
タップルで機械学習エンジニアをしている橋爪( @runnlp )と、AI Labでリサーチサイエンティストをしている冨田( @miitomi )です。9月18日から9月23日にシアトルで開催されたRecSys2022に現地参加してきましたので、その参加報告をさせていただきます。今回サイバーエージェントAI LabからはIndustryセッションでポスター発表を1件、Workshopで口頭発表を1件行いました。Industryセッションでの発表の紹介と、研究を日程順に紹介したのちに、現地の様子なども合わせてお届けします。
目次
- RecSysとは
- サイバーエージェントからの発表
- Tutorial ( 2つ紹介 )
- Main Conference ( Keynoteと論文を紹介 )
- Workshop ( 2つ紹介 )
- 現地の様子
- おわりに
RecSysとは
RecSysは、推薦システムのトップカンファレンスで、今年で16回目の開催となります。Industryセッションがあることもあり、研究者だけでなく、データサイエンティストや機械学習エンジニアの参加も多い学会となっております。昨年の開催に引き続き、ハイブリッド形式での開催となりました。参加者は過去最大の1,267人で、日本人参加者も48人と4番目に多い国でした。
今年は、論文投稿数は242本で、そのうち39本が採択されており、採択率は16.1%となっております。
採択された論文のカテゴリとしては、Algorithmsが29本で最も多く、次にReal-world applicationsの10本、その次にSocietal / Economic Impactの4本と続きます。
日程は、初日がTutorial、中3日間がMain Conference、残りの2日間がWorkshopでした。
サイバーエージェントからの発表
今回サイバーエージェントからは、AI Labの冨田・富樫・森脇による共著でIndustrial Trackにポスター発表で採択された「Matching Theory-based Recommender Systems in Online Dating」の発表を冨田が行いました。この発表では求人情報サービスやマッチングサービスなどで用いられる、ユーザーに対して他のユーザーを推薦する相互推薦システムにおいて、マッチング理論の分野で知られている移転効用付きマッチングモデルに基づいて相互推薦を行う「マッチング理論に基づく推薦システム(Matching Theory-based Recommender Systems; MTRS)」を提案し、そのプラットフォームにおける実応用と課題を議論しました。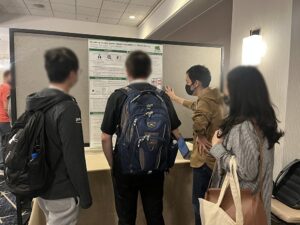
上の写真は発表時の様子です。ポスターのみの発表でしたが、想像していたよりも多くの参加者に興味を持っていただき質問をいただくことができました。近い分野の研究者の方や相互推薦システムの開発をされていた方ともゆっくり時間をとって話すことができたため、オンライン参加よりも現地参加することによってより有意義な議論ができたと思います。
Tutorial
学会初日は計8つのTutorialが2,3セッションずつ並列で行われておりました。そのうち”Psychology-informed Recommender Systems”と”Hands on Explainable Recommender Systems with Knowledge Graphs”の2つについて紹介します。

Psychology-informed Recommender Systems
心理学を推薦システムに活用する話です。推薦システムは行動履歴を始めとするデータから機械学習などを利用してユーザーの嗜好をモデリングしますが、それは根本的な心理的なメカニズムを無視していることがあるという前提のもと、心理学に基づいた手法を入れ込んだ推薦の研究事例を紹介していました。紹介された推薦システムは、認知に基づく推薦システム、パーソナリティを考慮した推薦システム、感情を考慮した推薦システムの3つに分類されています。本会議でも心理的な効果( オペラント条件付けや単純接触効果など )を利用した推薦システムの論文が採択されていました。
Hands on Explainable Recommender Systems with Knowledge Graphs
こちらは知識グラフを用いた説明可能な推薦システムに関する話です。まず説明可能な推薦システムを用いることの目的を、推薦の透明性やユーザーに対する説得性・有効性、推薦に対する信頼性やユーザー満足度を高めるためと整理した上で、解釈・説明可能な推薦モデルと、推薦モデルはブラックボックスとした上でそれを説明するためのモデルを用いる2種類の手法があるとし、その手法の入門的説明とハンズオンを行いました。こちらも本会議で推薦に説明を加えることでユーザー満足度を高めるという関連研究が採択されており、説明可能な推薦システムの重要性を感じる内容でした。
Main Conference
本会議はカンファレンス全体の2日目から4日目にかけての3日間にかけて行われました。Keynoteと研究発表に関して興味を持ったものをいくつかピックアップして紹介しようと思います。

Keynote
KeynoteはMor Naaman氏(Cornell Tech)とCatherine D’Ignazio氏(MIT)の2つありましたが、今回は前者の紹介をします。
“MY AI MUST HAVE BEEN BROKEN”: HOW AI STANDS TO RESHAPE HUMAN COMMUNICATION(by Mor Naaman)
人と人とのコミュニケーションの間にAIが関わることがどのような影響があるか、という話でした。メールの返信の自動補完のようなスマートリプライが入ると、人はよりポジティブなことを書きやすくなるなど、話す・書く内容や文体が変化するということが指摘されています。しかし一方でメッセージの受け手は、このメッセージの文章はAIによって書かれたものではないか、と思うと送り手に対する信用度を下げる傾向があることも確認しています。さらに現在では、文章がAIによって書かれたのか人間によって書かれたのかを人が見分けることは極めて難しくなるほど、AI技術は進歩しています。(このKeynote中でも2つの文章を提示されて、どちらがAIでどちらが人による文章でしょうか、と尋ねられるアンケートが取られましたが、AI技術に詳しいはずの学会参加者でも正答率は50%程度でした。)このようにAIが人と人とのコミュニケーションの間に入ることで文章や関係に対して影響を与えることが指摘されている中、テクノロジーがするべきことは何だろうか、と問いかけられる内容でした。
発表紹介
Countering Popularity Bias by Regularizing Score Differences
推薦における人気バイアス(Popularity Bias)についての研究です。人気バイアスとは、多くのユーザーに好まれる傾向にある人気なアイテムを過度に推薦してしまうバイアスで、ユーザーからの人気度がアイテム間でばらつきが大きいことから生じるデータバイアスと、その人気なアイテムをさらに推薦するようモデルが学習してしまうモデルバイアスとがあります。特に後者のモデルバイアスについて、200ユーザー×200アイテムの例で示したものが以下の図になります。
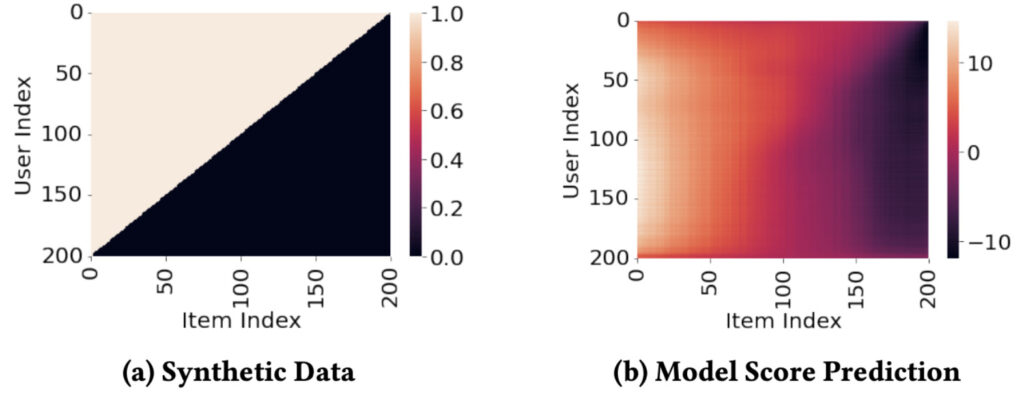
左図は各ユーザー(行)が各アイテム(列)に対して、ポジティブな評価をしているか(白)、ネガティブな評価をしているか(黒)を表しており、インデックスの小さいほど多くのユーザーに好まれている、人気なアイテムとなっています。これを推薦システムにおいて一般的な手法である行列分解(Matrix Factorization)でスコアを予測すると右図のようになり、人気アイテム(図b内左部分)は幅広いユーザーに対して高く予測されているのに対し、不人気アイテム(同右側部分)では本来ポジティブな評価を受けている部分(右上部分)であっても比較的暗く、低く予測されていることがわかります。
この論文では、ポジティブ評価をしているユーザー-アイテムペアに対してはスコアを高く、ネガティブ評価をしているユーザー-アイテムペアに対してスコアを低くするBPR(Bayesian Pairwise Ranking)Lossに対し、ポジティブなアイテムとネガティブなアイテムとの値を0に対して対称にしようとする(つまり足して0に近くなるようにしようとする)ゼロサムタームを正則化項を加えて計算することを提案しています。
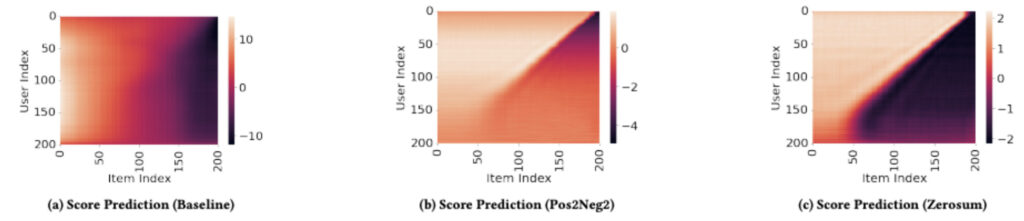
これにより、先ほどの例においては上図(c)のように人気バイアスを軽減することができ、また実データを用いた実験においても予測性能・人気バイアスに関する指標ともに既存手法と比べ比較的高い性能を実現しています。
Denoising Self-Attentive Sequential Recommendation
RecSys2022のベストペーパー。Transformerベースの推薦で課題となるノイズの多いattentionを除去する研究です。背景としてTransformerベースのSequential Recommendationは短期&長期的なアイテム列の依存関係を把握するのに非常に強力ですが、実サービスにおけるImplicit feedbackではアイテム列にノイズが多く、そのデータを用いて学習すると無関係なアイテムにもattentionをかけてしまうという課題がありました。
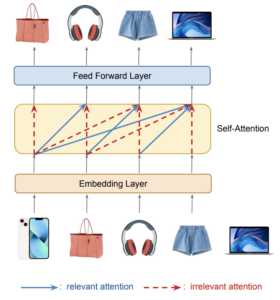
そこで、self-attention layerに学習可能なバイナリのマスクを付与して、ノイズの多いattentionを除去することを提案し、精度とモデルの解釈可能性が向上しました。また、ヤコビアン正則化によってロバスト性も高めています。この研究は特定のモデル改善ではなく、Transformerベースの複数の手法に適応可能であることも貢献が大きい点だと考えられます。
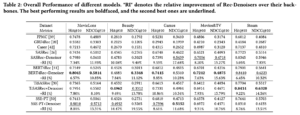
Revisiting the Performance of iALS on Item Recommendation Benchmarks
iALSの精度は新しく出てきたモデルに劣ると報告されている4つのベンチマークに対して、再実験を行い、iALSの精度がまだまだ最近のモデルに匹敵することを示した研究です。iALSとは、2008年に発表されたimplicit feedbackから学習されるItem Recommenderの問題を扱う協調フィルタリングベースの推薦手法です。計算効率が良くスケーラブルなことが特徴的で、推薦システムの研究論文ではよくベースラインに使われています。本研究ではハイパーパラメータのチューニングを行うことで、これまでの研究結果を覆す結果を示しています。この結果はiALSの可能性を示すと同時に、機械学習モデルのチューニングの難しさも表しています。
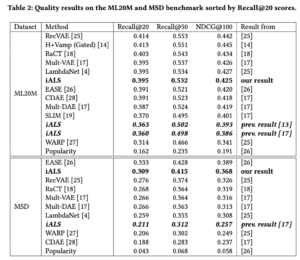
また、上記の実験では精度面だけを比較していましたが、model capacityの面でも比較しています。ここではモデルが各Itemに対して保有するパラメータ数をmodel capacityと定義しています。ベンチマークで良い性能を示した全てのモデルが大きなmodel capacityを持つことがわかります。そのため、model capacityと精度のトレードオフという点でもiALSが他のモデルと拮抗していると言えます。
![Our iALS benchmark results with a varying embedding dimension, d. For comparison, the plots contain also the previous iALS results from [17], EASE [26] and Mult-VAE [17]. The capacity for EASE, Mult-VAE and prev. iALS is not varied in the plot and the numbers represent the best values reported in previous work (see Section 3.1.2 for details)](https://developers.cyberagent.co.jp/blog/wp-content/uploads/2022/10/9adc8c244bb5b8dba8c119dac6aaf2c9-300x171.png)
最後にはiALSのチューニングのガイドラインもついています。各ハイパーパラメータに関する説明をした後に、どのように調整すると最適なモデルが得られるかを説明しています。現場のエンジニアにも活用しやすい論文になっています。自分の手元でも試してみようかなと思います。
Modeling Two-Way Selection Preference for Person-Job Fit
求人と求職者のマッチングで双方向の好みを考慮するために双方向のグラフを用いた研究です。求人プラットフォームに限らず人間同士のマッチングでは、求職者と雇用者の一方が良いと思うだけではなく、お互いが良いと思わない限り、目的( 求人の場合はマッチ or 訪問 or 雇用、マッチングアプリの場合はマッチ or デート or カップル成立など )は達成されません。そのため双方向の好みが重要になりますが、既存手法ではあまり双方向の好みをモデリングできていません。そこで、求人と求職者をノードに持つ双方向のインタラクションを扱うGraph Convolutional Networksを用いた手法を提案しています。この手法では求人情報などのテキストデータもBERTを用いて埋め込んでおり、ハイブリッドな推薦システムとなっています。
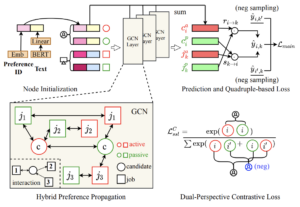
性能評価の結果を以下に示します。この表は3つの領域( Tech、 Sales、Design )のデータに対して、それぞれ協調フィルタリングベースの手法、コンテンツベースの手法、ハイブリッドな手法の結果です。どの領域でも提案手法( DPGNN )が最も良いことがわかります。また求人の領域によって、それぞれの手法との向き不向きもありそうです。
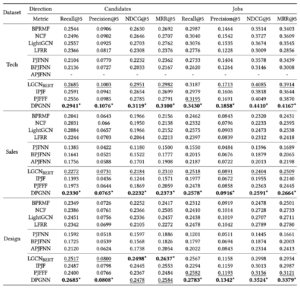
実際の求人データの例も紹介されていました。これは求職者は求人を好んでいるが、求人は求職者をあまり好んでいないため、推薦すべきではない例です。しかし、LightGCNと呼ばれる協調フィルタリングベースの手法やBPJFNNと呼ばれるコンテンツベースの手法ではマッチ度が高いと判定されて、推薦されてしまいます。本研究のように双方向の好みをモデリングすることによって、単方向の好みが削ぐわない場合に対応できることを示しています。

Workshop
計15のワークショップが2日間で行われました。その中から2つピックアップして紹介します。
RecSys in HR
このワークショップではHR分野の推薦システムに関連する招待講演、論文発表、ディスカッションが行われていました。HRとマッチングアプリは異なるドメインですが、人間同士のマッチングという点ではとても似ており、技術的に参考になる部分が多いので参加しました。
その中でも、indeedのdata science leaderであるRobyn Rapさんの招待講演が印象に残りました。この講演では、一般的な推薦システムとHiring marketplaceの異なる点を整理していました。その上で、単純にimpなどの定量的な評価だけではなく、定性的な評価による改善も必要であることを示していました。また、実際にindeedで行っている手法( Eye TrackingやDialy Studiesなど )の紹介をしています。スライドが公開されてなかったので引用は控えますが、HRのWorkshopについてはYoutubeで視聴可能なので、気になる方はご覧ください。
CONSEQUENCES+REVEAL
推薦システムにおける因果推論や反実仮想、および強化学習に関するワークショップです。推薦アルゴリズムの因果効果の推定や反実仮想分析は実プラットフォームの分析上非常に重要であり、またこの分野では経済学と方法論上の親和性も高いため経済学出身である私(冨田)は比較的馴染みがあるということで参加しました。このワークショップでの発表の中から一つ、次の招待講演について紹介したいと思います。
“Multiple Randomization Designs” by Guido Imbens (Stanford GSB)
計量経済学・因果推論の専門家で2021年ノーベル経済学賞受賞のGuido Imbens氏による、RCT実験(A/Bテスト)設計に関する発表です。WebプラットフォームにおけるA/Bテスト(例えばユーザーにアイテムを変更する際のUIを変更するなど)では、ユーザーを変更を加える介入群と加えない対照群に分割するか、あるいはアイテムを介入群・対照群に分割して実験を行うことが一般的です。しかしそのような分割方法によるA/Bテストでは、例えば一部のユーザーに対してだけ変更を加えられたアイテムとそうでないアイテムの売り上げを比較する、あるいは一部のアイテムだけ変更を加えられたユーザーとそうでないユーザーを比較するなど、スピルオーバー効果を推定することはできません。この発表では、単純にユーザーを2グループに分割する、あるいはアイテムを2グループに分割するのではなく、各ユーザー-アイテムペアに対して介入群に割り当てるか対照群に割り当てるかを慎重に設計することで、従来の実験よりスピルオーバー効果などより多くのことが推定できるようになるという話でした。
現地の様子
現地参加による交流では以下のようなものがありました。これらの時間では気軽にいろんな研究者や企業の方と話すことができます。
- Aquarium Reception
- WOMEN IN RECSYS BREAKFAST
- 企業ブース
- ポスター発表
Aquarium Reception



WOMEN IN RECSYS BREAKFAST
Women in RecSysとはRecSysコミュニティの多様性を育むために2014年から始まった取り組みです。8時集合で円になって自己紹介から始まりました。研究者や学生に並んで、機械学習エンジニアやデータサイエンティストの方も多いなという印象を受けました。自己紹介のあとは、少人数に分かれてカフェで朝食を食べながら話しました。この時間はじっくり話すことができてよかったです。
Nice to see the #WomenInRecSys come together at #RecSys2022. Not everyone joined simultaneously, but we counted at least 50 attendees. Additionally, we look forward to the virtual #WomenInRecSys meetup next week Wednesday. pic.twitter.com/Gv9PqtUXTe
— ACM RecSys (@ACMRecSys) September 20, 2022
シアトルの紹介も少ししておきます。
PIKE PLACE MARKET
RecSys2022の会場からは徒歩7分くらいでした。クラムチャウダーの有名なお店やスタバ1号店がありました。魚を投げる魚屋さんも有名らしく、着いた瞬間に1度だけ投げるタイミングに出くわして驚きました。



おわりに
私(冨田)がサイバーエージェントに入社してからはほとんどの学会がオンラインで開催されていたため、国際学会に現地参加させていただくのは今回が初めてでした。オンライン開催の学会でも他の参加者とのコミュニケーションはある程度は可能でしたが、現地参加ではより多くコミュニケーションをとる機会を得ることができ、大変有意義な経験ができました。特に私のポスター発表で近い分野の研究者やMLエンジニアの方と相互推薦システムに関してディスカッションをゆっくりできたことは、自分の今後の研究・プロジェクトにおいてとても参考になりました。
一方で、私は元々経済学の出身で推薦システムや機械学習に関しては知識・経験に乏しいこともあって、今回研究発表を聞いていて推薦システムについての勉強不足を痛感しましたし、今行っている相互推薦システムについての研究プロジェクトを成功させるためにも、推薦システムについてのインプットもしていかなければと強く感じました。サイバーエージェントにはタップル以外にも推薦システムが関わるプロダクトが多くありますし、社内で推薦に関わっている他の社員とも一緒にRecSysやその他関連分野の学会の研究をキャッチアップしながら、プロダクトの改善につながるような研究を進めていきたいと思います。
出典
- [1] Wondo Rhee, Sung Min Cho, and Bongwon Suh. 2022. Countering Popularity Bias by Regularizing Score Differences. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys ’22). Association for Computing Machinery, New York, NY, USA, 145–155. https://doi.org/10.1145/3523227.3546757
- [2] Huiyuan Chen, Yusan Lin, Menghai Pan, Lan Wang, Chin-Chia Michael Yeh, Xiaoting Li, Yan Zheng, Fei Wang, and Hao Yang. 2022. Denoising Self-Attentive Sequential Recommendation. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys ’22). Association for Computing Machinery, New York, NY, USA, 92–101. https://doi.org/10.1145/3523227.3546788
- [3] Steffen Rendle, Walid Krichene, Li Zhang, and Yehuda Koren. 2022. Revisiting the Performance of iALS on Item Recommendation Benchmarks. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys ’22). Association for Computing Machinery, New York, NY, USA, 427–435. https://doi.org/10.1145/3523227.3548486
- [4] Chen Yang, Yupeng Hou, Yang Song, Tao Zhang, Ji-Rong Wen, and Wayne Xin Zhao. 2022. Modeling Two-Way Selection Preference for Person-Job Fit. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys ’22). Association for Computing Machinery, New York, NY, USA, 102–112. https://doi.org/10.1145/3523227.3546752