
秋葉原ラボ 飯島 賢志
シュティフ ロマン(@rshtykh)
はじめに
サイバーエージェント内の研究開発組織である秋葉原ラボは、大規模データ基盤の開発・運用に加えて検索・機械学習・データマイニングなどを活用して、弊社の各サービスと様々な形で連携している。今回、Amebaトピックスで使用しているレコメンドAPIに分散キャッシュを導入してシステム負荷を軽減した事例を紹介する。
Amebaトピックス
Amebaトピックスでは、Amebaが展開するサービスの中でいまホットなトピックや記事を選定し配信している。誰にどのトピックを表示するかについていくつもの判定や処理が瞬時にされるが、今回の改善で一層速くレスポンスを返すことができるようになった。
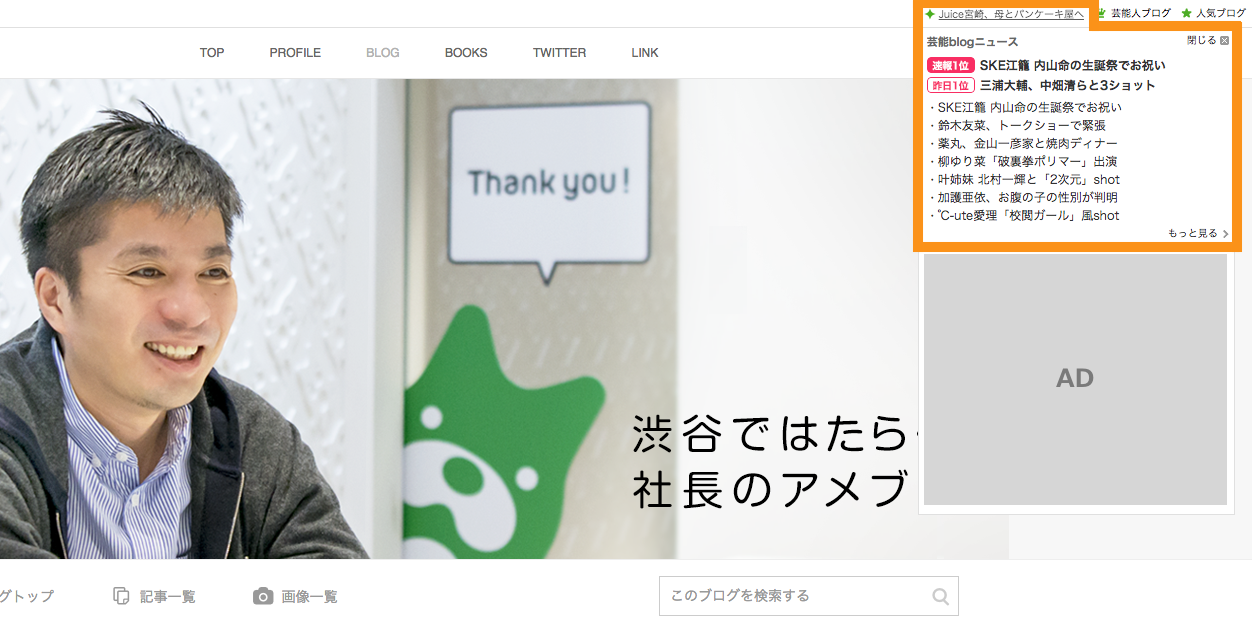
図1. Amebaトピックスのブログヘッダへの配信
システム構成
今回、改善対象となったレコメンドAPI周りのシステム構成を以下の図2に示す。一部省略しているが、レコメンドAPIではバックエンドとして主に3つのシステム (Hyuga Cluster, Amateras, Hyuga Zero) から必要な情報を取得し、表示する記事を決定している。
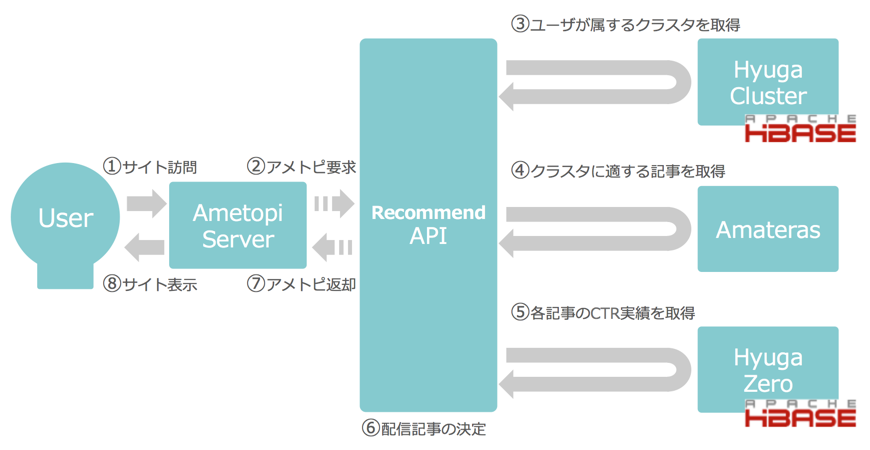
図2. レコメンドAPI周りのシステム構成 (Before)
レコメンドAPIは25台ほどあり、それぞれでローカルキャッシュを持ち、それを参照するようにしていたが、各レコメンドAPI間ではキャッシュが共有されず非効率であった。ここにキャッシュを共有する分散キャッシュを利用できれば、バックエンドのシステムに問い合わせる回数をより一層減らすことができレスポンスタイムもさらに低減できると見込んだ。
Apacheトップレベルプロジェクトであるインメモリープラットフォームの Ignite を検証し、十分なパフォーマンスや安定性が確認できたため、分散キャッシュとして利用することにした。以下図3がIgniteを分散キャッシュとして導入したシステム構成となる。
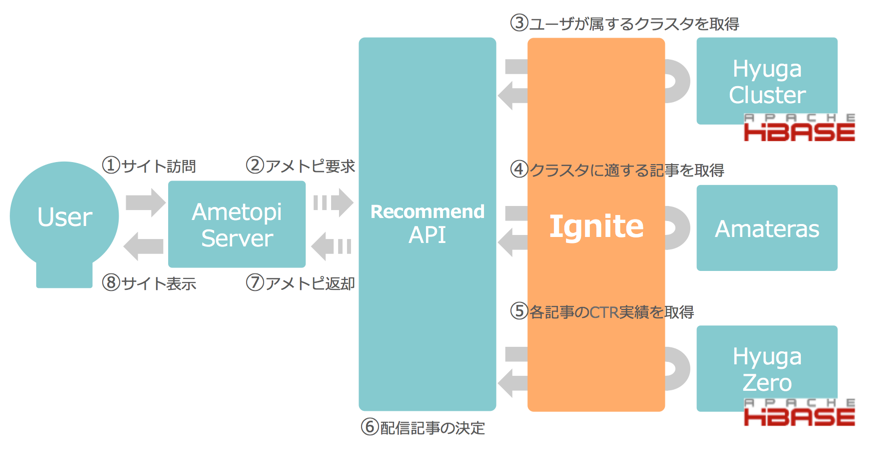
図3. レコメンドAPI周りのシステム構成 (After)
Apache Ignite
Apache Ignite In-Memory Data Fabric(以下、Ignite)は、リアルタイムでトランザクションも含め膨大なデータの処理を行うための高性能分散インメモリープラットフォームである。インメモリーストレージのみならず、Igniteクラスタ上でMapReduceのような様々な分散処理を行ったり、以下の図4にあるように、Apache Hadoop、Sparkや他のシステムとの統合を備えたプラットフォームでもある。
もともとGridGain社が開発し、Apache Projectに寄贈された。JCache(JSR 107)を実装したソリューションだが、Java言語のみならず、C#やC++言語用のAPIが用意されている。また、RESTやmemcachedプロトコル、PHPのPDOを用いたデータアクセスも可能である。
より詳しい概要については以前の下記記事から参照できる。
Apache Igniteとのインメモリーコンピューティング
http://ameblo.jp/principia-ca/entry-12124166753.html
図4. Apache Ignite In-Memory Data Fabric
当然ながら、ローカルキャッシュと違って利用面のメリットが大きい。Ignite*1を使うことでデータは遠隔ノード間で分散されるので、データ取得はローカルキャッシュよりは遅くなるが、次のような利点を享受できる。
- クライアント側でキャッシュサイズやキャッシュによるJVMのGCを気にせずに開発を進められる。
- アプリケーションとキャッシュの分離により、それぞれの責任範囲を明確して開発に専念することができる。
- データのアクセスパターンが類似した他のアプリケーションと分散キャッシュを共有することもできる。
さらに、設定で指定したレプリカ数で冗長化することにより、ノード障害が発生してもキャッシュされたデータへのアクセスが可能となる。
また、今回の事例では利用していないが、インメモリにあるデータに対して高速なデータ処理ができるコンピュートグリッドの機能もある。
インストールと起動
公式ドキュメント にある通りだが、現時点の最新バージョンである v1.7.0を /opt 配下にインストールする例を下記に挙げる。
# Download
$ wget https://archive.apache.org/dist/ignite/1.7.0/apache-ignite-fabric-1.7.0-bin.zip
# Unpack
$ unzip apache-ignite-fabric-1.7.0-bin.zip -d /opt/
# Symlink
$ ln -s /opt/apache-ignite-fabric-1.7.0-bin /opt/ignite
# Run
$ /opt/ignite/bin/ignite.sh
OR
# キャッシュの設定ファイルを指定した場合
$ /opt/ignite/bin/ignite.sh config/ametopi-cache.xml
以下のような出力(1ノードの場合)があれば起動完了となる。
[18:43:12] Ignite node started OK (id=6f21920a)
[18:43:12] Topology snapshot [ver=1, servers=1, clients=0, CPUs=8, heap=8.0GB]
上記手順をAnsibleなどによるデプロイで対応するとよいだろう。また、起動・終了のスクリプトのパッケージは弊社にて自作したものを使っているが今回は割愛する。
パフォーマンス検証
パフォーマンスの検証には yardstick-ignite を使用した。Igniteクラスタは弊社プライベートクラウド上で下記スペックの仮想インスタンスで構築した。Igniteのバージョンは当時の最新 v1.6.0 である。
- Number of Instances: 10
- OS: CentOS 6.6
- CPU: 24Core, 1.9 GHz, QEMU Virtual CPU version (cpu64-rhel6)
- Memory: 92GB
実行したyardstick-igniteのクラスは下記3つである。
- Put: IgnitePutBenchmark.java
- Get: IgniteGetBenchmark.java
- Put+Get: IgnitePutGetBenchmark.java
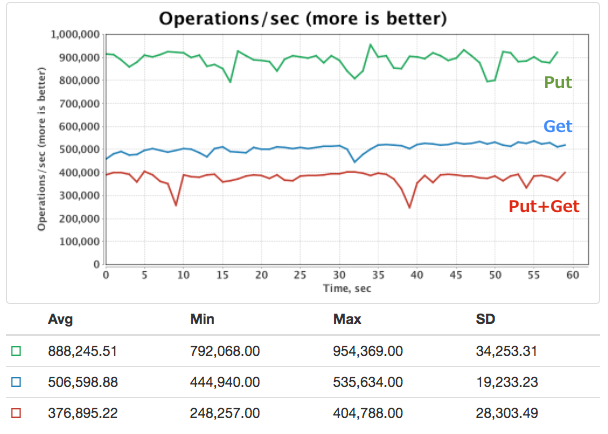
図5. yardstick-igniteのベンチマーク結果
実行結果は上記図5のようになった。Putのみで約90万ops/sec、Getのみで約50万ops/sec、PutとGetの混在で40万ops/sec弱という結果であった。Putについては非同期で実行する writeSynchronizationMode: FULL_ASYNC の設定にしたため、特に高いスループットが得られたと考えられる。このように想定する処理量にも十分に耐えられることを確認できた。なお、クラスタの台数を増やせば、さらにパフォーマンスをスケールさせることもできる。
設定・JVMチューニング
IgniteはJava仮想マシン(JVM)上で動くデータグリッドとなるが、JVMのヒープではなくネイティブ・メモリ(オフヒープ領域)にオブジェクトを格納することもできる。大量データをネイティブ・メモリに保持することはFull GCを避ける対策になるが、オブジェクトへのアクセス速度がわずかに遅くなるのと、今回保持するデータがそれほど大きくないことから、今回は ONHEAP モードを利用した。ちなみに、もしデータ量が大きくなった場合も、Igniteクラスタのノード追加で容易にスケールアウトができる。
また、バックエンドのシステムから取得するデータは絶えず更新されているので、古いデータが残り続けないようにするため、キャパシティプランニングを行った上で以下のようなキャッシュの退去ポリシーや有効期限を設定した(実値をxにする)。
<property name="expiryPolicyFactory">
<bean class="javax.cache.expiry.ModifiedExpiryPolicy" factory-method="factoryOf">
<constructor-arg>
<bean class="javax.cache.expiry.Duration">
<constructor-arg value="SECONDS"/>
<constructor-arg value="x"/>
</bean>
</constructor-arg>
</bean>
</property>
<property name="evictionPolicy">
<bean class="org.apache.ignite.cache.eviction.lru.LruEvictionPolicy">
<property name="maxSize" value="x"/>
</bean>
</property>
JVMオプションは bin/ignite.sh にて設定できる。想定するワークロードによって最適な設定は異なるが、パフォーマンス改善につながるJVMやシステムのパラメータは 公式ドキュメント が参考になる。
導入結果
Igniteを導入した結果、レコメンドAPIにおいて特にピーク帯のレスポンスタイムに大きな改善が見られた。導入前は約90msecだったのが導入後では約60msecとレスポンスタムを1/3ほど低減することができた。当時の導入前後のレスポンスタイムの推移を以下の図6に示す。
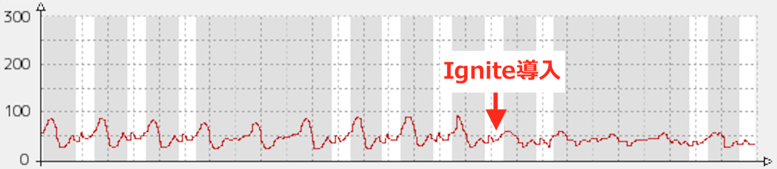
図6.レコメンドAPIのレスポンスタイム
Ignite導入以前もローカルキャッシュが有効になっていたにもかかわらず、このような改善が見られたのは、前述したとおりレコメンドAPIが25台ほどありこれらのAPI間で共有されていなかったキャッシュが共有がされるようなったのが要因と考えられる。
なお、今回の導入では既存のローカルキャッシュを参照するロジックを残した。当然ながら遠隔にある分散キャッシュよりもローカルキャッシュを参照する方が速いため、ローカルキャッシュにデータがなければIgniteを参照し、Igniteにもデータがなければバックエンドのシステムに問い合わせるように実装を行った。
バックエンドのDBであるHBaseへのGet処理は12万ops/secから8.5万ops/secとなり内部のリクエストも1/3ほど低減することができた。システム負荷の軽減により、過剰となったサーバを減らすなどコストダウンできるケースもあるだろう。
まとめ
本記事では、バックエンドのシステムを参照するコストが高いクライントの負荷を下げるためにIgniteを導入し、その改善効果を示した。また、Igniteの分散キャッシュとしての利用方法を紹介し、パフォーマンスの検証結果を示した。
分散キャッシュの導入は今回のレコメンドAPIに当たるクライアントの台数が多ければ多いほど大きな効果が期待できると言える。
Igniteを本番運用して半年が経つが、一度もクラスタが落ちることもなく、レスポンスタイムの目立った悪化もなく安定している。
今後もIgniteの開発状況に注視しつつ、コンピュートグリッドなどの機能も含め、導入する効果が高いと見込まれるシステムで導入を進めていきたい。
*1 Igniteに限らず、高いスケーラビリティや耐障害性を実現しているHazelcastや他のインメモリプラットフォームでも同じ効果が得られる。