
本記事は、CyberAgent Advent Calendar 2022 16日目の記事です。
はじめに
サイバーエージェント AI Lab NLPチーム所属の星野 (@shhshn) です。
巷で話題の画像生成AI向けに機械翻訳システムを試作し、(a) 日本語 (b) 英語 (c) 日本語から英語への機械翻訳 の三種類の方法で画像を生成した事例分析で得られた知見について紹介いたします。
背景: 画像生成AIとは
画像生成AIとはテキスト入力(別名プロンプト)から画像を生成する text-to-image モデルのことです。
本記事では特に拡散モデル、具体的にはLatent Diffusionモデル [Rombach et al. 2022] に基づくStable Diffusionを対象とします。手元で利用可能なモデルとしてはStable Diffusion 1.5(以後「英語モデル」)やJapanese Stable Diffusion(以後「日本語モデル」)などが公開されています。

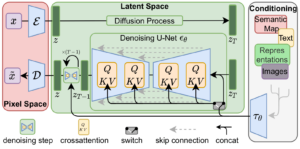
[Rombach et al. 2022] より引用
日本語モデルと英語モデルの違い
そこで気になるのが日本語モデルと英語モデルの違いです。例えば、Japanese Stable Diffusionを開発したrinna社は、日本語の「サラリーマン」という単語などを理解して画像を生成するための専用モデルであると説明しています。
以下が実際に試してみた結果です。本記事では4つの異なるシード値での生成結果を掲載しています。
- (a) 日本語モデル(プロンプト: “サラリーマン、油絵”)

- (b) 英語モデル(プロンプト: “salary man,oil painting”)

ご覧の通り、英語モデルでも「ビジネスパーソン」の画像を出力できています。一方で、日本語モデルの方が日本人のいわゆる「サラリーマン」により近い画像を出力していそうです。なお画像の良し悪しは私個人が主観的に判断しました。
ただ、日本語モデルが常に優れているかというと、必ずしもそうとは限りません。
次に示すのが「大統領」の生成結果です。なお黒塗り部分はモデル自身が不適切と判定した画像です。
- (a) 日本語モデル(プロンプト: “大統領”)

- (b) 英語モデル(プロンプト: “president”)

この例ではどうでしょうか。日本語モデルはアメリカ合衆国の国旗・国章・元大統領を想起させる画像を出力しました。一方の英語モデルはより多様な内容かつ高品質な画像を生成しています。
これらの異なる結果には日本語モデルと英語モデルの違い、特に異なる学習方法や学習データが影響していそうです。日本語モデルは英語モデルをLAION-5Bデータセットの日本語部分でfine-tuningしており、英語LAION-Aestheticsデータセットのような審美性 aesthetics の予測スコアによる低品質データの足切りは恐らく実装されていません。
これまで日本語モデルと英語モデルを使い分けることでより良い画像を生成できる可能性を示しました。しかしモデルに合わせてプロンプトまで変更するのは大変で、もっと別の方法はないのでしょうか?
機械翻訳による日本語と英語の橋渡し
このようにテキスト入力が日本語か英語かで異なる生成結果になる場合、機械翻訳を利用する第三の方法があります。まず日本語テキストを英語に変換し、その後に英語モデルに入力することで、日本語モデルと異なる出力を得るやり方です。言語横断検索などと呼ばれる技術で検索エンジンで応用されています。
次に示すのが、英語プロンプトを考えるのが難しそうな日本語プロンプトを拝借した事例です。
- (a) 日本語モデル(プロンプト: “新しい時代の到来を祝福するメチャクチャ太った猫の神聖で素晴らしい油絵”)

- (c) 英語モデル + 機械翻訳(プロンプト: “Blessing the arrival of a new era, the sacred and wonderful oil painting of cheat fat cat”)

この例では、日本語モデルより英語モデルの方がプロンプトの意図に近い生成結果となりました。機械翻訳の出力をそのまま英語モデルのプロンプトに利用したため誤訳も含まれていますが、それを差し引いてもより高品質な画像を生成できました。
なお英語モデルに日本語テキストを直接入力することも可能ですが、テキストを無視されるか、より低品質な画像が生成されます。
- (b) 英語モデル(プロンプト: “新しい時代の到来を祝福するメチャクチャ太った猫の神聖で素晴らしい油絵”)

日英機械翻訳システムの試作
今回は機械翻訳システムとして、事前学習済みの多言語翻訳モデル M2M-100 1.2B [Fan et al. 2022] を用いました。一般的に機械翻訳モデルの学習は膨大なデータと多くの計算資源を必要とするため大変で、個人開発で翻訳精度の高さを求めるのであればDeepLやGoogleなどの企業が公開している有料APIの利用が無難です。しかし事前学習済みモデルは手元のGPU環境で動作しながら翻訳精度も並以上と言われており、今回試してみました。
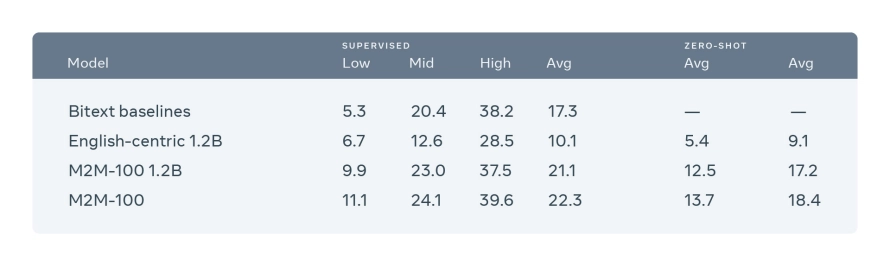
M2M-100の広報記事より引用
詳細は割愛しますが、M2M-100は日本語も含んだ多言語と英語の対訳データで学習されたニューラル機械翻訳モデルで、日本語テキストを入力に指定すると英語への翻訳結果を出力します。なお、このモデルを利用して画像生成AIの学習データを翻訳したLAION Translatedデータセットも公開されています。
事例分析
それでは実際に機械翻訳を他二つの方法と比較します。以下に示すのは (a) 日本語モデル (b) 英語モデル (c) 日本語から英語へ機械翻訳し英語モデルを利用、の三種類の生成結果です。今回使用したプロンプトは恣意的に選んだもので、日本語・英語として流暢なテキストでありながら出力結果に違いが生じそうな「絵画と作家名」および「名詞と社会的バイアス」に関連する事例をcherry pickingで分析しています。
絵画と作家名
ゴッホ風
- (a) 日本語モデル(プロンプト: “絵画、ファン・ゴッホ風”)
- 「星月夜」3枚と人物画で、やや単調かつ低品質です

- (b) 英語モデル(プロンプト: “painting, in the style of van Gogh”)
- 自画像、「ひまわり」、そして「星月夜」風の2枚とバリエーション豊かです

- (c) 英語モデル + 機械翻訳(プロンプト: “Painting by Van Gogh.”)
- 「ひまわり」代わりの風景画と、より「星月夜」に近い出力が登場しました

北斎風
- (a) 日本語モデル(プロンプト: “絵画、葛飾北斎風”)
- 高品質ですが「神奈川沖浪裏」4枚のみと単調です

- (b) 英語モデル(プロンプト: “painting, in the style of Hokusai”)
- 「神奈川沖浪裏」そのものだけでなく多様性があります

- (c) 英語モデル + 機械翻訳(プロンプト: “Painting and painting north.”)
- 機械翻訳モデルが「葛飾北斎」の語彙を認識できず “north” と誤訳してしまいました

名詞と社会的バイアス
大学の建物
- (a) 日本語モデル(プロンプト: “大学の建物”)
- 似通った建物が多いです

- (b) 英語モデル(プロンプト: “university building”)
- より多様な建築様式が反映されています

- (c) 英語モデル + 機械翻訳(プロンプト: “The University Building.”)
- (b)とほぼ同じですが、プロンプトの微妙な違いで形状が変化しました

国旗
- (a) 日本語モデル(プロンプト: “国旗”)
- 「日章旗」を想起させる生成結果が特徴的です

- (b) 英語モデル(プロンプト: “national flag”)
- 「ユニオンジャック」や「セント・ジョージ・クロス」を想起させます

- (c) 英語モデル + 機械翻訳(プロンプト: “The Flag”)
- プロンプトの違いにより「星条旗」を想起させる出力ばかりになりました

分析結果まとめ
全体的な感触として、英語モデルは日本語モデルより高品質かつ多様な画像を生成でき、そのため日本語から英語への機械翻訳を利用しても日本語モデルより優れた画像を生成できました。一方で、機械翻訳が誤訳しやすい「葛飾北斎」などの固有名詞を含んでいたり、日本人の「サラリーマン」を出力させたい場合には、日本語モデルが優れていました。
今回分析した事例を分類するとざっくり下記の3パターンが観察されました。今後モデルを使い分ける際の判断材料の一助になればと思います。
- 日本語モデルが得意な事例
- 英語モデル・機械翻訳モデルともに得意な事例
- 日本語から英語への機械翻訳に失敗する事例
その他モデルとの比較
先日公開された (d) 日本語も含む多言語モデル AltDiffusion [Chen et al. 2022] と (e) 新しい英語モデル Stable Diffusion 2.1 を試した所、以下事例については (c) Stable Diffusion 1.5と機械翻訳の組み合わせの方がプロンプトにより忠実な出力となりました。また機械翻訳精度にも結果が左右されるため、 (f) DeepL Translate および (g) Google Translateを使用した場合とも比較しました。
- (c) 再掲: 英語モデル + 機械翻訳(プロンプト: “Blessing the arrival of a new era, the sacred and wonderful oil painting of cheat fat cat”)
- (d) 多言語モデル(プロンプト: “新しい時代の到来を祝福するメチャクチャ太った猫の神聖で素晴らしい油絵”)

- (e) 新英語モデル + 機械翻訳(プロンプト: “Blessing the arrival of a new era, the sacred and wonderful oil painting of cheat fat cat”)

- (f) 英語モデル + DeepL Translate(プロンプト: “Sacred and wonderful oil painting of a messed up fat cat celebrating the arrival of a new era.”)

- (g) 英語モデル + Google Translate(プロンプト: “A sacred and wonderful oil painting of a fat cat that celebrates the arrival of a new era”)

おわりに
本記事では個人で趣味的に開発した画像生成AI向け機械翻訳システムについて説明いたしました。
普段は広告テキストの自動生成に取り組んでおり、機械翻訳も自然言語生成と呼ばれる同じ研究分野の一つです。我々の幅広い活動にご興味がありましたらお声がけいただけると幸いです。
参考文献
- Rombach et al. High-Resolution Image Synthesis with Latent Diffusion Models. CVPR2022.
- Fan et al. Beyond English-Centric Multilingual Machine Translation. JMLR2022.
- Chen et al. AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities. arXiv:2211.06679.