
こんにちは、株式会社サイバーエージェント 秋葉原ラボでデータ分析をしている鈴木元也と武内慎です。この度サイバーエージェントグループでの技術カンファレンスCA BASE CAMP 2019にて登壇させていただきました、「スマートなランキングの作り方 〜AWA、REQUへの適用事例〜」について解説させていただきます。

ランキングと聞くと “単純に数値を集計し、並び替えたリストを出せば終わり” と考えている人は多いのではないでしょうか?しかし、作ってみると思ったより考えることが多くて苦労した経験がある人は多少なりともいるかと思います。そんな人を今後増やさないために、スマートなランキングの作り方をまとめました。
ここでは幅広いサービスで適応できるように一般化したランキングの作成方法と AWA、REQUという2つのサービスのランキング作成事例についてご紹介いたします。
2つの重要なポイント
ランキングを作るためには「要件整理」と「ロジック」の2つの重要なポイントがあります。これからそれぞれについて詳しく説明していきます。

要件整理
要件整理はプロジェクトを進める上でとても大切です。やらないといけないことは分かっていても、いざやるとなると抜け漏れが発生したり明確にしないままプロジェクトを進めてしまったりするので注意が必要です。
ここでは、なぜ要件整理が大切なのかをメリット / デメリットの形式でまとめ、ヒヤリングシートを使って要件整理する方法を紹介します。
メリット/デメリット
まず要件整理をすることによってどのようなメリット、デメリットがあるのかをまとめました。

まとめた内容は当たり前のことではあるものの、意識して要件整理しないと疎かになってしまいがちです。後々苦労しないためにもプロジェクトメンバー内で改めて確認してみるとよいと思います。
ヒヤリングシートを利用して要件整理
要件整理の重要性を改めて確認したら、次はどのように要件整理すればいいのかを考えます。方法はいろいろありますがAWA、REQUで実際に作成したランキングを振り返りながら、なるべく一般化できるようにヒヤリングシートを作成しました。

このヒヤリングシートを利用して要件整理をすれば、最初のコミュニケーションコストが削減できたり、誤った方針になりにくくなると思います。
ロジック
ロジックと聞くと難しそうなイメージを持たれますが、ロジックにも簡単なものから複雑なものまで様々なタイプがあります(以下、モデルタイプと呼びます)」。目的や利用用途に合わせてどのようなモデルタイプを選択するかが大切です。
ここではモデルタイプにはどのようなものがあるかをまとめ、分析フローを中心に説明していきます。なお具体的なロジックについては事例にて紹介いたします。
モデルタイプの定義
既存のスコアリングモデルの系統を参考にしながら3つのモデルタイプに分類し、それぞれのタイプの説明と利用用途についてまとめました。

また、モデルタイプによって様々な特徴があります。どれか1つがよいのではなくそれぞれに一長一短があるので、この特徴もモデルタイプを選択する上で考慮することが大切です。
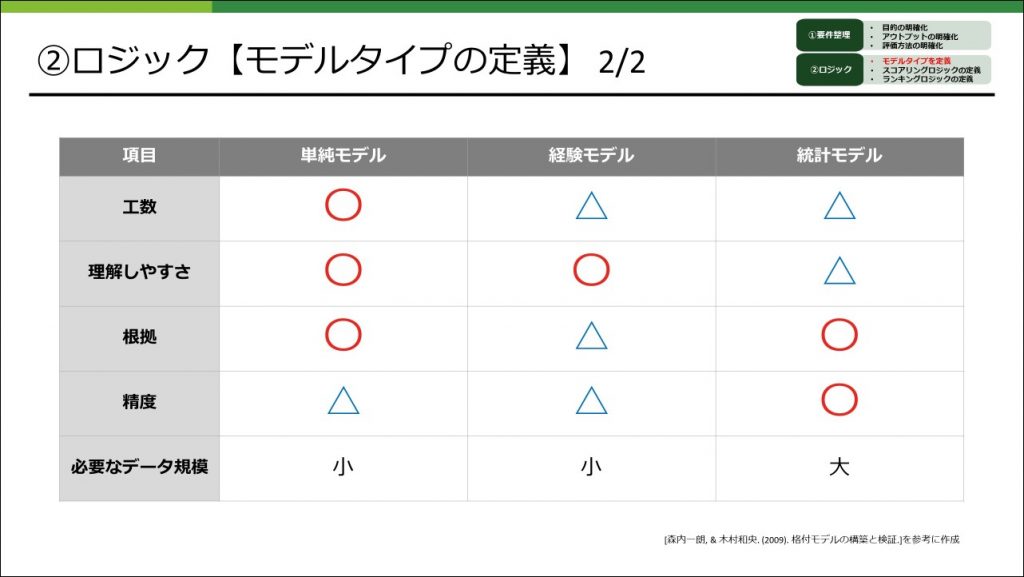
これらを参考にしながらどのモデルタイプが適切か判断すれば、過剰なランキングになりにくくなると思います。
スコアリングロジックの定義
スコアリングロジックを定義するためには以下のような分析フローで進めます。
この分析フローはランキング特有なものではなく、一般的な分析フローとほとんど変わりないです。分析経験がない方は分析するためには、こんなフローがあるんだということを覚えておいてもらえれば、分析者とのコミュニケーションがより円滑になるかと思います。

記載している分析フローの中で最も時間が必要なのは、「スコアリング」⇒「評価」の部分です。評価指標にもよりますが、多くのケースでの最終意思決定者はビジネス責任者です。したがって評価指標の精度はもちろん、ビジネス責任者に納得いただくための説明や資料を準備するのがとても大切であり、そのためにはそれなりの時間が必要になります。これらを踏まえて分析フローと必要な工数を事前に見積もっておけば全体のスケジュールをコントロールしやすくなると思います。
ランキングロジックの定義
ランキングロジックの基本ロジックはスコアの降順となることが多いです。ただしスコアの降順のままだと不都合が発生する場合が出てきます。例えば同一スコアが出た場合などがあります。
ここではこのような例外条件をランキングロジックとして定義します。もちろんスコアリングロジックの部分で考慮することもできなくはないですが、スコアリングロジックが複雑になってしまうので分けて定義します。

これまで説明した内容を参考にしていただき、スマートなランキングを作るお役に立てればと思います。また、今回は活用イメージがより明確になるようにランキングの作成事例を紹介いたします。
事例紹介
ここでは、AWAとREQUの2つのサービスについてのランキング作成事例を紹介いたします。
AWAとは
AWAはサブスクリプション型(定額制)音楽ストリーミングサービスです。国内最大規模の楽曲数がいつでもどこでも聴き放題。あなたの好みや気分、シーンを分析して自動で音楽をオススメします。
REQUとは
REQU(※リキューと読みます)は、これを読んでくれている皆さん個人個人が持っている知識や特技、これまでに得た経験などを活かして自由に販売できるマーケットです。例えば、自分のファッションセンスや恋愛経験を活かしたアドバイス、インテリア、料理や子育てなどの生活の知恵、ガイドブックには絶対に書いてないお出かけや旅行のちょっとしたヒント、趣味を活かしたオーダーメイドのハンドメイド販売、イラストやデザイン、プログラミングのスキルなど、REQUでは、自分のアイデア次第でどんなものでも商品として販売できます。
AWA事例とREQU事例の違い
事例の紹介をする前に、AWA事例とREQU事例では何が違うのかを整理します。大きな違いは、既存ランキングの改善なのか、新規ランキングの作成なのかです。もちろん実現したいことや評価指標も異なるので、それぞれのサービスでどのようなアプローチでランキングを作成しているかに注目いただければと思います。

事例紹介 AWA
ここからは、音楽ストリーミングサービスAWAでのランキング作成事例をご紹介します。
AWAには、ユーザー毎にパーソナライズドされるDISCOVERY、エディターが厳選した音楽が並ぶFOCUS、様々なランキングを表示するTRENDS等のページがあります。今回は、このTRENDSページに掲載される一部のplaylistのランキングロジックを作成した際の事例についてご紹介します。
この案件で取り組む問題
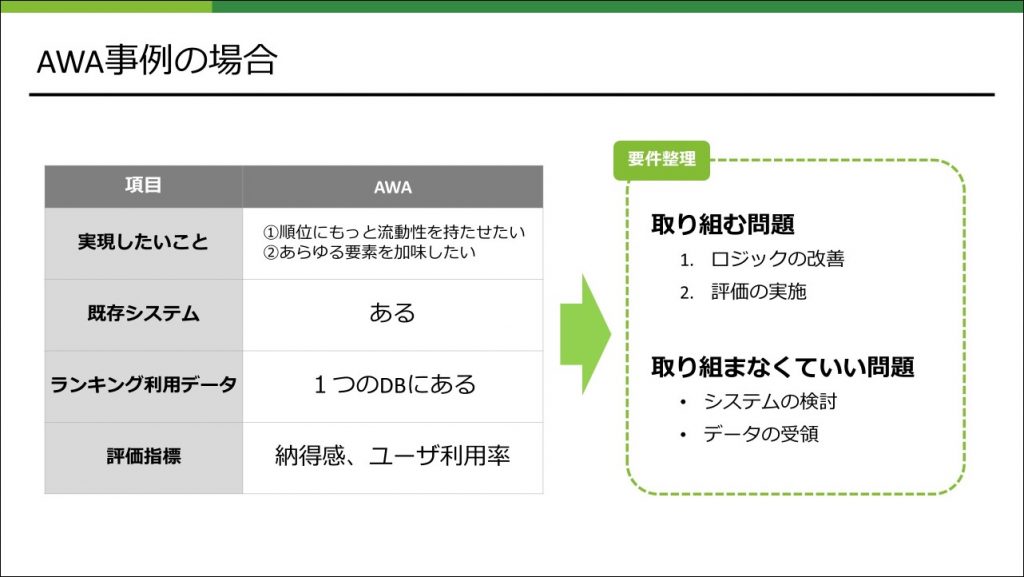
まず、この案件として取り組む問題を明確にします。状況としては、すでに動作しているランキング枠が存在しており、そのロジックの修正がメインの案件だったので、この事例紹介もロジック検討の話がメインになります。逆に、システムの検討やデータ受領に関しては、特に問題にならなかったため発表では触れません。
実現したいこと①
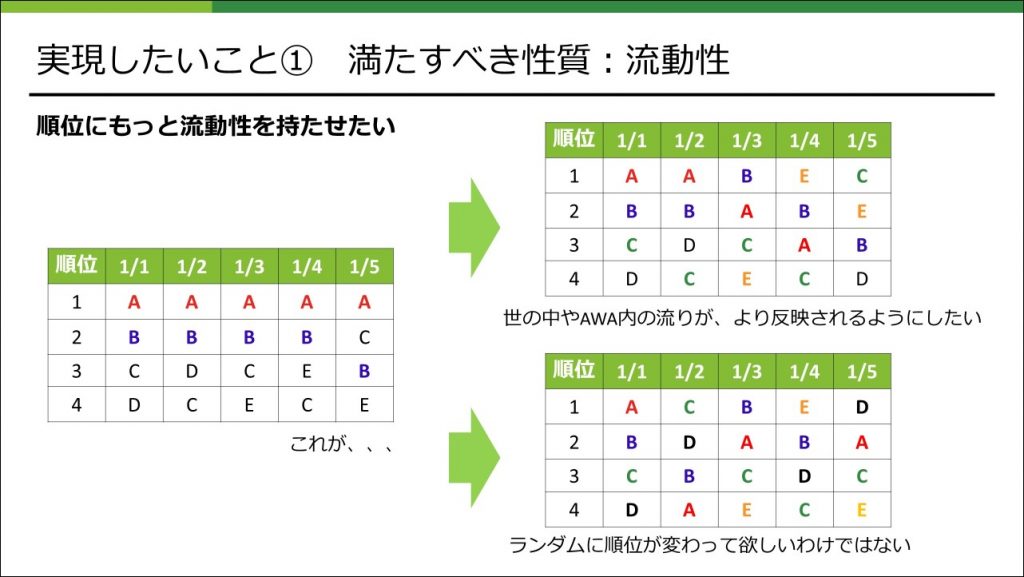
今回実現したいことの1つ目は、順位にもっと流動性をもたせたいということでした。
具体的には、世の中やAWA内での流行りをより顕著にランキングに反映させることで、その結果として順位がより流動的になり、コンテンツとしてもより面白いものにできるのではないかということです。ここで気をつけるべきことは、順位が流動的になればなんでもよいというわけではなく、極端な例ですが、例えばランダムに順位が変わってほしいということではありません。
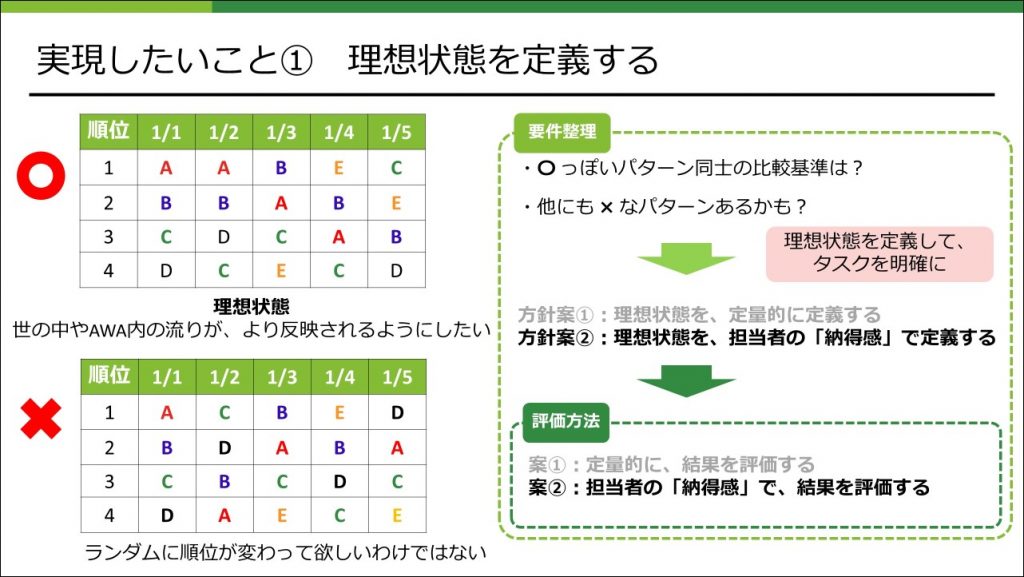
こういったことを検討、議論する上で必要になるのが、ゴールとしての理想状態の定義を決めるということです。「定義する」というと、「定量的に定義する」ことを考えがちですが、ここで言っている定義とはもっと広義のものを意図していて、この案件のゴールを関係者間で共有できるものであればなんでもよいです。
例えば、理想状態を「担当者の納得感で定義する」と決めてしまえば、担当者が納得するロジックを作り上げることがその案件のゴールになり、本件ではそのように理想状態を定義しました。
一旦、理想状態の定義を決めてしまえば、それを達成するために必要なタスクとして、「担当者の納得感で評価するために必要な環境を用意する」とかが明確になってきます。
実現したいこと②

実現したいことの2つ目は、あらゆる要素を加味したいというものでした。
要素とは、具体的にはユーザーの行動の種類を意図していて、その候補として考えられる行動は上げればキリがありません。

ランキングロジックに用いる変数を増やすと、その分表現力は増えますが、結果の解釈が困難になったり、作業やメンテナンスのコストが増加するなどのデメリットもあるため、重要な行動に絞ってそれを変数に採用するということを考えました。それらをパラメータで重み付けすることで微調整を行うということをすれば良さそうなので、ロジックは「経験モデル」となり、そこで採用する要素は基礎集計をして決めました。
基礎集計をするときの気持ち
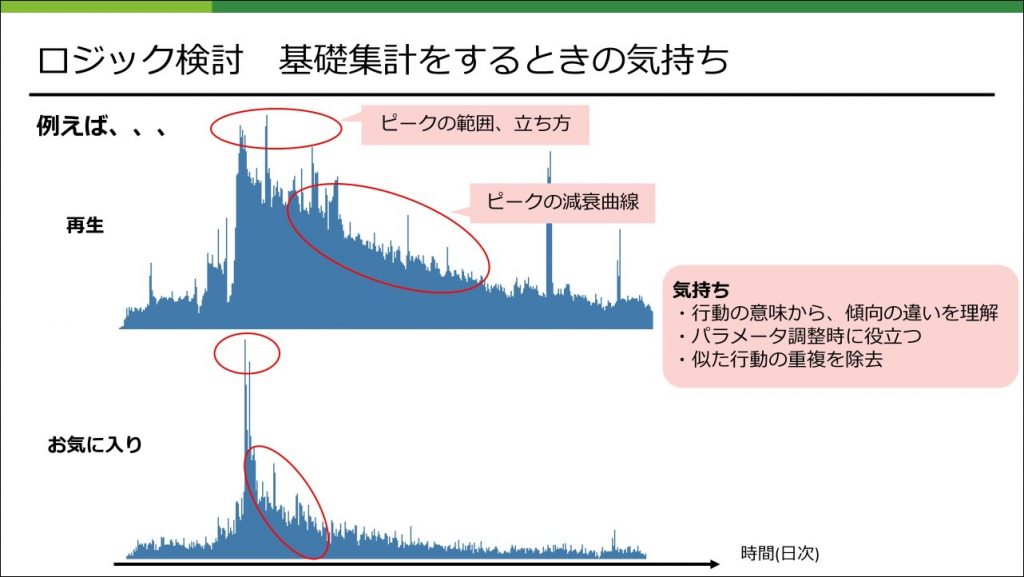
基礎集計では、ユーザーの行動毎に、その意味と性質を把握することを心がけました。わかりやすいところだと、「再生」は、普通一人のユーザーが複数回行いますが、「お気に入り登録」は一人のユーザーは1回しか行わないという違いがあります。そのような違いによって、ある外的な要因(新曲のリリース、話題のニュースなど)に対応した、特定のコンテンツに対する集団の行動数のピークの立ち方や、減衰の仕方にも違いが現れます。
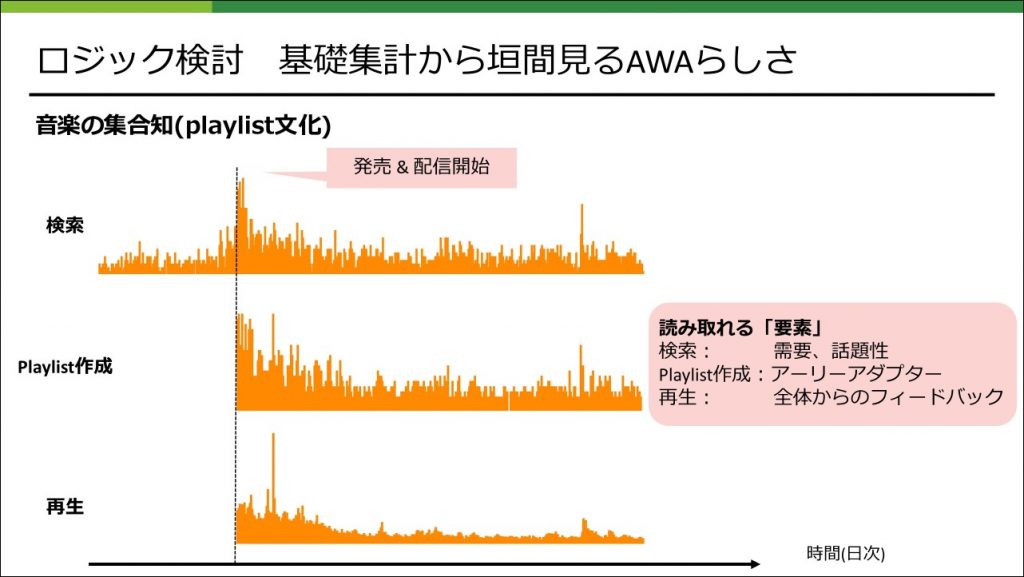
また、「特定のコンテンツが流行っていく」というような、確認したい現象をある程度想定してデータを見ることで、解釈が容易になるということもあります。
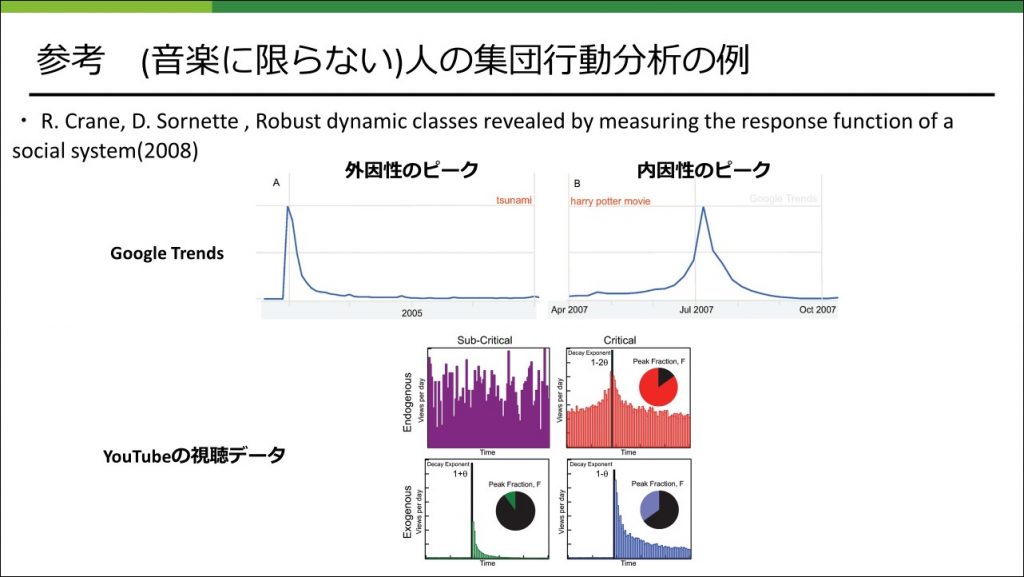
このような人の集団行動の分析に関して、ビッグデータの活用が叫ばれて久しい昨今では様々な分析研究の事例が存在していて、human dynamicsという研究分野もあったりしますので、サーベイしてみると色々な学びがあり面白いです。
AWA事例のまとめ
特に今回は、理想状態の定義を定量的に行うことを潔く諦めています。それによって「理想状態を定量的に定義する」という難問を解く必要はなくなりますが、その代わりに、担当者の頭の中に存在する理想状態と効率よく答え合わせをする方法が課題となりました。それを解決する1つの手段として、下記のような、パラメータ変更によってランキング結果の推移がどう変わるかがインタラクティブに確認できる環境を用意するということが考えられます。
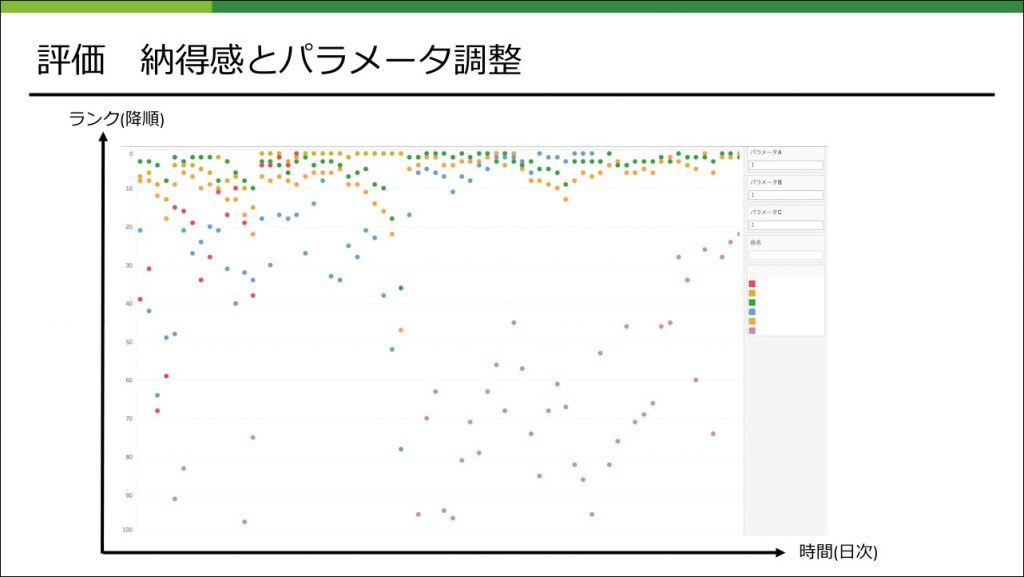
このように要件整理を心がけることで、早い段階で必要なタスクを明確にすることができ、その結果として出戻りが少なくなったり、取り組むべき課題に集中できたかなと思います。
事例紹介 REQU
ここからは、REQUでランキングを作成したときのロジックと作成までのフローについてご紹介します。
ヒヤリングシートを使って要件整理
まずはじめに前述したヒヤリングシートを使って要件整理を行いました。

その結果、ランキングを作成するのに重要な3つのポイントが明らかになりました。
3つのポイント

このポイントは分析者1人で対処できるものではなく、ディレクター、エンジニアの両者の協力が必要になってきます。そのためメンバー同士で認識を合わせ方針と役割を明確にすることが大切です。
ランキング作成フロー
今回は以下のようなフローでランキングを作成しました。

前述した「工夫ポイント③」にもあるよう今回はリソース不足のため、誰かがボトルネックにならないように取り組めるように考えました。具体的には「システム全体像の設計」にてランキングを作成する環境とインプットデータとアウトプットデータを定義します。これによってそれ以降の分析者とエンジニアのタスクを並列して進められるように工夫しました。詳細な設計方法は後ほどご説明します。
なお、今回は分析者視点でランキング作成フローの各プロセスについて説明していきます。
データアセスメント
今回は以下のようなフローでデータアセスメントしました。
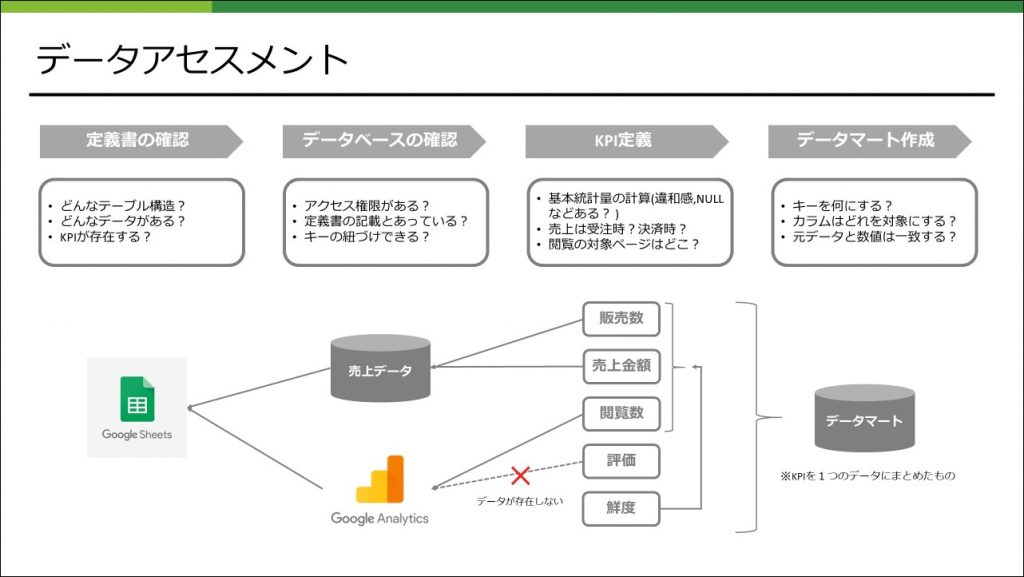
ここで注意が必要なのはKPI定義です。例えば「閲覧数」といっても対象ページをどこにするのか?おかしなログはないか?それらをどうやって定義するのか?など認識をしっかりすり合わせてかないと手戻りが発生してしまいます。KPIの定義はドキュメントに文章と定義方法の両方を記載しておくと、あとで振り返ったときにも分かりやすくなります。
モデルタイプの定義
ロジックのたたきを作成するために、まずモデルタイプの定義を行いました。
今回は複数のKPIを利用することやユーザ一律のランキング、並び替える対象がそこまで多くない、評価指標も納得感と定量的に評価ができないことから経験モデルを採択しました。しかし経験モデルは一歩間違えると考慮する要因が増えてしまい、パラメータチューニングが大変なため、最低限まで減らすようにロジックを考える必要があります。

スコアリングロジック
今回は以下のようなスコアリングロジックとなりました。見る人が見れば非常にシンプルなロジックとわかると思うのですが、そうでない人にもわかるように解説していきたいと思います。

まず、REQUのKPIツリーを作成しConsumerKPIの閲覧数とBusinessKPIの売上金額の2つのKPIに絞りました。Popularityはこの2つのKPIに対して重みづけをすることで定義します。しかしそれぞれのKPIのスケールが異なるため正規化した上で重みづけをします。正規化の方法は1日あたりの全体のKPIで割ってあげることで0~1の間になるようにしました。これでPopularityは定義できるのですが、REQUというサービスは売り切れが発生します。ある日の売上が上位でも売り切れてしまえば翌日のランキングは低くなってしまうと、売り手(以下、セラーとする)のモチベーションが上がりずらくなってしまう懸念がありました。
そこで過去のPopularityを残存効果として考慮しPopularityに加算するPopularScoreを定義しました。

スコアリングロジックではチューニングパラメータを少なくするため、売上重みと時間重みの2つのパラメータでチューニングできるようにしました。工夫したところとしては、閲覧数の重みと売上の重みを別々にパラメータにするのではなく、閲覧数の重みは「1 – 売上重み」としパラメータの数を減らしたところです。

ここまでで、Popularityについてはある程度理解いただけると思うのですが、残存効果に関してはMを横にした見たことあるような、ないような記号がありイメージがしにくい人も多いかと思います。そこで残存効果の数値イメージがしやすくするためさらに細かく解説します。
この残存効果でやっていることは、過去のPopularityを足し合わしているのですが、単純に足し合わすのではなく古くなればなるほど足す値を小さくするということをやっています。残存効果のパラメータ「λ」の役割は過去のPopularityをどの程度考慮するのか?をコントロールしています。例えば、「λ=0.5」とした場合、前日のPopularityに半分の0.5を掛けた値、2日前のPopularityにさらに半分の0.25を掛けた値を足し合わせていき、m日分まで足し合わせていくということをしています。
また残存効果としてよく用いられるのは指数関数的減衰ですが、指数というのは統計の知識がある程度ないとわかりにくいため、わかりやすさ重視で今回の減衰方法としました。

システム全体像の設計
次にシステム全体像の設計を行います。今回はデータソースが複数あるためデータを統合する環境が必要になり、その環境にGoogle Bigquery(以下BQとする)を利用しました。理由はGAからBQにエクスポートする機能が標準で付いているのと、REQUではレポートにGoogle Data Studioを利用している、そして別プロジェクトで既にGoogle Cloud Platformを利用していたため、アカウント設定済みだったためです。
ロジックを実装するシステムは、ロジックをシンプルにしたので新たに設けることはせず、BQ内のSQLで完結できるようにしました。ランキングをモニタリングするレポートを作成する際も、利用するデータがBQにあるので特別な設定が不要になるメリットもあります。
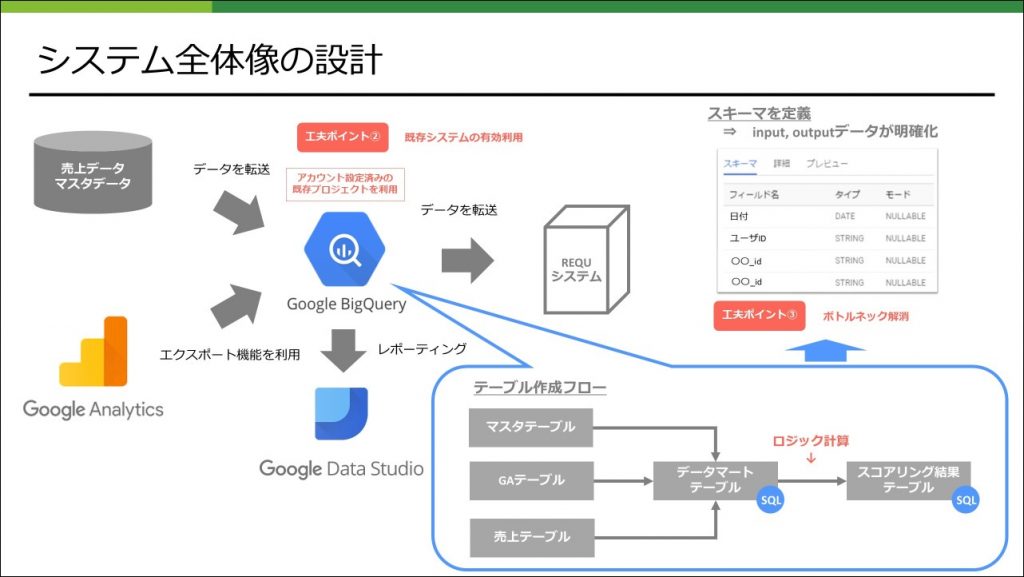
また、データの処理をBQで行うので処理ステップごとにスキーマを定義することになります。これによってデータ構造とデータ型が明確になりその後のシステム連携もスムーズに行うことができます。
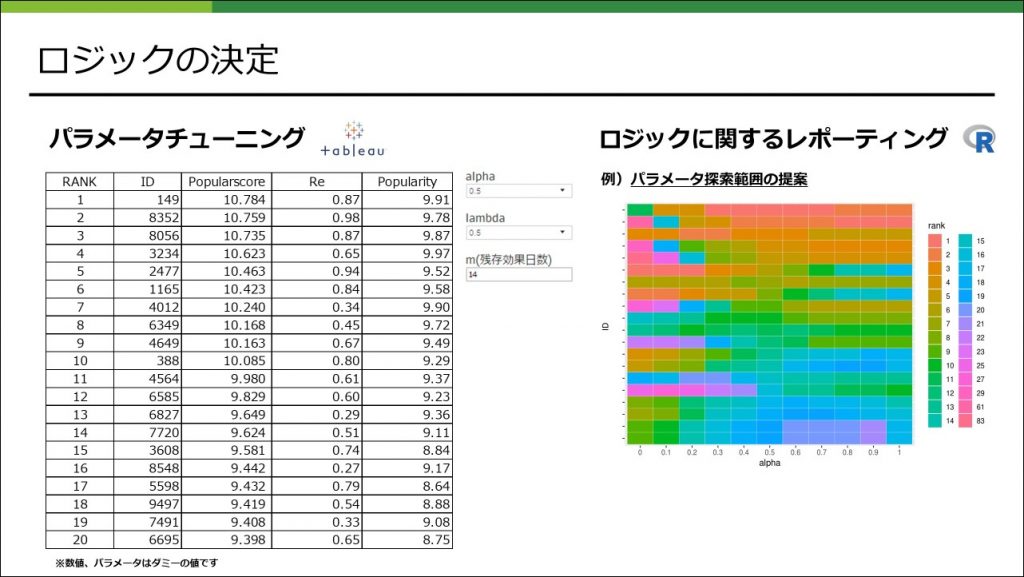
ロジックの決定
ここではスコアリングロジックのパラメータを決めます。
パラメータの数を減らしたとはいえ、組み合わせはそれなりに多く、組み合わせごとに結果を出力するのは負荷が大きいのでインタラクティブにランキング結果が出力できるようにTableauを利用しました。(Google Data Studioだと機能不足で実現できなかったためTableauを利用しました)さらにパラメータの探索範囲が広いと大変なので、探索範囲の提案レポートを作成するなどして効率的にパラメータをチューニングできるようにしました。
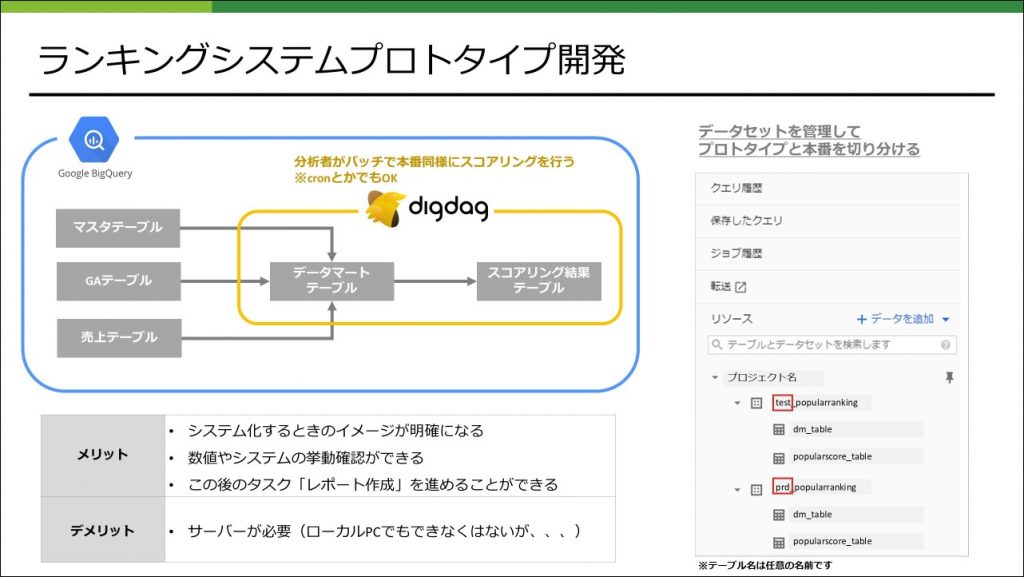
ランキングシステムプロトタイプ開発
システムの詳細も決まり、ロジックも決まったので残るはシステムを開発するのみです。エンジニアの開発が終わるのを待っていてもよいのですが、今回は分析者がプロトタイプシステムを開発し本番システムの開発が完了するまで試験運用を行いました。(もちろんリリースはしていないです)これを行うメリット、デメリットは以下にまとめました。これによりスムーズにエンジニアとの連携が行われます。
レポート作成
作成されたランキングをモニタリングできるようにGoogle Data Studioを利用してレポートを作成しました。具体的な数値はお見せできませんが、直近分のランキング結果を確認できるレポートなどいくつか作成し、ランキングのヘルスチェックができる状態にしています。
REQU事例のまとめ

さいごに
