
AI事業本部 Dynalystの事業責任者の木村です。
Dynalystは広告配信プロダクトとしてもうすぐ6周年を迎えるサービスなのですが、ある程度理想とする組織の姿に近づきつつあるので、プロダクトを支えるデータサイエンスチームについてどういう風にプロジェクトが育っていったか少し紹介しようと思います。
前提とする状況は以下。
- 広告配信に関わるログは基本的に全てS3に蓄積されている
- 分析基盤としてRedshiftが稼働しており、だいたいのログはSQLでアクセス可能
- 配信のアプリケーションはScalaでできている (分析で利用する言語はPython, Rが主)
当然最初からチームがあった訳ではなく、徐々にプロジェクトらしくなっていったというのが正直なところです。
人数論で語るべきものではありませんが、実際やれることの幅は変わってるなということで、規模に応じてどう変わっているかをみてみます。
【1,2人で回すMLプロジェクト】
- 当然やれることは限られます。(優先順位がとても大事)
広告配信のサービスなので、いわゆる王道のCTR予測, CVR予測
などプロダクトの基盤ともいえるところがメインになります。
- 分析から実装まで、結局人がいないので、スキルを習得する必要があります。
データサイエンティストもバックグラウンドはそれぞれですが、プロダクトとしては、価値を生むには何かしらの形で実環境にのせないといけません。
サーバーサイドのエンジニア陣もとても優秀なので、サポートしてもらいつつも、データサイエンティストはModelingを中心に、その前工程(ETL, ログ収集 etc)、後工程(Inferenceの為の実装や、ModelのVersioning etc)をキッカケにインフラ知識や、Scalaの実装スキルを習得します。
- 想像以上に、in-serviceになったMLの予測モデルたちを面倒をみるのは大変です。
予測モデルは一度作ったら終わりではないことが多く、
継続的なメンテナンスや監視などが必須です。(Concept Driftが起きて広告枠を爆買いしてしまったことも何度かあります。。)
【3,4人で回すMLプロジェクト】
- より顧客にとってわかりやすい価値を提供する機能に手をつけられます。
例えば、CPI最適化やCPA最適化、予算制約内のCV数の最大化などCTRやCVRの予測はもちろん前提として必要なのですが、マーケターにとってわかりやすい「機能」として認識できるようになります。
- 稼働する予測モデルの数が増えます。
配信サーバーのパフォーマンスが気になりはじめます。制約条件としてのInferenceCostを意識します。オフラインで驚異的な精度が出せても、予測のコストが高いと導入に至りません。
10msecそこらで予測+その他の処理を実行するにはかなりのテクニックが必要になります。
cacheレイヤーの設計から、ModelのKey構造まで、かなりサーバーサイドエンジニアが力を合わせて解決する課題です。同様に予測モデルを作るJobFlowも複雑になっていきます。
(Jenkinsおじさんはもう引退したそうな顔をして僕を毎日みつめてきます)
※ いわゆるMLOpsといわれる領域ですが、ここは書き出すと長いので、別の機会に。
- 作った人しかわからない問題と向きあう
Dynalystのデータサイエンスチームは週次の定例MTGを実施しています。取り組む内容はそれぞれですが、進捗や設計の方向性などここで議論しレビューをもらいます。また、取り組む内容に対して、ビジネスKPIに及ぼす影響も大きいことが多いため、A/Bテストはかなり厳格に行う習慣が付いています。
ここで、各々がどういう進捗なのか共有するので、コードレベルまでは分からずとも、どういう予測をしてどうプロダクトに組み込まれるのかを理解できます。
【5,6人で回すMLプロジェクト】
- 世の中的にもあまりないような研究開発に近いコトに取り組める余裕が少しでてきます
いわゆるリサーチ部門ではないのですが、内容的に論文をアウトプットにする場合もあります。直近だと、WSDMやWWWなどに論文を投稿し、実際にAcceptされています。
- 情報共有などの定例は時間が足りなくなりはじめます。
コミュニケーションパスを考えれば当然ですが、結構プロジェクトリードのディレクション能力が問われるのではないでしょうか
- ちゃんと成果が出ていくと、やりたいことはさらに増えていきます
【7+で回すMLプロジェクト】
- チームのメンバーの考え方次第ですが、どうプロジェクトを回すか岐路に立ちます
ここで改めて、ML系プロジェクトの実態と向き合うことになります。
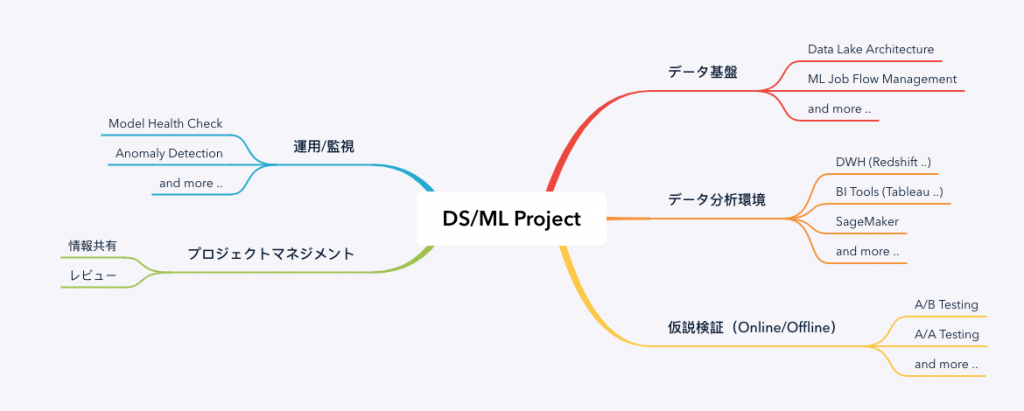
通常の開発のサイクルとの違いで大きいのは、A/Bテストなどのオンライン検証の時間をコントロールしづらい点ではないでしょうか。
(CounterFactual Machine Learningなど昨今力を入れている領域もありますが、いつでもどこでも使える訳ではありません)
個人的な見解ですが、上記の理由から、通常のプロダクト開発プロセスと同様の期待でフロー効率を追い求めるのは難易度が高いのではないかと思います。
実環境でのテスト中は様子をみつつも、別の事柄の仕込みをするような器用さが必要だったりします。
一方で、プロダクトに対していくつもの予測タスクを同時に検証したりするのも、因果関係を切り分ける作業が必要になり、苦労するところです。
考え方の一つですが、向き合う対象の課題を広げるという視野も大事です。
AIにまつわる事柄は誤解を恐れずにいうと、「何を予測するか?」であり、それによって何かのコストが劇的に下がるというのが昨今のAIブームの大枠の現象です。Dynalystを取り巻く周辺環境にも小さなことから大きなことまで活用先はたくさんあります。
もし、顧客のマーケティング予算が半年先まで予測できたなら?
もし、配信する前にクリエイティブの効果が予想できたなら?
上記はセールス戦略に影響を及ぼすようなものですが、
プロダクト戦略の根幹を為すような予測タスクというものもたくさんあります。
というわけで、Dynalystはまだまだたくさん向き合いたい予測タスクがたくさんあるわけですが、ここには惜しみなくヒトもお金も投資していく所存です!
興味がある方はぜひチームメンバーにお声がけください。
これからそういうチームを作ろう、さらに大きなチームにしよう、どっから手をつけたらいいかわからんという方々にとって少しでも参考になるところがあれば嬉しいです。