
こんにちはAI事業本部クリエイティブディビジョン、MLエンジニアをしている小林(@Cat_to_Love)です。 2020年6月からの極予測AIでの内定者アルバイトを経て、現在2021/04に新卒入社、現在も極予測AIの開発に携わっています。ML/DSの業務は勿論、最近はパブリッククラウド周りの勉強もしています。
本投稿ではDSPを構築する7日間の研修において推論モデルのバージョニングやメタデータ(特徴量)の管理からA/Bテスト基盤の構築、追加データの自動学習基盤までを構築するにあたって選定した技術、その中でも比較的新しいGCPの機能であるEventarcについて検証した結果についてGCPでのアーキテクチャとメタデータなどの管理法とともに共有します。
研修の要件
基本的には同じ研修を受けた同期の小売DX AirTrack 久米の以下の記事がDSPの概念などもわかりやすく解説してくれているので、そちらも是非ご参考ください。
AI事業本部の新卒研修で爆速の広告システム(DSP)を作った | CyberAgent Developers Blog
軽く説明をしますと2000rpsのSSPリクエストに対して100msあたりでCTR予測をレスポンスとして返す簡易的なDSPを構築する研修です, ざっくりとして要件を並べると
- マスト要件
- Bidレスポンスを返すDSPの実装
- 広告選択ロジックの実装
- 選択用データの為のdbサービスの選定・テーブルの設計
- CTR予測モデルの構築・実装(A/B用に2つ作成)
- オプション要件
- データ追加された際に自動でモデルを更新するバッチの作成
- CI/CDの導入
この様な形です、今回はML/DSエンジニアとサーバーサイドエンジニアの二人でのチームでの開発ですが今回ML/DSエンジニア二人(AI Creative 小林・小売DX 音賀)のチームで開発を行いました。システムの概説をしながら以下の点について今回特に触れたいと思います。
- 学習時の特徴量(メタデータ)の管理
- データ追加時の自動学習バッチの作成でのEventarcの採用・検証
今回の設計
ここは本題というより前提の話になりますので概観だけする事とします。
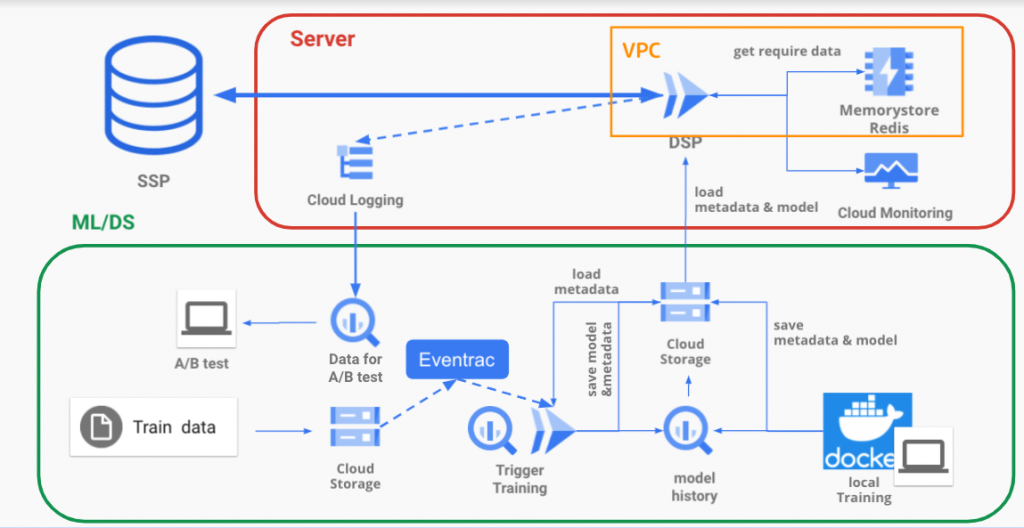
基本的にはコンテナ化を徹底して依存関係の不具合を排除する方針です。
- Cloud runにてDSPを走らせる(モデル自体はDSPに組み込まれています)
→Auto Scalingが間に合わないので負荷テストを行いインスタンス数を設定, ここはGKEでも良かったかも知れません - Cloud Loggingをシンクして予測ログをA/Bテスト様にBQに保有
- Dataに関してはKVSのRedis(DWHのBQからキャッシュ)
- CI/CDはGithubとCloud buildの連携にて行う
ML/DSの部分に関しては次の章にて詳説します。
学習時の特徴量の管理
今回DSPにモデルを載せるに当たり、ある程度軽量なモデルなLogistic Reggression(以下LR)を載せることになりました。LRに限った話ではありませんが使用する特徴量の管理、特にmultihot・onehot encodingの様に値が使う学習データによって変わる物などの管理が肝要になると考え設計しました。それに加え以下の点に留意しました。
- ローカルの学習時のメタデータをモデルの一致を保証
- 学習データの追加時の学習の際にも同じ様に保証
先ほど概説したインフラアークテクチャとともに見ていきます。
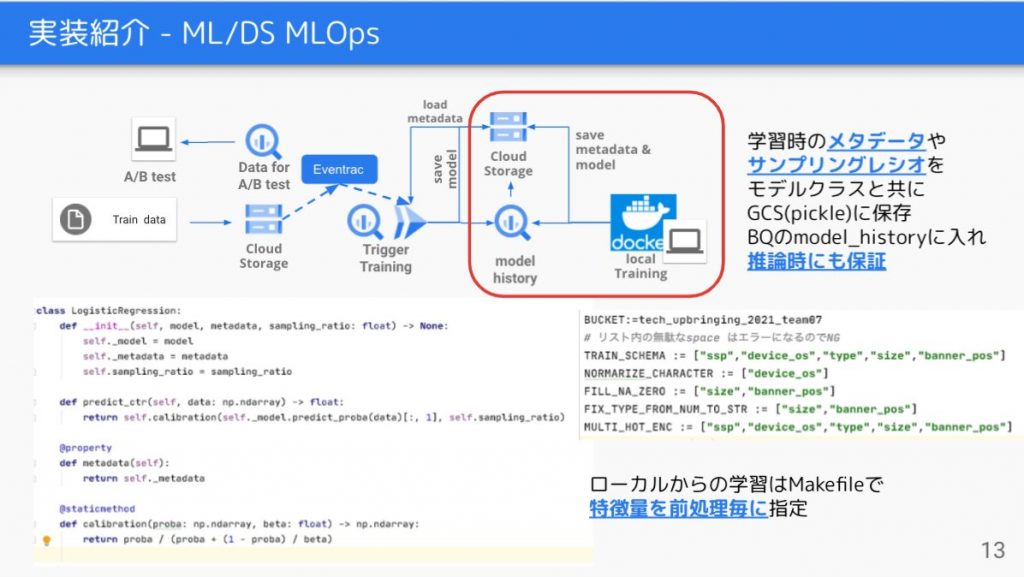
基本的にはdocker化したものを走らせて学習を走らせます、わざわざコンテナ化を行う理由として
- GCSへのデータの追加をTriggerにCloud runを起動して学習させる為(Eventarc)
- Docker内での環境変数で使用する特徴量を前処理毎に指定する(Makeコマンドで注入する図右下)
という物があります。またローカルの学習環境とバッチの学習環境を一致させられるという点もあります。
ここで最終的に学習する際に学習済みのモデルと共にインスタンスオブジェクト(図左下のコード)としてGCSに以下の情報を保存します。
- 使用した特徴量(multihotのuniqueな値を含む)のカラム名
- DownSamplingを行った際のサンプリングレシオ
imbalanceなデータ(click予測においてclickされたレコードがとても少ない)を補正した際のサンプリングの比率、CTR予測値の補正(Calibaration)の際に用います。
これらの情報をモデルとセットでGCSに保存しBigqueryにバージョンとGCSのパスなどをmodel_historyテーブルの様なものを作りInsertしておくことでモデルのバージョンと対応したmetadata・サンプリングレシオを保証します。
これに合わせて前処理もセットで保存しておく事も考えられます。これはGCP AI platformのカスタム予測ルーチンの思想とも似ているかと思います。
AI platoform Trainingを用いると実験のバージョニングやHPO(Hyper Parameter Optimization)もマネージドにできる為これを活用するのも良いかと思います。今回はLRを学習させる際にはAI Platfoform Trainingを用いる程の規模ではなかったのでCloud runを採用しています。
この学習コードはDocker化されている為、GCSにデータが追加された際にCloud runをトリガーできるEventarcにて検知しこの学習を走らせる事ができます。これにより新しく追加されたデータを用いてモデルをバッチ学習した際にも、そのデータでのmultihotのuniqueな値とサンプリングレシオを保存しモデルと紐付け、バージョニングと共に保存をし、推論時にも同じメタデータとサンプリングレシオによるCalibrationを保証することができます。
次にその学習用のCloud runをトリガーするEventarcを採用・検証した話に移りたいと思います。
データ追加時の自動学習バッチの作成でのEventarcの採用・検証
追加データの概要とEventarcの採用理由
今回研修のオプション設定として追加の学習データが指定されたGCSに追加される想定で、GCSにデータが追加されたら自動的に学習バッチが走るという機構を構築します。
データの追加としては以下の様な形です。
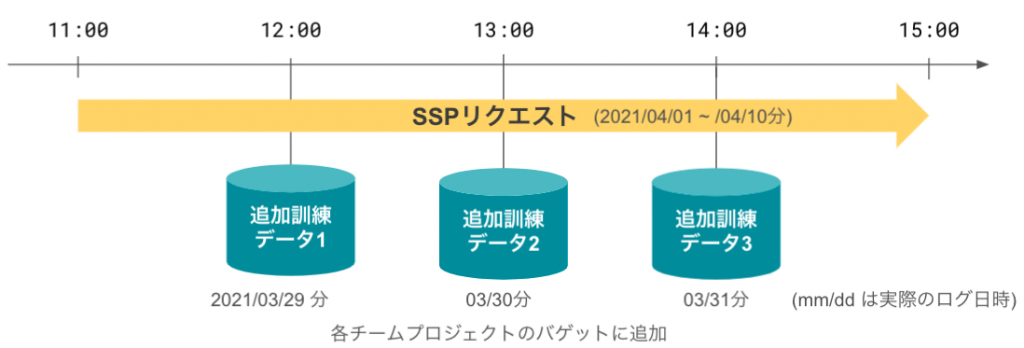
これに関しては単純にCloud functionによって学習をトリガーするという手段でも良かったのですが以下の理由からEventarcによるCloud runのトリガーを採用する事としました。
- 学習環境のContainer化の徹底
- Cloud functionにおけるリソースの制限(メモリ・実行時間など)
→Cloud runの方がリソースには余裕はある - 単純に比較的新しい機能なので検証してみたかった
Eventarcの概要
Eventarcは昨年10月にPreview機能として公開されています。 Eventarcは2021/05/31現在GA(General Available一般利用可能)はまだですので対応リージョンなど機能に一部制限があります。
Eventarcの機能としてCloud runをトリガーできるという物ですがそのイベントソースとして
- Pub/Sub トピック
- GCPサービスの監査ログ
ここではGCPサービスの監査ログという所が今回使用した物ですがEventarcの強みとしてもこの部分が大きいかなと個人的に感じています。
どういう事かと言うとGCPサービスの監査ログをトリガーにできると言うことはPub/Subなどの制約を受ける事なく監査ログが取れるGCPサービス(60以上)であれば監査ログレベルでトリガーできると言う事です。
GCSをイベントソースとしてトリガーする
基本的にGCSの監査ログをIAMから設定をする事で学習用のCloud Runをトリガーする事になります。ここで監査ログを設定できるサービスは基本的に利用可能な様です(87サービス)。ここでGCSのデータ書き込みの監査ログを有効化します。

詳細な方法は公式のドキュメントやチュートリアルに譲りますが(compute engineに適切な権限を与える等)軽くEventarcのトリガー設定に触れておくと
- Cloud SDKコマンド
gcloud eventarc triggers create trigger-${SERVICE_NAME} \\
--destination-run-service=${SERVICE_NAME} \\
--destination-run-region=${REGION} \\
--event-filters="type=google.cloud.audit.log.v1.written" \\
--event-filters="serviceName=storage.googleapis.com" \\
--event-filters="methodName=storage.objects.create" \\
--service-account=${PROJECT_NUMBER}-compute@developer.gserviceaccount.com
SERVICE_NAMEにてトリガーしたいCloud runにイベントソースを—event-filtersで紐つけます, 今回は
- サービス:GCS
- 監査ログの種別:書き込み
- method:GCSオブジェクト作成
と言うイベントソースをトリガーとしています。—event-filtersは他にもresourceName=${TARGET_OBJECT_PATH}などの様に指定のbucketやobjectを指定する事もできる様です。より細かい設定はCloud SDKドキュメントに譲ります。
- Cloud runのconsoleから Cloud runサービスの作成時にもトリガーを設定する事もできます。 (上から順に監査ログのタイプ・GCSのリソース指定・トリガーの際の呼び出しパス設定)
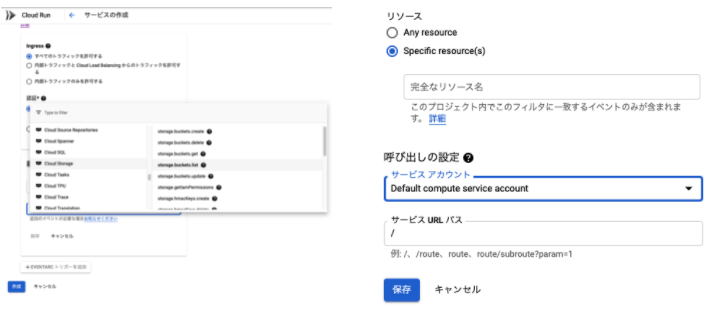
既存のCloud runにトリガーを設定する事もできます。
Eventarcの現状
今回Eventを用いてデータ追加時のバッチ学習の行いましたがEventarcの現状と所感について述べたいと思います。
まず現状ですが先述した様にEventarcはプレビュー版のため制限があります。 例えば今回の例でいくと—event-filterにて特定のリソース(バケットの任意のcsvや任意の拡張子)の様な形で正規表現やワイルドカードで柔軟に指定することは出来ない様でした。(今後GAに向けて正規表現やワイルドカードは対応予定)
つまり現状リソース指定する際には
- 特定のバケット内全てのオブジェクト作成
—event-filter="resouceName=gs://.../${BUCKET_NAME}/" - 特定のオブジェクト作成
—event-filter="resouceName=gs://.../${BUCKET_NAME}/train1.csv"
と言う形で指定する形となります。
今回は特定バケットに追加される学習データ全てを対象とするため1. の方を選択します。1. を選択する場合で同じバケット内に学習データ以外のデータが作成される場合はCloud runのサービス側で受け取ったイベントのファイル名やディレクトリ名をバリデーションする必要があります。
今回自分はgs://.../${BUCKET_NAME}/eventarc/*.csv の様にしてeventarc以外のディレクトリのものは400エラーで返すと言う形にしました。(コード参照)
@app.route('/', methods=['POST'])
def handle_post():
# app.logger.info(pretty_print_POST(request))
Ce = request.headers["Ce-Subject"]
# object = ""
object = request.headers["Ce-Subject"].split("objects/")[1]
target_dir = object.split("/")[0]
app.logger.info(f"Ce: {Ce},{object}")
if target_dir != "eventarc":
abort(400, "Event must be in /eventarc.")
上記はrequestのヘッダーから無理やり取ってきていますが
from cloudevents.http import from_http
...
@app.route('/', methods=['POST'])
def handle_post():
# Read CloudEvent from the request
cloud_event = from_http(request.headers, request.get_data())
# Parse the event body
bucket, name = read_event_data(cloud_event)
def read_event_data(cloud_event):
# Assume custom event by default
event_data = cloud_event.data
type = cloud_event['type']
# Handling new and old AuditLog types, just in case
if type == 'google.cloud.audit.log.v1.written' or type == 'com.google.cloud.auditlog.event':
protoPayload = event_data['protoPayload']
resourceName = protoPayload['resourceName']
tokens = resourceName.split('/')
return tokens[3], tokens[5]
return event_data["bucket"], event_data["name"]
といったfrom_httpメソッドからとる事を想定している様です。(GCPのサンプルコードより) ここで最終的に同じバケット内にモデル等の保存先を指定してしまうと無駄に一回リクエストがイベントトリガーとして飛んでしまうので注意してください。(バリデーションを入れないとループが回ってしまう可能性もあります)
現状はeventarc用のバケットとモデル等の保存用のバケットを分けておくのが良いかと思います。
所感
今回Eventarcを用いた所感を二つの視点でまとめてみます。
- イベント駆動のシステムを統合する機能としてのEventarc
- 監査ログでトリガーできるためかなり多くのサービスの連携に使えそう
- 監査ログレベルの制御のためリソースの細かい管理にも手が届きそう
- 長期的にはThird Party(Datadogなど)・カスタムイベントでもトリガーできるためモニタリングとの連携なども可能か?
と言ったようにイベント駆動のシステムを組む際の良い手段となりそうだと感じました。
- 追加データをイベントソースとした学習バッチのトリガーとしてのEventarc
- コンテナベースのCloud runをトリガーできるのは良い
- Bigqueryの書き込みでもトリガーできるのが良さそう
- 単純に学習バッチのフローを構築するのであればワークフローエンジン使った方が良さそう
- 単純にGCSの追加をトリガーに学習パイプラインを回すのであれば以下の方法の方が良さそう(Kubeflowも使えそうなので)
リモートやイベントでトリガーされる AI Platform Pipelines の使用 | Google Cloud Blog - DWHやメタデータの管理も含めて考えるのであれば以下の新機能(2021/5/26リリース)も注目か?
Google Cloud Dataplex unifies distributed data | Google Cloud BlogDataplex is built for distributed data. We are starting with data stored in Google Cloud Storage and BigQuery, with support for other data sources coming soon. It provides a workflow-driven experience helping you build an open data platform
と言った感じです。勿論ここまでのカスタマイズ性とGCPサービス間の細かい連携が可能であれば学習フローを自前でCloud runにて組む事が出来そうですが想定された使用方法ではないようにも思えます。
何より学習フローを単純に組むのであればEventarcはリッチ過ぎて大規模なイベント駆動のサービス、それこそCloud runでマイクロサービス化された大規模なシステムに向けている機能な気がしなくもないなとも思いました。(確かドキュメントにもそれらしいことが書いてありました)
研修を終えて
最後に今回の研修を終えて感じた事を述べて締めたいと思います。 今回DSPを組むと言う事でML/DSとしてインフラ構成やメタデータの管理など学習のフローとデプロイがスムーズに行えるように構成を考えました。
やはりインフラの技術選定は難しく提供されている機能の想定されている使い方を理解して導入する事が肝要だと感じています。
また今回は学習自動化の所とメタデータとモデルの一致の学習時と推論時での保証に重きを置いていましたがCloud runを用いてサービングしていたためモデルのホットデプロイなどの機構も考えてみようかとも思います。
更には今回ML/DSの二人でDSPサーバーを構築すると言うハードな研修でしたがサーバーサイドの実装とA/Bテストなどの実施を行ってくれた研修で同チームであった音賀氏に感謝申し上げたいと思います。実際にDSPサーバーはほとんど(1999.445/2000qps)のSSPリクエストを捌けていました。
今後もMLOpsやインフラ・モデリングを含めたエンジニアリングを勉強して参りますので何卒宜しくお願いいたします。
宣伝
CA BASE NEXT 登壇アーカイブ動画
先日弊社の社外技術カンファレンスにおいて「GCPで始めるMLシステム組み込み学習支援」とう題目で登壇しましたのでご興味のある方は是非アーカイブからご覧ください。他にも様々な登壇がありますので是非弊社Developersチャンネル登録とともに宜しくお願いいたします!
GCPで始めるMLシステム組み込み学習支援 | CA BASE NEXT
We are hiring!
弊社は一緒に働く方を積極採用中ですので是非インターン等も合わせてご検討ください!
新卒採用
キャリア採用