
こんにちは、技術本部 プライベートクラウドグループの中西(@whywaita)です。
今回はCA Tech JOBの制度を用いてインターンに参加して頂いた上野さんからの寄稿記事です。
以下本文です。
みなさんはじめまして。
メディア事業部技術本部プライベートクラウドグループで、2ヶ月間のインターン(CA Tech JOB)を行いました上野裕一郎 (https://www.y1r.org) です。普段は東京工業大学で深層学習をスパコンなどの高性能計算技術で加速・大規模化させる研究をしています。
本インターンではSegment Routing、とくにSRv6を用いてKubernetesのPodネットワーキング機能(CNI)を実装しました。本稿では、CNIとSegment Routingについて紹介したのち、その実装と動作を説明します。
Container Network Interface; CNI
まず、Container Network Interface(CNI)について説明します。CNIは、コンテナ間のネットワークを実現するためのソフトウェアの仕様です(参考)。この仕様に則って実装されたプラグインを、コンテナの生成や削除の度に呼び出すことで、プラグインがコンテナにIPアドレスを割り当てたり、プラグインがコンテナ間のネットワークを実現するために用いられるブリッジを構成したりします。Kubernetesは、この仕様に則ったプラグインをサポートすることで、ワーカーノードが物理的に接続されているネットワーク(Underlay Network)を意識せずに、それぞれに配置されたPod間(Overlay Network)の通信を実現しています。
では、どのようにすればPodネットワーキングが実現できるのでしょうか?
例えば、同一ノードに作成されたPod間の場合、ブリッジなどで仮想的にネットワークをつなげることで通信が行えます。しかし、他のノードに作成されたPod間のネットワークは、どのようにしてつなげられるのでしょうか?これには例えば、NATやルーティング・カプセル化などの方法があります。しかし、Kubernetesネットワークの基本要件から、NATを用いることはできません[1]。そこでKubernetesの文脈では、ルーティングやカプセル化などの手法が用いられています。
よく知られているCNIの実装として、Project Calicoやflannelがあります。Project CalicoはBGPによるルーティングを用いていますが、flannelはカプセル化を用いています。
flannel
ここでは、今回の開発のベースとして用いたflannelをより詳しく見ていきます。flannelはVXLANやIP in IP Tunnelingなどのカプセル化プロトコル[2]を用いており、デフォルトではVXLANが使用されています。そして、flannelでは、Podネットワーク(デフォルトで/16の大きさ)を、ノードごとに分割(デフォルトで/24の大きさ)しています。つまり、PodのIPアドレスがどの/24セグメントに属しているか、からどのノードに作成されたPodかを解決することができます。
flannelは、2つのコンポーネントから構成されています。
以下では、それぞれのコンポーネントの責務について紹介いたします。
flannel CNIの責務は、PodへのIPアドレスの割り当てと、ノード内Pod間ネットワーキングの実現です。ノードごとにPodが接続する仮想ブリッジインターフェイス(cni0, /24)を構成し、ノード内のPod間ネットワーキングを実現します。
flanneldの責務は、ノード間Podネットワーキングの実現です。先程述べたようにflannelの場合、PodのIPアドレスから、どのノードに属しているPodかは直ちに分かります。よってflanneldは、PodのIPアドレスに応じて、適切なノードにカプセル化されたパケットを転送するルールを予め構成することになります(flanneldは、直接パケット転送に関わるData Planeではなく、Kernelの設定を変更するControl Planeになります)。このときに、先程述べたVXLANのデバイスや、IP in IP Tunnelingを構成してKubernetesのPodネットワーキングが実現されます。例えばIP in IP Tunnelingを用いる場合、ホストのルーティングテーブルに、「宛先が特定のノードのPodネットワーク(/24)の場合、特定のノードのUnderlay Networkのアドレス宛にIP in IP tunnelingでパケットをカプセル化して送る」という経路を追加します。
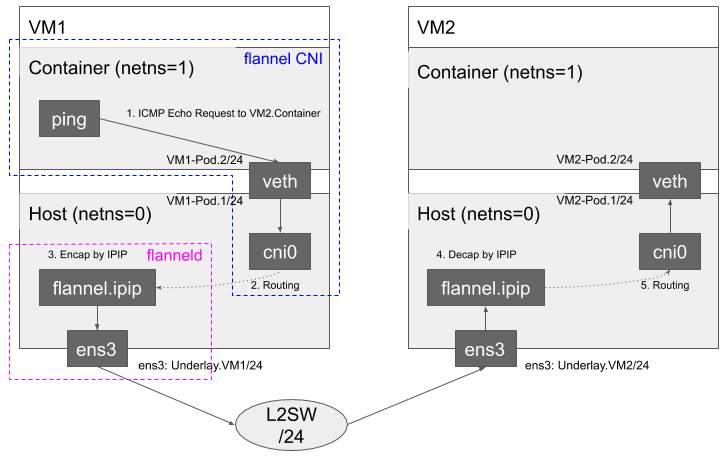
結果として、次のようなネットワークが構成されます。図にVM1内のContainerから、VM2のContainerに対するICMP Echo Requestが送信されたときの様子を表します。また、赤色と青色で前述したそれぞれのコンポーネントの責務の範囲を表しています。
まず、veth pairを経由して、コンテナのnetwork namespaceからホストのcni0ブリッジにパケットが到達します。そして、flanneldが予め構成したIP in IP tunnelingインターフェイス(flannel.ipip)を経由してVM2に向かうルートが選択され、適切なIP in IP Tunnelingが行われ、パケットが転送されます。対応するVM2では、適切なDecapsulationが行われ、同様にcni0, veth pairを経由してPodのnetwork namespaceまでパケットが転送されます。
今回のインターンでは、(実装の簡単のため、様々な仮定のもと)flanneldにコードの追加を行ってSRv6によるカプセル化を行い、KubernetesのPod間ネットワーキングを実現しました。
Segment Routingとその実装SRv6
Segment Routing
続いて、Segment Routing[3]とその実装SRv6について見ていきます。Segment Routingは、ソースルーティング(最終送信先だけではなく、パケットの中継先を指定する)を実現するルーティング手法です。例えば、サービスチェイニングと呼ばれる、ユーザごとに経由するサービスを制御する仕組みを実現することができます。
図に、Segment Routingを用いて構成したネットワークを示します。濃色で示されているルータがSegment Routingを理解するルータ、白色で示されているルータがSegment Routingを理解しないルータです。Segment Routingを理解するルータは、Segment Routingのヘッダを解釈してIPヘッダを更新しますが、理解しないルータはIPヘッダを更新しません。
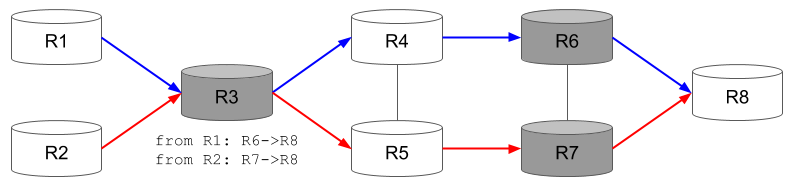
R3は、パケットの送信元によって、経由するルータをSegment Routingを用いてR6とR7で変更する機能をもったルータとしましょう。このとき、R3から送信されるパケットは、IPv6ヘッダの宛先はR6、もしくはR7となっていますが、Segment RoutingのヘッダにはR8が宛先ルータとして書かれており、Segment Routingを理解するR6, R7のルータによって宛先がR8に書き換えられます。よって、R1からR6に向かうパケットの場合、R3から送信されたときには、IPv6ヘッダの観点では宛先はR6なので、「通常のIPヘッダによるルーティング」で、R4を経由します。よって、R4がSegment Routingを理解する必要はありません。
サービスAとサービスBによる、Multi-Tenancy下のKubernetesクラスタを考えてみます。例えば、サービスAのコンテナからのパケットは信頼できないためIDS/IPSによる検査が必要ですが、サービスBについては検査が必要ない、というようなネットワークポリシーを考えてみましょう。このポリシーを実現するには、全ての通信について、サービスAとサービスBのどちらに属する通信かを特定してルートを変更する必要があります。そのためには、Underlay Networkの機器がKubernetesにパケットの送信元アドレスから対応するネットワークポリシーを問い合わせる必要があります。このような機能の実現は、Kubernetesと連携できるような拡張性のある機器をUnderlay Networkに用いる必要があり難しいです。
しかしSegment Routingでは、Podネットワーキングの両端であるLinuxホストで行われるカプセル化でネットワークポリシーをパケットに埋め込めるため、実装が比較的容易となります。また、パケットを転送するルータは、ポリシーを管理する必要はなかったり、Segment Routingを理解する必要も(例に挙げたR4やR5のようにほとんど)ないため、既存のルータをそのまま利用することができます。
SRv6
SRv6は、上の図でルータに付けた1~8の識別子のようなSegment ID(以下、SIDと略します)にIPv6アドレスを用いるものです。他にも、MPLS データプレーン上にSegment Routingを実現するSR-MPLSがあります。
Linuxは、Kernel 4.10からSRv6をサポートしており、簡単に試すことができます。実際にどのような設定ができるかは[4]が詳しいですが、一部ご紹介いたします。SRv6では、R6やR7のようなパケットの転送機能の他にも、R3のようなカプセル化機能が必要になります。これらのNetwork Functionには提案されている仕様があり[5]、その一部は既にLinux Kernelに実装されています。(他の実装されていない機能は、カーネルモジュールで開発されていたり[6]します)。以下に例を示します:
- End
- 通常のSegment Routing Headerの処理。残りセグメント(残りの経由するルータ)が1以上あることを仮定する。残りセグメントから1つPopし、IPv6のDestination Addressを書き換える。(つまり、Segment Routing Headerの削除は行いません)
- End.DX4
- Segment Routing Headerを削除する(Decapする)処理。残りセグメントが0であることを仮定する。Decapし、内側のIPv4ヘッダから成るパケットを送信する。End.DX4を設定するときに、Next Hopアドレスを指定できるようになっており、それを経由して送信するか、(0.0.0.0を指定して)直接送信することができる。
- End.DX6
- Next Hopアドレス・内側のIPv6ヘッダについて、End.DX4と同様のDecapを行う。
- End.BPF
- eBPFで拡張できる。
- T.Encaps
- パケットのカプセル化(Encap)を行う。
- 他にも?
- End.DT4(ホストのv4ルーティングテーブルを用いて、次ホップを検索)など。
今回はT.EncapとEnd.DX4を用いて、Kubernetesのノード間接続(Underlay)上に、Pod間接続(Overlay)を実現しました。
SRv6によるOverlay Networkの実装
以下に、今回構築するOverlay Networkのネットワーク構成を示します。図にVM1内のContainerから、VM2のContainerに対するICMP Echo Requestが送信されたときの様子を表します。まず、veth pairを経由して、ホストのcni0ブリッジにパケットが到達します。T.Encapsによりパケットをカプセル化する仕組みは、IP in IP Tunnelingとは異なり、特殊なデバイスを作るのではなく、ルーティングテーブルに対応するエントリを追加することで実現します。あとはこれをVM2でDecapsulationするだけです。しかし、ens3にSIDと同じIPv6アドレスを付与してしまうと、ホスト宛のパケットとして処理されてしまい、End.DX4のハンドラ[7]にパケットが届かないという問題がありました。この問題は、@makotakaさんのQiita[8]でも報告されており、カーネルモジュール[6]による設定では発生しませんでした。
ここでは、カーネルモジュールをインストールできないような環境でも動作させるため、別のアプローチを考えました。それは、ens3にSIDと同じIPv6アドレスを付与しない、というアプローチです。Linuxの場合、物理デバイスに届いたパケットが、自分のデバイスに割り当てられているパケットかどうかの検証は行われませんが、該当するパケットのハンドラが見つからない場合には破棄されます。よって今回のようなハンドラはある(End.DX4)場合には、ens3にIPv6アドレスが付いていなくてもパケットは到達しました。なお、ループバックデバイス(lo)にIPv6アドレスを付けた場合にも同様の問題が起こりました。しかし、Kernelには自ホストにどのIPv6アドレスが付いているか分からないため、kernelの機能であるIPv6アドレスから物理アドレスを問い合わせる近隣探索プロトコルの応答機能は動作しなくなりました。この問題を解決するため今回は、全VMのneighテーブルはCNIによって予め構成されるようにしました。これにより、直接接続されているVM同士の場合には、SRv6によるKubernetes Pod間ネットワーキングを実現することができました。
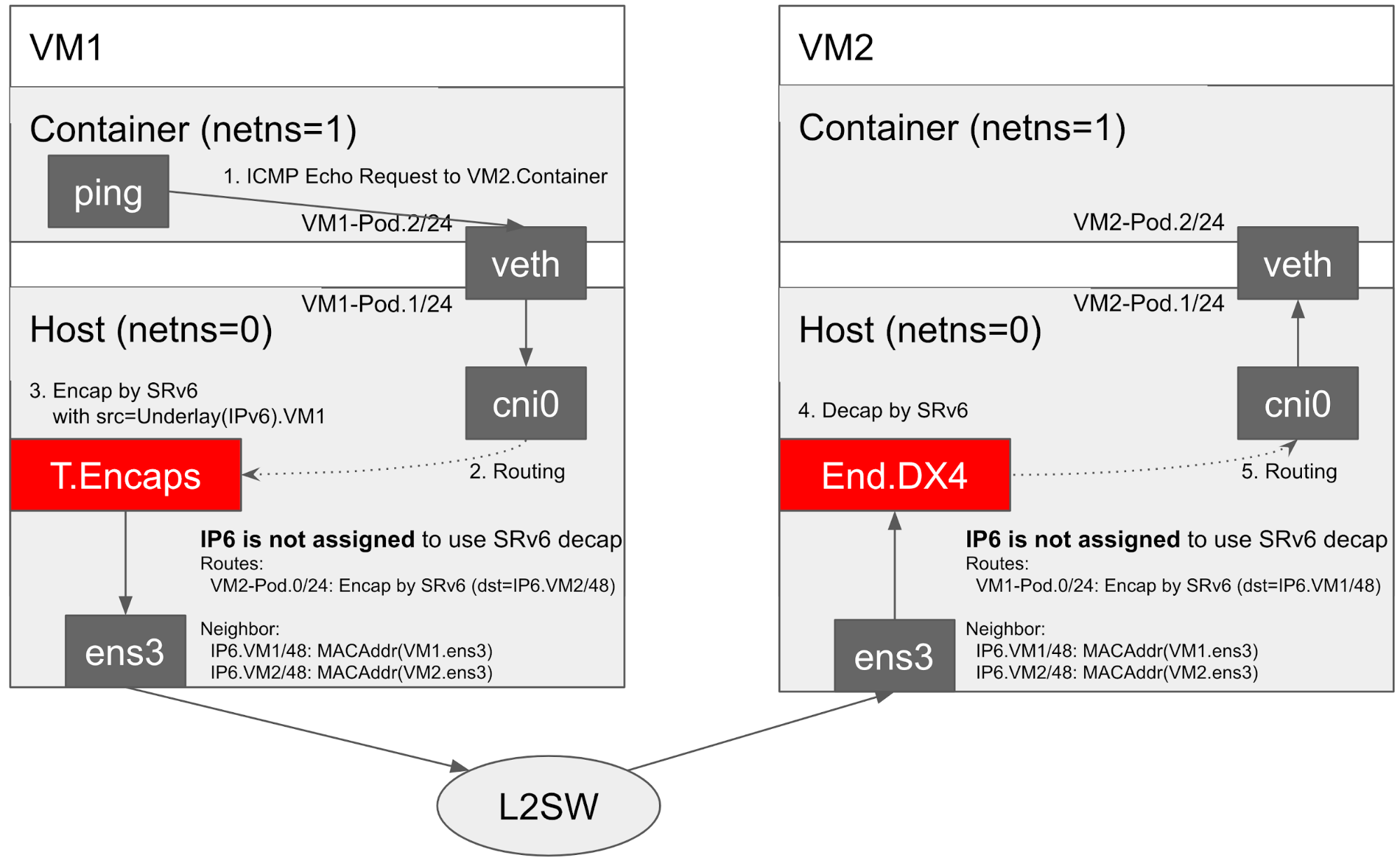
L3で接続されているVM同士の通信は、今回のインターンの範囲では実装することができませんでした。
なお、以下のようなアプローチでこの問題を解決できるかもしれません:
- 対向のルータのneighテーブルを設定する
- ルータのneighテーブルにetcdと同期する仕組みを実装する
- Neighbor Advertisementで、外部からテーブルにエントリを流し込む
- End.DX4を拡張する
- End.DX4の機能とICMP v6近隣探索プロトコルの機能を併せ持ったNetwork Functionを実装し、他のノードからのNeighbor Solicitationに答えられるようにする
- Advertisementを返す専用のVMをネットワーク上に追加する
実装したコードの紹介
https://github.com/y1r/flannel-srv6 に、今回のインターンシップで実装したCNIのコードを公開しています。IP in IPやVXLANなどのカプセル化を用いたOverlay Networkの実装に対応したflannelをベースとして開発しまして、backend/srv6 ディレクトリ以下が今回実装したコードになります。
以下に、今回のOverlay Networkを実現するために実装した機能の概要を示します。
- KernelのSRv6機能を有効にする(
seg6_enabled=1) - 現在割り当てられているIPv4アドレスからIPv6アドレスを生成してSIDとして用いる
- 決められたSIDに対応するencapルートを追加する (
ip route) - 決められたSIDに対応するdecapルートを追加する (
ip route) - 決められたSIDに対応してパケットが送信されるよう設定する (
ip sr tunsrc set {$SID}) - 決められたSIDに対応してneighテーブルを設定する (
ip neigh) - iptablesの構成
より詳しくは、ソースコードをご覧ください。
パケットキャプチャによる検証
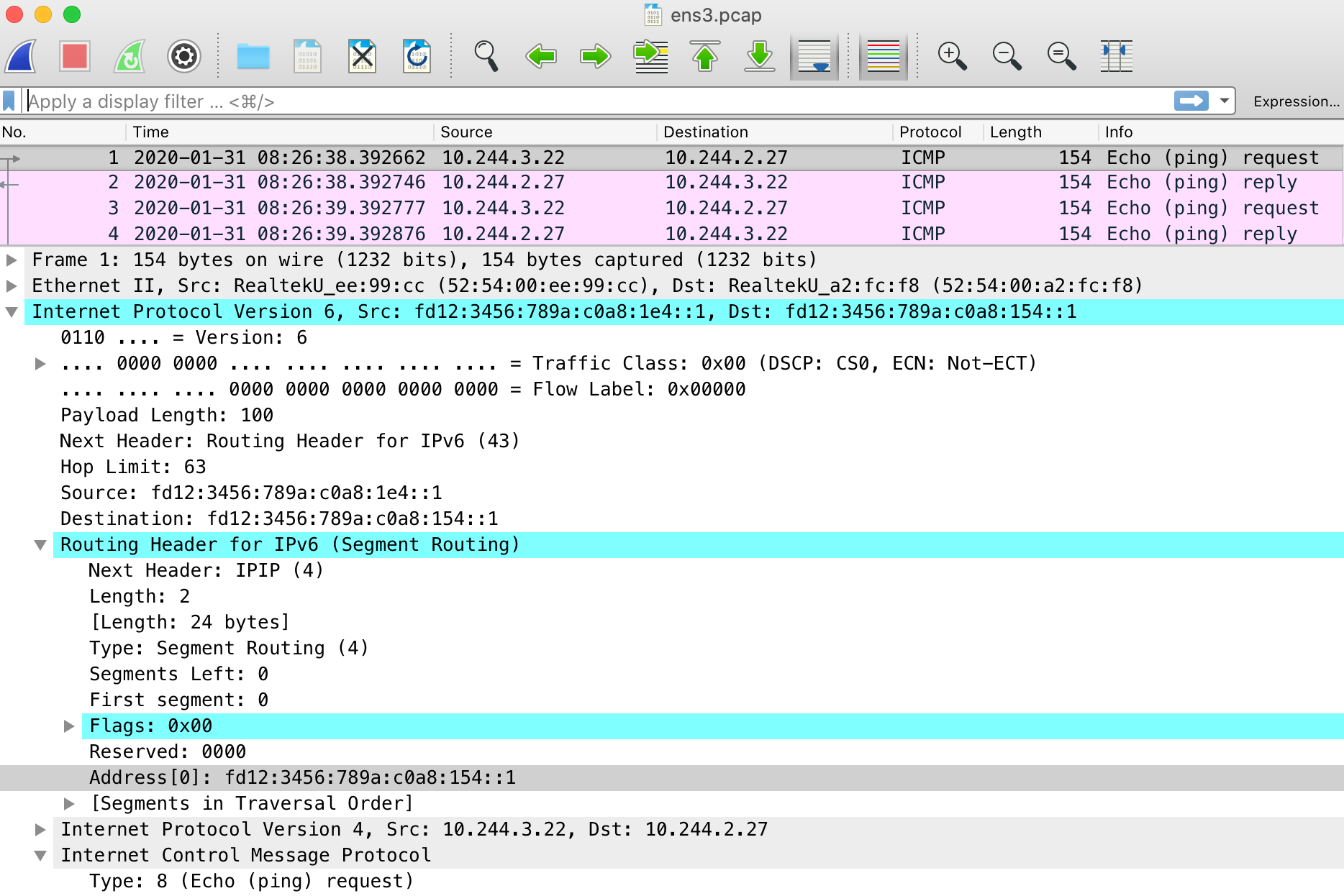
以下に、Pod間のping疎通を行っているときのパケットを物理インターフェイスens3で採取した結果を示します。IPv6のヘッダに拡張ヘッダであるRouting Header for IPv6 (Segment Routing)が追加され、その中にIPv4ヘッダ、ICMPのペイロードが含まれており、pingの疎通ができていることが確認できます。
まとめ
本稿では、SRv6を用いてKubernetesのPod間ネットワーキングを実現するCNIを、flannelをベースに実装しました。前述したようなKernelの挙動に悩まされ、L2で直接接続されているようなノード間のCNI実装しかできませんでしたが、自分で手を動かして、新しいKernelの機能を検証するのは非常に楽しい体験でした。デバッグのためにKernelのコードを追ったのは今回初めてで、どこでパケットが落ちているのか検証するため、多くのprintkをKernelに追加し、数十回もビルドを行ったのは手間がかかりましたが、大変勉強になることも多かったです。今回の問題は、Kernelに手を入れなければ原因を特定できなかったと思います。これからも、身近で発生した問題を(必要とあらば)Kernelまで潜って調べていきたいと思いました。
今回のインターンでは、プライベートクラウドグループのメンターの方々に大変お世話になり、ハードウェア的にも進捗的にも多大なるサポートをいただきまして、とりあえず動くものを作って公開まででき、大変うれしく思っています。本当にありがとうございました。