
AI事業本部 DX本部22新卒の西澤(@ZAWAVE7)です!
2022/11/28~12/2までアメリカのラスベガスで開催されたAWS re:Inventに現地で参加しました。
その内容や感想をレポートします。

Keynote
CEOのAdam SelipskyのKeynoteでは13の新サービスがアナウンスされました。
現代のイノベーションにおけるデータ分析の重要性の説明に始まり、一番にアナウンスされたAmazon OpenSearch ServerlessやAmazon Redshift, Amazon DataZoneなどのデータ分析関連サービスのローンチ情報が多かった印象です。


発表の瞬間の盛り上がりや新サービスのセッションの人気ぶりなどから注目度を肌で感じられることは、現地でしか味わえないカンファレンスの醍醐味だなと思いました。
また、Gravitonを活用している企業事例としてCyberAgentのロゴも掲載されました!

こちらのリンクから無料での視聴もできますので、CEOの他CTOやVPの発表もぜひご覧ください。
今回の私のレポートでは、数あるアップデートの中からAmazon Redshiftに注目して書いていきたいと思います。
AWSの意気込みを感じるRedshift
2030年には572ゼタバイトのデータが蓄積されると言われています。
ビジネスにおいて膨大なデータの分析は今後ますます重要で当たり前にすべき事になっていきます。今回のre:InventではDWHサービスとしてAWSが提供しているAmazon Redshift周りのアップデートが多い印象でした。
新機能を簡単に紹介します。
- S3 auto-copyやAuroraとのzero-ETL統合などデータの取り込みが単体で完結し圧倒的に楽に
- Apach Sparkの統合によりシームレスにSageMakerやGlueを用いた分析が可能に
- Multi-AZに対応し可用性と耐障害性が向上
- Amazon Managed Streaming for Apache Kafka(MSK)とAmazon Kinesis Data Streams(KDS)からリアルタイミングストリリーミングデータを直接取り込めるように
- SQL機能強化によりパフォーマンスが向上し、外部DWHからの移行がしやすくなる
- ポリシーを基に動的にデータのマスキングが可能に
- Centralized Access Controlsにより行、列単位でのアクセス管理が可能に
特にデータの受け渡し周りが便利になっています。
今回追加された機能によって何ができるようになり、何が不要になったかを図にまとめてみました。
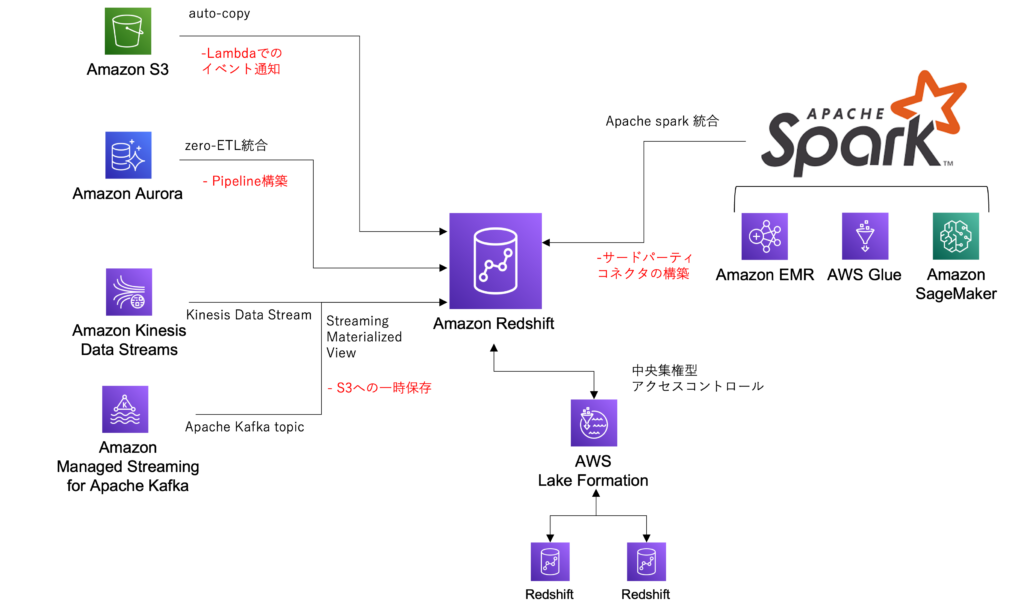
データの収集に始まり、加工・保有・分析までをAWSのマネージドな各サービス連携・エコシステム上で実現できることで、データの認可制御や移動に気を使う場面が減るのはとてもありがたいことです。
実際に弊社のデータ基盤運用としても、外部SaaSベンダーなどを経由して、各種データをS3に蓄積するインフラ構成は多く、その構成からデータ分析を行うためのDWHや分析基盤へのデータ移動のハードルはかなり低くなると思います。
実は、re:Invent 2022前にも、データ関連のサービスアップデートは数多くありました。
例えば、下記のようなアップデートです。
- Amazon SNS adds support for payload-based message filtering
- Amazon S3へのアクセスにACLが利用されたログを出力可能に
- Amazon Redshiftの書き込みリクエストに対する同時実行スケーリング機能が一般利用開始に
- Amazon Kinesis Data Streams adds capability to easily inspect data records in AWS Management Console
- Amazon SNS message data protection is now generally available with real-time data redaction and masking
これらはデータを連携する途中にデータをフィルタしたり、マスキングしたり、可視化で
るようになるアップデートが多いです。AWSというプラットフォーム上でビルディングブロックの設計思想に基づいて、各サービスそれぞれがデータに対してあらゆる責務を担えるようなアップデートが目立ちます。そのようなプロセスを経たデータが格納される場所がDWHのAmazon Redshiftです。
そんなRedshiftといえば7月にGAされたRedshift Serverlessが話題になっていました。
DWHを始めとしたデータ分析のサーバーレス化によって分析がどう変わるのかをサーバーレスがコンピューティングにもたらしたものと比較して考えてみたいと思います。
サーバーレスは、コンピューティングの歴史において
「スケーラビリティなど責任の多くを分離できる」「コストと技術面でのハードルが下がりチャレンジがしやすくなった」「開発者がインフラの保守運用に時間を割かず、アプリケーション開発に集中できる」
などの利点をもたらしてきました。
Redshiftもサーバーレス化によりセキュリティやスケーラビリティなどを責任共有モデルをベースとして、マネージドレベルでAWSと開発者の責任を分離して考える事ができます。クラスタの構築や管理をせずに利用後すぐにオートスケーリングを含むフルマネージドなクラスタが提供され、分析が行なえます。
今回の発表であったようなAWS内の連携強化機能により、今まで外部連携において、高額だが必要であったパイプラインやサードパーティコネクタのコストがなくなるのも大きな利点です。コストが下がることで、大規模なリアルタイム分析や検証ベースの簡易な分析にチャレンジしやすくなったと思います。
今回の発表からも分かる通り、分析において今、最も注目されているのは、分析者がより専門的なタスクに集中できるための機能です。
実際にkeynoteでもS3からRedshiftへのauto-copy機能を発表したときが最も盛り上がったように感じました。
これはサーバーレスに限らず全体に言えることですが、データ受け渡しや加工のインフラ部分を、分析者が意識する必要がない、あるいは専門的に担当しているデータエンジニアのようなリソースを他に回すことで、分析のリソースをより多く確保できるようになると思います。
下の画像はModernize your data warehouseというセッションでRedShift Serverlessによって分析者が集中すべき部分とAWSに任せる部分が明確に分けられていることを説明しているものです。サーバーレスにおける意識や責任の分担をわかりやすく視覚化しています。

(What’s new with Amazon Redshift ANT201より引用)
データ分析基盤は、あらゆるデータを生のまま一つに保管するデータレイク、分析しやすくするために加工したデータを保管するデータウエアハウス、更に分析しやすいよう分類して保管するデータマートと、構造化、抽出し3層に分けてデータを蓄積する3層構造を構築するのが主流です。
AWSはデータレイクとして強力で広く利用されているS3と、データウェアハウス、データマートとしてのRedshiftの連携を強化し3層構造と間の連携をフルマネージドにAWS上で実現できることが最大の強みだと思います。
また、今回発表されたAWS Data Exchange for AWS Lake Formationにより外部のS3にあるデータとの連携を権限管理のもとで簡単に行えるようになり、同じS3のリソース間で外部データと連携するハードルが大きく下がりました。
同様に今後もデータの管理、活用のコストを下げるようなアップデートが増えるのではないかと予想します。
セッションについて
話は現地ラスベガスに戻りますが、新規サービスやアップデートをいち早く試せる「Workshop」やその新サービスの詳細や、すでにあるサービスの裏側などが聞ける「Breakout Session」を中心に参加してきました。特に最新サービスやアップデートのセッションは要チェックです!なぜそのサービスが設計されてローンチされたのか、どのように使ってもらうことを期待しているのかという情報をサービスの開発者や設計者から直接聞くことができるからです。
さらに詳細な情報は、AWSのブログでまとめられていたのでぜひご覧ください。(https://aws.amazon.com/jp/blogs/news/aws-weekly-20221128-1/)
刺激を受けたもの
セッションやワークショップではAWSのPMや開発者とデモを通してコミュニケーションを取ることができます。デモを使った感想やユースケースなどについて質問できました。
実際に動かしながら説明してもらえたり全く違う視点からの質問に答えているのを見れたりと、広くも深くも知れる機会があるのはオフラインのコミュニケーションならではの経験でした。
EXPOブースでは世界中のクラウド関連企業のブースがあり、世界中の新規サービスのデモに触れることができました。特に、データ分析や監視サービスのブースが人気でした。
全く知らなかったサービスの説明や、DataDogやTerraformといった普段使う機会が多いサービスの新機能等、様々な情報に触れることができました。
今回の旅において意外と大切だと感じたことは、現地で共に参加している日本人との交流でした。
普段日本にいても交流できない方との接点ができました。
re:Inventに初回から参加されている方や、自費で来た大学生の方まで幅広く交流、情報交換させていただきまして、いろんな視点でのセッションの感想を聞けて面白かったです。JAWS(Japan AWS User Group)という日本のAWSコミュニティの方と交流させていただいて、長くAWSを利用されている上での意見や、私が小学生の頃のインシデント対応の話など聞かせていただきとてもおもしろかったので、コミュニティへの参加も今後していきたいです。
最後に、そして次回に向けて
新型コロナの流行に伴い全世界であらゆるイベントが中止、縮小して以来初の本格開催であるAWS re:Inventの参加レポートを書かせていただきました。
イベントへの参加の慣習や文化が途絶えたり、慎重にならざるを得ない状況の中で「若手に経験を積ませる機会を作る文化を取り戻さないといけない。」と急遽私達を送り出してくださった事業部に心から感謝します。
成長のための経験をさせる文化が強い会社で良かった、と思う一方で、自分としてもそういった文化をつくる側として貢献できるように邁進しなくてはいけないなと思います。
と言った手前ですが、私自身是非また参加したいです…!
また行けるように技術、言語、普段の業務にコミットし続けたいと思います。