
はじめに
CIU (CyberAgent group Infrastructure Unit) の西北(@nishi_network)です。
普段はプライベートクラウドで使用しているデータセンターの運用やそれに伴う開発業務に従事しています。
今回は、ディスク故障によって読み取れなくなったVMイメージを復旧させたので、その過程について紹介します。
事の発端
事の発端は、ディスクの故障が発生し交換の必要が生じたことでした。
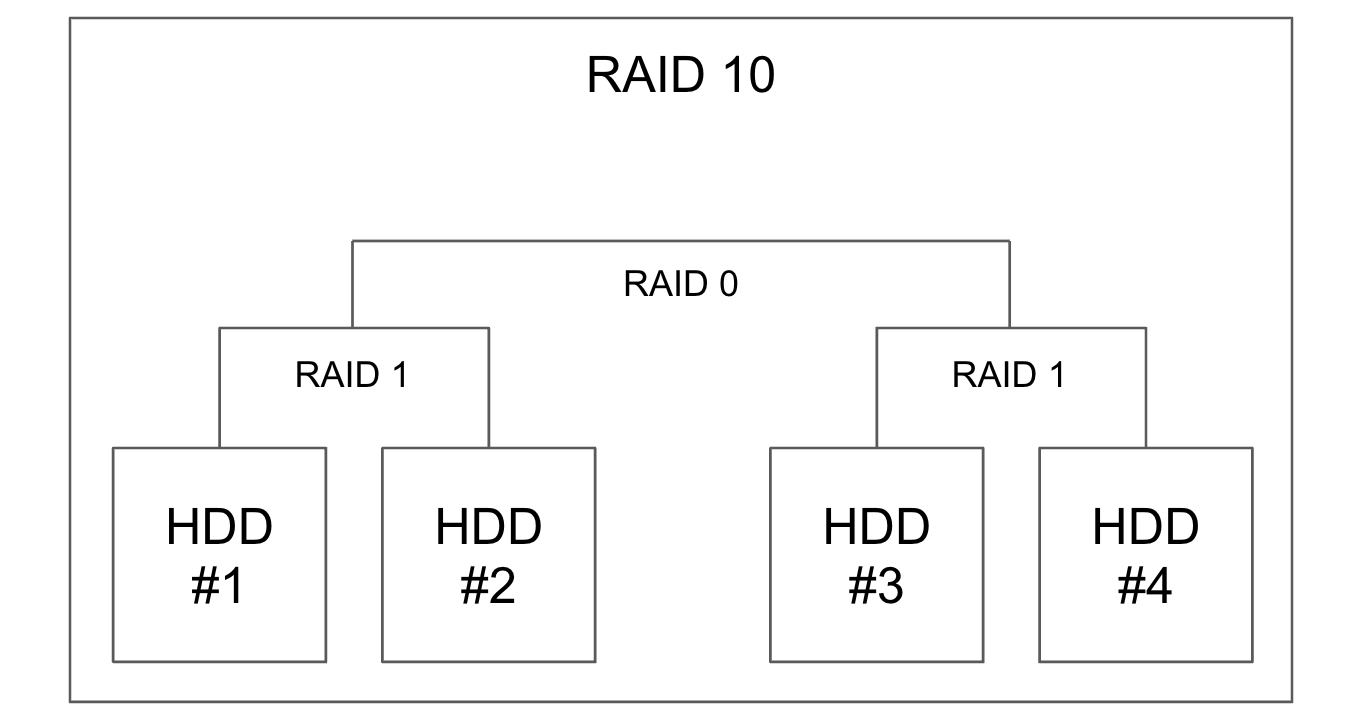
対象のディスクは4本でRAID10を構成しており、そのうち1本の故障を検知したため対象ディスクの交換を実施しました。
このような場合、通常であれば交換後にRAIDをRebuildすることで復旧させることができます。
しかし、今回はRebuildが30%ほど進んだところで失敗し、再度ディスクを交換しても同様に失敗するためRAIDの復旧が不可能でした。
Virtual drive : Target Id 0 ,VD name
Size : 1.088 TB
State : Degraded
RAID Level : 10
そのため、対象のサーバーがかなり古いものだったこともあり、動いてるVMを他の正常なサーバーへ移動(=マイグレーション)した後に引退させることにしました。
この環境ではKVMを利用していたため、VMのイメージファイルを直接scpなどで移動させることでデータ移動を完了することができます。
しかし、scpを利用したイメージファイルの転送では特定のファイルで処理が途中で止まってしまい転送を完了させることができず、データ移動を完了させることができませんでした。
データ移動ができなかったVMは再構築可能なものだったので諦めて再構築しても良かったのですが、対象の環境は本番環境とは別の開発環境だったこともあり、復旧にチャレンジしてみることにしました。
ディスクの状態を確認する
RAIDが構成されたディスクの状態を確認してみると、RAID10の内おそらく故障したディスクとRAID1でペアになっているであろうディスクに大量のエラーが発生していることが分かりました。
つまり、すでにRAIDは崩壊し一部データのロストが発生している可能性が高く、これが原因でRAIDのRebuildが失敗していたと考えられます。
# /opt/MegaRAID/MegaCli/MegaCli64 -PDList -aAll
~~~~~~~~
Enclosure Device ID: 64
Slot Number: 2
Drive's position: DiskGroup: 0, Span: 1, Arm: 0
Enclosure position: N/A
Device Id: 24
WWN: XXXXXXXXXXXXXXXX
Sequence Number: 2
Media Error Count: 88867
Other Error Count: 0
Predictive Failure Count: 0
Last Predictive Failure Event Seq Number: 0
PD Type: SAS
~~~~~~~~
また、scpについてもdmesgを確認するとio errorとなって転送に失敗しているようでした。
end_request: I/O error, dev sda, sector 906130672そもそもなぜこんな事になったのか
対象の環境は本番環境とは別の開発環境でした。
また、RAIDコントローラーがディスクの故障(障害予兆)を検知せず危険な状況を把握できない事があり、これを回避するには定期的に全データを読み取ることで正常性を確認する必要があります。
しかし、この正常性確認を行うと当然ディスクに対するI/Oは増えるためVMの動作に影響します。そのため、当該環境ではこの正常性確認を意図的に無効化していました。
その結果、ディスク故障の発見が遅れ、運の悪いことに故障したディスクとは別に故障しかけのディスクもあったためにIOができない領域が発生(=データロスト)し、このような状態となりました。
io errorを読み飛ばしてコピーする
さて、復旧を試みます。
対象のVMイメージは100GBですが、起動してOSを確認したところ使用しているのは15GBほどでした。
また、scpでの転送時にはおおよそ58GBほど転送したところで止まっていることから、VMが使用している領域には影響が出ていない可能性が高いと考えました。
加えて、qemu-imgを用いてイメージの状態を確認する限り正しく読めていることが分かり、VMイメージとして壊れている可能性は低いと考えられます。
# qemu-img info vm-image.img
image: vm-image.img
file format: raw
virtual size: 100G (107374182400 bytes)
disk size: 100G
つまり、エラーが出るセクタを読み飛ばして他のサーバーへコピーすることができれば、VMとして起動できる可能性が高いと言えます。
scpやddではio errorが発生した場合処理は異常終了してしまいます。しかしddrescueを使用すればio errorが発生した箇所を読み飛ばして処理を継続してくれます。
本来であれば別のディスクを用意してそちらにddrescueを使用してコピーを作成すべきですが、今回はサーバーの構成上難しかったため再破損するリスクを考慮しつつ同一ディスク上にコピーを作成してみます。
# ddrescue -n -v vm-image.img vm-image_ddrescue.img
GNU ddrescue 1.26
About to copy 107374 MBytes from 'vm-image.img' to 'vm-image_ddrescue.img'
Starting positions: infile = 0 B, outfile = 0 B
Copy block size: 128 sectors Initial skip size: 2176 sectors
Sector size: 512 Bytes
Press Ctrl-C to interrupt
ipos: 107374 MB, non-trimmed: 69632 B, current rate: 51314 kB/s
opos: 107374 MB, non-scraped: 0 B, average rate: 75379 kB/s
non-tried: 3342 kB, bad-sector: 0 B, error rate: 0 B/s
rescued: 107370 MB, bad areas: 0, run time: 23m 44s
pct rescued: 99.99%, read errors: 3, remaining time: 1s
time since last successful read: 0s
Copying non-tried blocks... Pass 1 (forwards)
ipos: 62162 MB, non-trimmed: 69632 B, current rate: 51314 kB/s
opos: 62162 MB, non-scraped: 0 B, average rate: 75379 kB/s
non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s
rescued: 107374 MB, bad areas: 0, run time: 23m 44s
pct rescued: 99.99%, read errors: 3, remaining time: 1s
time since last successful read: 0s
Copying non-tried blocks... Pass 2 (backwards)
ipos: 62167 MB, non-trimmed: 0 B, current rate: 0 B/s
opos: 62167 MB, non-scraped: 9216 B, average rate: 69497 kB/s
non-tried: 0 B, bad-sector: 3072 B, error rate: 0 B/s
rescued: 107374 MB, bad areas: 6, run time: 25m 44s
pct rescued: 99.99%, read errors: 9, remaining time: 1s
time since last successful read: 0s
Trimming failed blocks... (forwards)
Finished
やはり、io errorが発生しているようです。
しかしながら、エラーが発生する箇所を読み飛ばすことで無事にコピーを作成することができました。
後はこのコピー後のファイルを別ホストへscpで転送して起動を試み、無事に起動させることができました。
また動作にも影響が無いようなので現状では特に問題なさそうです。
振り返り
今回は、io errorにより正常に読み取れなくなりコピーが出来なくなったVMイメージをddrescueを使って復旧を試みました。
通常でMedia Error Countがあれだけ出ていればRAIDコントローラーが故障として検知するはずですが検知されなかったため、他のディスクが故障したときには時既に遅しでした。
しかしながら、io errorになるセクタの運が良ければddrescueなどを使用して対象のセクタを読み飛ばすことでファイルを読み出すことができました。