
こんにちは。OPENREC事業部で基盤系のエンジニアをしている石田です。
今回はOPENREC.tvに導入されているバッチ処理の基盤をご紹介したいと思います。
この記事では以下のことに関して話そうと思います。
- OPENREC.tvでのバッチ処理内容
- 従来のバッチ処理基盤の課題
- 新バッチ処理導入のモチベーション
- 新バッチのインフラ構成
- 実際に稼働してみて
- 本番稼働をして明らかになった課題
- まとめ
OPENREC.tvでのバッチ処理
OPENREC.tvでは、主に以下の処理をバッチとして実行しています。
- 視聴時間の計測結果の集計
- ランキングの集計
- 検索用のデータの作成
- おすすめ動画の作成
従来のバッチ処理基盤の課題
初期のバッチ処理は、1台のEC2で稼働していました。それゆえ、以下の問題を抱えておりました。
- インスタンス1台で稼働していることからスケーラビリティが皆無
- SPOFなので万一ハードウェア障害などでインスタンスが落ちた場合、データ欠損のリカバリ処理をしなければならない
- バッチ処理のコードがほぼメンテされておらず、テストも無いので開発・修正がとてもしづらい
このようなことから、バッチ処理関連の開発の硬直化が起きていました。
ここで新たにアーカイブ削除のバッチ処理の新規開発が入ってきました。
削除条件をまとめると、
1.チャンネルフォロワー数が1000未満かつ、公開されてから60日の視聴数が100未満のアーカイブ
2.条件1にかかわらず、非公開かつ作成から60日以上経過しているアーカイブ
3.ユーザーによって削除されているアーカイブ
4.既に退会済みのユーザーのアーカイブ
さらに、削除対象になった動画は、ユーザーの管理画面からダウンロードできるようにする必要がありました。動画の形式はMP4で、このファイルもバッチ処理にて生成する必要があります。
処理対象が、概算しただけでも100万件以上あり、また動画生成の要件も鑑みると既存のバッチに追加開発するのは現実的ではなかったため、新規開発をするに至りました。
新バッチ導入のモチベーション
以下の理由が新規開発のモチベーションとなっています。
- SPOFとならないコンポーネント
- 並列処理が容易であること(サーバーもしくはコンテナを並べるだけで処理数を増やせること)
- ポータビリティ性が高いこと
- 既存のバッチとは完全に分離されていること
- 開発が容易であること(ユニットテストが存在すること)
また昨今のKotlinの勃興を鑑みて、技術的挑戦の一つとして開発言語をKotlinとしました。
新バッチのインフラ構成
新バッチ開発にあたって導入モチベーションに合わせて、更に以下の要件があります。
- DBと疎通可能であること
- アーカイブが存在するS3と疎通可能であること
- キューで処理でき、万一処理途中において何らかの理由で落ちたとしても処理をロールバックできること
- 1時間程度の処理にも対応できること
- CPUヘビーなワークロードにも利用できること
以上の要件からコンテナベースかつ使用するリソースを自由に選べるAWS Batchを採用するに至りました。
以下の理由により(EC2 + AutoScale)やLambdaの採用は見送りました。
- ジョブ管理もマネージドに寄せたい
- EC2の管理はしたくない
- 長時間稼働を想定しておきたい
構築したインフラとしては図1のようになりました。
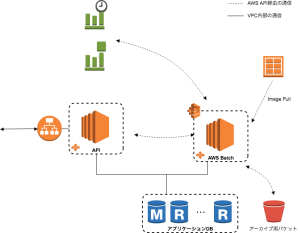
図1. AWS Batch概略図
オーソドックスなWebアプリケーションにAWS Batchを追加した形になっています。
実際に稼働してみて
処理自体はCloudWatchのトリガーとAWS Batch、クライアントからのAPIコールで完結するので基本的に人の手は不要です。
ですが、何件の処理完了したのか、また処理がうまく行かなかったなどの情報はエンジニアが知りたいので、図2のようにメールとSlackによって通知をするようにしています。
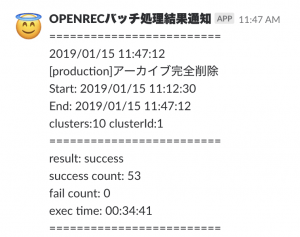
図2. Slack通知の様子
このバッチ処理によりアーカイブ削除が進み、無事にS3の費用削減を進めることが可能となりました。
図3のように無事にS3の容量が減っていることも確認できました。(具体的な数字などはマスクしています)
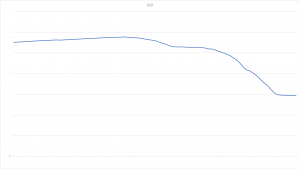
図3. S3の容量の推移
本番稼働をして明らかになった課題
ただ、実運用するにあたって以下の問題も明らかになりました。
- マネージドモードで作成すると、コンピュートノードのディスクが8GBしか無く、処理によっては失敗する
- AutoScalingGroupが自動でできてしまう
マネージドモードで作成すると、コンピュートノードのディスクが8GBしか無く、処理によっては失敗する
AWS Batchでは、AWS側が提供しているAMIを使ってコンピューティングリソースを起動させます。
通常の用途では、コンピューティングリソースのディスクがネックになることは無いのですが、今回のバッチの要件で、ユーザーが自身の管理画面から動画をダウンロードできるよう、専用のmp4を作成する要件がありました。
MP4を生成するために、一旦コンテナ側にダウンロードする必要があります。ですが、動画によっては8GBを超える動画もあるため、AWSがデフォルトで提供しているAMIでは対応出来ないことが分かりました。
幸いなことにマネージドのコンピューティング環境でもAMIの選択はできるので、今回はボリュームを拡張したAMIを新たに作り、MP4を作成するジョブは、そのコンピューティング環境で実行することで対応しました。
AutoScalingGroupが自動でできてしまう
これは割と運用に関する話となります。
OPENREC.tvではAutoScalingGroupをサービス及び環境ごとに管理していました。
ですがAWS Batchのフルマネージドモードで管理をするとAutoScalingGroupが自動的に生成されます。
ジョブ×インスタンスタイプごとに生成されるようで、開発環境用も含めると10個程度が生成されました。
正直なところ視認性が悪くなる程度の問題だったので、このまま続行することにしました。
まとめ
バッチ用のインフラ層をインフラエンジニアが工面すること無く、アプリケーションエンジニアのみで完結できるコンテナ由来の利便性、
バッチの実行をCloudWatchなどに寄せられる安心感など、従来のインフラでは成し得なかった利点を、AWS Batchを採用することによって、獲得できました。
Dockerがある程度分かっていれば簡単に利用できると思うので、導入を検討されている方は是非利用されてはどうでしょうか。