
アドテク本部の黒崎( @kuro_m88 )です。
2019/08/23にAWSの東京リージョンで特定のAZ内で大きめの障害がありました。
私が開発しているプロダクトもAWSの東京リージョンを利用していて、常時数百インスタンスが稼働しているため、今回の障害の影響範囲に含まれていました。
何が起きたのか?
AWSから公式発表が出ています。
東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要
データセンタ内の冷却の障害が原因で一部のハードウェアホストが過熱し電源が失われてしまったようです。これにより影響を受けたハードウェアホスト上で稼働していたEC2インスタンスやEBSボリュームは電源が失われているため、外部から見ると突然応答がなくなったように見えました。
担当サービスでも公式発表と同じくらいの時刻にELBやその配下のサーバでエラーレートの上昇を観測しました。第一報では東京リージョンの単一AZでのEC2の接続性に問題が発生しているという情報だったため、ネットワーク障害を疑いました。社内で同様なエラーレートの上昇を観測したチームがいくつか見受けられたため、サポートチケットを上げたり、社内Slackで状況を共有したりしました。その結果対象のAZを特定し、またAZ全体に渡って障害が発生しているわけではなさそうだという推測ができました。単一プロダクトだと全体像がすぐに把握できず、公式発表を待つしかできませんでしたが、社内で情報共有ができたためすぐに状況証拠が集まってきてその後の判断のヒントになったのはよかったです。
テレビのニュースでも取り上げられる程度には様々なサービスに影響が出たようで、この機会にアベイラビリティーゾーンとは何なのか、アベイラビリティーゾーン障害が起きた時にどうするべきなのかをまとめてみました。
そもそもデータセンタって?
学生のとき(2014年)にさくらインターネットの石狩データセンタ見学ツアーに行ったことがあり、そのシリーズの記事がわかりやすかったので紹介します。
第4回さくら石狩DC見学ツアーはドキドキワクワクが連続する感動体験でした
この記事を読むとデータセンタはどんな設備を持っているのか、ざっくり想像ができると思います。
データセンタは通信やコンピューティングの設備を設置して運用することに特化した設備です。24時間365日稼働するために電源が2系統以上引き込まれていたり、それでも電源喪失した時のためのバッテリや自家発電設備も備え付けられていたり、データセンタ外と通信するための光ファイバーも多数引き込まれています。物理的な不正アクセスを防ぐためにセキュリティも厳しくなっています。こういった環境でサーバやネットワーク機器は稼働しています。
データセンタに設置されるような高集約・高密度なサーバやネットワーク機器は大量の電気を消費します。大量の電気のエネルギーは何に変換されるかというと、ほぼ全てが熱に変換されます。
re:Invent 2016のセッション中でストレージサーバの写真が紹介されていたのですが、ラックにみっちりと機器が搭載されているのがわかりますね。

これくらいの集約密度の機器がずらーっと数百〜数千ラック並んでいるのがデータセンタだと思っていただければだいたい合っているはずです。動画の中では1つのデータセンタあたり5万〜8万台のサーバがあると紹介されていました。
データセンタにはPUE(Power Usage Effectiveness, 1.0に近づくほど効率がよい)という指標があり、AWSのデータセンタのPUEは1.2未満だそうです。PUE1.2というのはIT機器が1000W消費したら付帯設備に200W程度消費しているということで、一般的に付帯設備の大半は冷却設備のことを示すため、200W近くは冷却に電力を消費していることになります。この値は平均的なデータセンタとくらべるとかなり良い数値だそうです。
冷却にもこれくらいの電力を必要とするくらいですから、冷却機能の喪失が直接的にサーバ等のホストに影響を及ぼしてしまったのも理解できると思います。
AZとは?
AZ(アベイラビリティーゾーン)とは、物理的、ソフトウェア的に自律しているデータセンタの集合の単位です。最近ではアベイラビリティーゾーン内でもCellという概念でさらに分割をしているようです。
Looking back at 10 years of compartmentalization at AWS
2014年のre:Inventからの引用のため、今のほうがもっと規模が大きくなっているとはおもいますが、基本的な考え方は変わっていないと思うので紹介します。
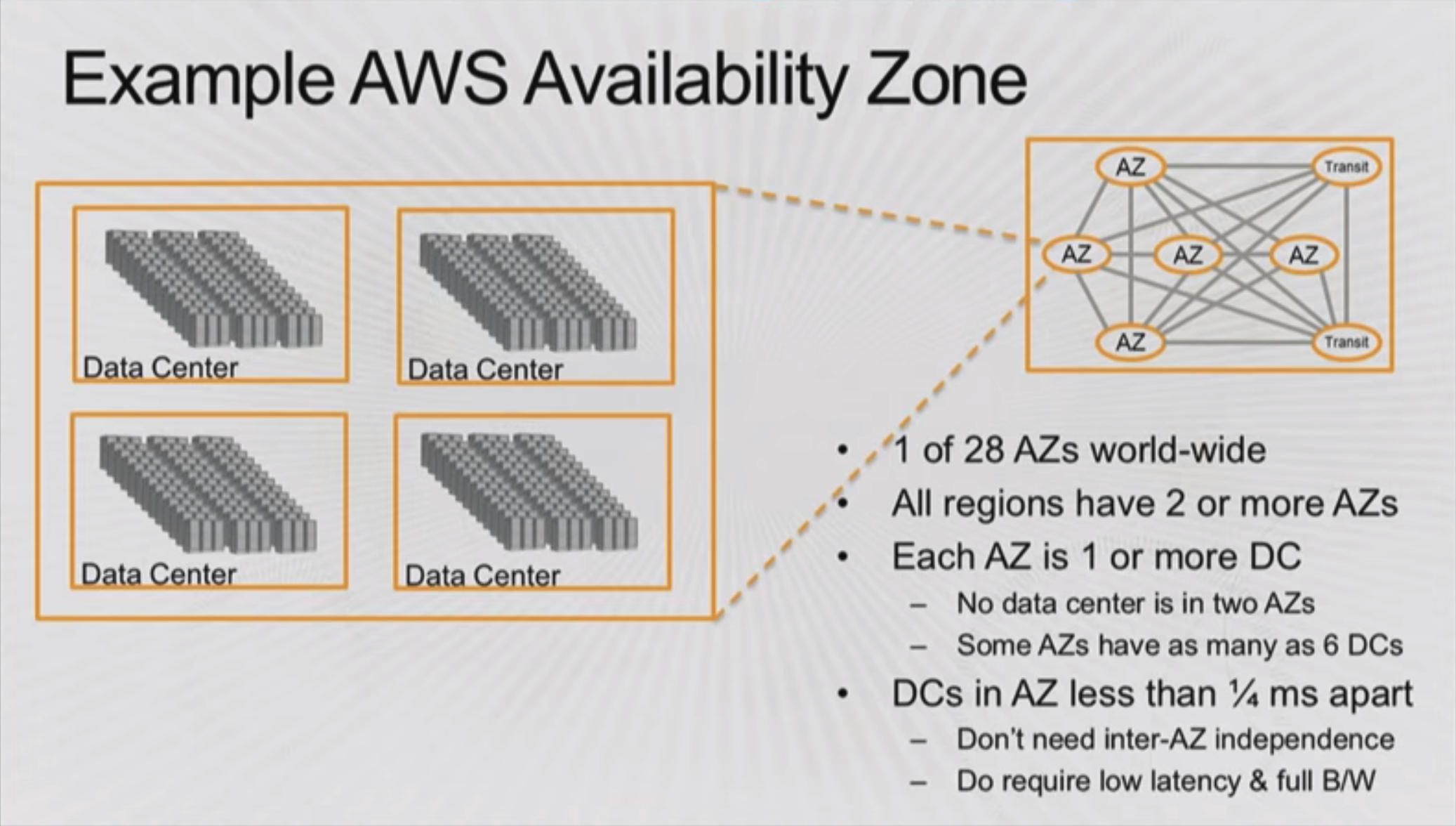
勘違いしやすいポイントですが、アベイラビリティーゾーンというのは1つのデータセンタの事を指しているわけではなく、1つのアベイラビリティーゾーンは1つ以上のデータセンタから構成されています。当時で多い場合で1つのアベイラビリティーゾーンが6つのデータセンタから構成されていたようです。ただし、同じアベイラビリティーゾーンに属するデータセンタ間の通信の遅延は0.25ms未満かつ帯域も十分に太いようです。概念的には1つの大きなデータセンタとみなしても差し支えなさそうですが、実際には複数のデータセンタから構成されていることがあります。これが単体のアベイラビリティーゾーンです。
今回の障害は冷却装置の制御に起因するもので、アベイラビリティーゾーン内のどこかのデータセンタ内の一部で発生したものと発表されています。もしこの障害がデータセンタ内全体に広がったとしても複数データセンタから構築されていた場合は他のデータセンタには影響せず、アベイラビリティーゾーン全体が障害にはならなかったのだろうなと推測しています。
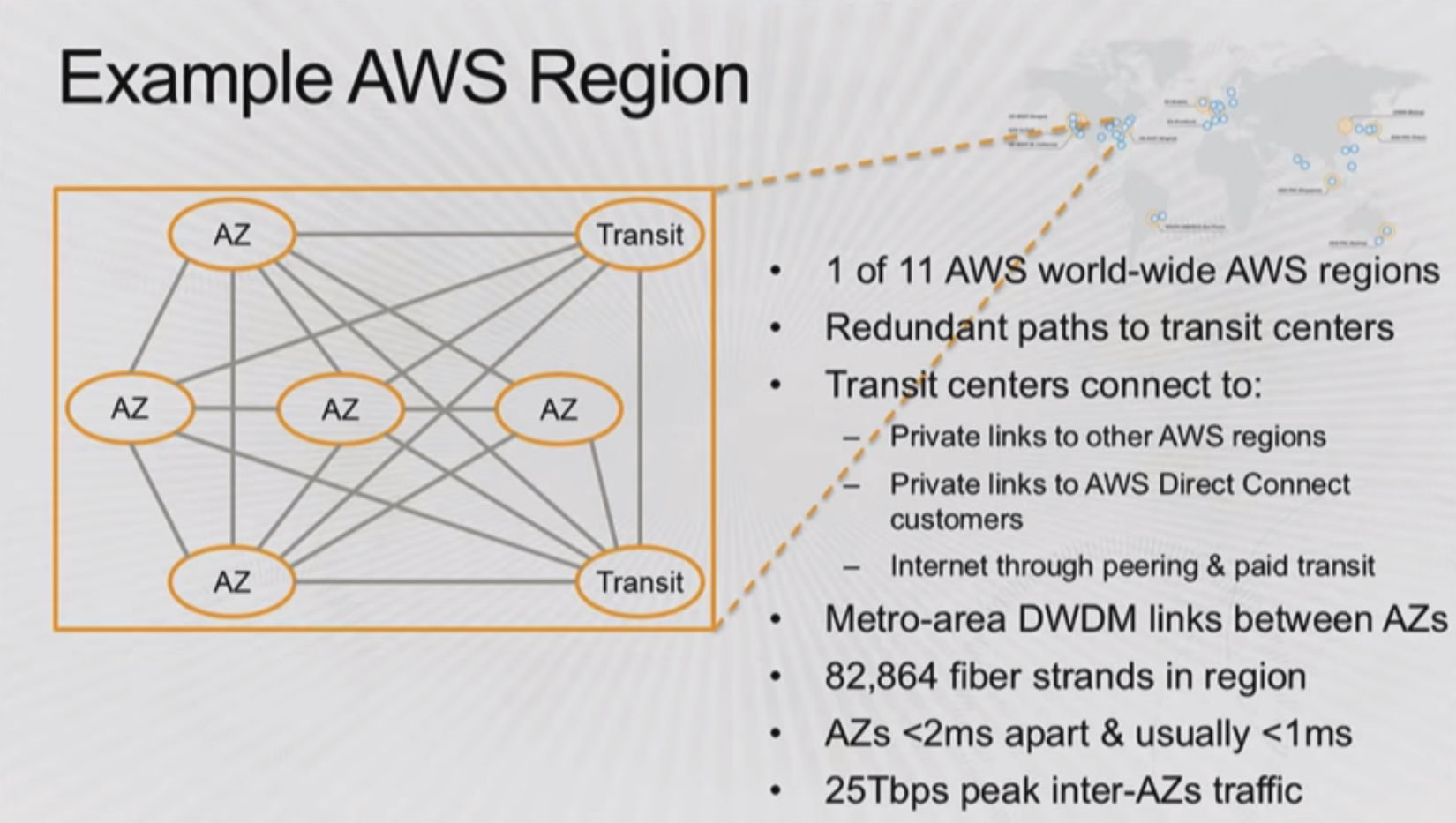
アベイラビリティーゾーン間は複数の冗長化された経路で接続されていて、DWDM(Dense Wavelength Division Multiplexing, 高密度波長分割多重)という技術で1本のファイバーに多数の信号を多重化して伝送しているそうです。この例だと全部合わせてで8万以上の論理接続を実現しているようです。
アベイラビリティーゾーン間の通信遅延は2ms未満になるように設計されていて、実際にはそれぞれのアベイラビリティーゾーンは100km以内に立地しています。
アベイラビリティーゾーン間がある程度の距離が離れていて、独立して稼働して作られていれば、例えばハードウェア的な要因でアベイラビリティーゾーンが一つまるごと障害が発生しても他のアベイラビリティーゾーンにデータが複製されていたり、サーバが稼働していたりさえすればサービス自体は継続が可能であるため、サービス全体では障害にはなり得ないという考え方のもと、アベイラビリティーゾーンは設計されています。
アベイラビリティーゾーン間の通信だけだとそれ以外の通信ができないため、トランジットセンターという施設が2つ以上存在します。トランジットセンターではAWSのリージョン間の通信やDirect Connect、インターネットに向けた通信を中継しているようです。
2つ以上のアベイラビリティーゾーンとトランジットセンターで構成されるのがリージョンです。
これによりリージョン単位で高い冗長性や高可用性が担保されています。
理論上はこのようになっていますが、実際サービスをアベイラビリティーゾーンを活用して理論通りの可用性きちんと担保するのは難しく、今回はアベイラビリティーゾーンの一部が障害になりましたがニュースを見ていると多くのサービスに影響が出たようでした。多くのアプリケーションがアベイラビリティーゾーンをまたいで分散できていても、ひとつでも単一障害点が単一のアベイラビリティーゾーンに遭遇し、運悪くそのホストが障害の影響を受けてしまえばサービス全体としては可用性を失ってしまうため、注意深く設計し作り込む必要があります。
また今回のAWSのロードバランサのマネージドサービスであるELB(ALB)が障害が発生していた時間に何度かELBがHTTPの500エラーを返すレートが上昇した事例がありました。ユーザ側でELBが障害の対象のアベイラビリティーゾーンを利用しないように切り替えることで結果的には対処できたのですが、複数アベイラビリティーゾーンで冗長化されているマネージドサービスに関してもアベイラビリティーゾーンの障害が発生時にはユーザ側で対処が必要になるのは想定外でした。これはマネージドサービス側の障害なのか、ユーザが監視し対処すべき前提のものなのか判断しかねるので調査中です。
他にも全体の可用性には影響しなかったものの細かい点で予想していなかった事がいくつかあったので対策をする予定です。
サービスレベルアグリーメント
AWSにはサービスレベルアグリーメント(SLA)が設定されているサービスが多くあります。EC2は以下のように定義されています。
Amazon Compute サービスレベルア グリーメント (PDF)
今回の障害に関連しそうな部分を抜粋すると、
サービス利用者がインスタンスまたはタスク(コンテイナー1 個以上)のうち該当するものを実行している同一地域内の複数の Availability Zone が、サービス利用者にとって同時に「使用不能」となることをいう。
ここになりそうです。複数のアベイラビリティーゾーンでインスタンスが使用不能ではない状態を月の99.99%以上に維持することがAWSのEC2におけるコミットメントであるため、今回の障害はコミットメントを下回る程度の障害ではなかったということになると思われます。
セキュリティの文脈ではありますが、AWSと我々顧客の責任範囲には定義があり、責任共有モデルと呼ばれています。今回の障害はどちらかというと責任共有モデルというよりはサービスレベルアグリーメントの部分で話す方が正しいと思いますが、重要な概念なので合わせて紹介します。
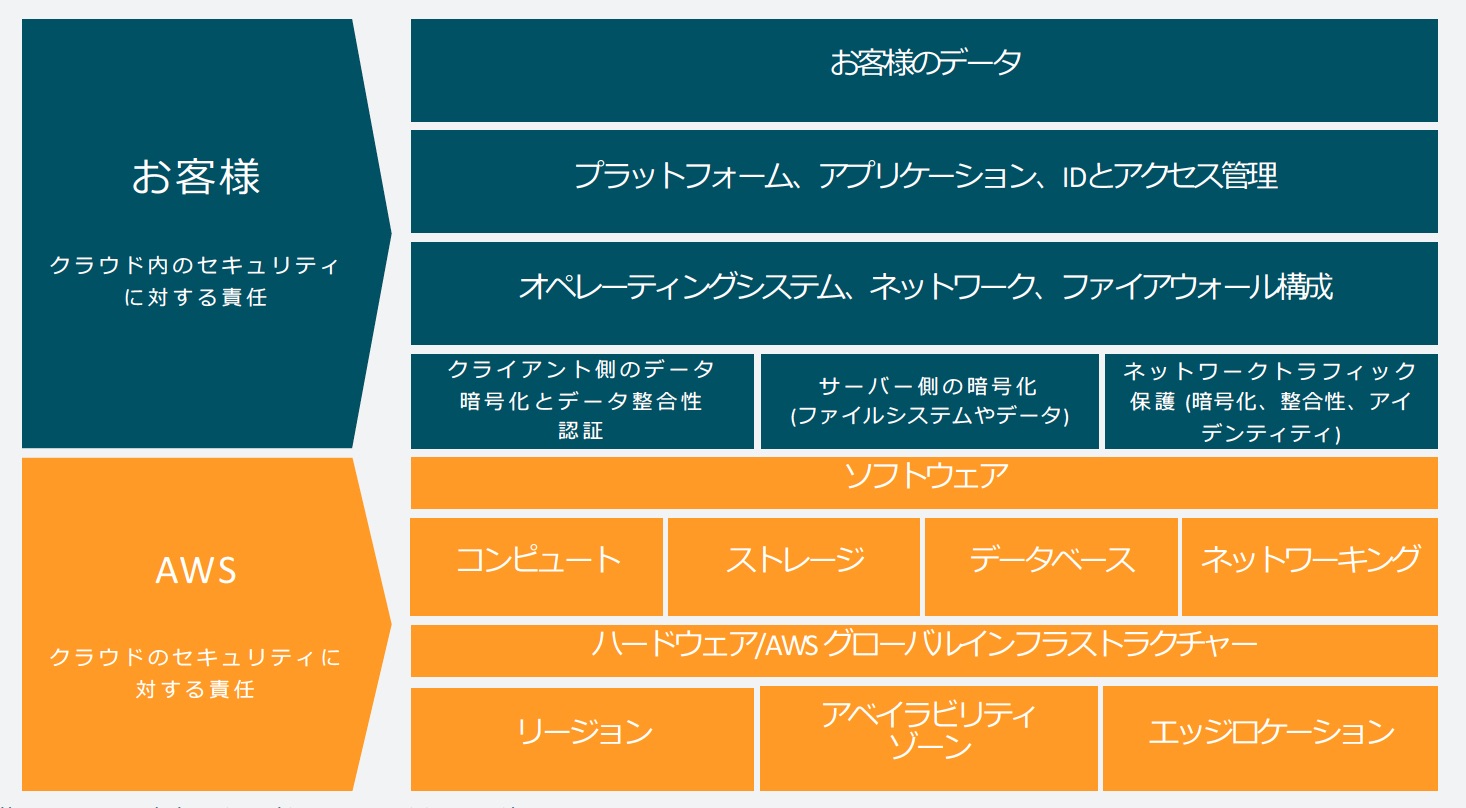
情報セキュリティには大きくわけて3つの要素があり、具体的には「機密性」「可用性」「完全性」です。これらを維持することが情報セキュリティで、今回のアベイラビリティーゾーンの障害にの文脈だと可用性が話題になりそうです。前述のサービスレベルアグリーメントですとEC2をリージョン単位で見て利用可能な状態に維持することがAWSの責任だという解釈ができそうです。ユーザのアプリケーションをアプリケーションレイヤで可用性を維持するのはユーザの責任ということになります。
サービスのコミットメントを下回った場合
サービスのコミットメントを下回った場合、「SLA クレジットの請求」という言葉を件名に入れて事象や影響を受けたリソースを記述すると、各サービスのサービスレベルアグリーメントに記載された表のとおりの割合のクレジットが発行され、利用料金の請求金額から差し引かれるようです。請求し承認されなければクレジットの発行は受けられません。
AZ障害が起きた時、ユーザはどうすべきなのか
今回はアベイラビリティーゾーンの一部が障害の対象でしたが、それでもニュースを見る限り多くのサービスが影響を受けました。冗長化しておくに越した事はありませんが、予期せず影響を受けてしまった場合の対処を考えてみます。
障害および障害が疑われるような事象が発生したときはまず原因の切り分けが大切です。
ホストやコンテナの健全性がすぐに可視化できるようなツールを導入しておくと便利です。以下の画像はDataDogでの監視の例です。サンプル用に適当に表示対象を絞り、適当にばらつきそうなメトリクスを選んで色をつけたのでこの画像自体には意味はありませんが、表示イメージ的にはこんな感じになります。ホストやコンテナの正常性や負荷で色付けすれば状況を可視化することができ、何が起きているのか把握できそうです。

日頃からメトリクスを収集し可視化できる状況を整えておけばアベイラビリティーゾーン単位の障害であればすぐに気づくことができます。
もしもアベイラビリティーゾーン単位の障害ということが確実にわかれば、回復するためには障害発生したアベイラビリティーゾーン以外でのリソースの強化を行う以外手段はありません。実際には同様の戦略を取るユーザが大量に居て、同じインスタンスタイプやサイズの在庫が不足しデプロイできなくなる可能性があるのでその場合は柔軟にインスタンスタイプやサイズを切り替えて対応しなければならないと思います。
冗長化しているはずにもかかわらず予期せず影響を受けてしまったケースが厄介ですが、中途半端に死活監視が成功してしまっていて悪影響を及ぼしている可能性があるため、慎重に原因箇所を特定し、特定アベイラビリティーゾーンが悪影響を及ぼしていることが判明した場合はそのアベイラビリティーゾーン自体の切り離しを行うかどうかの判断が必要になります。
今回はアベイラビリティーゾーン内の一部に対しての障害であったため、状況の把握に少し時間がかかりました。
アベイラビリティーゾーンをまたいでの冗長化がなされていないケースは残念ですが、最悪の場合データのロストも覚悟しなければなりません。
たまたま検証環境で冗長化していないインスタンスが障害の対象であったため、試しに強制シャットダウンをしたあと起動を試みました。強制シャットダウンが成功するまで時間が掛かったものの無事起動することができました。EBSのデータはアベイラビリティーゾーン内で複数のサーバにレプリケーションされているため、レプリケーションされている全てのサーバが故障していたり疎通が失われてさえいなければ新しいホストマシンで起動ができるようです。最終手段にはなりますが、強制シャットダウンを試すのも手かもしれません。
障害が起きうる可能性とどう向き合えばいいのか
AWSに限った話ではありませんが、サービスレベルアグリーメントおよび責任共有モデルの説明からわかるように、クラウド事業者は自社が提供するサービスにのみ責任を持っています。その上にシステムを構築し価値を提供するのは我々ネットサービス事業者ですから、自分たちで構築したレイヤの責任は自分たちで負わなければなりません。
データセンタ/アベイラビリティーゾーン単位の障害を回避するためには複数アベイラビリティーゾーンにまたがって冗長化された設計に、リージョン単位の障害を回避するためには複数リージョンにまたがって冗長化された設計に、特定クラウド事業者起因の障害を回避するためには複数クラウドにまたがって冗長化する、もしくは自社でデータセンタを運用し全てをコントロール下に置くことも視野に入れる必要があるかもしれません。
後ろに行けば行くほど難易度が上がってきます。多くの物を組み合わせた方が同時に障害等の異変が発生する確率が下がりますが、それと同時に複数のものを組み合わせてうまくいくように作り込む難易度が高くなり、逆に可用性が下がってしまったり、サービス開発の柔軟性を損ねる可能性もあります。
100%の可用性を求めるのは現実的ではないため、サービスを提供する側としてはどのレベルを目指すのかをまず考える必要があります。サービスの規模や特性、売上を考慮して掛けられるコストとビジネスを成立させる上での現実的なラインをさぐらなければなりません。(逆に要件にコストが見合わない場合はビジネス設計の方を修正すべきかもしれません)
最低限複数アベイラビリティーゾーンで冗長化されていれば今回のレベルの障害であれば最終的には乗り切れるはずですが、一つのアベイラビリティーゾーンがまるごと障害となっても直ちにサービスが継続できる程度のリソースを常日頃からコミットしておくべきかというと議論の余地があると思います。
また、サービスが停止してしまったとしても最低限保全しなければならないもの(ログやDBのバックアップなど)が守られる仕組みさえ整備されていれば万が一の際にも障害がきっかけでサービスを終了しなければいけなくなるという事態だけは防げるので、こちらに関しても定期的に防災訓練のようなものを行っておくのが理想だと思います。
このあたりの考え方も少し本に書いた事がありますので、興味がある方はぜひ読んでみてください(宣伝)
(学生向け)弊社のデータセンタ見学会を開催します
最後に告知です!
弊社ではAWS以外にGCPも使っていますし、プライベートクラウドも開発、構築、運用しており、サービスの特性に合わせて最適なものを組み合わせて活用しています。
学生向けではありますが、データセンタの見学会を開催します(何度か開催する予定です)。学生だと特にデータセンタという単語は聞いたことがあっても、どんなものなのか想像がつかない人も多いと思います。学生は特に実物を見る機会はあまりないと思いますので、興味を持たれた方はぜひ応募してみてください。
