan Sunkavalli, Eli Shechtman, Dimitris Samaras
プロジェクトページ

CGを使わず、2次元の入力画像から顔の属性を直接編集する試み。内部では表面幾何、アルベド、照明をネットワーク内できちんとモデリングし、End-to-endで学習できるようにしています。サングラスを追加するなど、顔画像の編集がよくできています。
Awesome Typography: Statistics-Based Text Effects Transfer
Shuai Yang, Jiaying Liu, Zhouhui Lian, Zongming Guo
https://arxiv.org/abs/1611.09026

フォントの装飾効果を他の画像から移植するという試み。例えば炎を纏ったような視覚的装飾を他の画像から持ってくることができる。深層学習は使っておらず、画像のフォントデータからの距離変換をInpaintingにうまく取り入れて最適化している。既存のクリエイティブ資産が多数あるような制作現場では利用価値が高いのではないでしょうか。
Fast-At: Fast Automatic Thumbnail Generation Using Deep Neural Networks
Seyed A. Esmaeili, Bharat Singh, Larry S. Davis
https://arxiv.org/abs/1612.04811

画像のサムネイルの自動生成。指定される画像サイズと、クロップ領域を深層学習モデルを使って自動で決定する。例えば様々なサイズのバナー画像を制作する際に素材画像をクロップするような場面で重宝しそうです。
VQA対話モデル
AI Messengerのようにチャットボットは様々な場所で利用されるようになってきましたが、画像にまつわる質疑応答技術はVisual Question Answering (VQA)と呼ばれ、CVPRではこれまでにも様々な問題設定で研究がなされてきました。初期の研究の取り組みに比べデータセットが充実し、より画像の深い内容理解に踏み込んだチャットボットが提案されています。
Visual Dialog
Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José M. F. Moura, Devi Parikh, Dhruv Batra
visualdialog.org
画像と履歴から内容に踏み込んだ対話ができるように設計されたチャットボット。プロジェクトサイトではデモも公開しています。また、この研究では新規にデータセットも公開していて、画像を含むチャットボット研究が一段と進みそうです。
おわりに
CVPRの数多くの発表の中からAI Labとして気になる研究を紹介しました。単純な画像分類問題であれば深層学習モデルで人間を超える性能が出せるようになり、今年のCVPRではここ数年の画像認識性能の急激な改善に貢献してきたImageNetのコンペティションが最終開催となりました。もはや画像認識技術は成熟し、自動運転やEC関連など数多くの企業がExpoに参加するなど、学術研究から画像認識を使ったビジネス創出への流れが進んでいる印象を受けました。CyberAgentのAI Labでは特に広告クリエイティブの制作支援と自動生成、広告配信の最適化、接客対話システムを中心に研究を進めています。皆さまに素晴らしい製品体験ができるよう引き続き研究開発に取り組んでまいります。