

3月24日、サイバーエージェントのエンジニア・クリエイターによる技術カンファレンス「CyberAgent Developer Conference 2022」を開催しました。本記事では、AI Lab のリサーチマネージャ・山口による「AI Labの進めるクリエイティブ自動生成の研究」の模様をお届けします。本講演では、AI Labのクリエイティブ研究チームの取り組みと、クリエイティブ自動生成で考えるべきことに加え、国際会議での発表成果、今後の研究についてお話ししました。
目次
■AI Labクリエイティブ研究チームの取り組み
■クリエイティブ自動生成において考えるべきこと
■研究成果1:テキストのベクタ再構成
■研究成果2:デザインテンプレートの自動生成
■研究成果3:ユーザーによるレイアウト生成の制御
■これからのクリエイティブを支える技術
■おわりに
AI Labクリエイティブ研究チームの取り組み
まず、AI Labのクリエイティブ研究チームの取り組み全体像についてご紹介します。AI Labのクリエイティブ研究チームでは、サービス開発から独立して研究開発をしています。学術分野としては、機械学習、画像認識、自然言語処理、音声信号処理などの領域です。例えば、広告効果の予測や、クリエイターが制作をする際の支援になるような技術などを開発しています。
●研究事例:広告効果を機械学習で予測
AI Labの研究事例を1つご紹介します。例えば、以下のスライドにあるように、バナー画像などのクリエイティブを入力して、その広告効果を事前に予測するという機械学習モデルの構築に取り組んでいます。
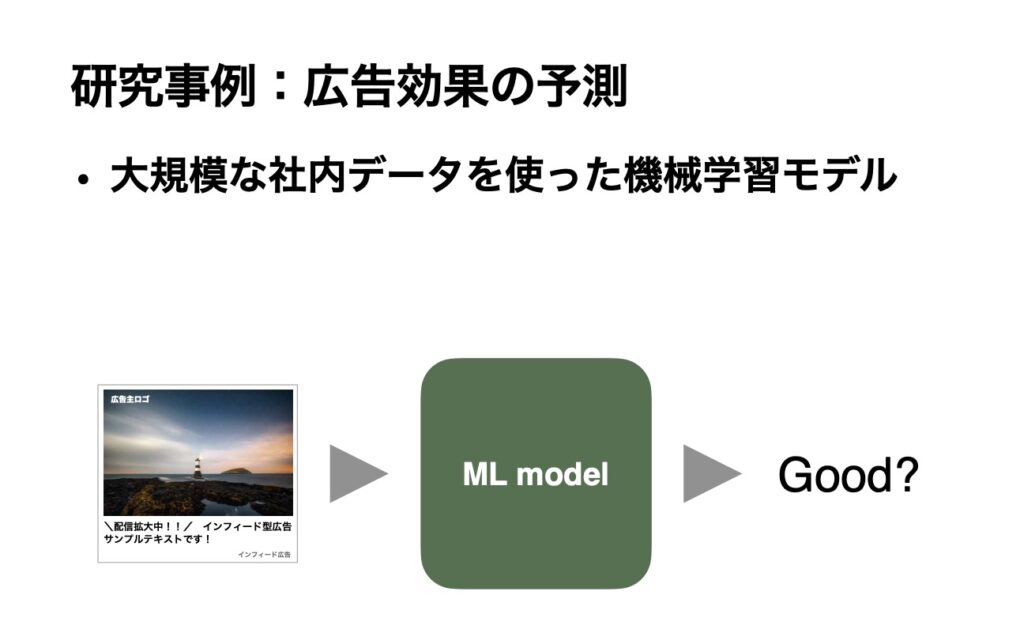
研究成果は実際のプロダクトにも反映されており、例えば、広告効果の予測モデルの応用として「極予測AI」や「極予測TD」といったサービスで機械学習モデルを活用しています。広告効果を事前に予測することが出来れば、デジタル広告の運用において大きなアドバンテージとなります。

クリエイティブ自動生成において考えるべきこと
次に、クリエイティブ自動生成において考えるべきことを整理します。
●画像の自動生成の現在
自然言語処理分野において、テキストの自動生成は既に実用に近いレベルまで達しているのに対して、画像を用いたクリエイティブの自動生成については、現時点でも技術的なハードルがまだ存在します。
下記のスライドは、最先端の画像自動生成技術の例です。「Bananas sold in the market」という文章を入力すると、右の絵が出力されます。確かにバナナがマーケットで売られているという絵が出てきますが、そのまま広告クリエイティブとして使える品質には達していません。

●ラスタ形式とベクタ形式
もう1つ大事な点が、データ形式です。既存の画像生成のモデルの多くは、ラスタ形式と呼ばれる形式で画像を生成します。ラスタ形式とは、一つ一つの点を並べる形で画像を表現する形式です。
クリエイティブ生成におけるラスタ形式の問題としては、まず画像の解像度が固定されていることがあげられます。ラスタ形式では、下記スライドの左にあるように、「Typography」と書いてある文字を拡大するとぼやけてきます。また、後から編集することも困難です。
実際にクリエイティブを制作をする際に使われるフォーマットは、ベクタ形式で、SVGやPDF、あるいはPower Pointのようなドキュメントの形式があります。
ベクタ形式の利点としては、解像度に依存しないフォーマットで書かれているので、文字を拡大しても、ぼやけることなくくっきりとした文字が描画されることです。

このような背景から、AI Labではベクタ形式での画像生成技術に取り組んでいます。機械学習のモデルによって、構造を記述するドキュメントを生成するという手法によって、解像度に依存せず美しい画像表現が可能となり、さらに後から人手で再編集できるようにもなるのです。
■研究成果1:テキストのベクタ再構成
ここからは近年、国際会議に発表した研究成果3つについてご紹介します。
1つ目が九州大学との共同研究の成果「テキストのベクタ再構成」で、2021年にコンピュータビジョン分野のトップカンファレンス「ICCV」にて発表を行いました。
AI Lab、コンピュータビジョン分野のトップカンファレンス「ICCV」にて共著論文採択 画像に描画済みのテキストが再編集可能となる手法を提案
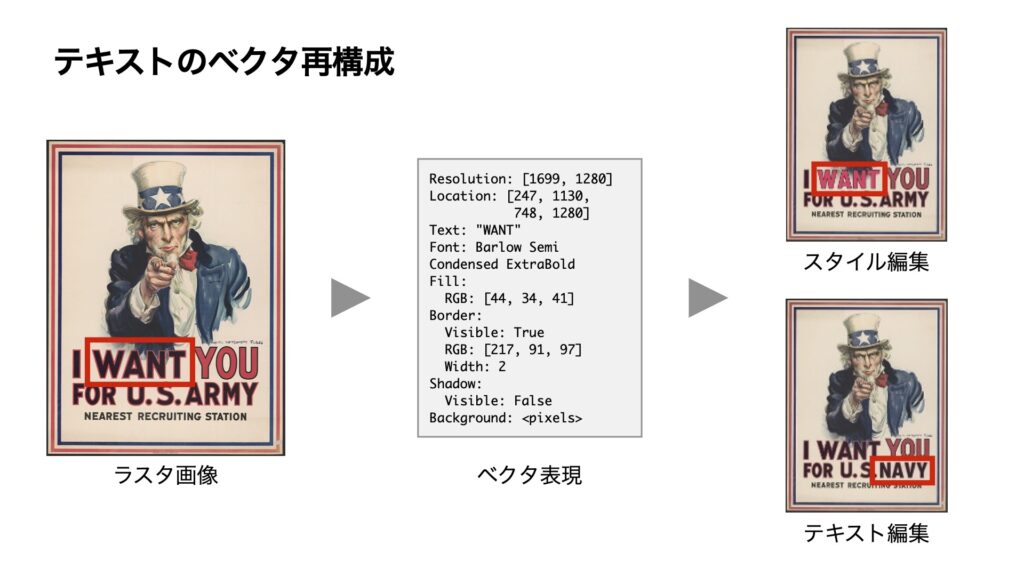
本研究では、テキストのベクタ再構成に取り組みました。下記スライドの左にあるようなポスター画像を入力した際に、テキスト部分だけをベクタ構造のドキュメントとして再構成するという技術です。
例えば「WANT」という文字の位置やフォント、大きさ、装飾などを、ドキュメントの中のベクタ形式の構造データとします。ベクタ形式であれば、スタイルを変えたり、テキストの中身そのものを書き換えるといった編集が容易に叶います。
●ベクタ再構成で可能になるワークフロー
ベクタ再構成によって可能になるクリエイティブ作成のワークフローを考えてみましょう。まず、既存デザインの再利用やアセット化が可能になります。
これまで一般的には、広告クリエイティブというものは配信されて一度限りというケースが多数でした。これに対して、ベクタ再構成の技術を用いることで、ラスタ化されたクリエイティブ表現が再利用でき、効果の高いクリエイティブの再現性が高められます。
また、ラスタ化してしまったデザインを微調整することで、解像度に依存しない編集が可能になるということも、大きなポイントです。
●ベクタ化への課題
ベクタ化には3つの課題がありました。

1つは、テキストを検出して認識するOCRと呼ばれる文字認識の技術です。これを適切に扱わないと、テキストをベクタ化できません。
2つ目が、テキストがどのようなスタイルになっているかの認識です。フォントや色、飾りといったことを認識するのは、スタイル認識と呼ばれているタスクです。
3つ目が、背景を推定するというタスクです。テキストのベクタ化に成功しても、背景を推定しないと、後ろに書かれた文字が残ってしまうので、それを除去する技術が必要になります。
●テキスト再構成モデル
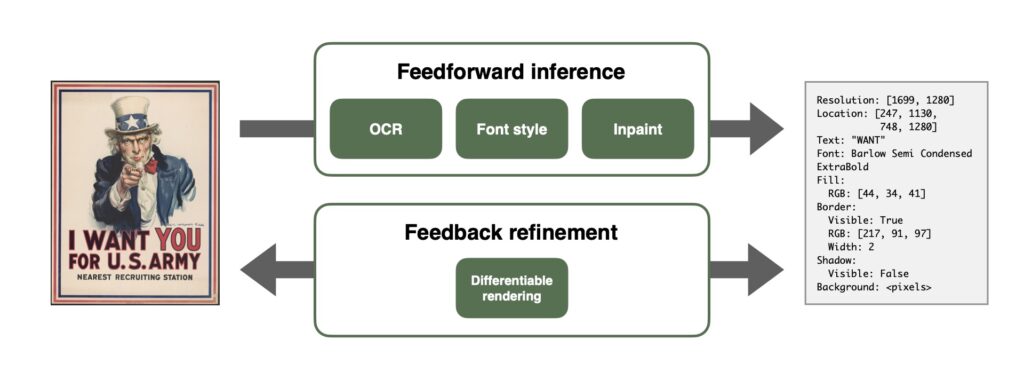
本研究で作ったモデルが下記です。大きく分けると2つのモジュールに分かれたディープラーニングのモデルを開発し、テキストの再構成に取り組みました。
1つ目が、Feedforward inferenceと呼ばれるディープラーニングのモデルです。入力のラスタ画像に対して、OCR、スタイルの推定、背景の推定ができるモデルを作りました。
2つ目が、Feedback refinementというベクタ化した後の情報を使って、さらに再描画したときのズレを修正するようなモジュールも作りました。
下記スライドがその例です。左側が入力のラスタ画像に描かれている文字、右側がベクタ形式に再構成したものです。かなり精緻にフォントや色を再構成していることが見て取れます。

●テキスト再構成の応用例
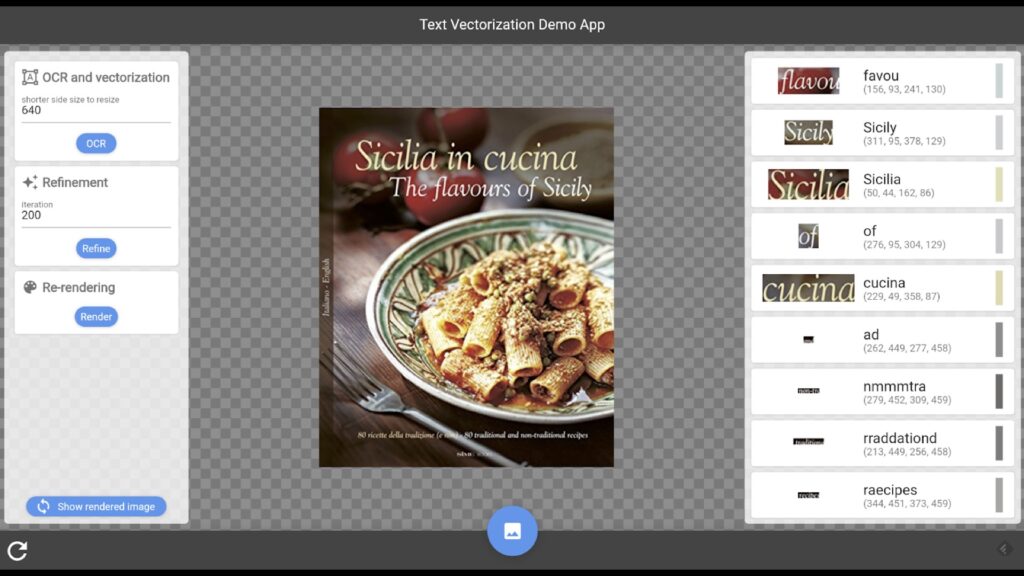
この技術を実際に動かせるWebのデモアプリも社内向けに開発しています。真ん中の本の表紙画像から、文字の部分をベクタ化して右側の列に表示するというUIです。
現時点では、1つの画像を処理するのに3分程度かかりますが、今後簡単に利用できるような形で開発を進めています。
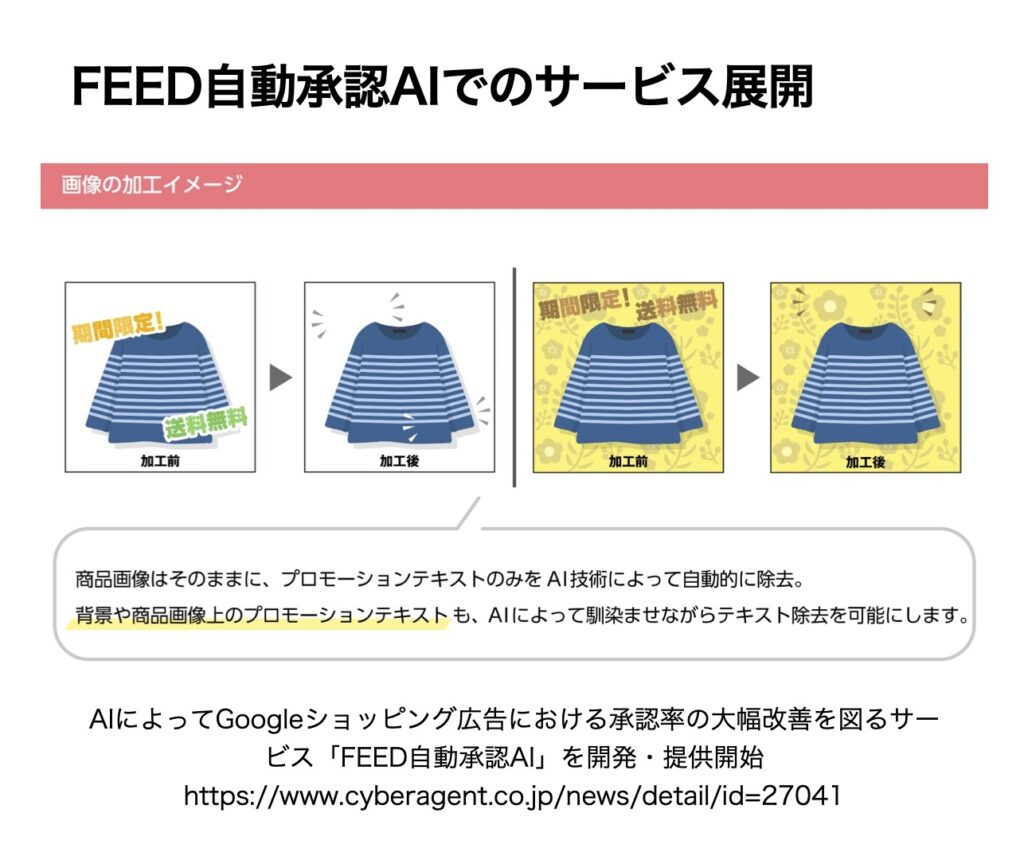
この研究成果を実際のプロダクトへ導入したのが、昨年12月にリリースした「FEED自動承認AI」です。
これはGoogleショッピング広告における承認率の改善を図るとともに、インプレッション数を最大化させるサービスです。
ここでは、商品画像の文字数が多すぎるといった理由で不承認になるケースに対応するため、文字が多すぎた場合には広告画像中の文字を自動で消して承認されるようにする、といったワークフローを自動化する部分に、この研究成果を活用しています。
■研究成果2:デザインテンプレートの自動生成
2つ目の研究成果は、「デザインテンプレートの自動生成」です。こちらも昨年、国際カンファレンス「ICCV」で採択されました。
AI Lab、コンピュータビジョン分野のトップカンファレンス「ICCV」にて主著論文採択 グラフィックデザイン自動生成手法を提案
これは、ベクタ形式のデザインテンプレートを自動生成するという研究です。デザインテンプレートとは、例えば文字や画像を差し替えてすぐに、新しいデザインを作ることができるドキュメントのことです。こうしたデザインテンプレートを機械学習モデルを使って生成するという研究に取り組みました。
●デザインテンプレート自動生成の利点
ベクタ形式でデザインテンプレートを自動生成できることの利点を見てみます。まず、自動的に生成されたテンプレートをシードとして、デザイナーが再編集できることで、無限にデザインテンプレートを作成することが可能です。加えて、解像度に依存しない画像生成という面でも興味深い研究です。
●モデリングとドキュメント生成モデル
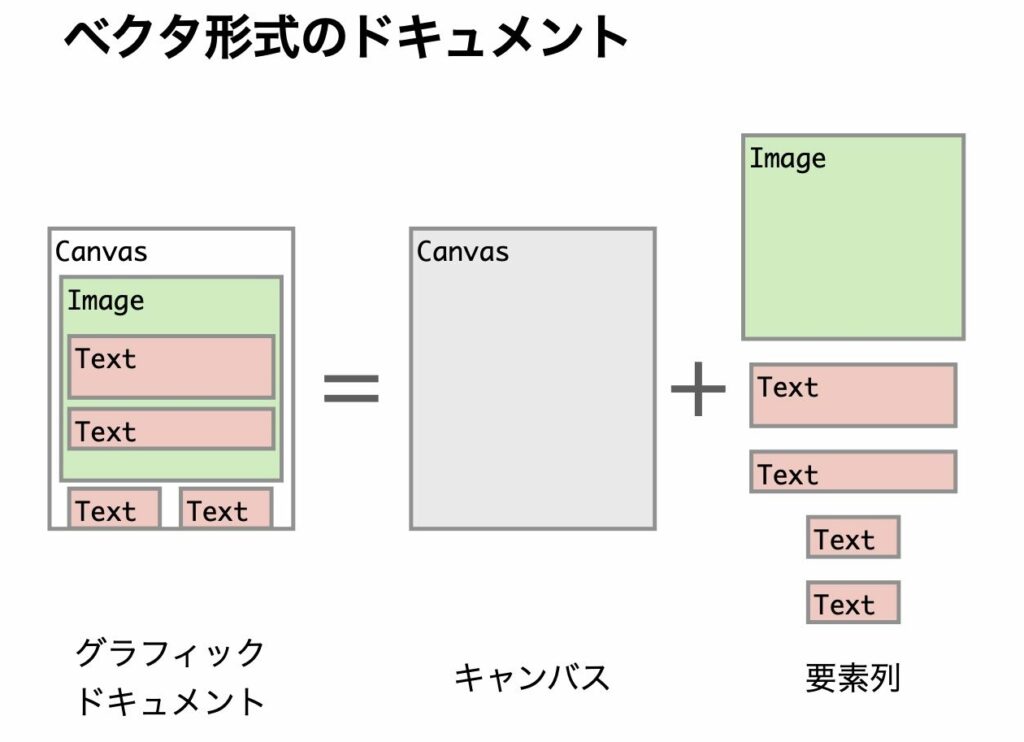
グラフィックドキュメントは下記のように扱っています。実際に画像を描画する対象となるキャンパスの面に、画像やテキストなどさまざまな要素を上に重ねていくというレイヤー構造で、ベクタ形式のドキュメントをモデリングしています。
これを機械学習のモデルに入れていきます。キャンバスや画像、テキストなど、たくさんあるデータをシーケンス(列)としてみなし、この列を取り扱う機械学習のモデルで生成することに挑戦しました。
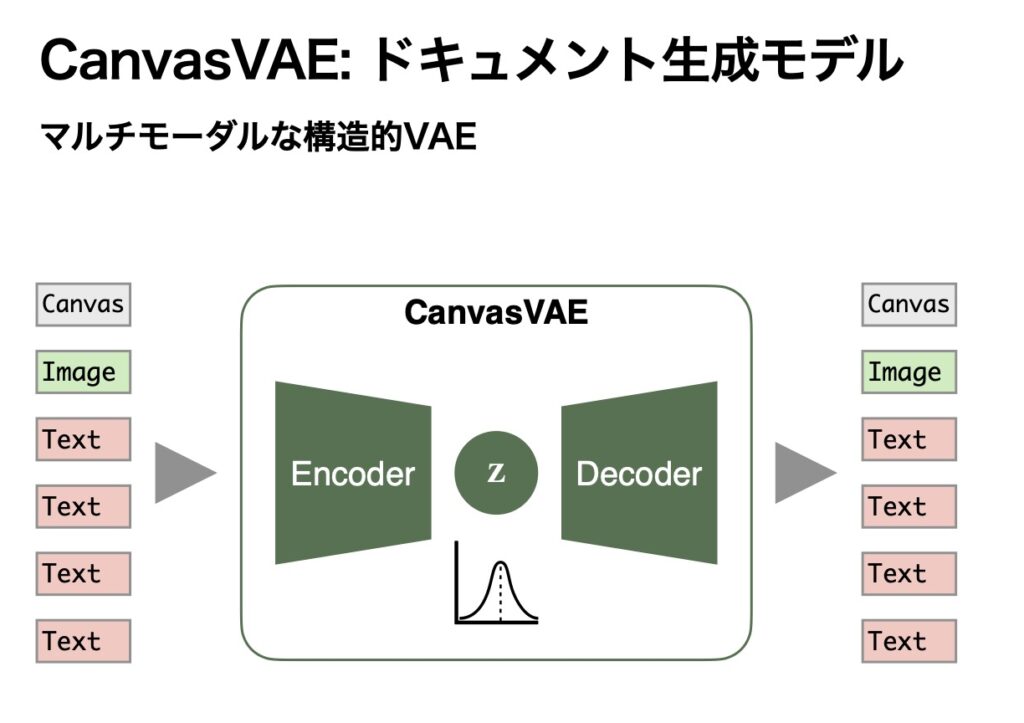
中身は、マルチモーダルな構造のVAE(Variational Autoencoder)と呼ばれる機械学習のモデルを使っています。ざっくり説明すると、与えたドキュメントをEncoderと呼ばれるモジュールにより、1つの数値的な表現(下記の図中z)に落とし込みます。その数値的な表現から、今度はDecoderを使って再びドキュメントに戻します。このようなモデルを使うことで、ドキュメントの生成を可能にするということに取り組みました。
●デザインテンプレートの自動生成の成果
下記スライドがランダム生成されたデザインのサンプルです。左側が、実際に画像やテキストの入っているもので、右にある色分けされたマップが、どんな要素が配置されているかを可視化したものです。
これを見ると、生成されたものをそのままバナー作成に活用することは、まだ難しそうです。但しこれらはすべてベクタ形式で容易に再編集できるので、これらのデザインをシードにして新しいデザインに取り組むといったことは実現可能です。

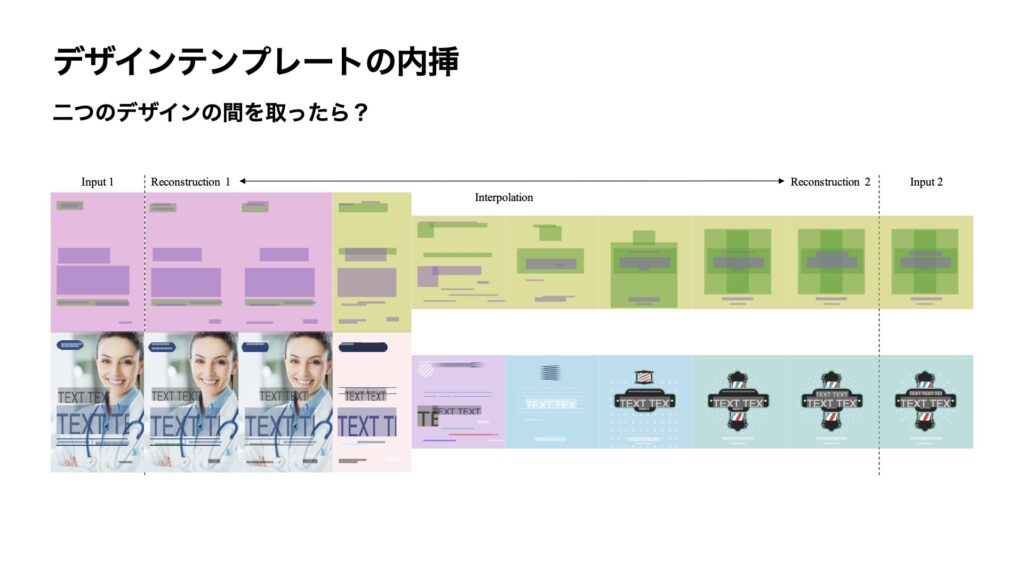
また、今回作成したモデルを使うと、2つのデザインの間をとるというような生成も可能になります。下記のスライドでは、一番左側にあるデザインと一番右側にあるデザインから、その間のデザインをとったらどうなるかを試してみた生成の結果です。間をとると、なんだかよく分からないデザインができてしまいますね。ただし、少しずつ左側のデザインが右側のデザインに近づいていくようなものを生成できることがわかります。
●クリエイティブ自動生成の現在と展望
クリエイティブ自動生成技術について、品質面でまだまだやるべきことがたくさんありますが、本研究によって、そもそも原理的に自動生成が可能であることを実証できたことが大きな成果だと思っています。私たちがこの研究テーマに取り組む以前は、世の中でグラフィックドキュメントを自動生成するような手法というものは存在しませんでした。
今後は、実用化に向けてさまざまな品質を向上するための施策に取り組んでいきます。例えば、データセットを拡充したり、モデルそのものを改善することで、より高品質なデザインを自動的に生成する日が来ると信じています。
■研究成果3:ユーザーによるレイアウト生成の制御
最後は「ユーザーによるレイアウト生成の制御」に関する研究です。これは早稲田大学と共同研究しているテーマで、昨年、マルチメディア分野のトップカンファレンス「ACM Multimedia」で共著論文が採択されました。
AI Lab、マルチメディア分野のトップカンファレンス「ACM Multimedia」にて共著論文採択 ー最適化による制約を満たしたレイアウトの生成手法を提案ー
本研究では、機械学習のモデルでレイアウトを生成したあと、ユーザーの指示によって自動的に修正する方法について取り組みました。例えば、テキストの位置をもっと上に動かしたいとか、隣のテキストと揃えてほしい、といった注文を反映して自動生成するというものです。ここで使った手法を私たちはCLG-LOと呼び、これは制約付きの最適化による生成制御をしています。
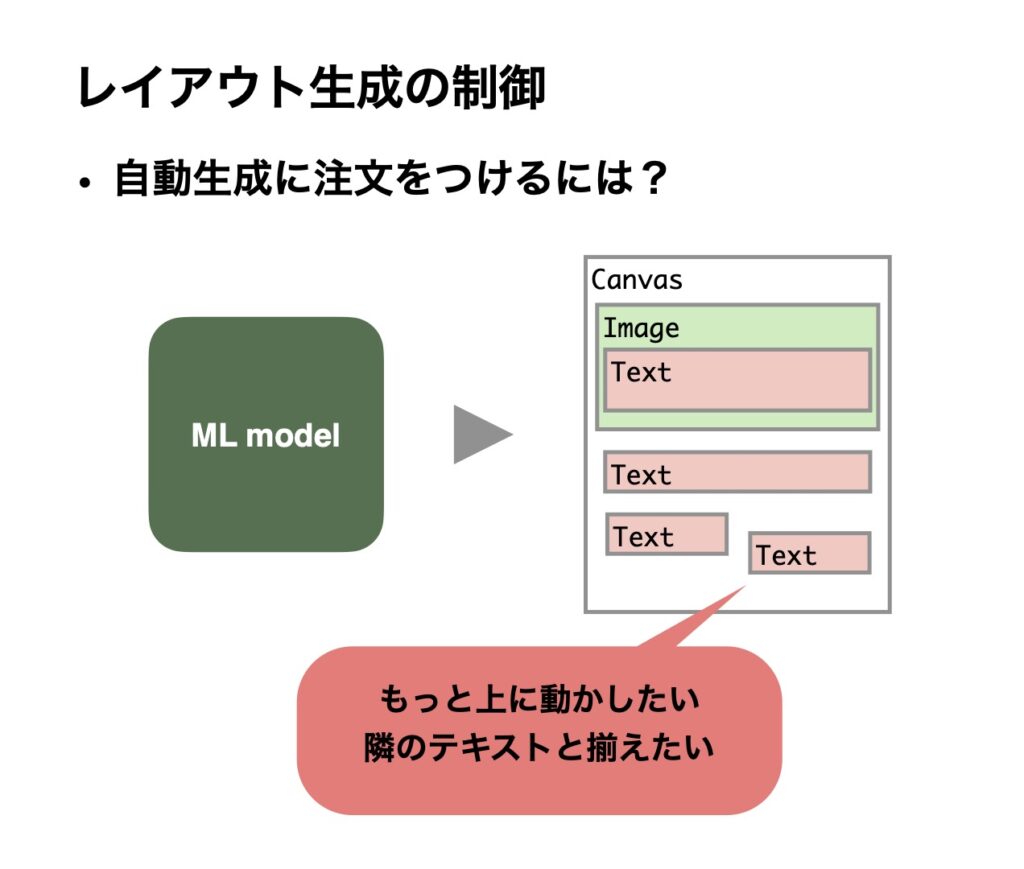
●制約付き最適化による生成制御
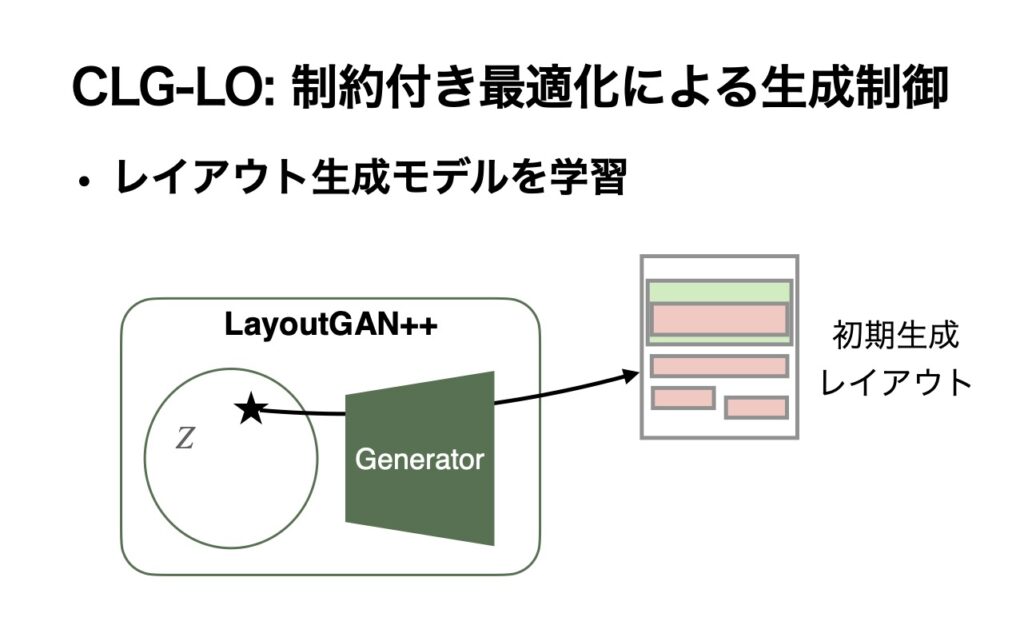
本研究では、まず最初にレイアウトの生成モデルに取り組みました。ユーザー指示による修正をするためには、その前に何らかのレイアウトを機械学習のモデルで生成しないといけません。まずは、大量のデータを使って自動的にレイアウトを生成します。
ここでは、LayoutGAN++という手法を使いました。何らかのシードとなるような数値表現から、Generatorと呼ばれるニューラルネットワークを介して、レイアウトを出力するモデルです。
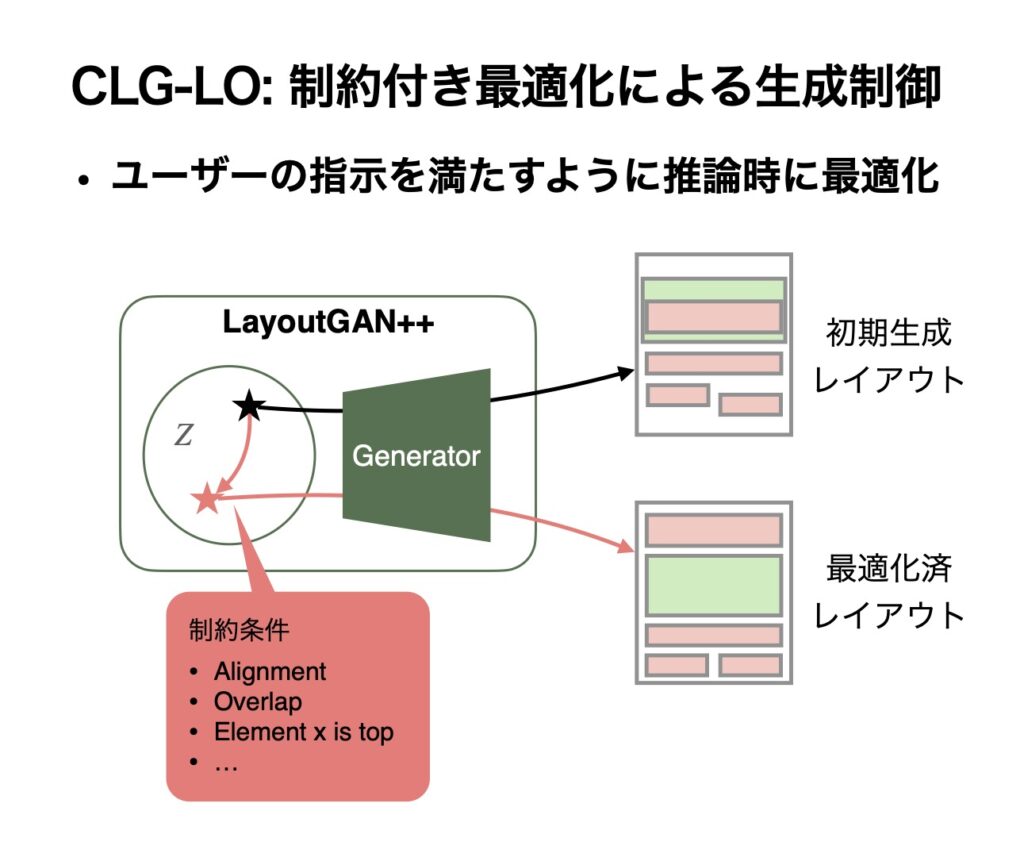
このモデルを今度は、要素を揃えてほしい、要素の重なりを減らしてほしい、この要素は別の要素の上に置いてほしい、といったユーザーの指示を満たすように変更することを考えます。そのために、一旦学習したモデルのシードを動かすことで、成約を満たすように生成する、という手法を提案しました。
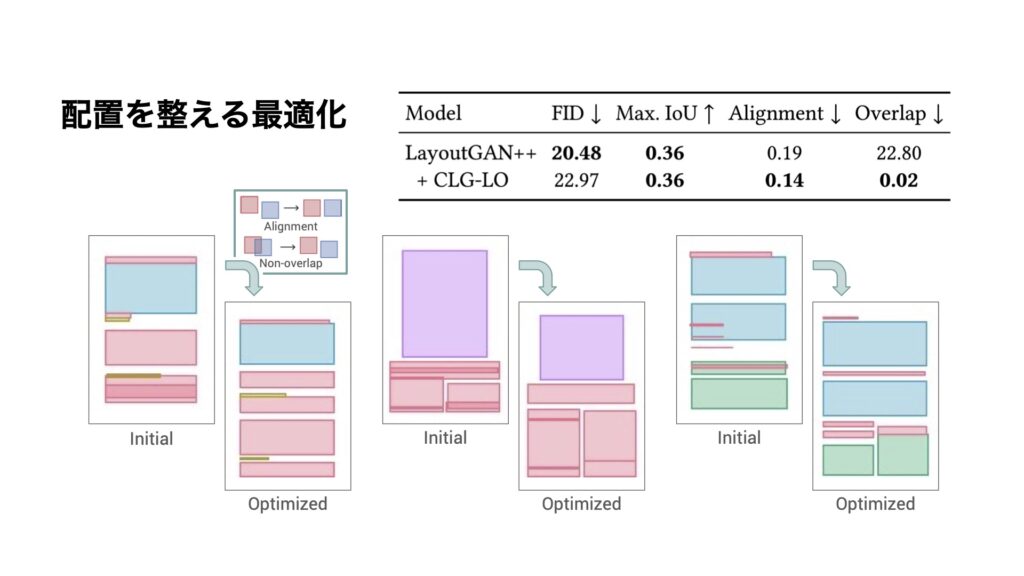
例えば、何らかのレイアウトを生成してあまり良くなかった結果を、下記のスライドのInitialとします。これに対して、例えば重なりをもうちょっと直してほしいというような指示を入れることで、その隣にあるOptimizedと表示されている結果に直すということが可能になります。
●自動生成と人間の協調
AI Labの一連の研究では、自動生成した後に人手で修正することを想定しています。しかし、機械学習のモデルによってランダムに自動生成したものを毎回人手で修正するとなると、結局工数がかかってしまいます。
そこで、より人間と協調する形で自動生成ができることを目指したのが、この研究です。人とAIで協調するようなワークフローを作ることで、クリエイターがより生産性高くクリエイティブを作成できる世界を期待し、研究開発を進めています。さらに将来的には、バナーやランディングページの制作などにも応用していきたいと考えております。
■これからのクリエイティブを支える技術
最後に、AI Labから見た、これからのクリエイティブを支える技術についてお話します。
●最近の研究トレンド
私たちが、最近の研究トレンドで注目しているものが2つあります。
1つ目が、事前汎化学習と下流タスクと呼ばれているものです。大きな深層学習のモデルを、大量のデータから作ることで、あらゆるタスクに使える機械学習モデルを作ってしまおう、というものです。事前汎化学習のモデルの例に、GPT-3やCLIPがありますが、文章や画像を生成する分野で、すでに目覚ましい品質を実現しています。
2つ目が、マルチモーダルと呼ばれているデータ構造をまたぐ手法です。最近では、あらゆるデータ構造に対して非常に扱いやすい、Transformerと呼ばれるニューラルネットワークの構造が提案されてきています。画像やテキスト、音声など、あらゆる種類のデータを統一して記述することができるようなアーキテクチャで、広告のように画像や文字、動画、音声など、さまざまなフォーマットのデータを統一して扱うのに使えます。今後はこういったモデルが流行るだろうと注目しています。
●クリエイティブ技術の強化戦略
上記のような研究トレンドをふまえ、AI Labがクリエイティブ技術を強化していく戦略として、2点が考えられています。
1つ目が、汎用モデルの流れです。社内に持っている大規模なクリエイティブデータから、あらゆるクリエイティブ生成タスクに使える汎用モデルを作ってしまう、といったことに取り組みたいと考えています。これにより、バナーでもテキスト広告でも動画広告でも、さまざまなフォーマットに対して、事前に一つ大きなモデルを作ってしまえば対応できる、ということを想定しています。
2つ目として、ベクタグラフィックの構造のための機械学習を追及していきたいと思っています。研究例としてご紹介した、テンプレートの自動生成や、ユーザーの指示に従うような生成手法は、ベクタグラフィック構造に関する研究です。この分野をより進化させることで、例えば動画広告のようなところにも柔軟にベクタグラフィックの構造の考えを使って、機械学習モデルを活用していけるようになるのではないかと考えています。
おわりに
AI Labでは研究開発のインパクトを最大化することを強く意識しています。リサーチの成果を、開発者や、ビジネス、クリエイターなど、さまざまな関係者に向けて、インパクトが出るような形で今後も研究開発を進めていきます。
「CyberAgent Developer Conference 2022」のアーカイブ動画・登壇資料は公式サイトにて公開しています。ぜひご覧ください。

https://cadc.cyberagent.co.jp/2022/
AI Labでは最新技術を駆使し事業の成長を牽引できる仲間を募集しています。同時に、博士インターンシップ2022も募集中です。詳しくは採用情報ページをご覧ください。
https://cyberagent.ai/ailab/careers/