
はじめまして!CLでiOS開発している劉と申します。
今回はCLライブキャス配信におけるリアルタイム字幕機能を紹介したいと思います。

目次
リアルタイム字幕とは?
リアルタイム字幕とは、CLライブキャスト配信者の音声をリアルタイムで認識・変換し、自動で他言語字幕を表示するというものです。
ユーザーはライブキャスト配信内の字幕言語選択ボタンから言語を選択することで、配信者の言葉がリアルタイムに字幕変換された状態で視聴することができます。
本機能は、日本語、英語、中国語(簡体字、繁体字)、韓国語、タイ語、インドネシア語の7言語が対応され、エンタテインメントコンテンツ配信プラットフォームでは国内初の機能となります。

リアルタイム字幕の仕組み
CLのライブキャスト配信は1人だけではなく、4人まで同時にコラボ配信ができます。(CLコラボ配信事例)
各ライブキャストの音声を認識し、音声からテキストにリアルタイム変換、テキストから他の言語に翻訳し、字幕をライブ動画に同期という流れとなります。
ライブキャスト配信は撮影された映像が視聴者の画面に表示されるまで遅延があります。リアルタイム字幕はこの「遅延」を利用し、音声から翻訳された字幕をライブキャスト動画に同期できるような仕組みとなります。ライブキャスト配信の「遅延」とはいえ、ある程度の時間しかないので、この時間以内に処理結果を視聴者に伝搬できるようにする必要があります。
そのため、配信者の音声認識からテキスト変換の部分をクライアント側が処理し、変換されたテキストをサーバーにおくり、サーバー側が翻訳を言語ごとに並列処理してから字幕を視聴側に届ける処理となります。
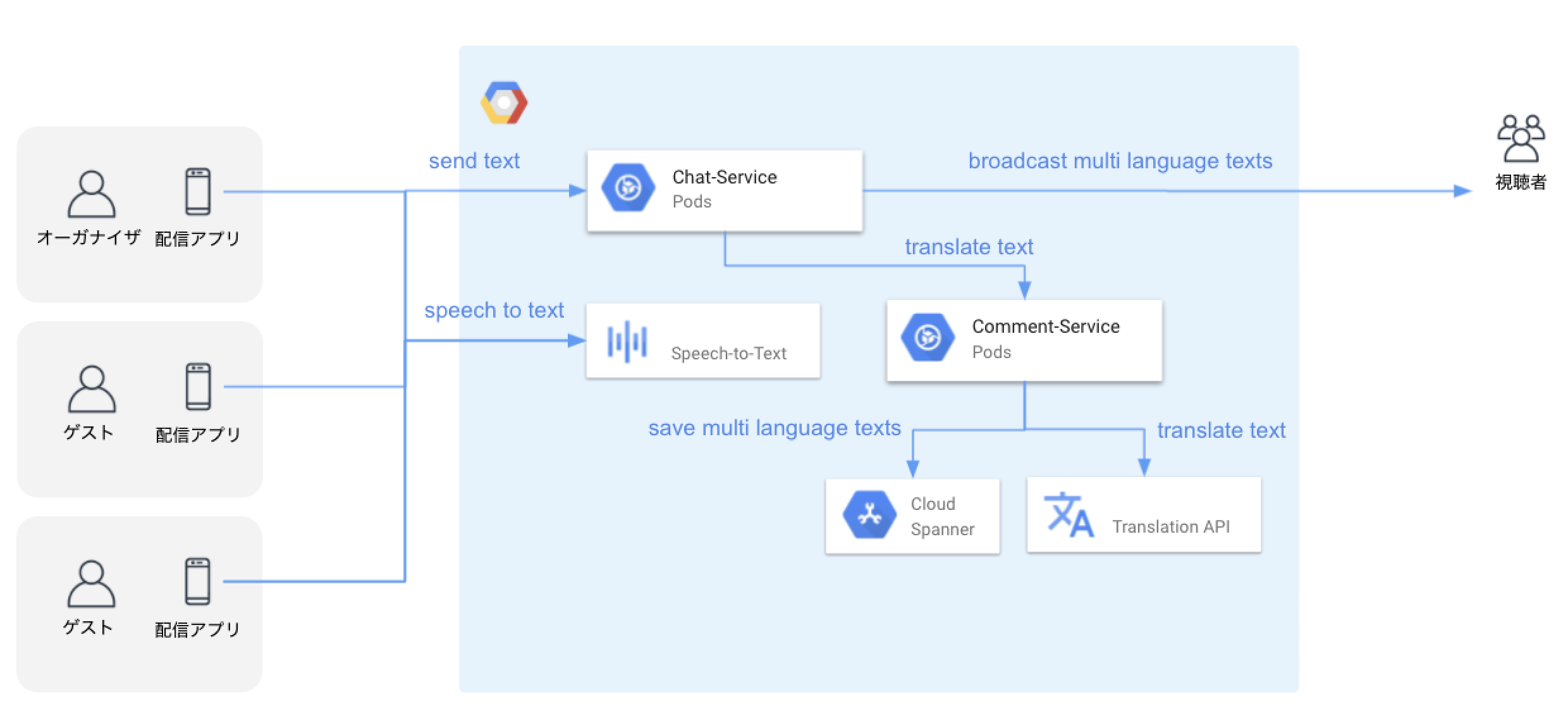
リアルタイム音声認識
音声認識技術の選定
世の中に音声認識技術はたくさんあります。アルゴリズムや人口知能の発展によって精度も急激に向上しており、CLはその中で代表的なサービスをいくつか検討しました。
- Google Cloud Speech-to-Text
Google 最新のディープ ラーニングのニューラル ネットワーク アルゴリズムを利用して、自動音声認識(ASR)を実現します。 - Amazon Transcribe
Amazon Transcribe は、自動音声認識 (ASR) と呼ばれる深層学習プロセスを使って迅速かつ高精度に音声をテキストに変換します。 - IBM Watson Speech to Text
Speech to TextはWatsonの音声認識機能です。ディープ・ラーニングを活用し、音響的な特徴と言語知識から正確にテキストを書き起こします。 - Microsoft Speech Services
85 を超える言語とバリエーションで、音声をすばやく正確にテキストに書き起こします。モデルをカスタマイズして、専門分野固有の用語の精度を高めます。 - Line CLOVA Speech
ノイズなど様々な環境下でも、日本語や韓国語等の認識能力は世界最高水準を誇り、正確に音声認識することができます。
上記を検討した結果、精度とコスパの点で総合的に良かった、Google Speech-to-Text を選定しました。理由は以下の通りです。
- APIが解放されており、言語翻訳のために Google Translate API が使える
- ストリーミング音声認識のAPIが提供され、マイクからストリーミングした音声入力の認識結果をリアルタイムに受け取れる
- 125以上の言語や言語変種に対応している
- マルチチャネルの状況で個別のチャネルを認識し、音声文字変換にアノテーションを付けて順序を維持できる
- 雑音の多い音声も正常に処理できる
- 分野固有の品質要件に合わせて最適化されたトレーニング済みモデルが用意されており、その中から選択できる
- 音声文字変換の評価ができる
Google Speech-to-Text API での音声認識方法
Speech-to-Text API には3つの主要な音声認識方法があります。
- 同期認識(REST および gRPC)では、音声データを Speech-to-Text API に送信してデータの認識を行い、すべての音声が処理されたら結果を返します。
- 非同期認識(REST および gRPC)では、音声データを Speech-to-Text API に送信し、長時間実行オペレーションを開始します。このオペレーションを使用することで、認識結果を定期的にポーリングできます。
- ストリーミング認識(gRPC のみ)では gRPC 双方向ストリームで提供された音声データの認識を行います。ストリーミング リクエストは、マイクからのライブ音声のキャプチャなどのリアルタイムの認識を目的として設計されています。ストリーミング認識では、音声をキャプチャしながら暫定的な結果を生成して、結果を表示できます。
上記の中から、CLライブキャストではストリーミング認識を使用しました。
ストリーミング認識APIをクライアント側で利用する
ストリーミング認識APIは gRPC のみとなります。
gRPC は、RPC(Remote Procedure Calls) を実現するためGoogleが開発したオープンソースです。HTTP/2 をトランスポートとして利用し、Protocol Buffers をインタフェース記述言語およびデータエンコーディングとして利用してます。提供する機能としては、認証、双方向のストリーミングとフロー制御、同期および非同期のバインディング、キャンセルとタイムアウトの対応などがあります。多くの言語において、クロスプラットフォームなクライアントおよびサーバーのバインディングを生成できます。
iOSでストリーミング認識APIを利用する場合は、grpc-swift を利用します。grpc-swift は Swift 向けのコード生成に関するプラグインが管理されているリポジトリです。
その中に Speech-To-Text gRPC iOS Example が提供されています。クライアントに導入する前に、これを参考にするのが良さそうです。
サンプルプロジェクトのセットアップに Speech-to-Text API に提供されている .proto ファイルを Swiftから呼び出せる .pb.swift ファイルの生成手順が書いてあります。makeコマンドを順次で実行し、生成された .pb.swift ファイルを xcode プロジェクトの /Generated フォルダに配置する必要があります。
ソースコードの以下の2つのクラスがメイン部分となります。
- AudioStreamManager.swift
オーディオストリーミングを管理するクラスです。マイクから入力した音声データを取得できます。 - SpeechService.swift
gRPC を利用し、Speech-to-Text API をインプリメントしたクラスです。 StreamingRecognizeRequest 型のリクエストストリームで音声データを送信し、StreamingRecognizeResponse 型のレスポンスストリームで中間および最終認識結果をリアルタイムで受信します。
ストリーミング認識APIを使う際の注意点としては、約5分ぐらいのコンテンツの上限があります。
5分の制約を超えた場合、「Exceeded maximum allowed stream duration of xxx seconds」とういうAPIエラーが発生します。
それを回避するため、Google Cloudガイドにある無限のストリーミングチュートリアルと同じように、5分ごとにストリーミングリクエストを再接続する必要があります。
音声認識を最適化する
最初の StreamingRecognizeRequest には、音声を伴わない StreamingRecognitionConfig 型の構成を含める必要があります。同じストリームで送信されるその後の StreamingRecognizeRequest は、生の音声バイトの連続フレームで構成されます。StreamingRecognitionConfig の設定を最適化することで、音声認識精度が向上します。
StreamingRecognitionConfig は以下の3つのフィールドから構成されます。
- config(必須)
RecognitionConfig 型の音声の構成情報が含まれます。 - single_utterance (省略可、デフォルト false)
音声が検出されなくなったらこのリクエストを自動的に終了するかどうかを示します。single_utterance を true に設定すると、音声コマンドの処理に役立ちます。
- interim_results (省略可、デフォルト false)
このストリーム リクエストは、後で(さらに多くの音声の処理後に)絞り込むことができる一時結果を返す必要があることを示します。中間結果は、レスポンス内で is_final を false に設定することによって通知されます。
リアルタイム字幕はライブキャストの会話を翻訳するため、一時的に結果を返してもらう必要があります。interim_results を true に設定しています。
音声の構成情報の RecognitionConfig に関して、いくつか最適化したフィールドを説明します。
- encoding(必須)
提供された音声(AudioEncoding 型)のエンコード スキームを指定します。コーデックを選択できる場合は、良好なパフォーマンスを得るために、FLAC や LINEAR16 などのロスレス エンコードをおすすめします。 - sampleRateHertz(必須)
提供された音声のサンプルレートを指定します(ヘルツ単位)。低いサンプリング レートでは精度が低下することがあります。可能であれば、音源のサンプリング レートを 16,000 Hz に設定します。 - languageCode(必須)
提供された音声を認識する言語とリージョン / ロケールを指定します。言語コードは BCP-47 識別子である必要があります。 - maxAlternatives(省略可、デフォルトは 1)
レスポンスで表示する音声文字変換候補の数を示します。デフォルトでは、Speech-to-Text API は最も可能性が高い音声文字変換候補を 1 つ表示します。 - profanityFilter(省略可)
下品な語句をフィルタで除外するかどうかを示します。 - enableAutomaticPunctuation(省略可)
音声認識の出力結果に句読点を付けるかどうかの指定できます。 - metadata (省略可)
RecognitionMetadata 型の音声のメタデータです。中に interaction_type と microphoneDistance を設定があり、場面によって音声認識の最適化できます。industry_naics_code_of_audio のフィールドもあり、音声認識業界を特定できます。 - speechContext(省略可)
この音声を処理するための追加のコンテキスト情報が含まれます。phrases フィールドがあり、音声認識タスクへのヒントを提供する語句のリストが含まれます。語句のヒントを使用して名前や用語を語彙に追加すると、特定の語句の精度が飛躍的に向上します。 - model(省略可)
認識モデルです。「video」動画の字幕作成などに適したモデル、「phone-call」電話から発せられた音声に適したモデル、「command_and_search」音声検索やコマンドに適したモデル、「default」上記のいずれでもない場合に適したモデル4つがあります。だたし、「video」と「phone-call」は日本語まだ対応されてないので、今回は「default」を使っております。モデルを有効させるため、use_enhanced を true に設定する必要があります。
音声認識は、日本語の場合は現時点では英語よりまだ認識精度が低い状況です。背景ノイズがある場合や複数の人が同時に話す場合などに、精度がかなり低下することがあります。可能な限りユーザーの近くにマイクを置くやイヤフォンマイクを利用するなどの手段がある程度必要になります。
音声認識結果から各言語へ翻訳
ストリーミング音声認識結果は、StreamingRecognizeResponse 型の一連のレスポンスで返されます。その中の isFinal はこのリストエントリ内に取得された結果が中間結果か最終結果かを示します。maxAlternatives を設定した場合、結果の中 alternatives にいくつの候補の音声文字変換リストが含まれ、その中の confidence が一番高いテキストが利用されます。
キャス配信開始の時間から会話区切りとして利用するための開始時間と停止時間を計算し、音声認識テキストと一緒にサーバーに送信しています。
CLサーバーは各言語の翻訳は並列に Google Translate API をリクエストし、すべての言語の翻訳結果を視聴側に gRPC を利用して送信しています。
CLではもともとコメントのストリーミングで gRPC を使用しており、今回字幕も同じ gRPC でデータを受信しています。
コメントと字幕の切り替えボタンを押したタイミングで、 grpc-swift の Bidirectional Streaming を使い、どちらの受信するかを指定し、通信データ量の削減をしています。
字幕を視聴動画へ同期
実際に字幕を視聴動画へ同期するとき、動画プレイリストファイルにある EXT-X-PROGRAM-DATE-TIME はサーバーの動画エンコーディング時に付与されるので実世界での日付と時間差が生じています。それを視聴側で補正する必要があります。
上述したキャス配信からサーバーで動画エンコーディングまでの時間差を正確に求めるのは不可能なので、近似値を用いております。具体的には映像が伝達されるまでにラグが生じるのでその値を latency として、 EXT-X-PROGRAM-DATE-TIME から引き算しています。
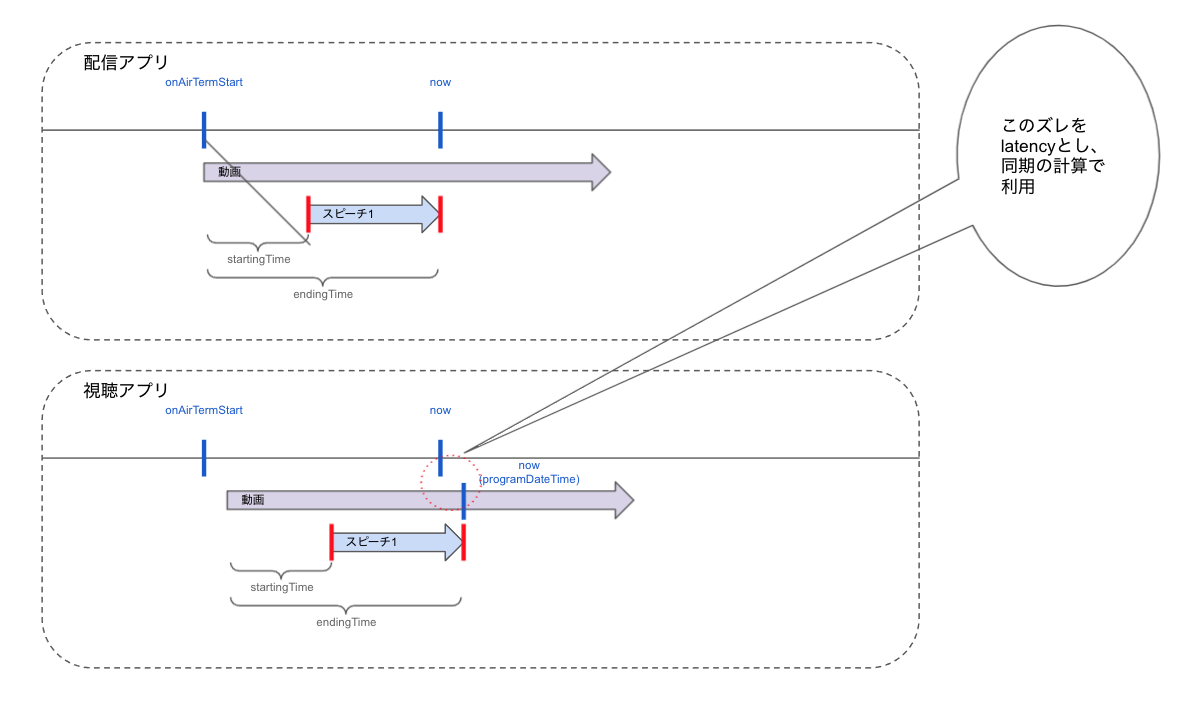
EXT-X-PROGRAM-DATE-TIME を配信開始からの経過秒数に変換する式は以下の通りです。
nowDate - EXT-X-PROGRAM-DATE-TIME = latency EXT-X-PROGRAM-DATE-TIME - latency = EXT-X-PROGRAM-DATE-TIME(adjusted) EXT-X-PROGRAM-DATE-TIME(adjusted) - onAirTermStart = 配信開始からの経過秒数
最後に
リアルタイム字幕機能は、声や話し方、配信環境等などが、字幕化の精度に影響を与えるため、100%の正確性が保証されず、意図しない字幕となる場合があります。しかし、字幕があることで海外ユーザーの皆さんでも以前よりわかりやすくキャス配信を視聴していただけるようになりました。これからもCLで、エンタメ業界の先駆者となるサービスとして革新的な機能を開発をして行きたいと思っています。
また、今回クライアントメインでリアルタイム字幕の仕組みを紹介しました。次回はサーバー側の仕組みの説明を予定させて頂いております。
最後まで読んでいただきありがとうございました。