
AI事業本部 Dynalystの黒崎(@kuro_m88)です。
今回はCA Tech JOBの制度を用いてインターンに参加して頂いた塚越さんからの寄稿記事です。
以下本文です。
みなさん初めまして!
AI事業本部のDynalystというWeb広告に関するプロダクトのチームで、2020年3月の間 CA Tech JOBに参加させて頂きました、名古屋大学情報学部コンピュータ科学科4年の塚越駿(@hppRC)と申します。最近はもっぱら自然言語処理の研究やお勉強をしています。
本インターンでは、Scalaのactor modelを採用した並行処理ライブラリのAkkaと、それをベースにしたストリーミング処理用ライブラリのAkka Streamsを用いて、DynamoDB Streamsから流れてくるイベントレコードを元にしたmemcachedのキャッシュ削除処理を実装しました。
本稿では、まず実装内容の説明のためDynalystというプロダクトに関して紹介し、併せて広告など周辺知識・技術などについても説明します。次に実装内容や苦労した点について解説します。最後に、インターン自体の感想や、特殊な社会情勢の中での開催だったことを踏まえて、どういった対応があったかなども書いていきたいと思います。

Web広告
さて、Web広告について理解していないとDynalystがどういったプロダクトかを理解するのも大変なので、まずはWeb広告の流れをザックリと説明します。
Web広告の舞台には、主に以下の4役が登場します(実際はもっと複雑です)。
- ユーザー(端末): Webサイトへアクセスすると、そのページ内の広告枠に関してオークションが始まります。このユーザーがコンバージョン(商品なら購入までだったり、ゲームならインストールだったり)してくれるのがWeb広告の目的です。
- SSP(Supply-Side Platform): Webサイトからのアクセス情報を元に、オークションを開催して複数のDSPからの入札を募集します。メディア(広告枠を提供している側)の利益を最大化させるためのサービスです(出来るだけ広告を高く買ってほしい!)。
- DSP(Demand-Side Platform): 広告主(広告配信を希望している側)のためのサービス。ユーザーのコンバージョン確率などを元に入札の是非と入札金額を決め、入札リクエストをSSPに送ります。広告効果を最大化させ、効率的な広告配信が出来るようにするのが目的です (安くて良い広告枠を買いたい!)。
- 広告主: 商品が売れて欲しい、アプリをインストールして欲しい!
また、Web広告が配信されるまでの流れは以下のようになっています。
- あるユーザがWebサイトのページを見る。
- ページ内の広告に関して、サイトからSSPに広告リクエストが飛ぶ。
- SSPは受け取った広告リクエストを元に各DSPへ入札リクエストを送る。
- DSPは広告枠の情報を元にいくらでその枠を購入するか決定し(100ms以内)、SSPにレスポンスを返す。
- SSPがオークションの勝者を決定し、サイトに勝者のレスポンスを返す。
- 広告枠にコンテンツが表示される。
実際には、一つの枠に対してSSPも複数存在し、また1つのDSPは複数のSSPに対して入札を行いますが、簡略化すると上記のような形になります。
Dynalystはこの中の、DSPにあたるプロダクトです。

Dynalystと実装の背景
次にDynalystに関して説明します。Dynalystはリターゲティング広告を主軸にしたプロダクトです。
リターゲティング広告は、一度広告主のWebサイトを訪問したことのあるユーザに対し、広告主に関連した広告を出すなどして、効率的に広告を行う方式のことです。これによって、例えばゲームの広告をするのであれば、休眠中のユーザに対して広告を出すことでもう一度起動してもらえるように訴求し、アクティブユーザーを増やすことに貢献します。
SSPからの入札リクエスト時にIDFAやAAIDといった情報が送られてくるので、それをもとにユーザ属性などを判定して処理を行います。これらの情報を元に、あらかじめ用意しておいた機械学習モデルを用いて、そのユーザーがどの程度の確率でコンバージョンするか、といった情報を予測して入札金額を決定します。
Dynalystでは入札時に利用するリアルタイム性の高い情報をDynamoDBに保存しています。
頻繁に使用されるIDとその値は、オンメモリでキャッシュすると効率的です。そこで、Dynalystではmemcachedを用いてDynamoDBの値のキャッシングを行っています。DynamoDBに直接キーを引きに行く前にmemcachedにキーが存在しているか確認し、キャッシュされていなければ、改めてDynamoDB にデータを引きに行きます。
キャッシュされている値は入札や配信に関する様々な情報を保持していますが、もしこの属性の値に変化があった時は、誤った情報を用いないように前もってキャッシュを削除しなくてはいけません。DynamoDBはupdateなどのイベントに関する情報が入ったレコードをDynamoDB Streamsに流すことができ(要設定)、この変更情報を元にしてキャッシュの削除処理を行うことができます。
Dynalystではもともとこのキャッシュ削除処理をAWS lambdaで実装していました。しかし、DynamoDBのイベントの発生回数は膨大で、愚直にDynamoDB Streamsに流れてくるレコードをLambdaがポーリングするように実装していると、同様に膨大な回数Lambdaが走ることになります。Dynalystではこの問題を緩和するために、Lambdaの1回の呼び出しで処理するレコードの数を増やすなどして対応していましたが、それでも1回のLambdaの処理時間が30秒程度になるなど問題を抱えていました。
そこで、Lambdaで実装していた処理をECS(Elastic Container Service)に載せ替えた上でストリーミング処理を行えるようにしよう、という機運があり、今回のインターンで私が取り組むことになりました。また、DynalystではScalaを使用しているので、Scalaでストリーミング処理をするのに適したAkka Streamsを使用することになりました。
実装内容について説明する前に、今回重要な役割を果たすDynamoDB StreamsとAkka Streamsについて述べておきましょう。

DynamoDB Streams
DynamoDB Streamsでは各レコードはshardという単位に分配され、そのshardの中に順に詰められていきます。shardを跨いだレコードの順序を保証することは出来ませんが、shard内であればイベント情報の順序は保存されます。この分配にはDynamoDB Streamsに設定されたpartition keyという値を用いています。DynamoDB Streamsのpartition keyはDynamoDBのhash keyが使われるので、同じhash keyのレコードは同じshardに分配されるようになっています。つまり、同じhash keyに対する更新イベントの順序は保証できるということです。
shard内の各レコードをどこまで消費したかは、checkpointという値を、消費したレコードの位置まで進めることで表現します。レコードを処理する前にcheckpointを打てば at most once(欠損するかもしれないが重複しない)な処理を実現できますし、レコードを処理した後にcheckpointを打てば at least once(重複するかもしれないが欠損しない)な処理を実現できます。今回はmemcachedのキャッシュを確実に1回は消す、という処理を行いたいので、at least onceになるようにうまく実装する必要があります。
DynamoDB Streamsのレコードや、DynamoDB Streamsと同じくAWSでストリーミング処理を行えるKinesisのレコードをどのように消費するかは、開発者の手に委ねられています。ただ、AWSが公式で出しているKCL(Kinesis Client Library)を用いることで、どのshardをどのように管理するか、どうレコードを扱うか、といった複雑な処理を任せることができます。これはどうやっているかというと、KCLにDynamoDBのconfig情報を渡すことで、新しくshard管理用のDynamoDBのテーブルを勝手に作成して、そこにDynamoDB Streamsのshardの情報管理や死活監視をする、というようになっています。

Akka & Akka Streams
それでは、今回の主役と言っても良いであろうAkka Streamsについて述べていきます。そのためには、そもそもAkkaとは何者かということを説明しなければなりません。
AkkaとはActor modelを採用して並行処理を効率的に実装できるライブラリのことです。Actor modelでは、各処理単位はactorと呼ばれ、actor同士が並行してメッセージという単位をやり取りすることで、各actorが適切に処理出来る許容量を超えないようにしつつ、処理能力を最大限まで生かすことができます。
Akka StreamsはAkkaをベースとしたストリーミング処理ライブラリで、非常に大規模で一度にメモリに載せることが難しいデータや、次々とデータが発生してくるような状況で、データを効率的に処理してくれます。
Source(始点)、Flow、Sink(終点)と呼ばれる単位が存在し、SourceからFlowへ、Flowからまた別のFlowまたはSinkにつなげていくことで、宣言的に処理の流れを記述することができます。
Akka StreamsにはGraphDSLという記法が用意されており、Akka Streamsで定義した独自の演算子~>を用いることで、以下のように、処理を見た目に可愛く記述することができます。
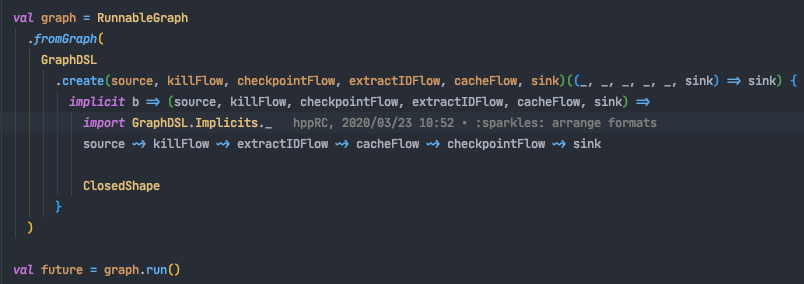
手続き的に処理を書くのではなく、Scalaの関数型言語らしさを生かして宣言的に、かつ見やすく記述できるのが非常に魅力的です。単純な1本のフローだけでなく、枝分かれの発生するようなフローでも記述することができ、柔軟さも兼ね備えています。
Akka StreamsでSourceとして扱えるデータは、イテレータを意識していただくと分かりやすいかと思います。すなわち、逐次的に処理するにしろ、一気に処理するにしろ、そのようなSequenceの一種として扱えるものをSourceに変換して、それぞれのデータに加工を加えるような形で処理を記述することが出来ます。

実装内容
長くなりましたが、実装内容を説明していきます。まず、Lambdaで逐次処理を行うのと、ストリーミング処理を行うのでは実装方針が異なるので、データの流れ方を大まかに説明します。この時注意するポイントが何点かありますが、それらに関しては後述します。
大まかには以下のようになります。
- DynamoDBのupdate eventが発生する
- DynamoDB Streamsにイベント情報のレコードが流れてくる
- ECS上のサーバがDynamoDB Streamsをポーリングし、流れてくるレコードを受け取る
- DynamoDB Streams Kinesis Adapterを噛ませてDynamoDB StreamsのレコードをKinesisのレコードとして扱えるようにする
- KCLにDynamoDBのconfigを渡して、shardをうまく管理してもらう
- kcl-akka-streamを使ってDynamoDB StreamsをSourceとして扱えるようにする
- Sourceから流れてくる各レコードの情報を元に、対応するmemcachedのキャッシュを消しに行くFlowを用意する
ザックリとこのような感じになります。この流れを図に表したのが、以下の図になります。
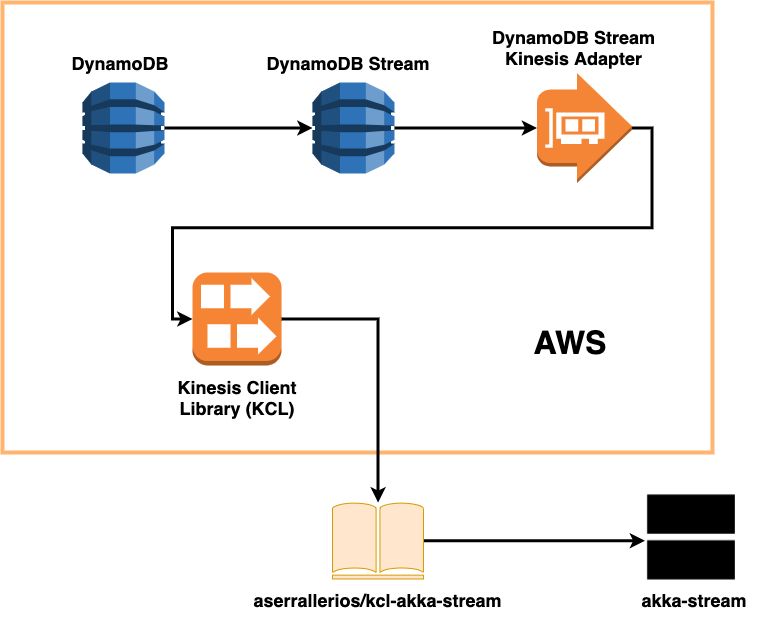
では、次に注意点について述べます。
まず1つ目は、DynamoDB Streamsのレコードを競合なく効率よく扱えるようにする工夫が必要な点です。Kinesisのレコードを扱う際は、先述の通りKCLというライブラリを用いると簡単なのですが、今回はレコードがDynamoDB Streamsのものなので、KCLでそのまま扱うことは出来ません。そこで、AWSが公式で出しているDynamoDB Streams Kinesis Adapterというライブラリを用いることで、DynamoDB Streams型のレコードに対してKinesisのレコード型のインターフェイスを実装し、KCLで扱うことが出来るようになります。
次に2つ目の点は、DynamoDB StreamsをAkka StreamsのSourceとして扱うために少々複雑な処理をする必要がある点です。これはaserrallerios/kcl-akka-streamというライブラリを用いれば、Kinesisのレコードを扱っている限りは簡潔に扱うことが出来ますが、今回はDynamoDB Streamsのレコードを扱うので、素直に実装することは出来ませんでした。具体的には、Kinesisのレコードには存在しているであろう値がDynamoDB Streamsのレコードには存在しておらず、その値に関する処理でNullPointerExceptionが発生してしまっていました(ぬるぽというやつですね)。
そこで、今回は手元にこのライブラリをcloneしてきて、エラーを吐いている部分にパッチを当てることで解決しました。本来はPullRequestを出せると良かったと思うんですが、最新バージョンのkcl-akka-streamが使用しているKCLのバージョンと、今回使用しているKCLのバージョンが不整合を起こしていたため、それをやろうとするとかなり大規模な改修を加えなくてはならず、苦肉の選択という感じでした。ここはもっとうまくやりたかったポイントの一つです。
以上の注意点に気を配りながら、Scalaでの実装を進めていきました。Dynalystではレイヤードアーキテクチャを意識したコード設計をしているので、既存コードを参考にさせて頂きつつ、ScalaTestでテストも書きつつ実装しました。

インターンについて
最後に、インターン全体について述べます。特に良かったな、と思ったポイントが何点かありますので、まずはそちらについて書いていきます。
環境が最高すぎた
働く上で最高の環境が整っていたと思います。チームの皆さんから、自分の実装に対する疑問やアーキテクチャに関する質問など、いつでも真摯に答えていただけました。メンターさんからは業務の合間を縫ってJavaのGCに関する解説をして頂いたり、Akkaを使う上で理解していたいActor Modelについての説明や、それに関連したJavaのThreadPoolExecutorとForkJoinPoolに関する詳しいお話などを伺うことも出来ました。
また、設備も大変よく、モニターの用意はもちろんのこと、メンターさんにHHKBを貸して頂いて、図らずもHappy Hackingデビューをすることが出来たり、オフィス内の図書館のような場所で面白そうな本を借りることも出来ました。

他チームの社員さんとのお昼ご飯会もたくさん用意して頂くことができ、自分の知らない技術や知識をもっている方とお話することが出来ました。毎週4回ほどランチの機会があり、メンターさんがとても積極的にセッティングをしてくださったので、非常によい刺激を受けることができ、とても感謝しています。
カフェのコーヒーもとても美味しかったですし、コーラが飲み放題でした(カップに注がれたドリンクが出てくる自販機が無料で使えます)。なんとマンスリーマンションも手配して頂いていたので、勤務後も快適でした。

社会情勢に対して柔軟
今回のインターンは実は予定より3営業日早く終了することとなりました。これは、新型コロナウィルスの感染拡大による社会情勢に合わせて全社でリモートワークが推奨されるようになったためでした。個人的にはもっと長く取り組みたい気持ちがあったので残念でしたが、slackやミーティングでリモート移行の連絡があった後、すぐにその体制を整えるために皆さんが柔軟に動かれていたのが印象的です。
普段からリモートでも仕事を出来る体制を整えており、また移行自体もスムーズで、有事にあるべきチームの姿勢を見ることが出来たのはとても良い経験になりました。

大変だったこと
自分はこのインターンに参加するまでScalaを書いた経験が無く、またWeb広告に関する知識も無かったため、最初は勉強することだらけでした。といっても、大変だから嫌になったということでは無く、メンターさんを始めとして、チームの皆さんにフォローして頂いたり、プロダクトに関連する様々なお話を伺えたりと、大変ありがたかったです。
また、今回は一つのタスクに取り組みましたが、他に用意して頂いているタスクもあり、そちらもやりたかったというのが正直な感想です。予想以上にAWSのドキュメントを漁ったり、プロダクトに耐えるコードを書くためのScalaの学習に時間を掛けてしまい、かなり悔しい思いをしました。(NDA的に)公には言えないような実装・実験のタスクもあり、そちらもとても楽しそうでしたので、機会があれば是非取り組んでみたいです。
それと、初週は貸して頂いているマンスリーマンションの換気口が全開で閉まらず、極寒でした。人事の方に迅速に業者の方の手配をして頂いたので、週明けには快適生活を手に入れることが出来き、大きな問題にはなりませんでした。

終わりに
本当に楽しく実装まで出来たので、インターン全体として非常に満足できる内容になりました。
自分は修士課程に進学予定なので、23卒に当たります。これは面接の段階から人事の方にも伝えていましたが、内心受け入れてもらえるのかとても不安でした。そんな自分の予想に反して、非常に暖かく迎えていただき、複雑な社会情勢の中、最後まで丁寧な対応をしていただきました。本当にありがとうございました。
また力をつけて戻ってきたい、と心の底から思える経験になりました。本稿を読んで頂いた皆さんも、ぜひ応募してみてください。
