
オレシカナイトとは
オレシカナイトは、「ABEMA」や「Ameba」をはじめとしたサイバーエージェントグループが運営するメディアにおいて、パブリッシャー独自の視点でアドテクノロジー開発を行うエンジニアの横断組織 「CyberAgent Publisher adTechnology Associations (PTA)」が主催する技術者向け勉強会です。
今回のテーマは「アーキテクチャ」です。
当社のエンジニアが登壇し、「ABEMA」や「Ameba」で実際に運用している広告システムのアーキテクチャについて発表しました。
新ABEMA広告配信アーキテクチャ(株式会社AbemaTV サーバサイドエンジニア 芝崎拓海)
概要
まずは株式会社AbemaTV芝崎の発表です。
新しい予算消化型配信基盤の刷新と新規開発に向けて、採用した技術とマイクロサービスの構成を紹介した後、直面した課題とその解決方法について詳しく発表しました。
発表スライドは下記をご覧ください。
ABEMAの広告配信システム
ABEMAの商品パッケージとして、予約型と予算消化型の広告配信があります。予約型は、配信期間とimpressionを保証する形式で、予算消化型は設定された予算分の広告が配信される形式です。
ABEMAではリニアとビデオ両方に広告配信をしており、これまでは予約型の配信基盤で予算消化型の配信も行っていましたが、予算消化型の配信基盤を新規で構築及び刷新を行いました。
予算消化型広告配信のアーキテクチャ
設計方針は以下の5つです。
- (なるべく)新しい技術を導入する
- マイクロサービスによる関心の分離
- そこまで高くないレイテンシ要求
- (なるべく)キャッシュを使わない
- 運用容易性
採用した技術
Istio
主にEnvoyのconfigを管理する用途で採用しています。これまでは、コンポーネントでEnvoyのバージョンが異なりconfigの記述方法もコンポーネント間で異なっていることが問題でしたが、Istioの導入で一元管理できるようになりました。
open policy agent
フロントエンドのAPIの認証・認可に利用しています。認証・認可の実装をコンポーネントから切り出すことができました。regoというポリシー記述言語で認可のルールを記述します。
コンポーネント構成
予算消化型広告配信システムは大きく以下3つのコンポーネント群で構成されています。
- 配信系コンポーネント群
- 集計基盤群
- 管理画面用コンポーネント群
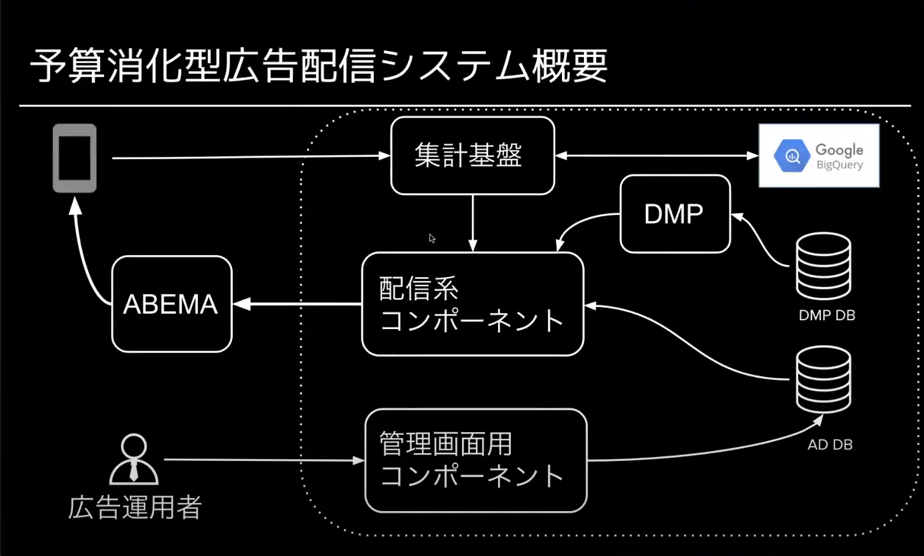
配信と集計に関わるコンポーネントについて紹介します。
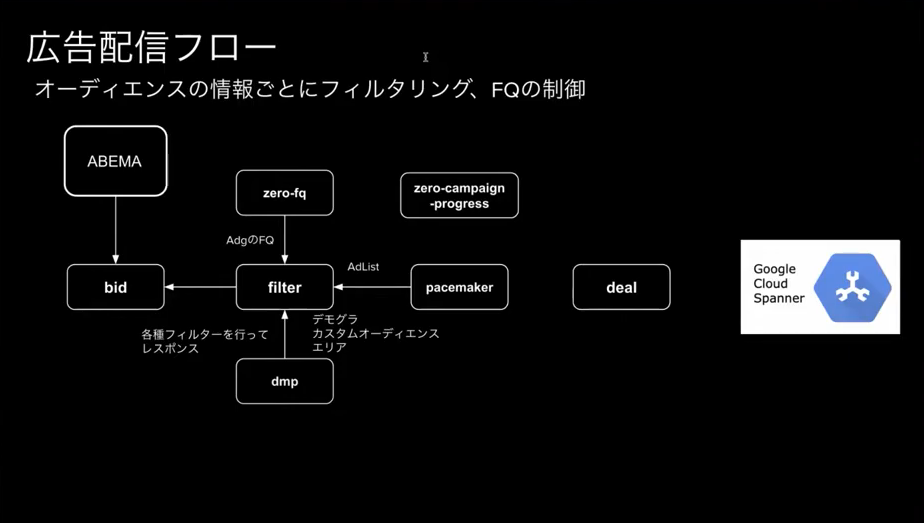
配信系コンポーネント群
- bid:OpenRTBのリクエストをパースしてgRPCに変換
- filter:ユーザーごとの広告フィルタリング
- pacemaker:予算進捗の管理
- deal:DBから配信可能な広告の取得
配信系コンポーネント群の処理の流れは以下の画像の様になっています。
集計系コンポーネント群
- zero:リアルタイム集計基盤でユーザーのフリークエンシー作成と予算進捗管理に利用
- tracking:広告の視聴ログをAvroに変換してPubSubに入れる
集計系コンポーネント群の処理の流れは下記画像の様になっています。
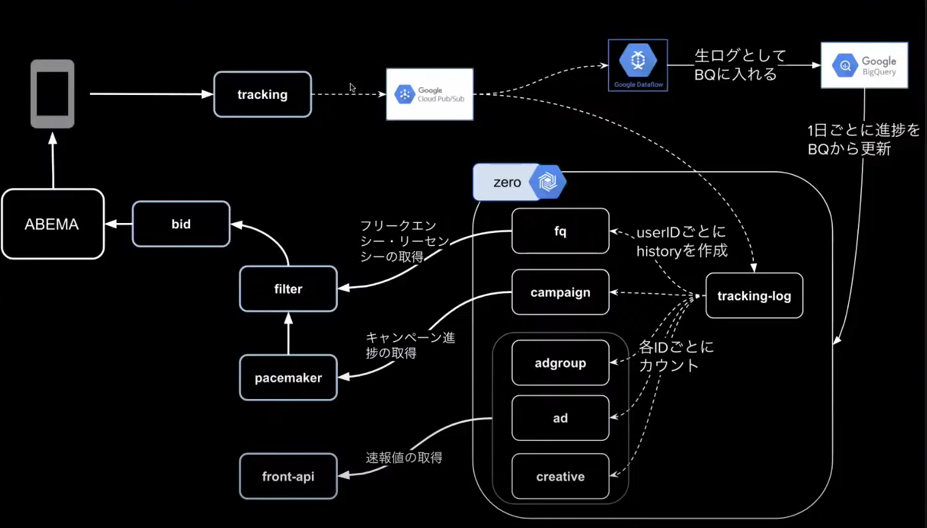
直面した課題と解決方法
opa-envoy-pluginがIstioで使えない
課題:gRPCをパースする処理がEnvoyには実装されていたが、Istio proxyには実装されていなかった
解決方法:フロントエンドのAPIはIstioを利用せずEnvoyを利用することにした
スケールとレイテンシ
課題:データを分散させすぎると複数シャードへのアクセスが発生し、パフォーマンスが悪化してしまう
解決方法:インターリーブという設計方法を用いて、親子関係にあるテーブルを物理的にまとめた
jsonのデコード処理
課題:ユーザーの広告接触履歴のjsonデコード処理が遅い
解決方法:goのjsonデコードでReflectionを使わずeasyjsonを利用することで改善
Spanner sdkのデコード処理
課題:sdk内で広告データのgRPCデコード処理が重かった
解決方法:やむなく広告をキャッシュすることで解決
まとめ
- 新しい技術を採用して様々な課題に直面した際はドキュメントやIssue、コードを読む必要があるので覚悟が必要
- レイテンシとスケーラビリティはトレードオフの関係にあるため、ビジネスの要件にあったテーブル設計を行う
- パフォーマンスは実際に負荷試験をやってみないとわからないケースがあるため、実装と負荷試験のループを早く回せるとよい
リアルタイム予測システムアーキテクチャ(株式会社サイバーエージェント データサイエンティスト Tristan Irvine)
概要
次に、株式会社サイバーエージェントIrvineの発表です。
既存の予測システムが抱えている課題について言及した後、予測システム刷新によってその課題をどの様に解決したのか発表しました。
発表スライドは下記をご覧ください。
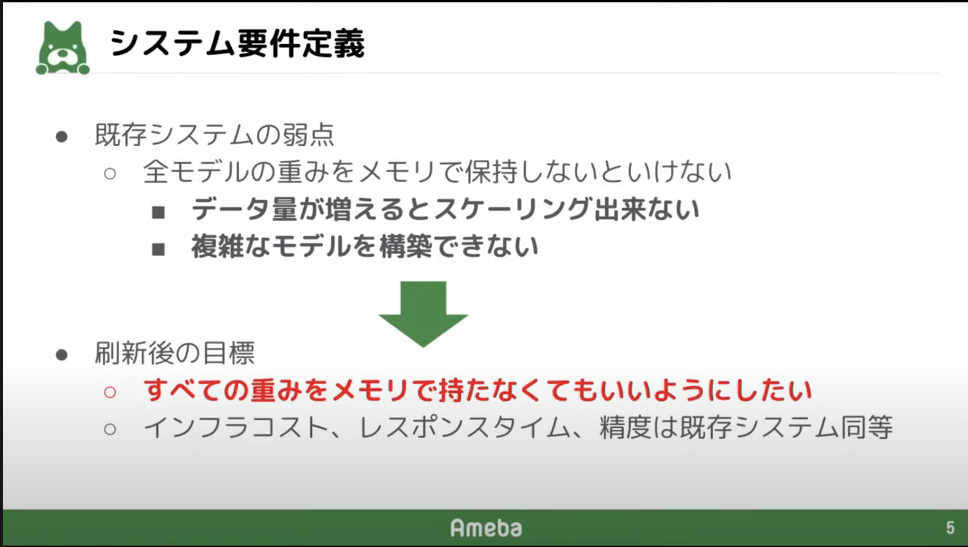
旧予測システム
予測システムは広告の入札額を計算するために、広告のCTRとCVRを予測します。
そして、実際に予測の結果広告が配信されると、その広告の実績(imp、click、CV)が予測システムにフィードバックされ、予測のモデルを更新するという仕組みになっています。
Amebaの広告配信システムで利用されている予測システムには「モデルの重みをメモリで保持しなければならない」という課題がありました。モデルの重みをメモリで管理していると、データ量が増えてくるとその分メモリを必要としてしまうので、複雑なモデルを構築できません。
そのため、刷新後にはすべての重みをメモリ上で保持しないことで上記課題を解決します。この際、インフラコストやレスポンスタイム、予測の精度は既存システムと同等である必要があります。
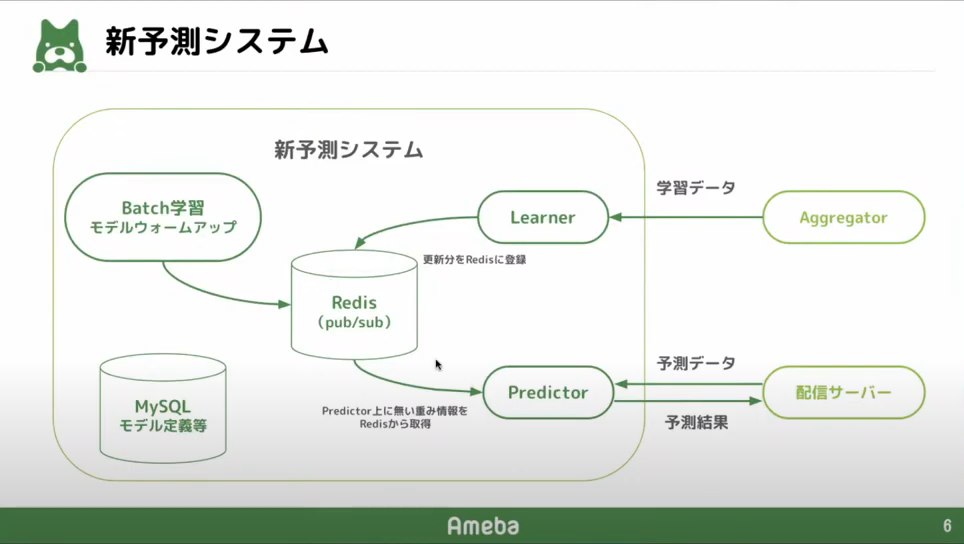
新予測システム
新予測システムは、下記画像のような構成になっています。新予測システムでは、モデルの重み情報をRedis上に保存します。Learnerはモデルの更新分をRedisに登録します。PredictorはRedisからモデルの重み情報を取得します。こうすることで、モデルの重みを常にメモリ上で保持する必要がなくなりました。
予測の流れ
新予測システムにおける予測の流れは下記のようになっています。
- リクエスト:候補広告ごとに共通の特徴量と広告個別の特徴量に別れている。
- データパーシング:simd-jsonという高速なjsonパーシングの仕組みを採用。
- 重み取得:非同期で重みの情報をRedisから取得し、24時間はローカルキャッシュとして残しておく。
- 予測:共通の特徴量と広告個別の特徴量から予測を行う。共通の特徴量予測は広告数によらず1回で済む。
ローカルモデルのデータ構造
Factorizaiton Machineのモデルデータは、1次元の配列と2次元の配列で表されるが、それらの配列を1次元の配列としてマッピングすることで、メモリ上のアドレスが近い場所にモデルデータが配置されるようにした。
こうすることで、CPUキャッシュのパフォーマンスを向上した。

モデル更新
モデルの更新にはRedisのPub/Sub機能を利用しています。5分に1回の頻度でLearnerのモデル情報をRedisにPublishすると、RedisをSubscribeしているPredictorに更新分が送信されます。そうすることで、常に最新のモデルを利用する事ができます。
流量制限
リクエストが多すぎると、AutoScalingが間に合わずに処理が詰まってしまう。そのため、レスポンスタイムが10msを超えたらPID制御でレスポンスタイムが10msに戻るまで流量制限をする仕組みを作りました。
開発言語
新予測システムは一律Rustで実装しました。既存のシステムはC++ライブラリとJavaのAPIで実現しています。C++と比べてコンパイル時に危険なコードはエラーとして教えてくれるのでバグが発生しにくく、現状の新予測システムはセグフォもヌルポもメモリリークも発生していないです。
パフォーマンス
新予測システムは既存のシステムに比べてパフォーマンスが大幅に改善しています。Redisアクセスが発生しているにも関わらず、すべての広告予測値を1-2msで返せている。また、必要な予測サーバの台数は既存システムの半分で済んでいる。さらに、新しいインスタンスの起動時間は20分から20秒まで短縮されました。
まとめ
- 予測システムを刷新した
- 大量の重みをRedisで保持することでメモリに対してスケーリング可能なシステムになった
- パフォーマンスが改善され、既存システムよりもインフラコストが下がっている
imp進捗管理機能のアーキテクチャ(株式会社AJA サーバサイドエンジニア 坂本泰規)
概要
最後に、株式会社AJA坂本泰規の発表です。
imp進捗管理機能を開発するにあたっての設計方針、技術選定、アーキテクチャについて発表しました。
発表スライドはこちらをご覧ください。
imp進捗管理機能
imp進捗管理機能とは、案件のimpが出るペースを管理する機能です。Programmatic Guaranteedという広告取引では、imp数を保証する必要があります。また、ディールの期間全体になだらかに配信できるようなペーシングも必要になります。これらを実現するのがimp進捗管理機能です。
技術選定
処理概要
imp進捗管理機能の処理概要は下記です
- 時間単位で配信するimp数をペーシングする
- 現状は未配信imp数の均等割と前倒し係数による調整を行っている
- ディール期間の最後に在庫が逼迫してimpが出しきれないと困るので前倒し係数が必要です
- 落札した際にペーシングした値を減らしておく
- 落札したとしてもimpがでない場合もあり、乖離が発生するが毎時のペーシングの際に実績を元に補正する
- 0を下回ったらリクエストを止める
選定基準
技術を選定する際の基準は下記です
- コスト:売上相応に抑える必要がある
- スケーラビリティ:広告配信に影響が出ないように非同期に集計する必要がある
- 集計レイテンシ:集計レイテンシが高いと必要以上にimpが出てしまうのでレイテンシを抑える必要がある
比較対象
imp進捗管理機能を実現するにあたって候補になったサービスは以下です。
- SQS
- DynamoDB Streams
- Kinesis Data Streams
SQSは扱いが楽である代わりに明示的にスケーリングをコントロールできないので不採用としました。また、DynamoDB Streamsは想定する広告リクエストパターン(ABEMAのリニアような場合、ユーザーが同じ時間に同じ番組を見ていると、広告が流れる際に広告リクエストがスパイクする)とオートスケールの相性が良くないため不採用としました。Kinesis Data Streamsはスケーラビリティに優れており、Kinesis Data Analyticsとの相性も良いため、Kinesis Data Streamsを採用しました。
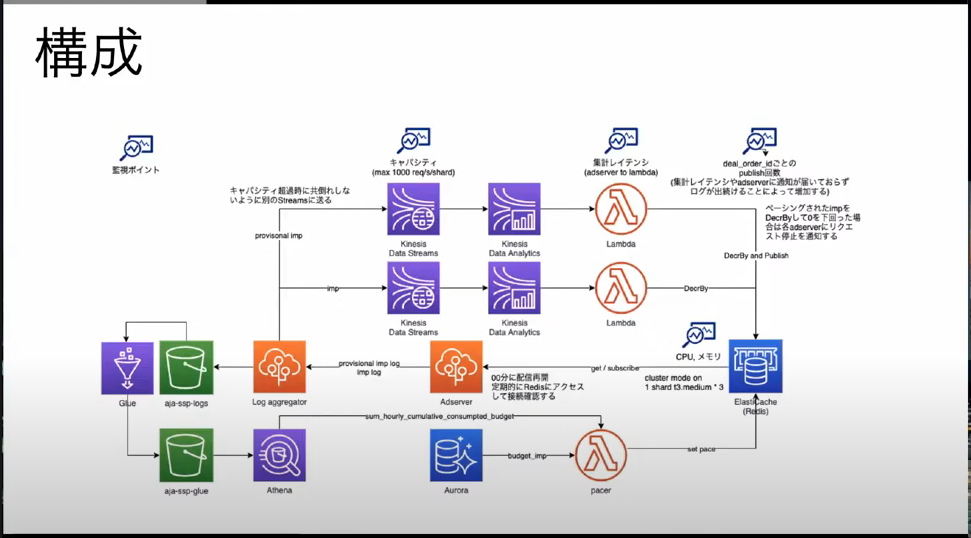
システムの構成
システム全体の構成は下記画像の様になりました。
副系統
開発したimp進捗管理機能において想定される障害として、リクエストが瞬間的に増加してKDSのキャパシティ超過してしまう可能性があります。このような場合にもimp進捗を管理したいので副系統を実現しました。以下、障害発生時に起動する副系統に対して、もともと起動しているシステムを主系統とします。
選定基準
副系統に利用する技術を選定する際の基準は以下です。
- コスト:可用性が上がることによる利益がインフラ・運用コストを上回る必要がある
- スケーラビリティ:主系統と同等のスケーラビリティが求められる
- 集計レイテンシ:副系統では集計レイテンシのサービスレベルをさげることでインフラコストを下げる
比較対象
副系統を実現するにあたって候補になったサービスは以下です。
- Managed Streaming for Apache Kafka(MSK)
- Glue
結論としてGlueを採用しました。GlueはAJA内で集計に利用しており知見がある点と、バージョン2.0からジョブが数秒で起動するようになった点が採用の理由です。
MSKはインスタンスにコストがかかるのでコールドスタンバイを試みたのですが、起動に時間がかかってしまうため不採用としました。
主系統と副系統の切り替え
主系統と副系統の切り替えには、EventBridgeのDatadogインテグレーションを利用しました。アラート発火時に、Lambdaを実行した副系統のcronを有効にします。ただし、現状このインテグレーションはap-northeast-1では対応していないため、この切替部分のみUSのリージョンに構築しました。
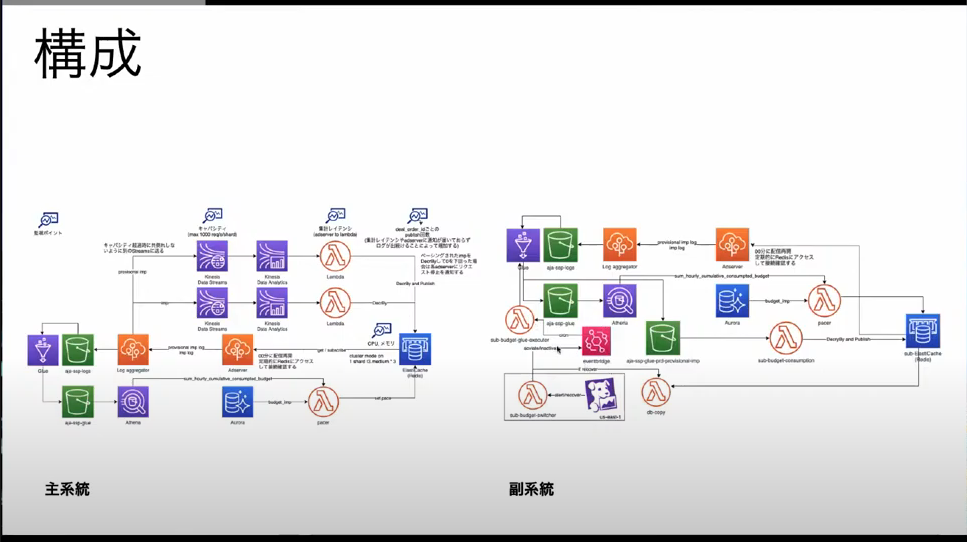
主系統と副系統をあわせた構成
主系統と副系統をあわせた構成は下記画像の様になりました。
まとめ
- AWSのサービスを利用してimp進捗管理機能を実現した
- 主計等はKinesis Data Streamsを利用して実現した
- Kinesis Data Analyticsを連携させてストリーミング集計を行った
- 副系統はGlueのバージョン2.0を利用して実現した
次回予告
そんなオレシカナイトの16回目がオンラインで11/17(水)19:00
に開催されます!!(※時間が変更される可能性があります。コンパスよりご確認ください)
次回のテーマは「アドテク×プロダクト開発」です。
広告プロダクトを開発する際に、普段どんなことと向き合っているのかお話していただきます。
どんな話が聞けるか楽しみですね!
以下のURLからぜひエントリーください!
connpass:https://cyberagent.connpass.com/event/227271/
Profile:
株式会社サイバーエージェント
永井陽太
▼PTA