
こんにちは。
CyberAgent group Infrastructure Unit(CIU)Private Cloudチームで内定者アルバイトをしていた杉浦智基(github)です。
この記事では、自身が携わった、CIUで運用しているOpenStack GlnaceのデータストアのCephクラスタにおけるデータ移行作業について紹介します。
OpenStack
OpenStackはクラウド環境を構築・管理するOSSです。
OpenStackを導入することで、複数のマシンを束ねて一つのプラットフォーム上で扱うことが可能になり、ユーザはそこで仮想マシンの構築や、それに伴うネットワーク、ストレージの管理といったことができます。
またOpenStackは一つのソフトウェアではなく、VMの管理、ネットワークの管理、ストレージの管理といった機能ごとに一つのソフトウェアが作られており、これらが互いに通信して連携することでOpenStackとして様々な機能を提供しています。
CIUが社内で提供しているクラウドサービスであるCycloudでは、Kubernetes上にこれらOpenStackのコンポーネントをPodとしてデプロイしており、ユーザーの要求に応じて、仮想マシンの提供などを行っています。 CycloudにおけるOpenStackの詳しい構成について、興味がある方はよろしければこちらの記事を参照ください。
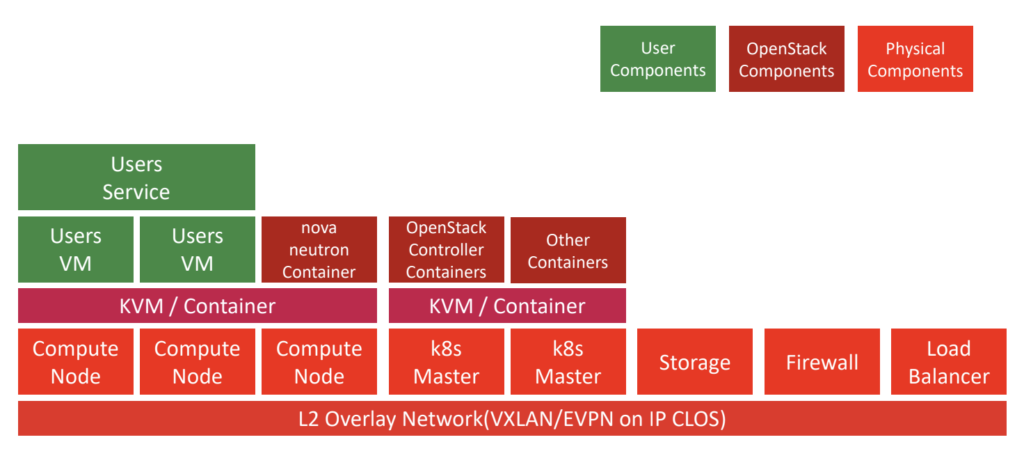 Cycloud k8s OpenStackのコンポーネント
Cycloud k8s OpenStackのコンポーネント
Glance
GlanceはOpenStackの構成要素の一つであり、VMイメージの管理を担当しています。
VMイメージとはAWSにおけるAMIのようなもので、必要な設定を行ったマシンをVMイメージとして保存し、次回以降そのイメージを用いてVMを構築すること、設定を行う手間を省くことができます。
GlanceではこのVMイメージを、予め用意しておいたデータストアに保存し、リクエストに応じてVMイメージの提供します。
Ceph
Cephは分散ストレージを構築するOSSの一つです。
Cephでは複数のストレージを束ねてRADOSと呼ばれるストレージクラスタを構築し、そこからブロックデバイス(RBD)やオブジェクトストレージ(RADOSGW)、ファイルシステム(CephFS)を提供します。
CycloudのGlanceではこの内、ブロックデバイスであるRBDを使って各VMイメージを保存しています。
ちなみにCephという名前は頭足類を意味するcephalopodから来ており、アイコンやバージョン名にはタコ関連のものが使われたりしています🐙
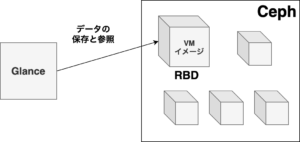
GlanceとCephのイメージ
Cephクラスタの移行
CycloudではCephをKuberentesのPodとして構築し、KubernetesのノードにCeph用のストレージを搭載する方法を用いていました。
この方法は管理対象となるノードが減る一方、ストレージに対するオペレーションに対して、Kubernetesへの操作が伴う点や安定性の観点から、いくつかの問題点が存在していました。
そのため、現在Cephクラスタは専用のストレージノードを設けてそこで運用されることになり、Kubernetes上のCephクラスタのデータは新しいクラスタへ移行することとなりました。
それに伴いGlanceが保管するVMイメージも移行が必要となり、今回の移行プロジェクトがスタートしました。
データ移行計画
今回のGlanceのVMイメージの移行は大きく分けて次の三つの作業で行いました。
- 新CephクラスタでのRBDの作成と旧Cephクラスタからのデータコピー
- Glanceの設定ファイルを更新し、新Cephクラスタへ接続
- GlanceのVMイメージ保管場所を管理するDBのレコードの更新
新旧Cephクラスタ間のデータコピー
Cephのrbdにはデバイスマッピング機能があるため、これを用いて操作対象のVMイメージを保管したrbdをそれぞれ作業用マシンにマッピングしました。
デバイスマッピングでは、あるマシンに対象のブロックデバイスを物理的にアタッチされているように見せることができます。
これによりネットワーク通信を意識せずに、ddといった既存のツールでデータコピーが可能となります。
Ceph rbdをデバイスマッピングする際のコマンドは以下のようになります。
$ rbd map --pool ${TARGET_POOL} --conf ${CEPH_CONFIG} ${RBD_NAME}なおこの作業では大量のrbdに対してマッピングとコピーの作業が必要となるため、Go言語を用いた補助CLIツールを作成して使用しました。
Glanceの新Cephクラスタへの接続
Glance内のCephの設定ファイルおよびkeyringを更新します。 Cycloudでは前述の通り、OpenStackのコンポーネントをKubernetes上で管理しており、マニフェストファイルはhelmを用いて構築されるため、該当箇所を修正後、 helm upgradeによって更新しました。
VMイメージ保管場所の更新
GlanceではそれぞれのVMイメージの保管場所をMySQLデータベース内の image_locationsというテーブル内で管理しています。
そのためこのテーブルのデータを以下のようなSQL文で更新します。
UPDATE image_locations
SET value=REPLACE(value,'OLD_CEPH_ID','NEW_CEPH_ID')
WHERE deleted=0;
データ移行準備
手順とツールの準備ができた段階で開発環境に対して操作を行い、いくつかの項目を確認しました
正確にデータを移行できているか
移行対象のデータが全てコピーできているかは非常に重要です。
また、データコピーの確認は操作対象rbdのメタデータだけではなく中身の確認もしなくてはいけません。
今回はデバイスマッピング機能で作業用マシンに簡単にデータを取り出せるため cmpを用いて確認を行いました。
$ cmp -b old_data new_data移行の所要時間
VMイメージの移行中、ユーザはこれらのデータを用いた操作ができなくなるため、作業時間は必要最小限であるべきです。
今回は移行したVMイメージ情報を以下のようなyaml形式で記述して、二回目以降はその情報から差分を計算してコピーする機能を実装することで、当日の作業時間を削減しました。
update_date: 2021-...
images:
- id: xxxxx-xxxx
name: image_name
size_bytes: "123456"
migrated_at: "2021-..."
original_deleted: 0
- id: yyyyy-yyyy
...また、今回の作業においては、それぞれのVMイメージデータに対する操作は独立したものだったので、Go言語の強みを生かして、コピー作業を並行処理しました。
しかし、開発環境でデータコピー作業を行ったところ、並行に処理してるにも関わらず、想定より速度が上がりませんでした。そこでコピー中の様子を眺めてみると、多数のプロセスが長時間実行され続けている様子が見られ、コンテキストスイッチによる性能低下が予想されました。
コンテキストスイッチとはプロセスの切り替え作業を指します。
通常CPUはある時点においては一つのプロセスしか実行することができず、OSは複数のプロセスを実行するため、時間区切りでプロセスの切り替えを行います。この切り替え作業、つまりコンテキストスイッチでは、現在のプロセスの状態を保存し、次のプロセスの状態をレジスタに書き込みます。
しかし、これらの作業はCPUの処理速度と比較して遅く、コンテキストスイッチの頻発は全体の処理完了時間に影響を与えます。
通常、goroutineの管理はGoのランタイムで行われており、OSによるコンテキストスイッチは発生しません。
しかし、このCLIツールではデータコピーに外部コマンドを発行し、またそのコマンド1つあたりの実行時間が長いため、OSによるコンテキストスイッチが頻発しこのような性能低下が発生したと思われます。
これを踏まえて、本番作業ではCPUリソースが潤沢なマシンを使うとともに、セマフォ(semaphore)を用いた並列数の制限を行いました。セマフォは処理の並行数を制限するために使用されるデータ型を指し、Goでは [golang.org/x/sync/semaphore](http://golang.org/x/sync/semaphore) を用いてカウンターのようにして以下のように実装できます。
func migrateImages(ims []*Images) error {
var eg errgroup.Group
// NewWeightedの引数の数が並行処理の数の上限になる(ここではCPUのコア数)
sem := semaphore.NewWeighted(int64(runtime.NumCPU()))
for _, im := range ims {
im := im
// 並行数が上限に達している場合、Acquireでブロックされる
_ = sem.Acquire(context.Background(), 1)
//eg.Go内は並行に処理される
eg.Go(func() error {
// Releaseで並行処理が終わったことを通知
defer sem.Release(1)
err := migrateImage(im)
return err
})
}
// 全ての並行処理が終わるまで待機
err := eg.Wait()
return err
}これらの対策により(実際はどの対策が有効だったかは検証していませんが)、開発環境でデータ移行に30分程度かかっていたところを、本番では約4倍のデータ量に対してデータ移行を20分程度で完了させ、大幅な作業時間の短縮ができました。
手順書の準備
社会人にとって必要なのは”ほうれんそう”だとよく言われます。
この作業においても例外ではなく、手順書を作ることで操作する本人のミスを防ぐだけでなく、他のチームの方々への作業内容と影響範囲の共有をしました。
データ移行当日
当日は事前の準備と社員の方々のサポートの甲斐もあって滞りなく終了しました。
現在は、新しいデータストアをバックエンドとするGlanceが元気に動いています。
おわりに
今回はGlanceのデータストアの移行作業について紹介しました。
調べてみるとGlanceのデータストアの移行、特にあるCephクラスタから別のCephクラスタへの移行というのはあまり行われてないようで、作業手順の考案ではGlanceやCephのドキュメントとにらめっこする日々でした。
また、趣味ではなく業務として運用している基盤を触るということもあり、その準備におけるノウハウは普段の開発では得られないものが多くありました。
サポートしていただいたチームの皆さん、協力いただいたユーザの方々、ありがとうございました!