
初めまして。サイバーエージェント技術本部インフラエンジニアの@prog893です。今回は「AWA」という音楽ストリーミングサービスのMongoDBクラスタの復旧時間を短縮するために行ったインフラの改善について紹介したいと思います。復旧時間が12時間から55分まで短縮できたのですが、皆さんの参考になれば幸いです。(※注意:今回紹介する施策はAWAのインフラ構成や設定のものであり、他の環境で同じような効果が得られるとは限りません)
AWAのデータストア構成
まず、現在のデータストア構成について軽く説明します。こちらの図でAPIサーバ,MongoDBに関連する構成の概要を示します:
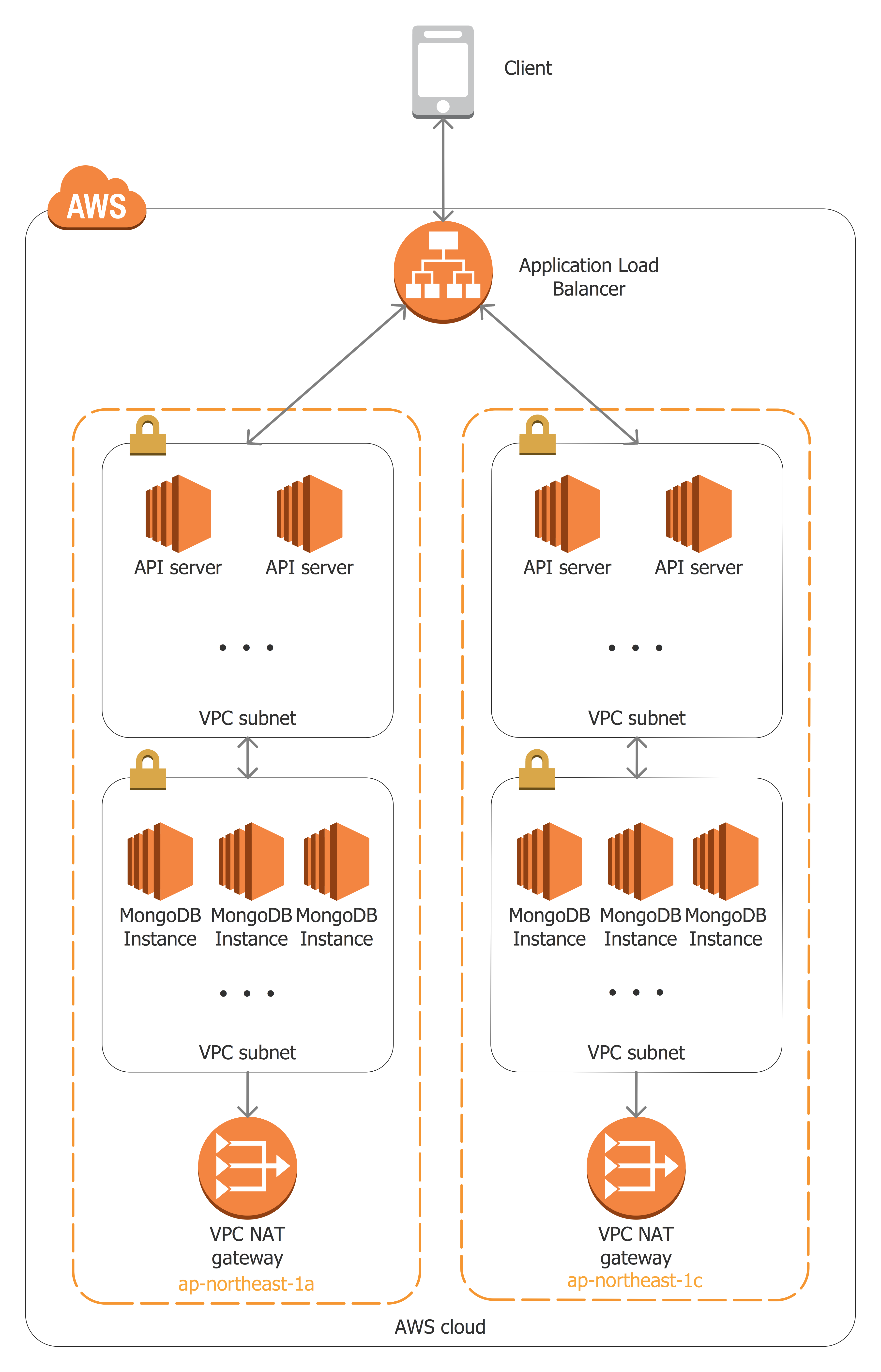
メインのデータストアとしてはMongoDBを使っており、MongoDBのインスタンスはAWSで管理しています。APIサーバ、MongoDBのインスタンスがそれぞれのプライベートサブネットに配置されています。APIサーバへのリクエストはApplication Load Balancerを介してのみ可能であり、APIからMongoDBへのアクセスはVPC内、プライベートサブネット間で行われます。MongoDBクラスタの管理、データのバックアップのためにMongoDB Cloud Managerを利用しており、各MongoDBインスタンスはCloud Managerと通信する必要があります。Cloud Managerとの通信のために、当初はNAT Instanceを使っていましたが、後述する通り現在はNAT Gatewayを使うようになっています。アベイラビリティゾーン(AZ)単位の障害が起きてもサービスの提供ができるように、それぞれのAZでは同じ構成を構築しており、MongoDBクラスタではレプリケーションを設定しています。
復旧が、実はめちゃくちゃ遅かったと気付いた瞬間
Mongo Cloud Managerでは、インクリメンタルバックアップを取ることが可能であり、特定の時点の状態に復旧できるという、point-in-time recovery機能があります。AWAでは、障害発生時この機能を使って復旧を行います。
ある日、障害が起きてDBが真っ白になってしまいました。幸い障害直前までのバックアップがあったので、データのロストは避けることができました。リリース当初、許容範囲内だった復旧時間が、データの増加によりデータが増加し続けたため、ものすごく延びてしまい、12時間以上かかることが判明しました。この障害の反省を活かし、障害時になるべく早く復旧できるよう、バックアップ周りのリフォームを行うことになりました。(障害をそもそも起こさせた原因の対応ももちろん行いましたが、今回の記事ではそれを割愛し、リストア高速化に着目します)
素直にサポートに問い合わせてみる
Cloud Managerのサポートチーム(Cloud Team)に現状の復旧時間、現状の設定、目標時間(当初2時間とした)などを伝え,サポートケースで問い合わせをしてみました。パラメータ最適化などについてアドバイスをいただくなど、手厚くサポートしていただきました。助言通りに設定等を行ったら、復旧時間がとりあえず6時間まで短縮できました。目標時間からはまだ遠いので、続けて調査しました。(ここで行った具体的な作業は割愛しますが、Cloud Manager Backupをお使いの皆様にはサポートに問い合わせてみることを強くおすすめします)
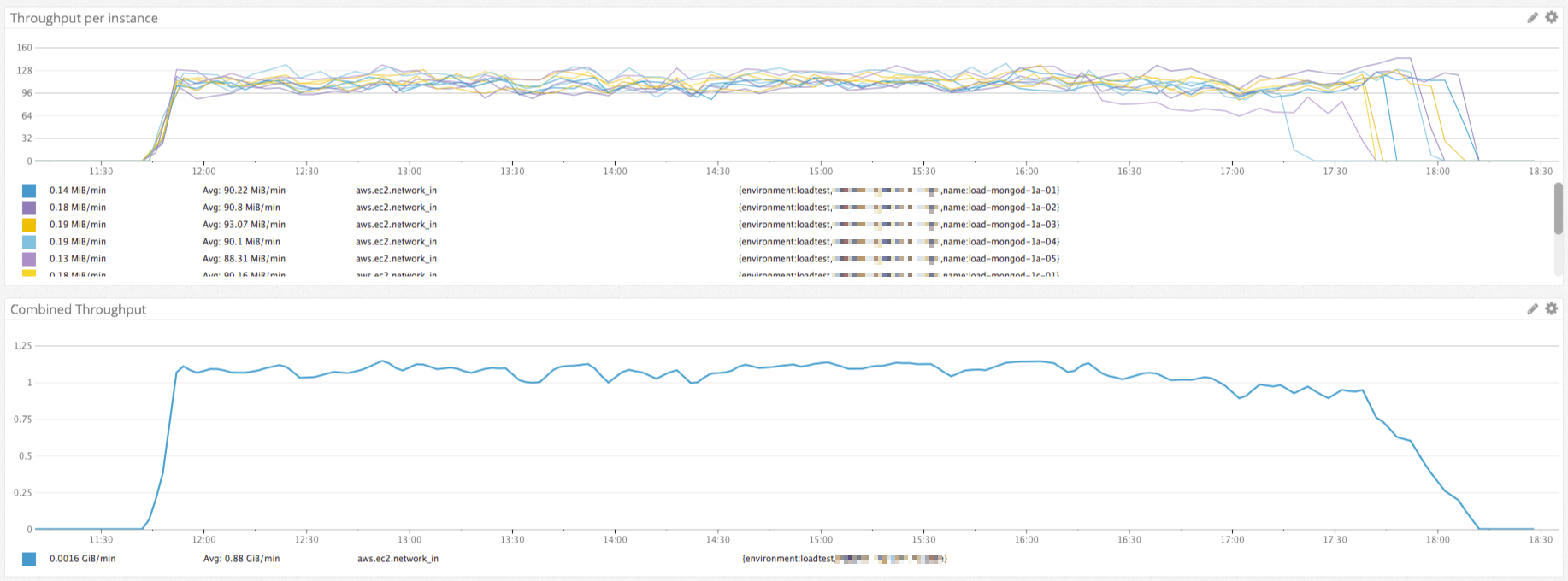
NAT Gateway
上記の設定変更後に行った復旧テストのインスタンス別の帯域が気になりました。ネットワークレイヤーを疑い、ネットワークレイヤーに限定したテストを設計し、実行してみました。
まず、東京リージョンで二つの検証インスタンスを用意しました。一つは、ネットワークデフォルト設定(パブリックネットワーク)、それ以外の設定やAMIなどはAWAの本番DBと同じインスタンスです。もう一つは、AWAの本番DBと全く同じインスタンスです。つまり、ネットワーク設定だけが違っています。
次に、二つのテストインスタンスでテスト用ファイルをcurlでバックアップ保存先リージョンからダウンロードするというスクリプトを実行して帯域を測ってみました。結果、デフォルト設定インスタンスの方がダウンロード速度が圧倒的に速く、帯域が数倍違っていました。これは絶対ネットワークだ!と確信を持ち、ボトルネックを探り始めました。
二つのテストインスタンスの唯一の違いが、前述の通りネットワークの設定です。今回の測定で遅かったインスタンスは、プライベートネットワークを使っており、グローバルとの通信がNAT経由で行われています。
AWSにおけるプライベートネットワークは、0.0.0.0/0のルートを持たないか、インターネットゲートウェイ(IGW)でないものに転送するルートを持つネットワークのことを指しています(参考:https://docs.aws.amazon.com/ja_jp/AmazonVPC/latest/UserGuide/VPC_Subnets.html)。AWAのDBインスタンスが使っているプライベートネットワークでは、0.0.0.0/0のルートでNAT Instanceに転送するというルールになっていました。
AWAでは、MongoDBやSecurity Groupの設定ミスなどによる不正アクセスを防ぐために、DBクラスタやAPIサーバにパブリックIPを持たせず、プライベートサブネットに配置することでグローバルから直接アクセスできないようにしています。例えば、APIに対するリクエストをロードバランサ(ALB)が受信し、リクエストがVPC内の通信でバックエンドに転送されます。
NAT Instanceは、パケットを転送するように設定されているEC2インスタンスとなっており、ネットワーク帯域が使用するインスタンスタイプによって決まります。ネットワークを設計していたタイミングでは、NAT InstanceしかNATを実現する方法がありませんでした。2015年12月にNAT GatewayというNAT Instanceに変わる、マネージド型NATが発表されました(参考:https://aws.amazon.com/blogs/aws/new-managed-nat-network-address-translation-gateway-for-aws/)。インスタンスを管理する必要がなく、一つのNAT Gatewayあたりの帯域が最大10 Gbpsとなっています。10Gbpsの帯域を持つEC2より安くなっていることもポイントです。
さらに、NAT Instanceが冗長構成になっていなかったこともボトルネックになっていたと考えられます。リージョンには複数のアベイラビリティゾーン(AZ)があります。NAT Instanceがアベイラビリティゾーン(AZ)ごとに用意されていなければ、NAT Instanceが存在しないAZからのグローバルとの通信が発生する際に、AZ間の通信が発生します。AZ間の通信によってさらに遅延が出ると考えられます。NAT Gatewayでも同様です。
まとめとして、ネットワークのボトルネックは、帯域の狭いNAT Instanceを使っていること、NATが冗長化構成になっていないことがわかりました。早速、NAT InstanceをNAT Gatewayに置き換え、冗長化構成にしました。これで環境の推定最大ス帯域が300 Mbit/sから20 Gbit/sと、大きく改善されました。同時に、AZを跨いだ通信がなくなり、遅延が軽減し、耐障害性を高めることができました。
バックアップリストアが改善されたかを確認するために、再びテストを行ってみました。リストアテストの結果、完全復旧にかかる時間が2時間20分まで短縮できました。すっごーい!でも、もっと頑張れる気がしたのでさらにボトルネックを探ってみることにしました。
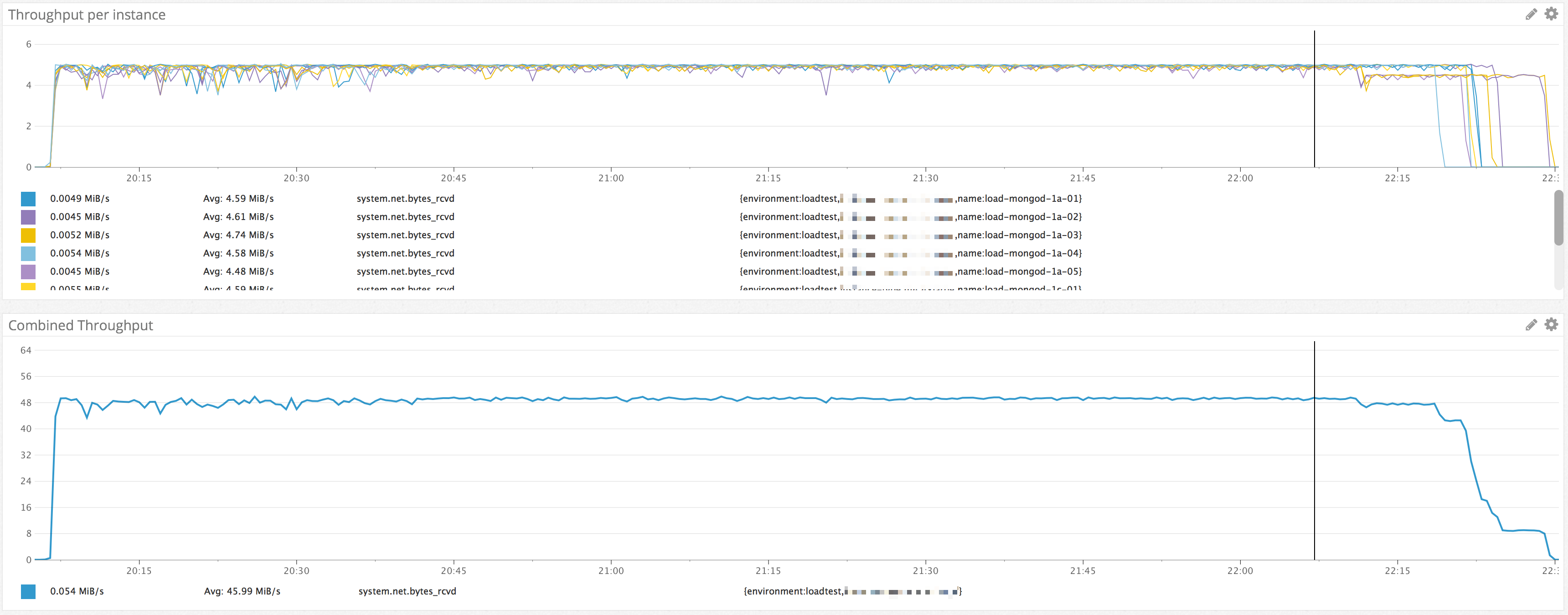
ラスボス:MTU
最後のテストのスループットグラフと比較していて、グラフの形に違和感を感じました。初動が早いが、全インスタンスが5 MB/sに達し、最後5 MB/s前後。帯域の上限のように見えますが、前述した増設でCloud Manager側の帯域が倍以上あるとのことでした。こちら側で問題があるとすればIPレイヤーかと思い、調査を行いました。
AWSでは、一部のインスタンスタイプのMTUがデフォルトで9001(Jumbo Frame)となっています(参考:https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/network_mtu.html)。これは、ローカル通信のときの帯域を最大限活かすための設定らしいのですが、Jumbo Frameが対応されているのは、VPC内のローカル通信のみです。IGWを介してグローバルとの通信を行うとき、MTU 9001のフレーム(Jumbo Frame)がインターネットで転送可能な最大MTU(=1500、通常のフレーム)という単位に分割されます。このフレームの分割がボトルネックになっているのではないかという仮説を立てて、MongoDBのインスタンスのMTUを1500に設定して、またリストアテストを行ってみましたが…
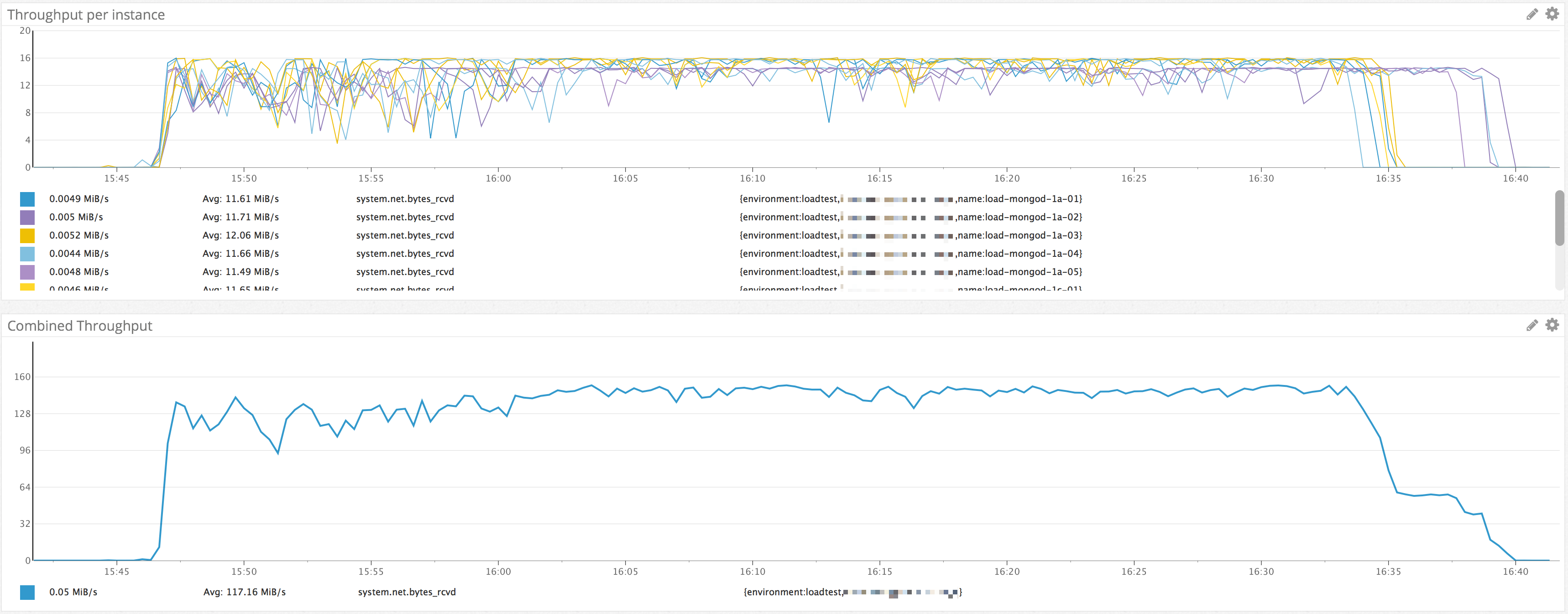
おおおお!
驚愕の55分達成
1時間を、切ってしまいました。
MTUを1500に設定してもローカルでの通信に影響がないかをこれから確認する予定です。影響があるようならば、リストア時に一時的にMTUを1500に設定するか、リストア時の通信用のMTU = 1500な専用インターフェイスを用意するという選択肢があります(確認が終わるまで前者にしています)。
まとめ
今回は、Cloud Managerを使ったバックアップリストアの高速化のために行った施策について紹介しました。Cloud Managerの運営との問い合わせで改善した点もあり、インフラ改善やIPレイヤー設定なども行いました。DBの完全復旧にかかる時間を1時間以内に収めることに成功しましたが、ここで足を止めることなく、さらに復旧の改善を行っていき、AWAのインフラの耐障害性・信頼性を高めていきたいと思います。
所感
個人的に、特にIPレイヤーなど、低レイヤーがクラウド環境では忘れられがちだと思います。今回紹介したこの高速化プロジェクトでは、サポート契約を活かし素直に問い合わせることも大事ですが、自分の環境、自分自身を疑うことも大事だなと、思い知らされました。変化が激しい近年の世の中、特にWeb分野では、定期的にインフラ構成や設定などの見直し・修正を行っていくことが重要であると感じました。