
この記事は CyberAgent Developers Advent Calendar 2023 6日目の記事です。
はじめに
こんにちは。タップルでバックエンジニアをしている李 俊浩と申します。普段は主に施策をしていますが、タップルでChatGPTを利用してプロダクトを開発したことがきっかけでタップルの宣伝も兼ねて個人で勉強したLangChainを紹介しようと思います。
タップルでは生成AI(ChatGPT)を利用して業界初!マッチングアプリ「タップル」、ChatGPTでプロフィール文を添削できる新機能「プロフィールAI添削」の提供を開始しておりタップル内でも生成AIの活用事例も多数あります。
今回は、LangChaintの説明と初心者向けの活用事例について解説します。
この記事は、大規模言語モデル(Large Language Model:LLM)やプログラミングの基本的な知識がある方を対象に書いています。
LangChainとは?
LangChain は、大規模言語モデル(Large Language Model:LLM 例: ChatGPT)言語モデルを利用してアプリケーションを開発するためのフレームワークです。様々なモジュールが提供され、これらを組み合わせることで簡単にLLMアプリケーションの開発ができます。LLMアプリケーションの開発ならLangChain、WebアプリケーションならNode.js言語で開発する際はExpressというフレームワークを使うイメージに近いです。
実装はPythonとJavaScript(TypeScript)をサポートしていますが、Pythonがファースト対応で全機能が使えるのでPythonでの開発がおすすめです。
LangChainを使うメリット
LangChainを利用することで、以下の3つの点で効率よく開発ができます。
主にスクラッチでLLMを用いる開発において制約や限界を越えるために利用するイメージです。今回は3点ほどあげます。
1. 長文入力に対応している
2. 最新情報やChatGPTが学習してないデータへアクセス方法が提供されている
3. モジュールを組み合わせることでより複雑なタスクを対応
長文入力に対応している
gpt-3.5-turboなどは日本語で一回あたり約5000文字までしか入力できないです。一般的な質問用途では問題ないレベルですが、ページ数の多いPDFや本などを取り込んで質問に答えさせたいなどのユースケースに簡単に対応できません。
最新情報やChatGPTが学習してないデータへアクセス方法が提供されている
ChatGPTのWeb browsing機能はWebで最新情報を取得することはできますが、APIはまだサポートしていません。そしてChatGPTが学習してない自社プロダクトの情報やセキュリティに敏感な社内データなどを連携する場合スクラッチ開発になるため、全ての設計と実装を最初から行う必要があります。
モジュールを組み合わせることでより複雑なタスクを対応
こちらが本来のLangChainの強みでもあります。
命令文であるプロンプトのモジュールとモデルのモージュルを選択して繋げることで結果を得られるという簡単なタスクから「1.ページ数の多いPDFを読み込んで 2.ページ数と文字数で分割して 3. 分割した文字(チャンク)を保存して 4. 質問して回答を得るなど複雑なタスクにも簡単に実装することができます。
LangChainのモジュール
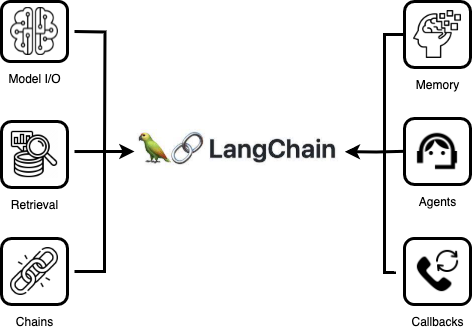
Model I/O
あらゆる大規模言語モデルを統一インタフェースで入力と出力を可能にする機能です。
Model I/Oは「Prompts・Language models・Output parsersの3つの機能で構成されています。
1. Promptsとは?
Promptsはプロンプトの入力に当たります。変数を受け取るテンプレートのPrompt templatesと多数の例文を与えてその中で条件に基づいて例文を選ぶ必要があるときに有効です。
2. Language modelsとは?
様々なサービスのモデルを利用する機能です。この機能は2つのChat models・LLMsに分かれます。
Chat modelsはチャット形式で入力してやりとりする機能、LLmsはテキストを入力してテキストを返してもらうモデルのことです。
LLMs vs Chat Models
LangChainを使う前にLLMsとChat Modelsの基本的な違いについて説明します。
LLMsは基本的な言語モデルです。プロンプトを与えると、チャットが返されます。 1つのメッセージが入力され、1つのメッセージが出力されるイメージです。
Chat Modelは会話型になるように微調整されたLLMです。実行時にチャット履歴全体を渡して複数のメッセージが入力され、1つのメッセージが出力されるイメージです。
3. Output parsers
出力の定義です。様々なアウトプットをサポートしていて、例えば、JSON形式でフォーマットを返してもらいたいときにPydantic (JSON) parserを使うことでJSON形式で出力することも可能です。
Retrieval
LLMが学習してない or 学習できなかった外部データを加味して回答させたい時に利用します。例えば、社内データやプロダクト情報などをLLMに学習せずRAG(Retrieval Augmented Generation)という検索拡張機能を用いて検索することができます。
Agents
プロンプトと共にツールを用いてアクションを引き起こしその結果を回答に加味する機能です。
例えば、ChatGPTがまだ学習していない最新情報を加味して回答してもらいたいときにプロンプトと共にGoogle検索やBing検索のツールを利用して最新情報を取得して回答してもらうことも可能です。
サポートしている有名なツールでは「Google Search・Wikipedia・Bing Search・AWS Lambda・OpenWeatherMap API」などがあります。
Chains
ある一連の動作をいい感じに処理してくれる機能です。例えば、ページ数の多いPDFを要約しようとします。一番シンプルなやり方はLLMに対してPDFを入力して要約してということです。この結果はどうなるでしょうか?トークン数の制限事項でエラーになる可能性が高いです。そこでPDFを分割してグループ分けして要約した文章を要約することで要約精度があがるしエラーになる心配もありません。
Memory
Memoryは状態(state)を保存する機能です。例えばChatGPTのチャットデータは揮発性データであり過去チャットデータに基づいて回答させるにはMemory機能を利用して保存して会話を保存して教える必要があります。
Callbacks
LangChainは、LLMアプリケーションの様々なステージにフックできるコールバックシステムを提供します。これはロギング、モニタリング、ストリーミング、その他のタスクに便利です。API全体で利用可能なcallbacks引数を使うことで、これらのイベントをサブスクライブすることができます。この引数はハンドラー・オブジェクトのリストで、以下に詳しく説明するメソッドの1つ以上を実装していることが期待されます。
活用事例に
1. LLMアプリケーションに最新情報を追加して回答させる
この事例はOpenAI社のAPIだけでは実現できないWebの最新情報も含めて回答させるコードの説明です。
Web版のChatGPT 3.5モデルでは現状2022年1月までのものしか学習されてないため最新情報は取得できませんでした。
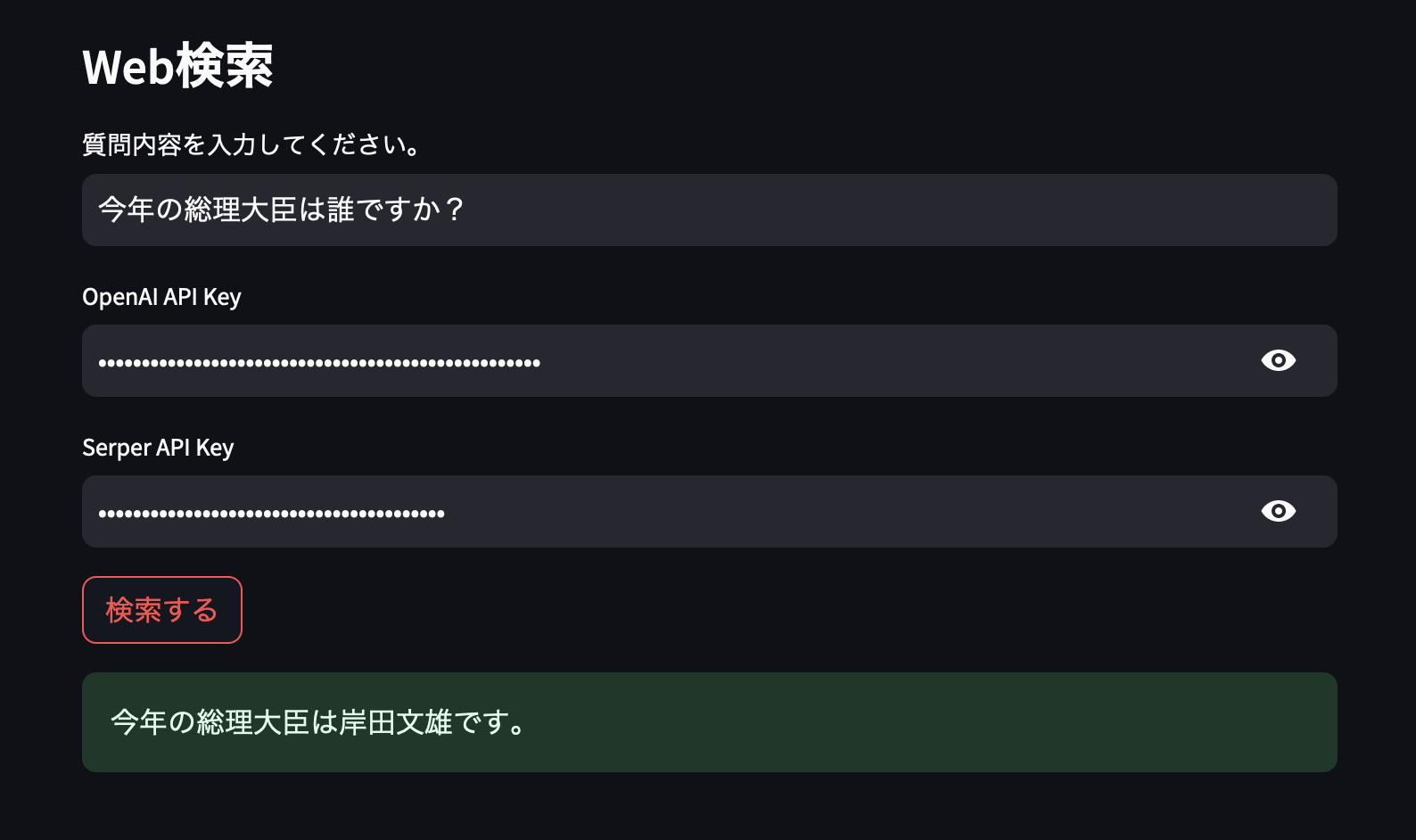
以下の画像では「今年」と「総理大臣」の二つの文脈が含まれている質問とOpenAPIのキー、Google検索を行うためのSerper APIキーを渡してLangChainを実行して結果を得ました。
質問に対してLangChainは以下の画像のように動いてくれます。
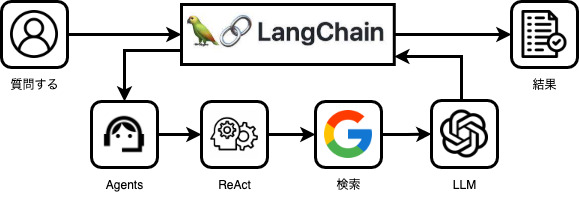
Agentのコードと動き
llm = OpenAI(temperature=0, openai_api_key=openai_api_key, verbose=True)
tools = load_tools(["google-serper"], llm, serper_api_key=serper_api_key)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
result = agent.run(search_query)
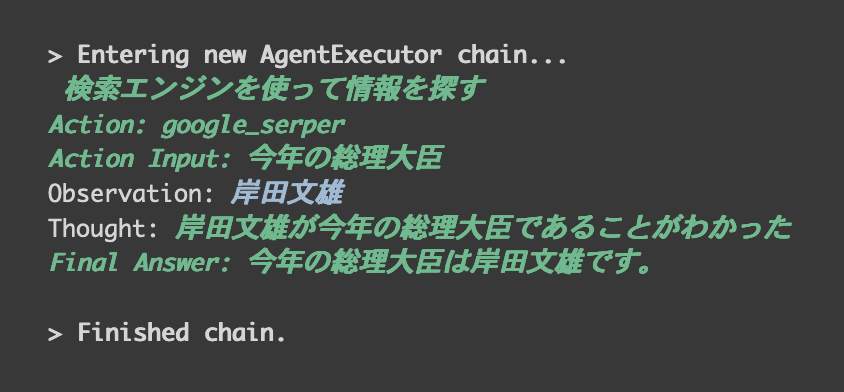
agent=”zero-shot-react-description”について軽く説明します。これはReActフレームワークという手法で簡単にいうと1. 考えて 2. アクションを起こすという作業の繰り返して結果を得ています。(上記の画像の「検索エンジンを使って情報を探す」が1で、「1の考えた結果に基づいて2のgoogle_serperを利用してActionを起こす」になります)
この場では説明が長くなってしまうため、軽く触れましたが、興味がある方はこちらをご参照ください。
完全ソースコード(Google Colaboratory)
2. URL入力してサイトを要約する
今回はURLを入力しそのURLの内容を要約してくれるアプリケーションを実装します。
フロー図は以下の画像のように動きます。
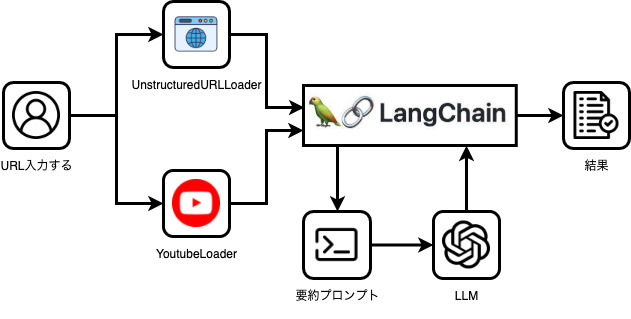
コードも非常にシンプルです。ユーザーの入力URLを判定しYoutubeのURLの場合はYoutubeLoaderを呼び出してデータを取得(中の処理はtranscriptを取得してテキストデータを取得)しYoutubeのURLではない時はUnstructuredURLLoaderを呼び出してHTMLのテキストからデータを取得します。
それぞれのloaderからデータの取得が完了したらChatOpenAIのgpt-4モデルを利用して要約を行います。
ここで重要なポイントが二つあります。
1. 要約プロンプトに文字数の制限をかけることで結果が変わる
2. chain_typeを変更することで精度が向上する場合がある
1.に関してはプロンプトテンプレートの内容を日本語で変更するだけですぐ確認できますが、2.に関しては実装が少し変わります。
今回はstuffを使って一番シンプルな方法でしますが、map_reduceやrefineをすることで要約をチャックで分割しそれぞれ要約をすることで要約の品質の向上とそれに伴いAPIコールが増える短所もあります。
# URlからデータの取得
if "youtube.com" in url:
loader = YoutubeLoader.from_youtube_url(url, add_video_info=True, language="ja")
else:
loader = UnstructuredURLLoader(urls=[url], ssl_verify=False, headers={"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13_5_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"})
data = loader.load()
# ChatOpenAI モジュールを初期化し、要約チェーンを実行します。
llm = ChatOpenAI(temperature=0, model='gpt-4', openai_api_key=openai_api_key)
prompt_template = """以下の内容を日本語で1000文字程度で要約してください。
{text}
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="stuff", prompt=prompt)
summary = chain.run(data)
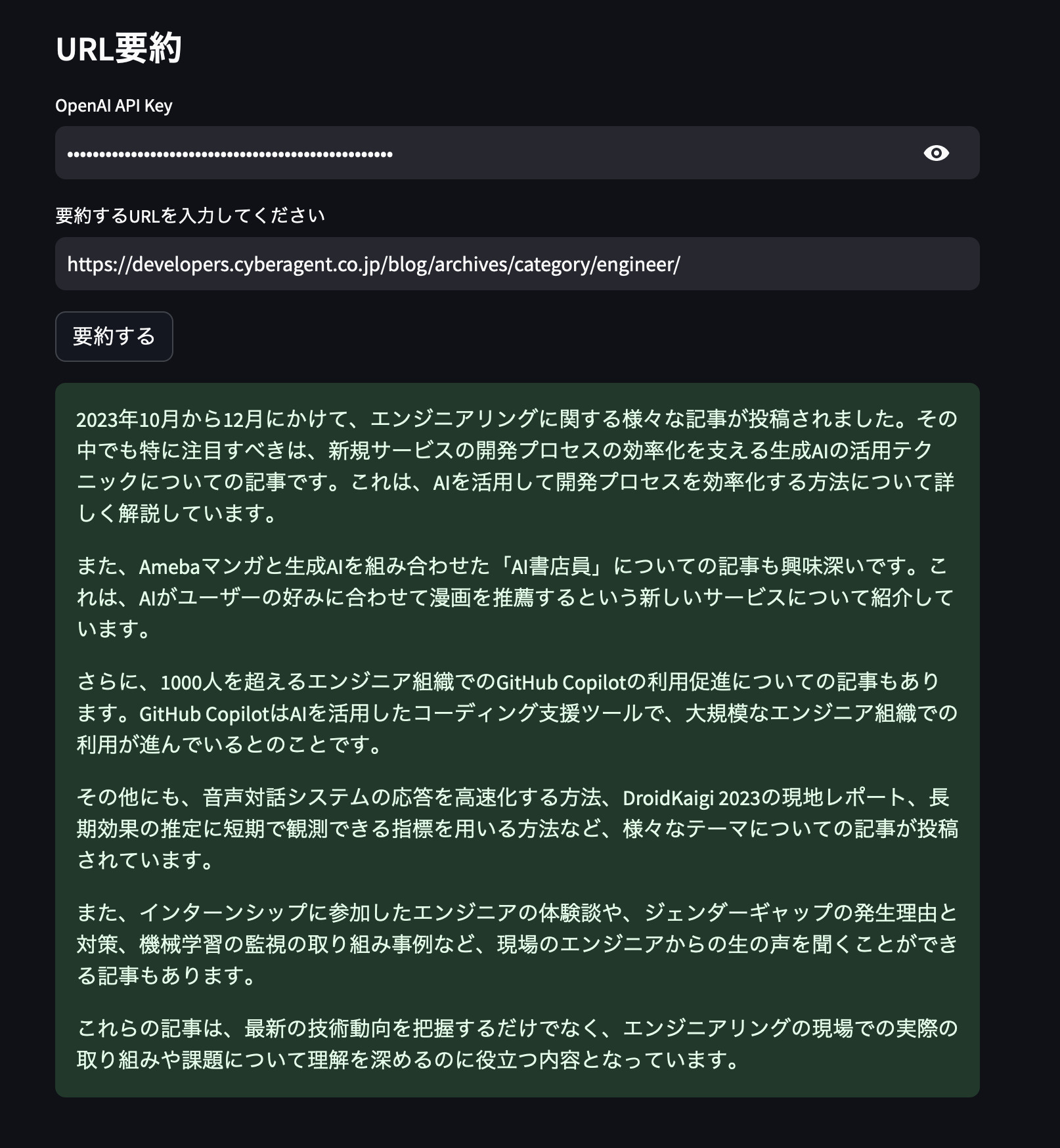
要約するURL
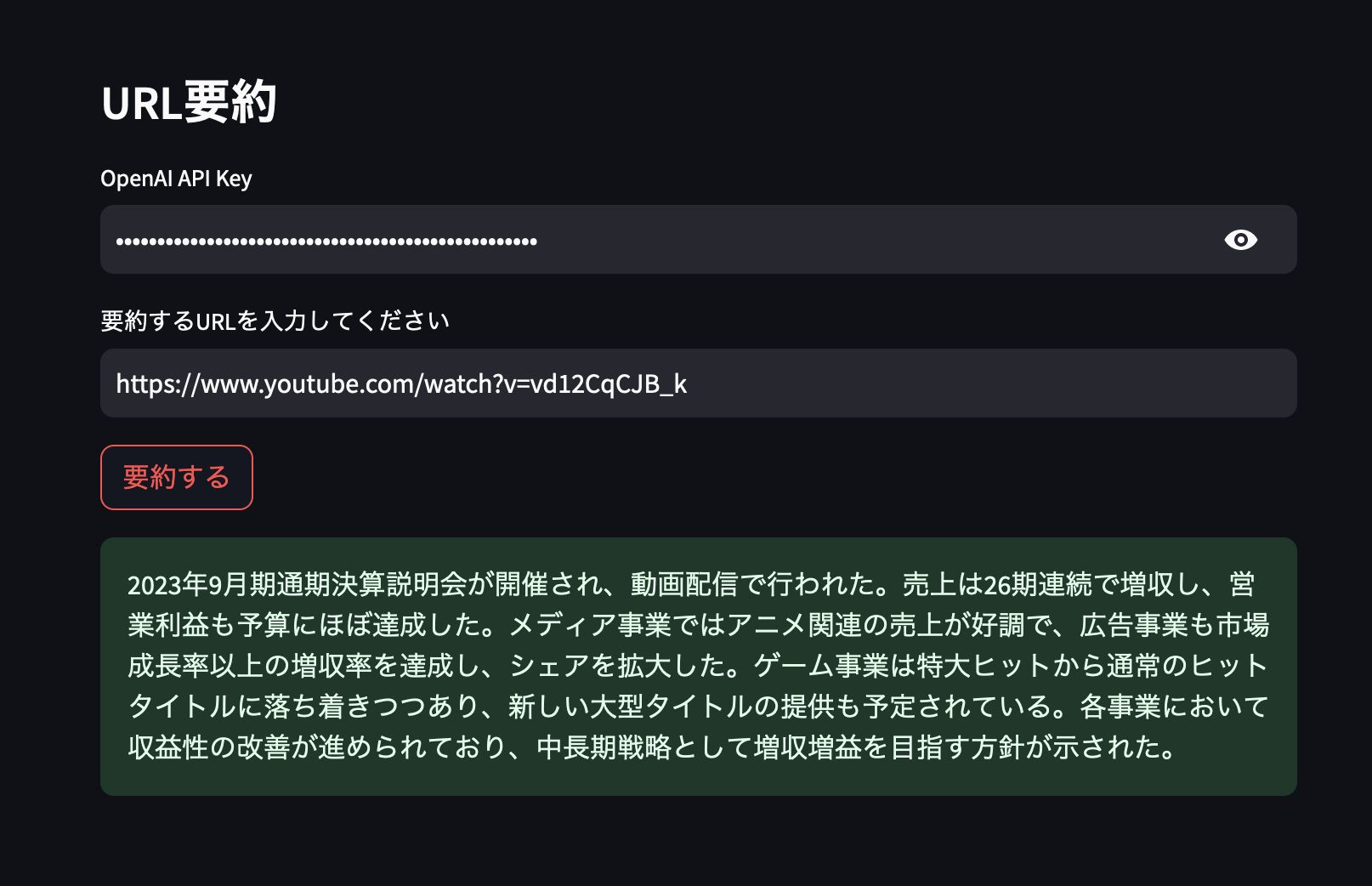
1. CyberAgent 2023年9月期 通期決算発表のYoutube)
2. CyberAgent Developer BlogのエンジニアのトップページURL
それぞれの要約結果です。
Yotubueの要約

CyberAgent Developer Blogの要約
完全ソースコード(Google Colaboratory)
まとめ
今回はLangChainの説明と活用事例についてまとめました。
- 大規模言語モデル(Large Language Model:LLM 例: ChatGPT)言語モデルを利用してアプリケーションを開発するためのフレームワークです。
- LangChainを利用することで3つのメリットがあります。長文入力に対応・最新情報やChatGPTが学習してないデータへアクセス方法が提供されている・モジュールを組み合わせることでより複雑なタスクを対応
- LangChainのモジュールの説明とLangChainのメリットの恩恵を最大限受けられる活用事例
個人的には活用事例のコードを少し変更するだけでプロダクトの仕様書に関する品質向上や検索性の向上、要約を一目で把握することで理解度の向上などにつながると思います。ぜひみなさん色々試してください。最後までお読みいただきありがとうございます。