
機械学習の国際会議であるICML2017に、アドテク本部データサイエンティストの金本が参加してきました。本稿では個人的に気になった研究をピックアップする形で参加報告をさせて頂きます。
ICMLについて
ICML(International Conference on Machine Learning)はNIPSと肩を並べる機械学習関連のトップカンファレンスで、機械学習の様々な分野の研究発表が行われました。その中でも深層学習の割合は年々増加しており、本稿の報告も主に深層学習関連となっています。論文を受理された研究機関についての分析も報告されており、やはりGoogle/DeepMindが群を抜いています。今年はシドニーでの開催となり、欧米からのアクセスの問題もあり参加者数は前年(@ニューヨーク)と比べ多少減少したようでした。

論文ピックアップ
Decoupled Neural Interfaces using Synthetic Gradients
DeepMind
https://arxiv.org/abs/1608.05343
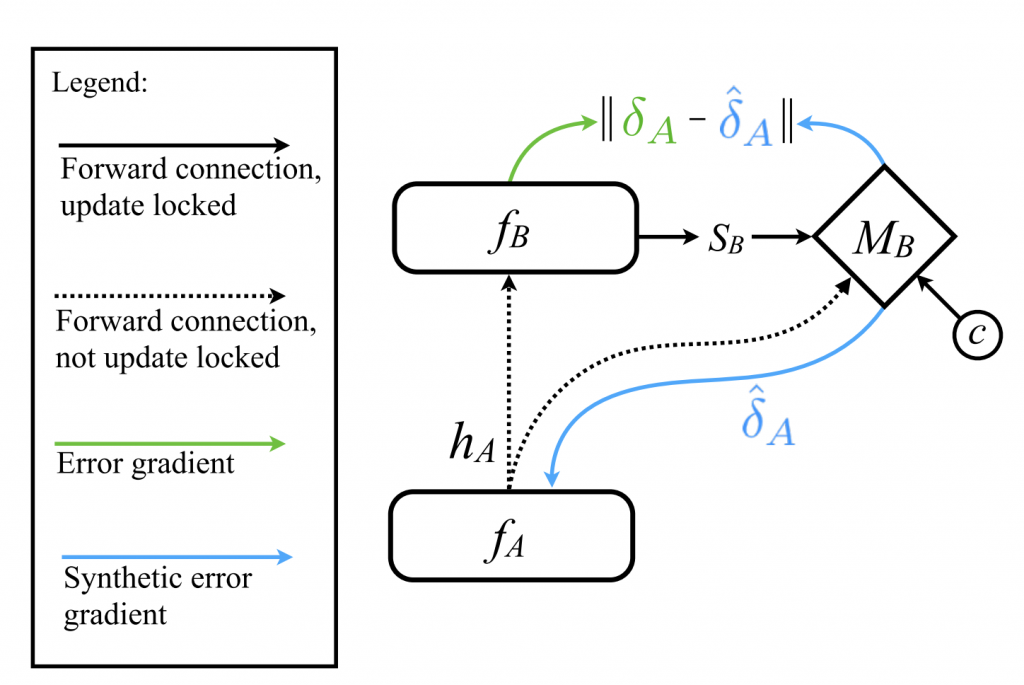
ネットワークを学習させるにあたり順方向/逆方向の伝播を要するが、これにより各層が様々な形で”lock”された状態に陥っている。その中でも、注目している層以降の層が順方向伝播を終えるまで待つ必要性がある状況をupdate lockingと呼び、この制約によりネットワークの学習はスケール出来なくなっている。それを乗り越えるためにネットワーク全体の知識を必要としない独立で非同期な学習モジュールが必要であるという目的意識のもと、注目している層の直後に局所的な情報のみを用いて誤差勾配を予測するsynthetic gradientを導入することによりupdate lockingを除去し、ネットワーク全体を複数のモジュールへと分割する手法を提案している。
Understanding Black-box Predictions via Influence Functions
Stanford University
https://arxiv.org/abs/1703.04730
ICML2017のベストペーパー。 ブラックボックス関数であるニューラルネットワークにおいてモデルがなぜその予測をしたかを知るというのは重要であるという問題意識のもと、統計学において古典的な手法であるinfluence functionを用いて個々の学習データと予測結果の関係性を調べる手法を提案。二次微分の計算や微分可能性・convexityの仮定が機械学習へのinfluence functionの導入の障壁となってきたが、二次最適化手法により精度を保ちつつinfluence funcitonの近似を得る手法を提案している。SVMと比べニューラルネットワークが画像中の特徴を捉える様や、モデルが誤った予測をした際のデバッグへの応用などが示されている。
Learning to Generate Long-term Future via Hierarchical Prediction
Google Brain
https://arxiv.org/abs/1704.05831
人の動きを推定した動画を生成するモデルを提案。画像から姿勢を推定したのち、sequence2sequenceにより姿勢の遷移を推定。訓練時の姿勢と推定された姿勢の差分をとり、訓練時の画像と組み合わせて画像の遷移を推定するネットワークを構築して動画を生成。デモ動画は圧巻のクオリティ。
Efficient softmax approximation for GPUs
FAIR
https://arxiv.org/abs/1609.04309
RNNを自然言語処理に適用する際、ボキャブラリーの大きさよりsoftmaxの計算が大きな負担となる。そこでボキャブラリー中の少数の単語が出現割合のほとんどを占めること(Zipf law)を利用し、(2クラスの場合)出現頻度の高いクラスターと低いクラスターに分けてclass-based hierachical softmaxを行うことにより計算を効率化。softmaxと比べてほぼ同等の性能で、より早く学習を行えた。既に以下のFAIRの論文でも使用されている。
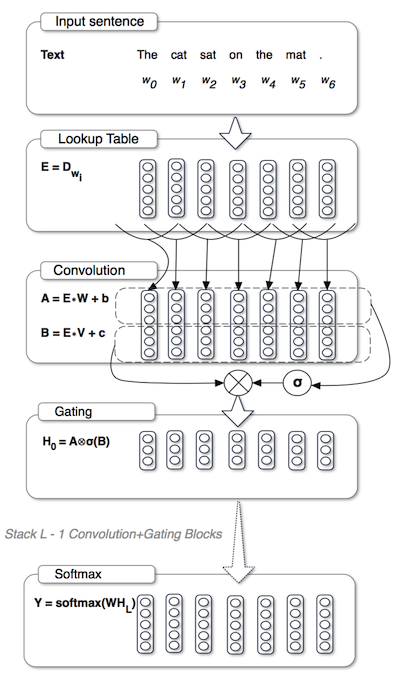
Language Modeling with Gated Convolutional Networks
FAIR
https://arxiv.org/abs/1612.08083
RNNを自然言語処理に適用する際には連続したトークンを並列処理できないという問題があり、それを解決するためにgated CNNモデルを提案。ゲート機構やresidualブロックを加えることによりRNNに対してもcompetitiveな性能を達成。並列化により処理速度がRNNに比べて20倍程度に向上。
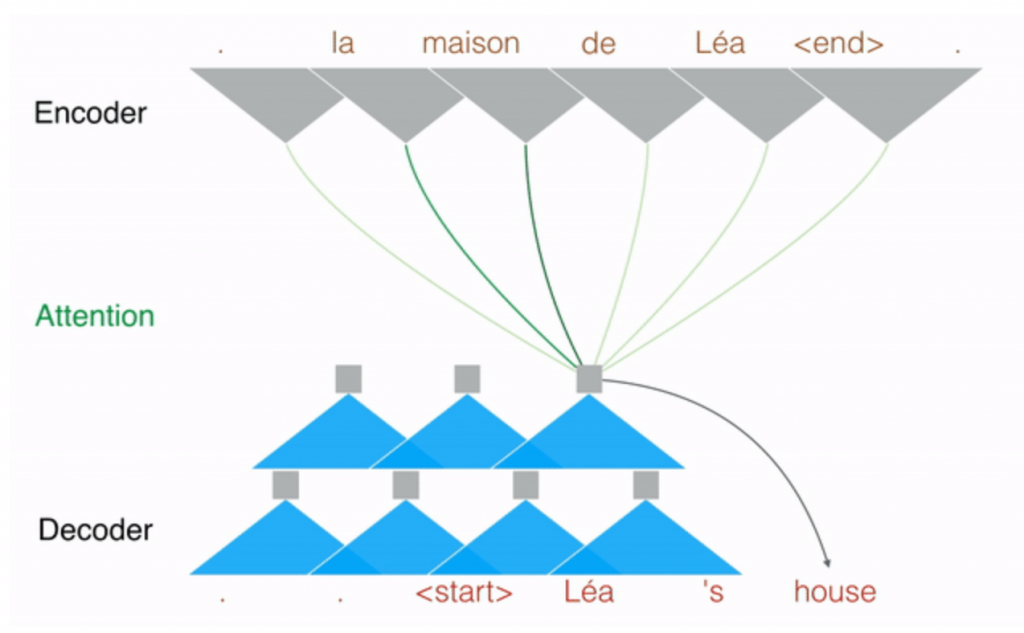
Convolutional Sequence to Sequence Learning
FAIR
https://arxiv.org/abs/1705.03122
上記のstacked gated CNNを用いてattention付きsequence2sequenceモデルを構築。GNMTを上回る性能を約9倍の速さで達成。githubにコードあり。ただしdecoderは並列処理できないのになぜこんなに速いのかという会場の質問に対する回答は曖昧だった。
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
SK T-Brain
https://arxiv.org/abs/1703.05192
対応関係のない2組の画像に対してGeneratorとDiscriminatorを2組掛け合わせた上で、Generatorの入出力に対しても制約を加えた構造のGANの一種(DiscoGAN)。対応関係のあるデータを必要としないのが利点であり、またmode collapseはあまり起きていない模様。原理的にはCycleGANと同じ。
Gradient Boosted Decision Trees for High Dimensional Sparse Output
http://www.stat.ucdavis.edu/~chohsieh/rf/icml_sparse_GBDT.pdf
GBDT(Gradient Boosted Decision Tree)でmulti-label classificationを行う際にlabelの次元が非常に大きい際には学習の遅さやモデルの大きさが問題となるが、各弱学習器が上位のlabelのみを保持するL0正則化を加えることにより対処する方法を提案。また入力データが疎であることにより決定木がimbalancedになる問題に対しては、LEMLという教師あり学習により低次元に落とし込んで対応。
Deep Voice: Real-time Neural Text-to-Speech
Baidu Research
https://arxiv.org/abs/1702.07825
リアルタイムでテキストを音声化する手法を提案。テキストをsequence2sequenceでphonemes(音素)に変換、次にphonemesをsequence2sequenceでf0(fundamental frequency)とdurationに変換したのち、WaveNetにかけて音声化。アルゴリズムやハードウェアに様々な工夫を重ねて実用的なスピードを達成。
Dynamic Word Embeddings
Disney Research
https://arxiv.org/abs/1702.08359
年月とともに変わっていく単語の意味の遷移を捉える確率的word2vecモデル。年度ごとに別々にモデルを作るのではなく、latent diffusion processにより各時点でのベクトル表現を動的に繋げるモデルを提案。以下の動画が視覚的で分かりやすい。
Dance Dance Convolution
UCSD
https://arxiv.org/abs/1703.06891
音声ファイルからDance Dance Revolutionの譜面を自動生成するニューラルネットワークを提案。ステップをいつ配置するかの問題に対しては音声スペクトグラムをCNN/RNNで学習し、どのステップを配置するかに対してはRNNで学習。
おわりに
ICML2017から気になった論文をいくつかピックアップして参加報告とさせて頂きました。発表者としてもスポンサーとしても数多くの企業が参加しており、ますます機械学習の分野において大学との垣根がなくなっていることを実感しています。世界の研究の最先端に触れることで、個人としても非常に刺激を受けた6日間となりました。少しでもこのレベルに近づけるよう日々努力していきたいと思い直した次第です。
