
こんにちは、ABEMA開発本部開発局Webチームの@kubosho_です。最近はウマ娘でようやくパワー18因子が自前で使えるようになりました。
さてさっそく本題ですが、ABEMA Webにおけるパフォーマンス向上施策としてChunkの細分化(Granular Chunks)をおこないました。この記事ではABEMA WebにおけるChunkの細分化を実施した方法と、施策実施後にどのような影響が出たかについて解説します。
なおこの記事は、技術書典12で頒布したABEMA Tech Book 2022からのシングルカット的な記事です。ABEMA Tech Book 2022には他にも様々なことが書かれているのでぜひ買ってください(ダイレクトマーケティング)。
なぜChunkの細分化を実装するのか?
目的は次の通りです。
- 各ページに必要なコードだけを読み込むようにすることで、不必要なコードのダウンロードを無くす
- 変更があまりないファイルについては、長時間キャッシュさせるといった戦略を取れるようにする
これらの目的を果たすことで、ページの表示時間を短縮し、よりよいサービスの体験を提供できることを目指しました。
ただし我々のチームではNext.jsやGatsbyといったフレームワークを導入していないため、それらのフレームワークで提供されているChunkの細分化は使えず、コードの分割を自分達で実装する必要がありました。
そこでChunkの細分化を実装するのに役立つ Loadable Components というライブラリを使い、Next.js で実装されている Chunk の細分化を再現しようと考えました。
Chunkの細分化実装に向けた課題
ということで実際の改善に入りたいのですが、ABEMA Webには複数の課題がありました。
バックエンドとフロントエンドそれぞれで課題を抱えていたので、これらの課題について書いていきます。
バックエンドの課題
まずはバックエンドの課題から見ていきましょう。バックエンドの課題は次の2つがありました。
- ExpressでviewシステムとしてEJSを使いHTMLを返す設定が入っていた
createRenderVariablesという複数の処理をひとまとめに実行している関数があった
それぞれの課題について詳細を書いていきます。
ExpressでviewシステムとしてEJSを使いHTMLを返す設定が入っていた
我々はサーバー側のviewシステムとして EJS を使っていました。
Expressとの連携が簡単だったのでそこは良い部分でしたが、問題点としては次に挙げるものがありました。
- ReactDOMServerのAPIが使えないため、将来的なパフォーマンス向上施策に制限がかかってしまう
- 我々の環境要因によって、EJSのバージョンアップに困難が伴った
- クライアント側ではReactを使っているが、サーバー側ではEJSを使っているという統一感の無さ
Chunkの細分化を導入するにあたって、特に「ReactDOMServerのAPIが使えない」が致命的でした。
Loadable Componentsはloadable-stats.jsonというファイルを元に、読み込むファイルを決定します。簡略化したコードで示すと次の通りです。
const chunkExtractor = new ChunkExtractor();
const scripts = chunkExtractor.getScriptElements();
chunkExtractor.collectChunks(<Component {...props} scripts={scripts} />);
chunkExtractor.collectChunks() を実行する際JSX Elementが引数として必要ですが、EJSを使ったままだと引数にJSX Elementを渡せません。
そのためEJSからReactに移行するのは必須要件でした。
createRenderVariables() という複数の処理をひとまとめに実行している関数があった
また createRenderVariables() という関数がBFF側で実装されていました。
createRenderVariables() は複数の文脈が違う処理を実行しているため、処理が複雑になり、触りづらいものになっていました。
具体的に関数内でやっていた処理を挙げてみると次の通りです。
- SSRをおこなうにあたり必要なデータの設定
- hydrateのためのデータの設定
- meta要素に設定するための値の設定
- ノーマライズされたuser-agentの設定
- WebPが使えるかどうかの設定
- リージョンの設定
- SEOのための 構造化データの設定
こういった処理を1つの関数内で処理していたため、テストを書くのは困難でした。
そのため createRenderVariables() はテストがなかったですが、かといってテストがない状態だとリファクタリングしたときにどこに影響が出るのか分からず、触ってはいけないあのコードみたいな扱いになっていました。
フロントエンドの課題
フロントエンド側では、Chunkの分け方が最適化されていない課題がありました。
webpackのchunkに関する設定部分を見ると、app, app-mobile, vendor-compat, vendorという4つのchunkが出力される設定になっていました。この4つのchunkはそれぞれ次の役割がありました。
| 名前 | 役割 |
|---|---|
| app | ABEMA Webを動かすためのファイル(デスクトップブラウザー用) |
| app-mobile | ABEMA Webを動かすためのファイル(モバイルブラウザー用) |
| vendor | node_modules内をまとめたファイル |
| vendor-compat | node_modules内の古いブラウザーで見た場合に使うライブラリをまとめたファイル |
entry: {
app: path.resolve(SRC_CLIENT_DIR, './main.ts'),
'app-mobile': path.resolve(SRC_CLIENT_DIR, './main-mobile.ts'),
},
optimization: {
splitChunks: {
cacheGroups: {
'vendor-compat': {
name: 'vendor-compat',
test: (module) => {
return (
module.context &&
module.context.includes('node_modules') &&
isCompatPackage(module)
);
},
chunks: 'all',
enforce: true,
},
vendor: {
name: 'vendor',
chunks: 'all',
test: (module) => {
return (
module.context &&
module.context.includes('node_modules') &&
!isCompatPackage(module)
);
},
enforce: true,
},
},
},
}
chunkが細かく分けられず大まかに分けられていたことで、特定のページでしか使われないライブラリやコードが全てのページで読み込まれて、ページの読み込みに時間がかかったり、必要以上にデータ通信量が増えてしまったりする問題がありました。
実装の方法
ここまでを踏まえた上で、Chunkの細分化の実装方法を実際に見ていきましょう。
サーバー側のviewシステムをReactに変更する
まずはEJSが使われていたviewシステムをReact (TSX) に変えました。
変更前は次の通りindex.ejsをテンプレートとして、createRenderVariables() を使ってSSRを行う際に必要なデータをview側に渡していました。
res.render(
'index',
createRenderVariables(req, {
title: 'ABEMA',
description: 'ページの説明文がここに入ります。',
}),
);
変更後は react-dom/server の renderToStaticMarkup() をラップする renderToStaticMarkupWithTailComment() を用意して、JSX.Elementを返す createIndexPage() を実行してクライアント側へSSRに必要なHTMLを返すようにしました。
renderToStaticMarkupWithTailComment(
createIndexPage({ deviceInfo, metadata, canUseWebP, regionData }),
res,
);
loadable componentsの導入
次にloadable componentsを導入します。今回は @loadable/component を使わず @loadable/server だけを使うようにしました。
import path from 'path';
import { ChunkExtractor } from '@loadable/server';
import { BUNDLES_DIR } from '../application/serve_bundle';
export type Entrypoint = 'app' | 'app-mobile' | 'app-migration';
const webExtractorMap: Map<Entrypoint, ChunkExtractor> = new Map();
export async function createWebExtractors(): Promise<void> {
const entrypoints: Entrypoint[] = ['app', 'app-mobile', 'app-migration'];
entrypoints.forEach((entrypoint) => {
const statsFile = path.join(BUNDLES_DIR, 'loadable-stats.json');
const chunkExtractor = new ChunkExtractor({
entrypoints: [entrypoint],
statsFile,
outputPath: __dirname,
});
webExtractorMap.set(entrypoint, chunkExtractor);
});
}
export function getWebExtractor(entrypoint: Entrypoint): ChunkExtractor {
const webExtractor = webExtractorMap.get(entrypoint);
if (webExtractor === undefined) {
throw new Error(
`WebExtractor for entrypoint: ${entrypoint} has not been initialised.`,
);
}
return webExtractor;
}
定義されている createWebExtractors() と getWebExtractor() のそれぞれの役割について説明します。
createWebExtractors() はBFFのentrypointとなるファイルを実行するときに呼び出されます。事前に createWebExtractors() を実行することでextractorのキャッシュを作成し、その後の処理時間を高速化する目的があります。
createWebExtractors() の内部ではentrypointごとに必要なchunkを @loadable/server の ChunkExtractor を使って引っ張ってきてMap objectに設定しています。
なおentrypointが複数ある理由としては、ブラウザーごとに読み込まれるJavaScriptが異なるためです。各環境で読み込まれるentrypointがどれになるかはそれぞれ次の通りです。
| 名前 | 役割 |
|---|---|
| app | ABEMA Webを動かすために共通で必要となるコードが入ったファイル(デスクトップブラウザー用) |
| app-mobile | ABEMA Webを動かすために共通で必要となるコードが入ったファイル(モバイルブラウザー用) |
| app-migration | IE11向けのページで使われるファイル |
appとapp-mobileは特定のページごとに必要なコードは入っておらず、ABEMA Webのページ共通で必要なコードのみ入っています。
そして getWebExtractor() を呼び出すview側のコードは次の通りです。
export const createIndexPage = (props: PageProps) => {
const { deviceInfo } = props;
const entrypoint = getEntrypoint(deviceInfo);
const webExtractor = getWebExtractor(entrypoint);
const scripts = webExtractor.getScriptElements({
async: false,
defer: true,
}) as React.ReactHTMLElement<HTMLScriptElement>[];
const links =
webExtractor.getLinkElements() as React.ReactHTMLElement<HTMLLinkElement>[];
return webExtractor.collectChunks(
<IndexPage {...props} scripts={scripts} links={links} />,
);
};
IndexPage というSSR時に使うReactのコンポーネントがあります。コンポーネントのpropsに getWebExtractor() 内の getScriptElements() と getLinkElements() を実行して得られたscript要素とlink要素を渡しています。
propsに渡されるscript要素とlink要素は、ページの表示に必要なものだけ渡されます。
webpackの設定変更
Next.jsの 7ae76f4 時点のコミットを元にwebpackの設定ファイルにChunkの細分化の設定を追加しました。追加した設定は次の通りです。
const splitChunks = {
chunks: 'all',
cacheGroups: {
default: false,
vendors: false,
defaultVendors: false,
framework: {
name: 'framework',
chunks: 'all',
enforce: true,
priority: 30,
test: /[\\/]node_modules[\\/](react|react-dom|luxon|rxjs)[\\/]/,
},
lib: {
chunks: 'all',
priority: 20,
minChunks: 1,
reuseExistingChunk: true,
test(module) {
return (
module.context &&
module.size() > 140000 &&
/node_modules[/\\]/.test(module.identifier())
);
},
name(module) {
const rawRequest =
module.rawRequest && module.rawRequest.replace(/^@(\w+)[/\\]/, '$1-');
if (rawRequest) return rawRequest;
const identifier = module.identifier();
const trimmedIdentifier = /(?:^|[/\\])node_modules[/\\](.*)/.exec(
identifier,
);
const processedIdentifier =
trimmedIdentifier &&
trimmedIdentifier[1].replace(/^@(\w+)[/\\]/, '$1-');
return processedIdentifier || identifier;
},
},
shared: {
chunks: 'all',
priority: 10,
minChunks: 2,
reuseExistingChunk: true,
test(module) {
return module.context;
},
},
},
maxInitialRequests: 25,
minSize: 20000,
};
基本は [RFC] More granular default Webpack chunking · Issue #7631 · vercel/next.js や Improved Next.js and Gatsby page load performance with granular chunking で書かれている設定を踏襲しています。ただしABEMA Web向けに変更した点がいくつかあるため、その点について解説します。
frameworkに含めるライブラリ
ABEMA Webで使っているライブラリの中で基盤となるようなライブラリをframework chunkに含めています。
reactreact-domluxonrxjs
framework: {
name: 'framework',
chunks: 'all',
enforce: true,
priority: 30,
test: /[\\/]node_modules[\\/](react|react-dom|luxon|rxjs)[\\/]/,
},
libのmodule.size() > 140000の設定
Next.jsでは module.size() が160000 (160KB) より大きい場合は独立したchunkになるよう設定しています。
ただ160KBをそのまま閾値として使ってしまうとABEMA Webで使われている Immutable.js が別のchunkになりません(ちなみにABEMA WebではImmutable.jsを新規で書くコードには使っていません。Immutable.jsを使っているコードは負債になっています)。
なので、ABEMA Webでは140000 (140KB) より大きい場合に独立したchunkとすることでImmutable.jsを別のchunkにしています。
lib: {
chunks: 'all',
priority: 20,
minChunks: 1,
reuseExistingChunk: true,
test(module) {
return (
module.context &&
module.size() > 140000 &&
/node_modules[/\\]/.test(module.identifier())
);
},
...
}
default: false, vendors: falseの設定について
元々 Next.js側の設定と合わせていたものの、Next.js側の更新で設定が合わなくなった部分もあります。それが次に示す部分です。
{
default: false,
vendors: false,
defaultVendors: false,
}
この部分はNext.js上でwebpack 5を使うときに定義されていません。Next.jsではwebpack 5向けの設定が追加されて、sharedというgroupが無くなっていたり、デフォルトのキャッシュグループが有効化されていたりといった変更がありました。
improve splitChunks config for webpack 5
この変更は Clean up configuration – To v5 from v4 | webpack 内で次の通りdefaultとvendorsをfalseにするのは推奨しないと書かれています。
It was possible to turn off the defaults by setting
optimization.splitChunks.cacheGroups: { default: false, vendors: false }. We don’t recommend doing this, but if you really want to get the same effect in webpack 5:optimization.splitChunks.cacheGroups: { default: false, defaultVendors: false }.
Next.jsはこのwebpackのドキュメント上の記述に追従したと思われます。
ABEMA Webではまだdefaultとvendorsは無効ですが、機を見て検証したのちに有効化しようと思います。
esbuildの設定変更
ABEMA Webでは esbuild を導入しています。ちなみにesbuildを導入してどのような効果があったかについては ABEMAにesbuildを導入してWebのバンドル処理を69倍高速化した話 の記事でまとめているのでそちらをご覧ください。
現状Loadable Componentsは esbuild の plugin 機構を使って esbuild 向けのサポートをする予定はないそうです。
そのためなんらかの手段でLoadable Componentsを使うときに必要な loadable-stats.json を出力する手段をesbuild側に用意しないといけません。
ということで loadable-stats.json を書き出す関数を用意して、esbuildでビルドを実行するときに関数の実行をおこなうようにしました。それが次に示すコードです。
async function generateLoadableStats(filePath) {
const json = {
publicPath: '/',
namedChunkGroups: {
app: {
chunks: [],
assets: ['main.js', 'main.js.map'],
children: {},
childAssets: {},
},
'app-migration': {
chunks: [],
assets: [
'migration/main-migration.js',
'migration/main-migration.js.map',
],
children: {},
childAssets: {},
},
'app-mobile': {
chunks: [],
assets: ['main-mobile.js', 'main-mobile.js.map'],
children: {},
childAssets: {},
},
},
};
await fs.promises.writeFile(filePath, JSON.stringify(json));
}
コードを見てもらうと分かる通り、出力する loadable-stats.json 内では特にchunkの分割をおこなっていません。
これは先述したABEMA Webにesbuildを導入したという記事を見ていただけると分かるのですが、我々のesbuildの使い方としてはesbuildを本番環境では使わず開発者のローカル環境でのみ使うようにしています。そのため code splitting を使う意味があまりありません。なのでchunkの分割設定はありません。
適用した結果
ここまでChunkの細分化を取り入れた理由や実装方法について見てきましたが、ここからは実際にChunkの細分化を適用した結果を書きます。
期待した改善項目
まずChunkの細分化を導入した後に、改善を期待した項目について書きます。
Chunkの細分化はページ内で必要なコードのみを読み込み実行することで、JavaScriptの読み込み時間と実行時間を短縮し、ページ表示が早くなることを想定しています。
Improved Next.js and Gatsby page load performance with granular chunking の終盤にも書かれていますが、splitChunks.maxInitialRequests の値と splitChunks.minSize の値を適切に設定するとキャッシング効率が向上します。
これを踏まえて、この施策の適用後はCore Web VitalsでいうLCPやFIDといった指標が改善することを期待しました。
施策適用前後の様子をSynthetic Monitoringで見る
実際に適用前後でLCPやFIDが変わったかを見ていきましょう。今回は Lightkeeper というLighthouseを複数回実行して統計情報を出力するSynthetic Monitoring toolを使って計測します。
対象のページはトップページとなります。ただし検証した環境は次に挙げる条件があります。
- 自分のパソコン上でLightkeeperを実行しているため、同時に動いているソフトウェアなどの関係で値にブレが出ている可能性があります
- 検証した環境はテスト環境かつChunkの細分化を適用した前後の環境のため、現在の本番環境とは異なる点が多くあります
これらを了承の上、計測結果を見ていただけると幸いです。
計測結果: Largest Contentful Paint
まずはLargest Contentful Paintの結果から見ていきましょう。なお表の単位はミリ秒で、小数点以下第二位以下を切り捨てています。
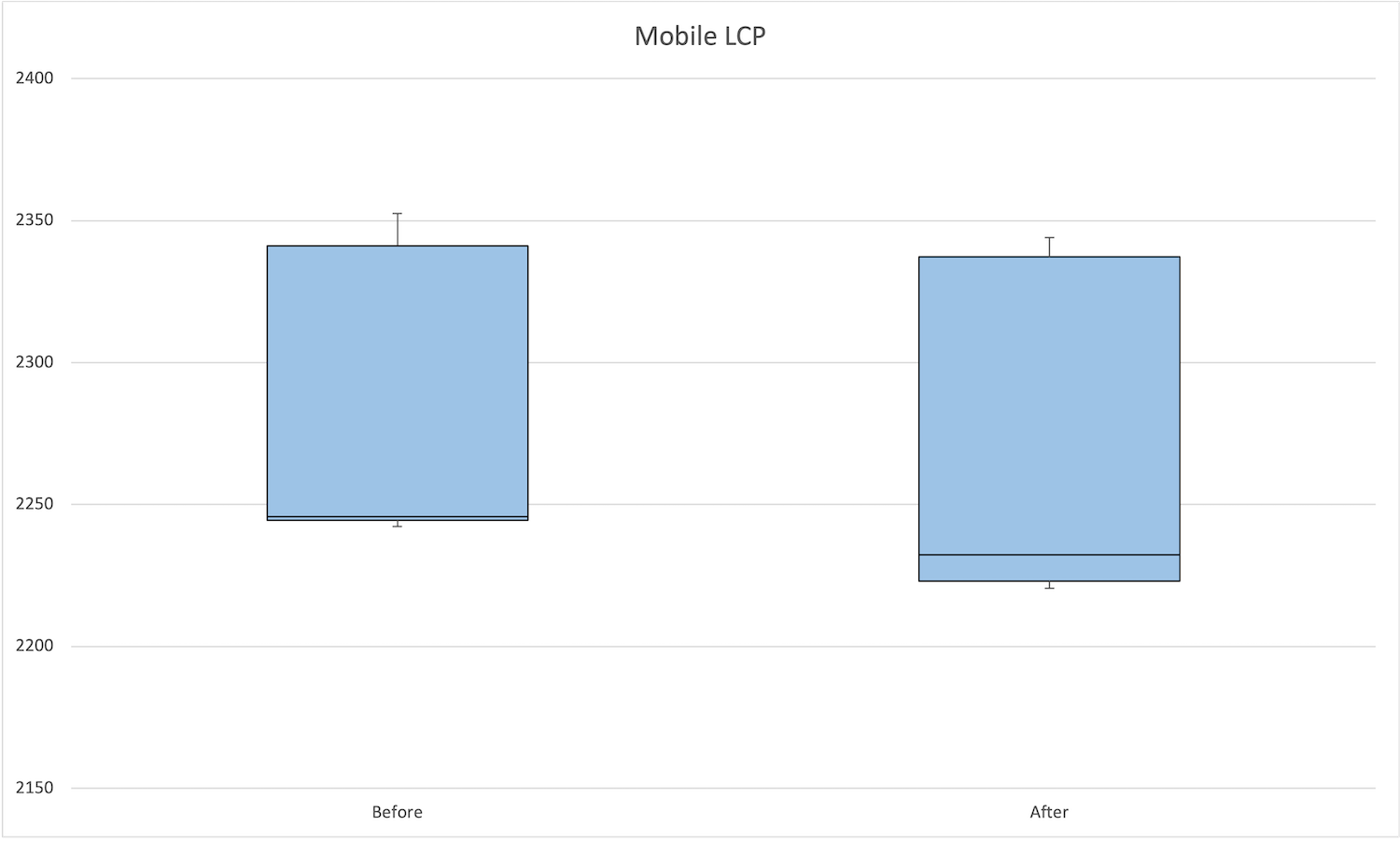
モバイル
適用前後を比較すると、中央値と最小値がわずかに改善されています。
| 状態 | 最大値 | 75パーセンタイル | 中央値 | 25パーセンタイル | 最小値 |
|---|---|---|---|---|---|
| 適用前 | 2352.5 | 2341.1 | 2245.7 | 2244.4 | 2242.2 |
| 適用後 | 2344 | 2337.2 | 2232.2 | 2223 | 2220.4 |
モバイルのLargest Contentful Paintの箱ヒゲ図は次の通りです。
デスクトップ
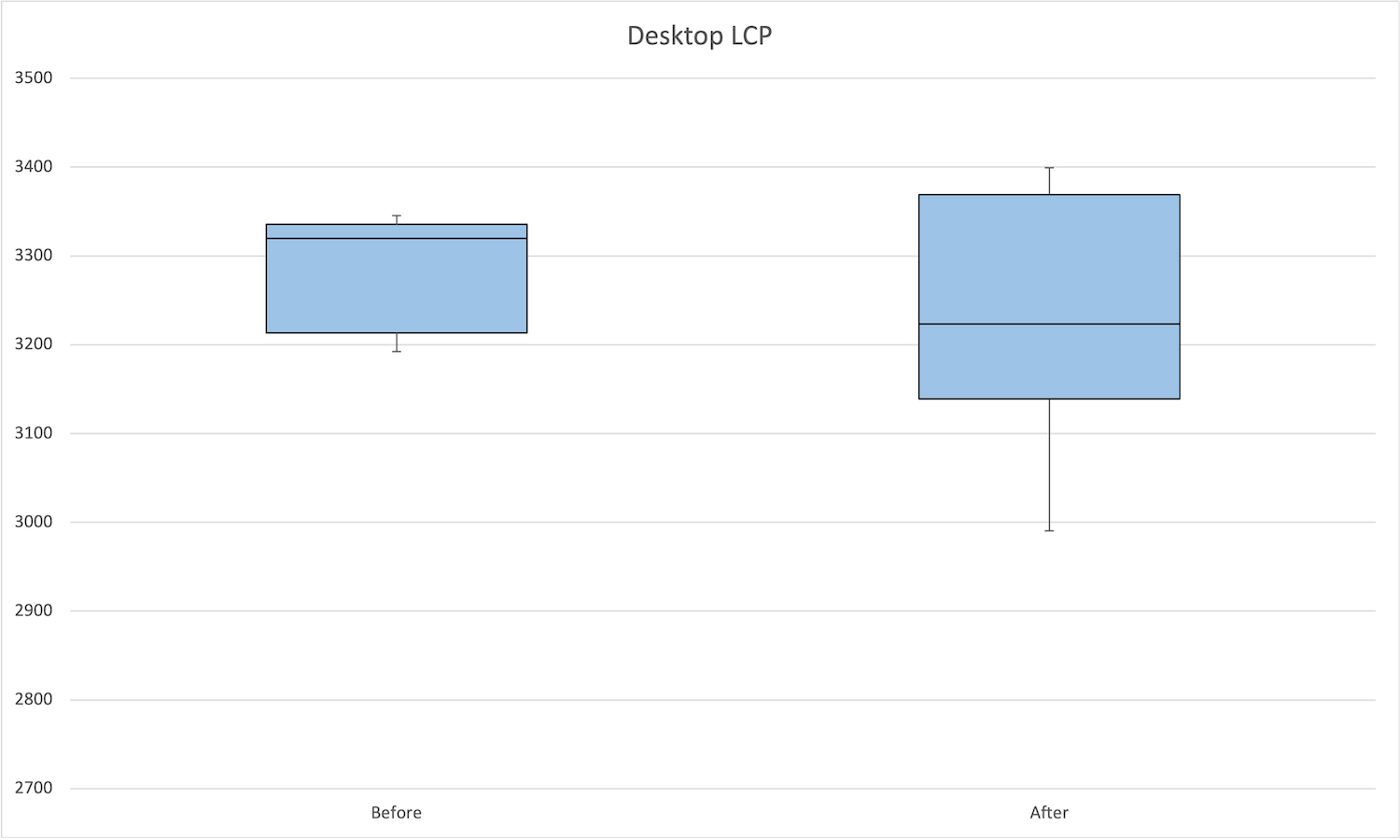
適用前後を比較すると、中央値が約100ms下がり、最小値は約200ms下がっています。
| 状態 | 最大値 | 75パーセンタイル | 中央値 | 25パーセンタイル | 最小値 |
|---|---|---|---|---|---|
| 適用前 | 3345.3 | 3335.4 | 3319.5 | 3213.2 | 3192.2 |
| 適用後 | 3399 | 3369.1 | 3223.6 | 3138.7 | 2990.7 |
デスクトップのLargest Contentful Paintの箱ヒゲ図は次の通りです。
計測結果: Total Blocking Time
次にTotal Blocking Timeの結果から見ていきましょう。こちらも同様に表の単位はミリ秒で、小数点以下第二位以下を切り捨てています。
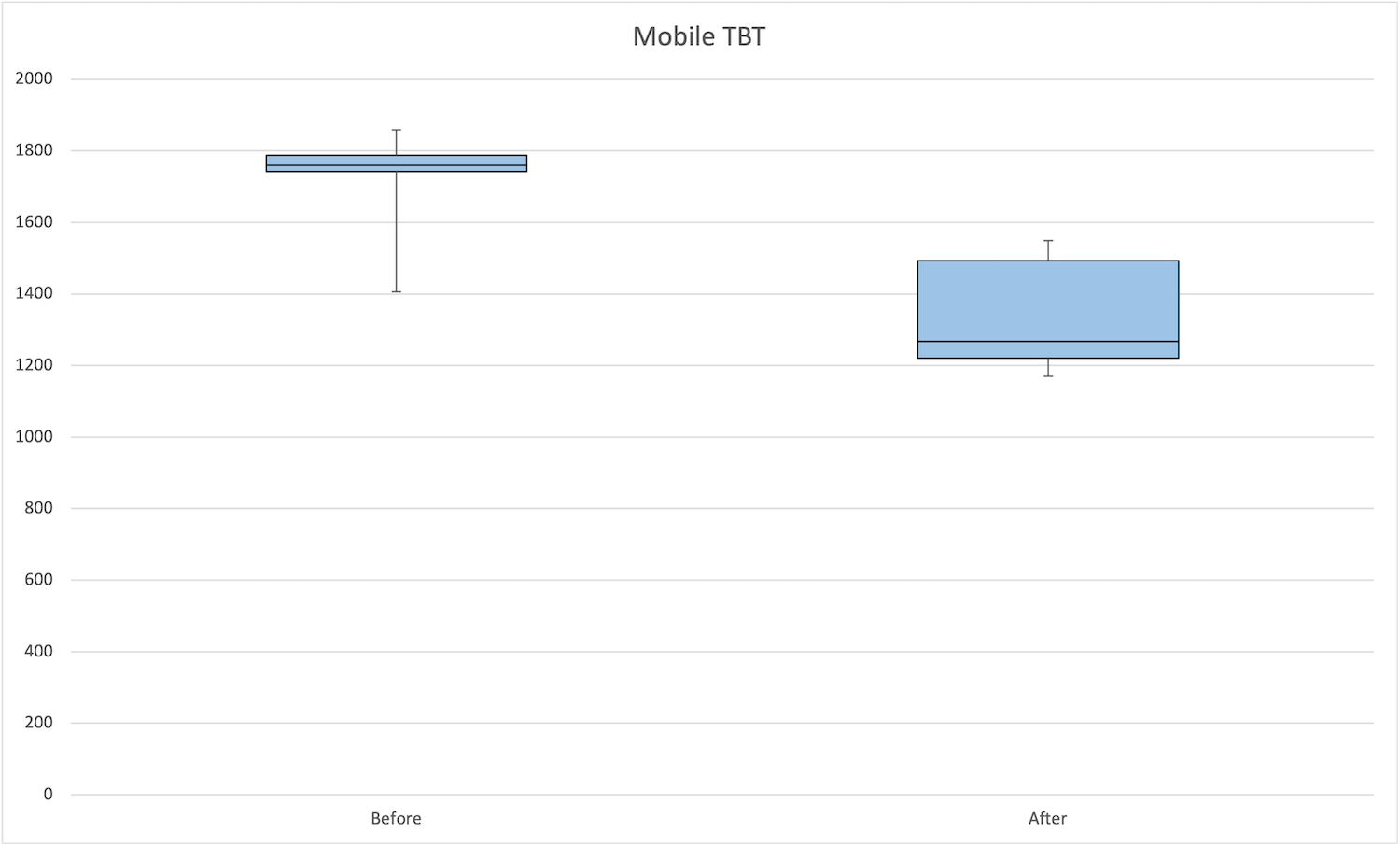
モバイル
適用前後を比較すると、全体的に大幅改善しています。中央値は約500ms下がっています。
| 状態 | 最大値 | 75パーセンタイル | 中央値 | 25パーセンタイル | 最小値 |
|---|---|---|---|---|---|
| 適用前 | 1859 | 1788 | 1759.8 | 1741.5 | 1405.5 |
| 適用後 | 1548.8 | 1493.3 | 1267 | 1220 | 1170 |
モバイルのTotal Blocking Timeの箱ヒゲ図は次の通りです。
デスクトップ
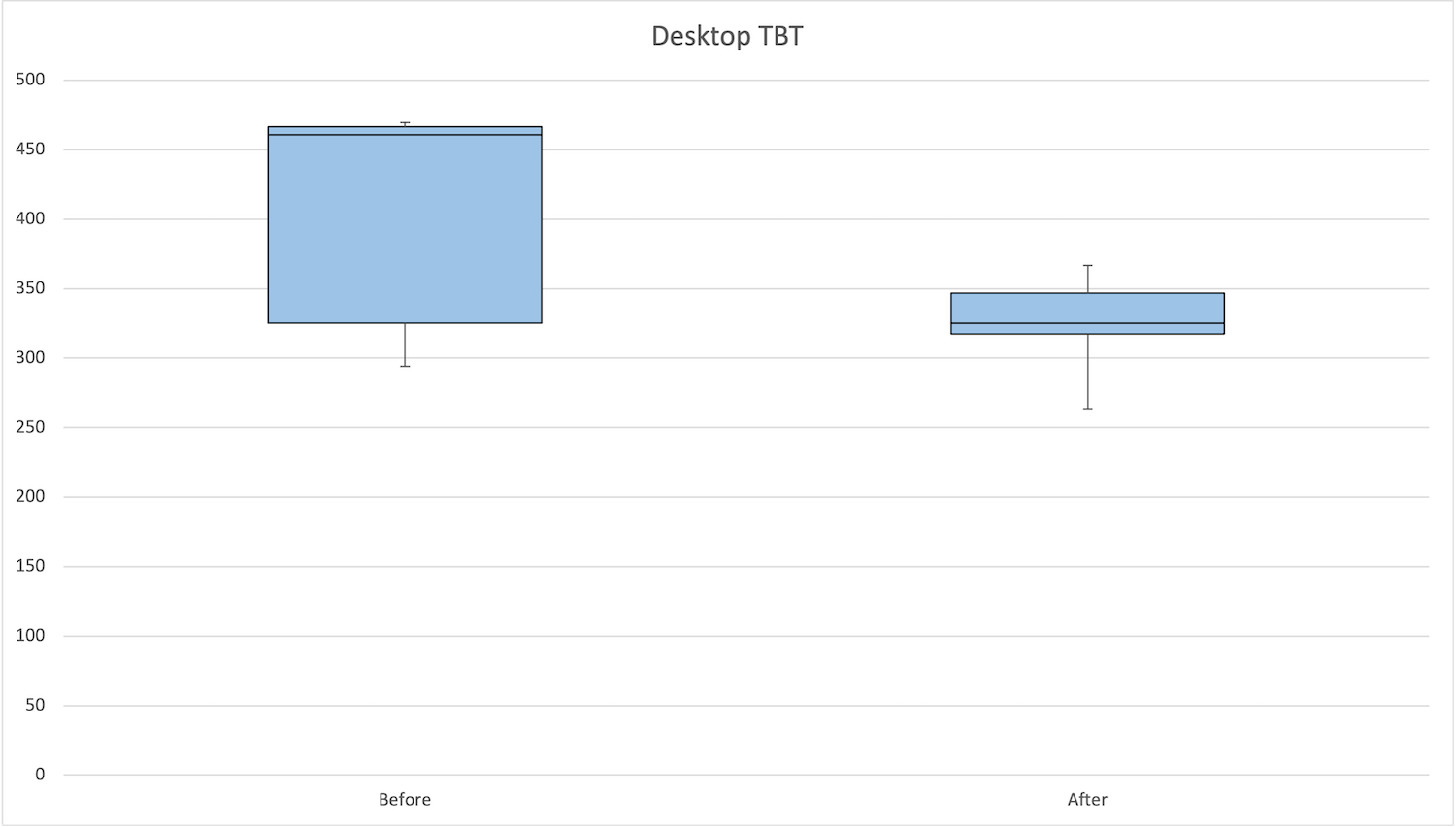
適用前後を比較すると、全体的に大幅改善しています。中央値は約140ms下がっています。
| 状態 | 最大値 | 75パーセンタイル | 中央値 | 25パーセンタイル | 最小値 |
|---|---|---|---|---|---|
| 適用前 | 469.5 | 466.5 | 460.9 | 325.3 | 294 |
| 適用後 | 366.8 | 346.6 | 325 | 317.5 | 263.5 |
デスクトップのTotal Blocking Timeの箱ヒゲ図は次の通りです。
Real User Monitoringの結果について
ここまでSynthetic Monitoringの結果を見てきましたが、Real User Monitoring (RUM) の結果はどうなのかと気になったかもしれません。
もちろん計測していないということは無く、Chunkの細分化を適用するにあたってChunkの細分化を適用している群としていない群でA/Bテストをおこないました。その時の結果は次の通りです(値の単位は秒、計測指標はコンポーネントの描画が終わった時)。
iOS
| 種類 | 平均値 | 中央値 | 最小値 | 最大値 | 標準偏差 |
|---|---|---|---|---|---|
| 非適用 | 2.32481314970401 | 2.27 | 0.4 | 4.39 | 0.727874818992531 |
| 適用 | 2.3547623693266 | 2.3 | 0.43 | 4.74 | 0.743580475668322 |
Android
| 種類 | 平均値 | 中央値 | 最小値 | 最大値 | 標準偏差 |
|---|---|---|---|---|---|
| 非適用 | 3.94758314452637 | 3.86 | 0.1 | 7.96 | 1.30518158208065 |
| 適用 | 4.0432780682178 | 3.95 | 0.09 | 7.88 | 1.35002960179113 |
PC
| 種類 | 平均値 | 中央値 | 最小値 | 最大値 | 標準偏差 |
|---|---|---|---|---|---|
| 非適用 | 3.31212332005449 | 3.13 | 0.1 | 7.86 | 1.42658748233996 |
| 適用 | 3.38707323921253 | 3.21 | 0.1 | 7.41 | 1.45148269488342 |
データを見ると適用後は平均値と中央値が上がっています。ただ最小値と最大値は減少しているのと、標準偏差が大きくなっていることからデータのばらつきが大きくなったという感じです。
サンプルの数は大きいため1ユーザーの結果は大きく影響しないと考えられます。とはいえ多種多様な機器のスペックや通信速度、またバックグラウンドで動いているアプリの数などさまざまな変数が存在するため、データにばらつきが出たと考えられます。
ただ平均値と中央値が上がったとはいえ直帰率などの指標に影響があまり見られなかったこと、速度が改善している環境もあることから、速度が悪化した環境を今後調査し改善をすることを前提にChunkの細分化を全適用することにしました。
まとめ
Next.jsのChunkの細分化を参考に、Loadable Componentsを用いてABEMA WebでもChunkの細分化をおこないました。
ABEMA Webの構成を見直しつつ、Loadable Componentsをどのように活用するか試行錯誤したので、計画から実際の改善をするまで半年かかりましたが、その分パフォーマンスが向上したり、ABEMA Webで技術的負債になっていた部分を改善できたりといった効果がありました。
この記事がWebアプリケーションに対するChunkの細分化実装の参考になれば幸いです。