はじめに
メディア事業部でサーバーサイドエンジニアをしている宋です。私はAmebaというサービスで、デモグラフィックターゲティングを実現するために、システムの設計、開発を担当しました。今回は、このシステムを開発する上で、コスト最適化を実現するために工夫した点を紹介します。
デモグラフィックターゲティングとは
ユーザーの性別や年齢などの情報をもとに、広告を配信するターゲティング手法です。詳細な説明はGoogleに任せます。
システムの全体像
デモグラフィックターゲティングを実現するために、バックエンドでは、ユーザーのIDを受け取り、IDに紐づくデモグラフィックデータを返すAPIを実装します。amebaではシステム刷新が進んでおり、インフラ層をAWS上に統合する、AmebaPlatformという構想があります。今回開発するシステムも、このプラットフォーム上に構築します。よって、APIサーバーはAmazon EKSを利用します。DBは、Amazon DynamoDBを選択しました。事前に、データモデル、データの件数、パフォーマンス要件などの情報を詳細に得られたので、ワークロードに合わせてDBを選定しました。デモグラフィックターゲティングでは、ユーザーの属性情報を扱うので、DBにデモグラフィックデータを保持する必要があります。このデモグラフィックデータは、社内のデータ処理基盤である、Patriotから取得します。Patriotは、データ転送先としてAmazon S3をサポートしているので、デモグラフィックデータを社内のデータ処理基盤からパブリッククラウドに集める準備ができました。今回、S3に集めたデータを処理するサービスとして、AWS Glueを利用することにしました。
AWS Glue
AWS Glue は、分析を行うユーザーが複数のソースからのデータを簡単に検出、準備、移動、統合できるようにするサーバーレスのデータ統合サービスです。分析、機械学習、アプリケーション開発に使用できます。また、ジョブの作成、実行、ビジネスワークフローの実装のための生産性向上に役立つツールやデータ運用ツールも追加されています。
ドキュメントへのリンクはこちらです。
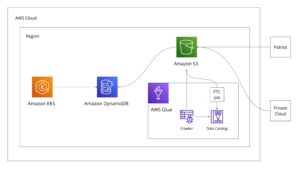
S3のデータをDynamoDBのテーブルに書き込む前に、データを加工する必要があります。まず、PatriotからS3にデータを転送する際に、クエリを実行してデータを整形することができます。デモグラフィックデータのデータソースがPatriotに全てあれば、Glueを経由する必要はなかったかもしれません。しかし、デモグラフィックデータのデータソースはPatriot以外にもあります。今回は、プライベートクラウドのデータも利用する必要がありました。複数のデータソースからデータを収集して、特定のロジックでデータを整形し、DynamoDBのテーブルに書き込む必要があります。いわゆる、ETLと呼ばれる処理です。Glueには、AWS Glue Data Catalogというコンポーネントがあります。これは、AWS クラウド内にある永続的な技術メタデータストアです。そして、GlueはS3などにあるデータのスキャン、分類、スキーマ情報の抽出、そのメタデータの AWS Glue Data Catalog への自動保存ができるcrawlerを設定することが出来ます。これらの機能を利用して、データをPatriot, プライベートクラウドからS3に転送し、Glueのcrawlerでデータを収集、分類して、Data Catalogに保存し、ETL jobでロジックを実装することにしました。バックエンドのシステムの全体像を表した図を添付します。
DynamoDBのテーブルへの書き込み
ここからが記事の本題です。Glueを利用して、デモグラフィックデータを収集、加工、整形するフローまでは整いました。残るは、DynamoDBのテーブルへの書き込みです。書き込み方法を決めるために、前提条件を定めます。
- DynamoDBのテーブルの項目は、1日毎に全項目を入れ替える
- DynamoDBのテーブルの項目数は、3億
- DynamoDBのテーブルのストレージのサイズは、20GB
- DynamoDBのテーブルの項目のサイズは、1KBより大きい項目は存在しない
- DynamoDBのテーブルへの目標書き込み時間は、5時間
仮に上記のような条件が与えられた場合、どんな方法でテーブルに書き込むのが最適でしょうか。実際にコストを概算して比較してみましょう。
パターン1
まず、単純な方法として、GlueのETL jobでデータを加工しているので、jobからDynamoDBのAPIを呼び出して、テーブルに書き込む方法が思い浮かびます。DynamoDBでテーブルへの読み込み、書き込みを考える上で、read/write capacity modesを考慮する必要があります。
Amazon DynamoDB には、テーブルで読み込みおよび書き込みを処理するための読み込み/書き込み容量モードが 2 つあります。
– オンデマンド
– プロビジョニング済み (デフォルト、無料利用枠の対象)
ドキュメントへのリンクはこちらです。
本来、DynamoDBのキャパシティーモードを検討する際は、読み込み、書き込みの両方のワークロードの特徴を考慮する必要があります。ただし、この記事ではシンプルにコストを比較するために、書き込みの条件だけを考慮します。書き込みのキャパシティーモードとして、オンデマンドを選択した場合を考えてみましょう。
オンデマンドモード
Amazon DynamoDB オンデマンドは、容量計画なしで 1 秒あたりに数千ものリクエストを処理できる柔軟な請求オプションです。DynamoDB オンデマンドには、読み取りおよび書き込みリクエストのリクエストごとの支払い料金が用意されているため、使用した分だけ課金されます。
オンデマンドモードでは、事前に書き込みキャパシティーユニット(以後、WCUと記載)を指定する必要はありません。一般的に、リクエストの量が変動するワークロードに適しているとされます。今回のケースだと、前提条件にテーブルへの書き込みの頻度が定められています。テーブルへの書き込みは1日おきなので、デイリーです。プロビジョンドキャパシティモードだと、事前にWCUを確保して、時間単位で課金されますが、オンデマンドモードだと、書き込みリクエストに対してのみ課金されます。今回のバッチ処理のようなワークロードだと、オンデマンドモードが適していると言えます。では、料金を見積もってみましょう。料金の計算には、AWSが提供しているAWS Pricing Calculatorを利用します。
| Region | ap-northeast-1 |
| DynamoDB features | DynamoDB on-demand capacity |
| Table class | Standard |
| Data storage size(GB) | 20 |
| Average item size (KB) | 1 |
| Standard writes(%) | 100 |
| Transactional writes(%) | 0 |
| Number of writes(per Day) | 300,000,000 |
| Total Monthly cost(USD) | 13,026.16 |
上記の値を入力した結果、月額のコストは、13,026 USDでした。1ドル130円で計算すると、1,693,380円です。これは、とても許容できるコストではありません。
プロビジョンドキャパシティモード
次に、プロビジョンドキャパシティモードで計算してみましょう。
プロビジョニングモードを選択した場合、アプリケーションに必要な 1 秒あたりの読み込みと書き込みの回数を指定します。Auto Scaling を使用すると、トラフィックの変更に応じて、テーブルのプロビジョンドキャパシティーを自動的に調整できます。
つまり、WCUは書き込み時間に反比例します。WCUを増やせば増やすほど、書き込み時間は短くなります。項目のサイズが1KBより大きい場合、DynamoDBは追加のWCUを消する必要がありますが、今回の前提条件で、1KBより大きい項目は存在しないと仮定しているので、1項目の書き込みに必要なWCUは、1WCUとなります。前提条件では、S3へのデータの転送時間、ETL jobの実行時間、デイリーの処理が失敗した場合のリカバリ対応の時間などを考慮して、テーブルへの目標書き込み時間を、5時間と設定しています。WCU、書き込み時間、コストの関係を表した表を記載します。
| 項目数 | WCU | 書き込み時間(hour) | 月額コスト(USD) |
月額コスト(JPY)
|
| 300,000,000 | 5,000 | 16.7 | 2,671 | 347,256 |
| 300,000,000 | 10,000 | 8.3 | 5,342 | 694,512 |
| 300,000,000 | 15,000 | 5.6 | 8,014 | 1,041,768 |
| 300,000,000 | 20,000 | 4.2 | 10,685 | 1,389,024 |
| 300,000,000 | 25,000 | 3.3 | 13,356 | 1,736,280 |
| 300,000,000 | 30,000 | 2.8 | 16,027 | 2,083,536 |
| 300,000,000 | 35,000 | 2.4 | 18,698 | 2,430,792 |
| 300,000,000 | 40,000 | 2.1 | 21,370 | 2,778,048 |
| 300,000,000 | 45,000 | 1.9 | 24,041 | 3,125,304 |
| 300,000,000 | 50,000 | 1.7 | 26,712 | 3,472,560 |
| 300,000,000 | 55,000 | 1.5 | 29,383 | 3,819,816 |
| 300,000,000 | 60,000 | 1.4 | 32,054 | 4,167,072 |
| 300,000,000 | 65,000 | 1.3 | 34,726 | 4,514,328 |
| 300,000,000 | 70,000 | 1.2 | 37,397 | 4,861,584 |
月額コストは、下記のような式から計算可能です。
1WCUの1時間あたりの料金(USD):0.000742
WCU:5,000
0.000742(USD) × 5,000(WCU) × 24(時間) × 30(日) = 2,671 USD
1ドル130円で計算すると、347,256円です。
目標書き込み時間は5時間なので、書き込み時間が4.2時間で済む20,000WCUの場合の料金は、1,389,024円です。こちらも、とても許容できるコストではありません。
書き込み時間を長くすれば、コストは抑えられるのか
プロビジョンドキャパシティモードの表を見て、書き込み時間を許容して長くすれば、コストは抑えられると思ったかもしれません。テーブルの更新頻度は1日で24時間あるので、書き込み時間を数十時間にすれば、WCUも減らせてコストを抑えられると。しかし、書き込み時間を長くすると別の問題が発生します。それは、GlueのETL jobの実行時間も長くなるということです。
AWS Glue を使用すると、ETL ジョブの実行に費やした時間に対してのみ支払うことができます。
コストを低くするために、DynamoDBのテーブルへの書き込み時間を長くすればするほど、ETL jobの実行時間は長くなり、Glueのコストは高くなります。ジレンマですね。そもそも、DynamoDBのテーブルへの書き込みに、GlueのETL jobを利用することは、適切ではありません。データの加工、整形を行わないのであれば、Amazon EKSのcronjob, AWS Lambda, AWS Batchなどが適切かもしれません。ただ、いずれにせよ、オンデマンドモード、プロビジョンドキャパシティモードを利用した方法だと、コストが高いです。
パターン2
そこで採用した案が、DynamoDBのS3からのデータインポートです。
Amazon S3 からの DynamoDB データのインポート
文字通り、S3からDynamoDBにデータをインポートする機能です。この場合、料金はインポートするデータのサイズに依存します。リージョンがアジアパシフィック(東京)の場合、料金は、0.171USD per GBです。今回のケースだと、DynamoDBのテーブルのストレージのサイズは20GBという条件なので、
20(GB) × 0.171(USD) × 30(日) = 102.6 USD
1ドル130円で計算すると、13,338円です。
めちゃくちゃ安くなりましたね。
注意点
インポート機能を利用する場合、考慮しなければいけない点もあります。まず、今回コストに大きな差が出たのは、ストレージのサイズが比較的小さかったからです。前提として、1KBより大きいサイズの項目が存在しないという条件があり、ストレージのサイズも20GBと仮定しました。項目のサイズが大きい場合、ストレージのサイズも大きくなり、コストは多少上がるかもしれません。次に、現時点では、既存のテーブルへのインポートは、サポートされていません。必ず新しいテーブルが作成されるということです。今回のケースだと、1日毎にインポート機能を利用するので、アプリケーション側で新しいテーブルを参照するように実装する必要があります。テーブルの新規作成に失敗した場合の実装も必要になるかもしれません。そして、インポート可能なファイルの形式にも制限があります。
まとめ
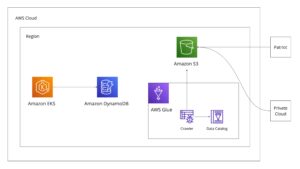
最終的なバックエンドのシステムの構成は下記の図のようになりました。今回は、コスト最適化を実現するために工夫した点を紹介しました。DynamoDBのS3からのインポート機能を利用するメリット、デメリットを比較して、メリットがデメリットを上回ると判断したので、採用しました。ある問題に直面した時、複数の選択肢から最適解を導き出せるように、情報のアップデートを続けたいですね。