
はじめに
はじめまして、AI事業本部小売セクターAirTrack所属の清水です。2020年4月にサイバーエージェントに入社しMLエンジニア/データサイエンティストとして働いています。
AirTrackは広告配信事業を営んでいるのですが、今回はAirTrackのプロダクト内で使われている機械学習モデルにまつわるABテストの実行フローの導入事例をそれらがビジネスへどうインパクトを与えるのかを交えて紹介させていただきます。はじめに、インターネット広告業界の中でAirTrackがどのようなプロダクトであるか、そして、広告枠の取引(RTB)の中で機械学習がどのように使われるかを説明します。その後、機械学習モデルのABテストフローでの具体的な導入事例についてご紹介します。
章立ては以下のような構成になっています。
- はじめに
- インターネット広告配信の仕組みと機械学習モデルによる事業改善
- ABテスト実行フローの導入事例
- おわりに
インターネット広告配信の仕組みと機械学習モデルによる事業改善
AirTrackの立ち位置
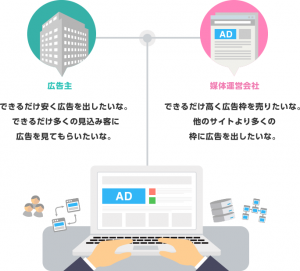
インターネット広告の中でのRTBという広告枠オークションの仕組みがあります。説明はこちらに任せたいと思います。 (https://cyberagent.ai/blog/pr/3601/)
RTBの中において、AirTrackはDSPという立ち位置にいます。AirTrackはオフラインの実店舗への来店を最大化することを目的としたプロダクトです。ユーザに広告配信後に広告接触ユーザが来店したかどうかを計測が出来るのが特徴になります。
機械学習を入札ロジックに適用する
RTBにおいて入札価格を決めるのに(以下、入札ロジック)、適切な価格で入札する必然性があります。より適切な価格で入札するため、入札ロジックの中に「広告がクリックされる確率(CTR) 」や「広告接触後に広告主の実店舗に来訪する確率(CVR)」などが含まれています。このCTRやCVRを正確に予測次第でプロダクトの利益を左右するため、データサイエンティストの主なタスクとして入札ロジックで使われる機械学習による予測モデルの改善や、入札ロジック自体の改善などが挙げられます。
事業改善を推進する仕組みづくり
事業改善について最も大きな要点の一つに、施策のリスクの最小化とリターンの最大化が挙げられます。新たに施策をする上で、施策のリスク(時間的資源や影響範囲)を最小化、施策のリターン(事業成長、施策から得る学び)を最大化する仕組みや、それらをサポートする仕組みづくりが重要になります。
これらの仕組みづくりを見落としていると具体的には、施策実行までに時間がかかってしまうことにより事業成長機会を損なう。施策の評価が健全ではない。施策を実行したのに意思決定に繋がらない。施策にビジネス的損失が伴う場合、ロジックを復元するための資源投下の必要性。など様々な問題が生じます。これらの問題を解消することで、仮説検証のサイクルを継続的に推進することが可能になります。(これらは大きく、ABテスト基盤、ABテストの実行フロー、効果検証などのキーワードで記述できると思います。)
本章を踏まえ、今回はABテストの実行フローについて次章で説明します。
ABテスト実行フローの導入事例
新たな施策をリリースして評価する際、効果測定の品質を担保するためABテストを採用しています。私たちのプロダクトにおいては、ここでいう施策という言葉は、機械学習モデルの置き換えや入札ロジックの変更にあたることが多いです。前章で説明した施策のリスク・リターンをコントロールするという旨の元、施策のABテストの実行フローを紹介します。
SQR ramping framework
新たな施策の実験する際、 はじめに小さいramp(=実験対象の割合)から初め、ramp up(実験対象割合の拡大)のプロセスを経ることで、リスクをコントロールしながら施策を評価し意思決定に繋げることが一般的に知られています。最短で実験の結論を得るためにははじめから50%適用でABテストを行うのが最適だといえます。しかし、サンプルサイズが大きいと施策の影響も大きくなりビジネスリスクも最大化してしまいます。逆に、サンプルサイズを小さくしてから徐々に大きくするとビジネスリスクは最小化できますが、全面適用までの時間的・人的リソースを不要に消耗してしまいます。このような理由で、適用範囲を適切に拡大していくことを迫られますが、ランプ率や実験期間を実験者が各々意思決定することは実験者によって判断基準が異なるため、誰がどんな実験をおこなっても共通の判断基準に従う必要があると言えます。
そこで SQR ramping framework ([Xu et at. 2018], https://arxiv.org/pdf/1801.08532) では、実験の推奨する ramping の提案と、自動的にramp upを行うアルゴリズムの紹介をしています。SQRとは、Speed, Quality, Risk を指し、それらをバランスさせることで施策のリスク・リターンを最適化することが狙いになります。具体的には、実験の適用範囲をどのように拡大するかにフォーカスした内容になります。
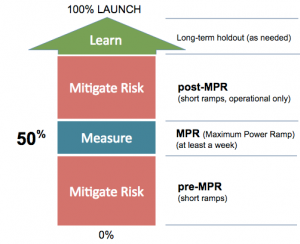
SQR framework では、4つの原則にのっとり、rampingのフローを定めています。(上図)
- preMPR: Ramp quickly to the Maximum Power Ramp (MPR), as soon as the risk is determined small.
- SpeedとRiskのトレードオフが要点になります。ここでは、Quolity(意思決定の質)は考慮していないため、施策の統計的有意な結果を得ようとせずリスクを許容範囲であれば素早くMPRに移行することを推奨しています。
- MPR: Spend enough “waiting” time at MPR.
- SpeedとQuality(意思決定の質)のトレードオフを念頭に置いています。介入群・対照群での統計的検定の結果から質の高い意思決定を行うことが目的となります。実験期間はできる限り短くしたいところですが、一週間以上設けることが推奨されています。実験期間を長くすることは、ヘビーユーザの偏りを無くし真のユーザ分布に近づくことで効果検証の品質(Quolity)向上を目指します。
- post-MPR: Conduct quick post-MPR ramps if there are operational concerns.
- リスク低減のフェーズとして、トラフィック増加によるインフラへの負荷の懸念を取り除くフェーズです。施策によっては任意の実施フェーズになります。
- Long-term holdout: Conduct optional long-term holdout ramps only if the learning objectives are clear.
- 施策がユーザに見つかりづらい機能である時に長期的な変化を追いたい場合や、大きな機能変更によってビジネス指標をケアしないといけない場合など、実施目的が明確な場合のみ行うフェーズになります。
ABテストフローを簡易的にプロダクト導入
SQR frameworkは、Ramp Recommender algorithm という自動的に ramp upする手法を提案していますが、私たちのプロダクトでは、一先ず、上述の原則にのっとりSQR framework を手動運用で簡易的に導入しました(ABテスト基盤に ramp upを自動化する仕組みがなく、ramp up 可否を自動化するモチベーションがないため)。ABテストの実行ランプをそれぞれ以下のような目的に、具体的なフローとしては以下の図ように拡大可否を設定しています。
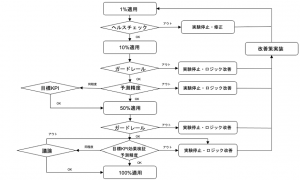
- pre-MPR(1%, 1日): 新しい機械学習モデルの動作確認によるリスクチェック
- pre-MPR(10%, ~7日): Protecting Guardrail metricsによるリスクチェックと機械学習モデルのオンライン精度の担保
- MPR(50%, 7日~): 効果検証の品質の担保
※ ()は(ramp率, 実験期間)を指しています。
それぞれについて説明すると、
1%では機械学習モデルを変更した場合がそのロジックが適用されているかどうかのみを確認しておりヘルスチェックという意味でリスク低減を達成するフェーズです。
10%ではProtecting Guardrail Metricsを複数のビジネス指標から選択しており実験中に顕著な改悪を示したら実験を中断することでリスク低減を行っています。論文中ではリスク関数を導入し、仮説検定によってramp up するかどうかを決定してしていますが、手動運用のためランプ終了後にメトリクスの集計を行います。そこではビジネス指標と機械学習モデルのオンライン精度を主に拡大可否を決定しています。
50%では上述の推奨にもあるとおり最低でも1週間実験しています。OEC(Overall Evaluation Criteria)の効果検証を行い、全面適用するかどうかの意思決定を健全に行います。
pre-MPRを複数回設けているのは、施策の結果の解釈や原因特定のリソース削減のためです。例えば、50%適用時の効果検証で施策による効果が負の影響を示した場合、モデルの精度が悪いからなのか、入札ロジック自体に問題があったのか、あるいはモデルが正常に適用されていないからなのか、それぞれの原因を特定するのに時間がかかることが有り得ます。そこで削減したリソースだけ次の施策の仮説検証に向けて時間を生み出すことが出来ます。SQRの言うところのSpeedの改善につながることなります。
プロダクトではバッチ推論のためインフラコストが全面適用までに大きく変わることがないとし、実行フローにpost-MPRは省いています。Long-term holdoutに関しても、サービスの特性上、施策の効果が出るまでの期間に差はないとして省略しています。
実行フローを予め策定しておくことで各フェーズの結論から意思決定を半ば自動的に行なえ、場当たりでヒューリスティックな意思決定を下すことを防ぐことができ、事業改善、事業理解を促進させることが出来ます。
おわりに
本稿では、私たちのプロダクトでABテストの実行フローについて紹介をしましたが、上記はあくまでビジネスにおいてリスク・リターンをコントロールするためのフレームであり、入札ロジックや予測モデルの改善によってはじめて事業改善が出来ると言えます。本稿で紹介したフローは簡易的に導入した段階ですのでまだまだ自動化する余地はあります。この実行フローやABテスト基盤の改善、それらを利用した事業改善に興味があるという方は是非AirTrackにお越し頂けければと思います。
【採用強化中】サイバーエージェントでは、140兆円の小売業界をデジタルで再発明するため、覚悟ある仲間を募集しています。
