
こんにちは。秋葉原ラボの高野(@mtknnktm)と申します。 今回は秋葉原ラボ 2016年研究発表についてご紹介いたします。
本記事はCyberAgent Developers Advent Calendar 2016 – Adventarの14日目です。13日目はk_enokiさんの「Slackに突然の死っぽいアレを投稿するスペシャルなコマンドをSlash CommandとLambdaを使って作った話」でした。
秋葉原ラボでは分散システム・検索・機械学習・データマイニングなどを扱う研究開発組織です。サイバー エージェントが運営する「Ameba」を始めとした多数のサービスデータを利活用するために大規模データ処理を基盤Patriotを構築・開発・運用し、検索・機械学習・データマイニングの技術を活用して利便性向上、サービスの健全化、サービスの改善をしています。
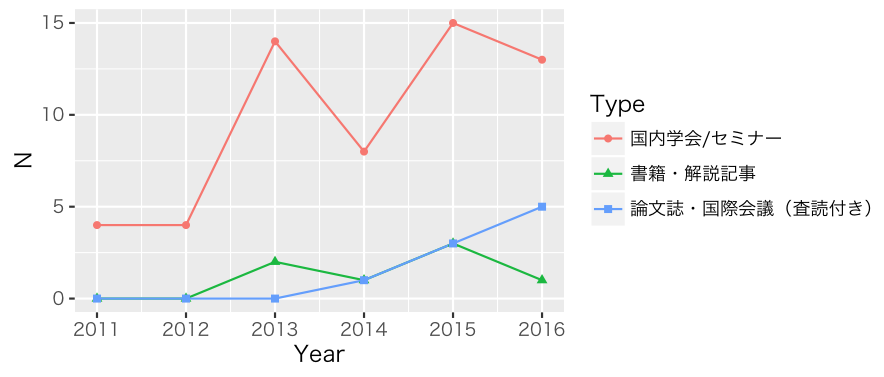
同時に秋葉原ラボでは、それらをより良くするために研究開発もしており、下図の通り成果発表も徐々に増えてきました(秋葉原ラボの発表一覧から作図)。本記事では2016年に秋葉原ラボのメンバーが行った研究発表についてご紹介いたします。
大規模データ処理
Apache Ignite
高性能分散インメモリープラットフォーム Apache Ignite についてのコミッターのShtykhが講演いたしました。本講演では、Flume、Kafkaとインテグレーションを紹介し、Igniteをデータ処理ハブにした高信頼性・高スケーラビリティ・低オペレーションコストデータ処理パイプライン構築について説明しました。またAmebaで構築した事例や今後のIgniteを用いた分散インメモリーコンピューティングの可能な活用を解説しました。
- 関連資料
データ処理のワークフロー管理
- T. Zenmyo, S. Iijima, and I. Fukuda, “Managing a Complicated Workflow based on Dataflow-based Workflow Scheduler”, 2016 IEEE International Conference on Big Data (IEEE BigData 2016), short paper, 2016.
Amebaは多種多様なサービスを持つため多様な要件に対応できる基盤が必要です。多様な要件に対応する複雑なワークフローを実現するために、Hadoop/Hiveをベースとしたデータ分析プラットフォーム「Patriot」を構築し運用しています。Patriotのワークフロースケジューラは巨大な依存関係を管理し、保守性を維持しながら効率的な計算資源利用を可能にします。この論文ではワークフロースケジューラの設計について述べ、それをどのように運用しているかについて解説しています。
汎用的なKey-Valueストアクライアント
Key-Valueストア(KVS)を用いたアプリケーション開発をシンプルにするクライアントライブラリの提案です。KVSへのアクセスには煩雑な作業が存在し、アプリケーション開発においては実装や保守が課題です。提案するクライアントライブラリはアプリケーションデータと Key-Value の間の変換を自動化することで,様々なスキーマの Key-Valueに SQL ライクな言語でアクセスすることを可能にします。これにより,KVS に関する知識がない開発者でも KVS を用いたアプリケーション開発することを可能にします。
機械学習システム
スパムブログ対策
- 數見拓朗, 角田孝昭, “アメーバブログにおけるスプログの特徴と検知手法の検証”, 人工知能学会 合同研究会 第10回 データ指向構成マイニングとシミュレーション研究会(SIG-DOCMAS2016), 2016.
ブログサイトには悪意のあるユーザによってスパムブログ(スプログ)が大量に投稿されることが有ります。それらはユーザの満足度を下げるとともにSEO順位の低下などの問題があり対策が必要です。本発表では、それらの対策のためにスプログとスパムユーザの特徴を分析し、投稿内容に含まれる名詞、投稿回数、更新回数がスプログやスパムユーザの判定に有効であることを示しました。
レコメンド
- 内藤遥, “A.J.A Recommend Engine におけるテキスト類似度を用いたレコメンドエンジンについて”, 第9回 Webとデータベースに関するフォーラム(WebDB Forum 2016)ポスターセッション, 2016.
Amebaではユーザーの興味関心や行動、記事の特徴などを自動で解析し、関連したコンテンツを表示することで、ユーザーのコンテンツ間の回遊性を高め、メディアの継続的な成⻑を促進するためのシステムを開発・運用しています。それを A.J.A Recommend Engine と呼んでいます。本発表では A.J.A Recommend Engineの中核技術となっているテキスト類似度を基にしたレコメンドエンジンにおいて、大規模データを扱いリアルタイムで処理する仕組みについて紹介しています。
データ分析
ユーザ行動理解のためのデータマイニング
- H. Kawazu, F. Toriumi, M. Takano, K. Wada, and I. Fukuda, “Analytical method of web user behavior using Hidden Markov Model”, Workshop Application of Big Data for Computational Social Science (workshop at IEEE BigData2016), 2016.
- 河津裕貴, 鳥海不二夫, 高野雅典, 和田計也, 福田一郎,
“潜在状態ネットワークに基づくソーシャルゲームユーザの行動抽出”, 第30回人工知能学会全国大会, 4D4-2, 2016. - 河津裕貴, 鳥海不二夫, 高野雅典, 和田計也, 福田一郎,
“隠れマルコフモデルを用いたソーシャルゲームユーザの分類”, 第35回ゲーム情報学研究会, 2016.
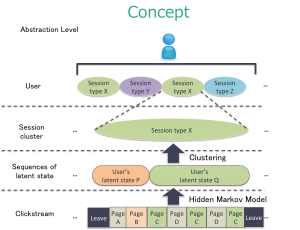
東京大学 大学院工学研究科の鳥海研究室との共同研究です。Amebaで運営しているサービス(AbemaTV、AWA、アメーバピグ、アメーバブログ、ソーシャルゲーム)には多様な使用スタイルが存在し、そのすべてを把握し評価することは困難です。本研究では、その多様な既知・未知の使用スタイルを発見し評価することを目的としたデータマイニング手法を開発しています。本発表ではソーシャルゲームのデータを題材として、そのプレイスタイルの発見・分類をしています。下図のようにユーザのスタイルは階層性があると考えられます。本研究では最下層の個々の行動(clickstream)から、短時間の行動傾向(session cluster)を分類する手法を提案しています。このように段階的に分類していくことで解釈のしやすいモデルを目指しています。
ユーザのアクティブ度定量化
- 和田計也, 福田一郎, “インターネットテレビにおけるユーザの視聴行動分析―継続・離脱分析とユーザアクティブ度の定量化―”, マーケティングカンファレンス2016, Vol. 5, pp. 61-65, 2016.
- 和田計也, “AbemaTVでのデータ分析事例”, 第9回 Webとデータベースに関するフォーラム(WebDB Forum 2016), 2016.
サービスを改善する上でユーザの行動を分析し、継続・離脱の傾向について知ることは重要です。本研究ではAbema TVを対象としてユーザ行動のモデル化し、ユーザの継続しやすさを示す「アクティブ度」を定義し、定量化しました。また、アクティブ度に影響するユーザ行動(視聴時間、視聴チャンネル、予約など)を分析しました。これによってユーザのアクティブ度を測るとともに、それを向上させる行動傾向を知ることができました。
音楽データマイニング
音楽を自動生成のための研究です。本研究では柔軟な自動生成モデルを構築するために、音楽の部分構造を抽出することを目的としています。本稿では部分構造情報も持っていない MIDI データから2種類のクラスタリング手法を用いて音楽部分構造を抽出する手法を提案しました。加えて、得られた部分構造情報をリカレントニューラルネットワークによって学習させ楽曲生成モデルを構築する点について実験・議論しています。
経済データマイニング
人々の心理や世の中の雰囲気のことを「センチメント」と呼びます。Twitterとアメリカの金融市場との関係を実証したBollen, et al. (2011) でも言及されているように、センチメントは、金融経済に影響を与える重要な要素になっています。本研究では、日本経済新聞から人々の心理を表す「センチメント・インデックス」を抽出し、過去29年間という非常に長い期間で、センチメント・インデックスと日本の株式市場と関係について調査しています。本研究では、作成したセンチメント・インデックスが日本の金融市場を予測し得ることと、内閣府が公表している景気循環と対応付けて解釈することが可能であるという結果を得ています。
データ分析環境
Rによるデータ分析を効率的に実施するための環境 RStudioについて「特集1 データ分析実践入門 第2章 RStudioでらくらくデータ分析」で和田が解説しています。効率的に利用するための各種設定から、データ分析の再現性を保ったレポート作成機能(RMarkdown)について述べています。この改訂2版では最新のRStudioに対応するための修正もされています。
協調行動のソシャゲデータを使った実証研究
- M. Takano, K. Wada, and I. Fukuda, “Lightweight Interactions for Reciprocal Cooperation in a Social Network Game”, The 8th International Conference on Social Informatics (SocInfo), 2016 (acceptance rate: 36/120).
- M. Takano, K. Wada, and I. Fukuda, “Reciprocal Altruism-based Cooperation in a Social Network Game”, New Generation Computing, 34, pp. 257-271, 2016.
- 高野雅典, “ソーシャルゲームのユーザ行動データを使った協調行動研究: 互恵関係構築におけるライトなコミュニケーションの効果分析”, 社会情報学会 学会大会 若手プレカンファレンス「ゲームとしての社会/社会としてのゲーム」, 2016.
- M. Murase, M. Takano, R. Suzuki, and T. Arita, “A statistical analysis of play data in a social network game: Effects of communication on cooperative behavior”, 31st International Congress of Psychology (ICP2016), Poster Presentation in Japanese, RC-05-2, 2016.
- 高野雅典, “ソーシャル系Webサービスのデータを用いた社会科学”, 成城大学 経営情報論 特別授業, 2016/07.
相互の協調はヒトをはじめとして多くの動物に見られる現象であり、社会を形成する上で重要な要素です。ヒトやその他の動物の協調行動を説明するために非常に多くの理論的・実験的研究が為されてきました。そのため、安定した相互の協調状態を実現するにはどういった仕組みが必要か? それを促進するような環境はなにか? といった知見が多く存在します。本研究では現実に近い環境(ソーシャルゲーム)のヒトの行動から協調行動を研究しています。それによって、(理論・実験研究の)理想化された環境で得られた知見が、でも成立するか? について検証すること、理想化環境では考慮されていない重要な要因を発見することを目的としています。上記の研究では互恵的利他主義について検証し、さらに社会的グルーミングと呼ばれる他愛もないコミュニケーションが重要であることを発見しました。このような協調行動研究は、協調の進化的起源解明という理学的な意義があるとともに、ヒトの協調行動の促進という面で社会的にも重要であると考えています。
社会的グルーミングと社会構造
- M. Takano and I. Fukuda, “The critical effect of social grooming costs on structures of social relationships”, under review.
- 高野雅典, 一ノ瀬元喜, “社会関係の強さに基づく社会的グルーミング戦略の適応性”, 第13回ネットワーク生態学シンポジウム, 3, 2016.
- 高野雅典, “ソーシャルなビッグデータによるヒトの社会性と社会構造の分析”, 第57回 GRL浜松セミナー, 静岡大学, 2016.
ヒトの維持可能な社会関係の数には限度があり、その社会関係の強さには大きな偏りがあります(ベキ則を示す)。その偏りはヒトが社会関係の構築維持する相手を選別していることを示唆します。すなわち限られた時間や認知能力の制約の上で有利な社会関係を構築維持する戦略を進化的に獲得してきたと考えられます。我々は、ヒトはどのような戦略で社会関係の構築維持をし、それが社会構造にどのような影響を与えているか? その戦略はどのように進化的に獲得されたか? について知るために次の2つのアプローチを取っています。1) ヒトの時間的なコスト分配戦略についてSNSなどのビッグデータ分析。2) その戦略の進化的適応性を進化ゲームに基づくシミュレーション。その結果、社会関係構築維持行為(社会的グルーミング)のコストは社会関係の強さと共に増加すること、その増加度合いが社会関係の構造を決めることをデータ分析により示しました。また、偏った社会関係構造を生み出す戦略は社会集団のサイズと環境の豊かさに依存して進化しうることを進化シミュレーションによって示しました。
まとめ
いかがでしたでしょうか?上記のように秋葉原ラボでは、現場で利用するための応用研究から基礎的な研究まで幅広く研究しています。今後も業務とともに研究開発も進め、インパクトの高い研究を目指していきたいと考えています。