
この記事は CyberAgent Developers Advent Calendar 2023 11日目の記事です。
はじめまして。株式会社MG-DX でバックエンドエンジニアをしています、北田です。
MG-DX では医療機関・クリニックや薬局を予約して、オンライン診療・オンライン服薬指導が受けられる 薬急便 というサービスを提供しています。
近年、企業の業務効率向上と課題解決において、様々な技術の導入が進んでいます。
特に、LLM(Large Language Model)はその中でも注目されており、社内業務においてもその有用性が確認されています。
今回は LLMを活用する一方で、LangChainとRAG(Retrieval Augmented Generation)を組み合わせて、外部データを活用した回答生成の手法に焦点を当てます。これにより、社内データやプロダクト情報を学習せずに利用し、より高度な検索拡張機能となることが期待されます。
前提
- OPENAI_API_KEY の発行が前提の記載があります。
- Slack API が利用可能である前提の記載があります。
- Google Cloud Platform が利用可能である前提の記載があります。
- 記載のコードは実際の運用とは異なり、説明の簡易的なものとなっています。
LangChainの活用とLLM導入における期待
LLMの導入により、言語モデルの力を借りることで新たな可能性を提供しています。
特に、膨大な情報を素早く理解し、的確な回答を生成することが期待されますが、多くのインターフェースを持つLangChainでも、その適用方法や最適な設定は重要であり的確な対応が求められます。
LangChainとは
LangChainは言語モデル(LLM)を利用したアプリケーション開発のためのフレームワークです。
GitHubで開発されており、執筆直前ではスター数が70kを超えています。
三ヶ月間の Release Tagを見ても、v0.0.279から v.0.348までアップデートされていて、リリース頻度が非常に高いフレームワークとなっています。(下書き時点でさらに2つ上がってました)
CyberAgent Developers Advent Calendar 2023 6日目の記事にも、LangChainに関する記事がありますので是非、一読ください!
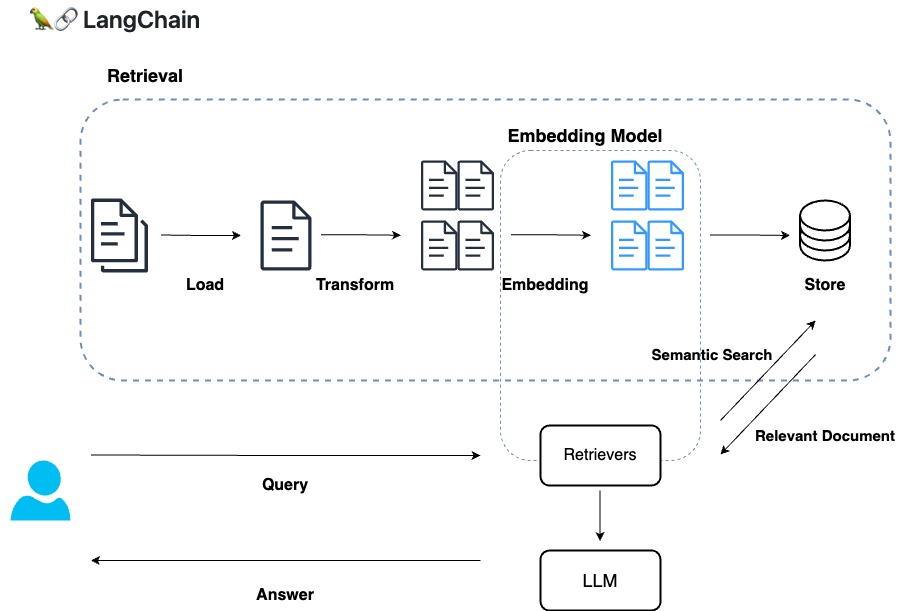
RetrievalAugmentedGeneration(RAG)
自然言語処理(NLP)のタスクにおいて、情報検索(Retrieval)と生成(Generation)の両方を組み合わせた手法です。
大規模な文書集合から関連性の高い情報を検索し、その情報を元に新しい文章や答えを生成します。
RAGは情報検索とテキスト生成の両方を組み合わせることで、より正確で詳細なテキスト応答を生成することができます。
Embedding
自然言語処理(NLP)におけるEmbeddingとは、単語や文といった自然言語の情報を、その単語や文の意味を表現するベクトル空間にマッピングする方法です。
Embeddingは、浮動小数点数のベクトル (リスト) として出力されます。2つのベクトル間の距離によって、それらの関連性が測定でき、距離が小さい場合は関連性が高いことを示し、距離が大きい場合は関連性が低いことを示しています。
OpenAIのサイトでは以下の説明があります。
OpenAI のテキスト埋め込みは、テキスト文字列の関連性を測定します。埋め込みは、一般的に次の目的で使用されます。
- 検索 (クエリ文字列との関連性で並べ替えられた結果)
- クラスタリング (テキスト文字列が類似度によってグループ化される)
- Recommend (関連するテキスト文字列を持つアイテムをお勧めします)
- 異常検出 (ほとんど相関のない外れ値を特定)
- 多様性尺度(類似度分布の分析)
- 分類 (テキスト文字列が最も類似したラベルによって分類される場合)
Faiss
FAISS(Facebook AI Similarity Search)は、Meta社が提供する、高性能な類似性検索ライブラリです。
FAISSは、大規模な高次元ベクトルのデータセットに対して高速な類似性検索を行うために設計され、
類似性検索は、例えば画像、音声、テキストなどのデータセットにおいて、あるクエリと最も類似したデータを見つけるために使用されます。
FAISSはCPUとGPUの両方で動作し、大規模なデータセットに対しても高速な検索性能を提供します。
Retrieval Module
CSVデータを Retrievalモデルで処理し、DocumentLoadersから Retrievarsまでを簡単に実装してみます。
- Document Load: CSVLoader
- DirectoryLoaderを使い、ローカルの dataディレクトリから、CSVファイルを読み込みます。
- Transform: RecursiveCharacterTextSplitter
- チャンクサイズの制限を下回るまで再帰的に分割するTextSplitterです。
- Embeding: `text-embedding-ada-002`
- 執筆時点のOpenAI標準のEmbeddingsモデルを利用します。
- Vector Store: Faiss
- ローカルで利用可能Vector Storeである、Faissにベクトル化したドキュメントを保存します。
下記のディレクトリ構成と、CSVサンプルデータデータを用意します。
|- data
|- data.csv
|- vectorstore
data.csv
No,歌人,上の句,下の句,上の句(ひらがな),下の句(ひらがな) 1,天智天皇,秋の田のかりほの庵の苫をあらみ,わが衣手は露にぬれつつ,あきのたのかりほのいほのとまをあらみ,わがころもではつゆにぬれつつ 2,持統天皇,春過ぎて夏来にけらし白妙の,衣干すてふ天の香具山,はるすぎてなつきにけらししろたへの,ころもほすてふあまのかぐやま 3,柿本人麻呂,あしびきの山鳥の尾のしだり尾の,ながながし夜をひとりかも寝む,あしびきのやまどりのをのしだりをの,ながながしよをひとりかもねむ 4,山辺赤人,田子の浦にうち出でてみれば白妙の,富士の高嶺に雪は降りつつ,たごのうらにうちいでてみればしろたへの,ふじのたかねにゆきはふりつつ 5,猿丸大夫,奥山に紅葉踏み分け鳴く鹿の,声聞く時ぞ秋は悲しき,おくやまにもみぢふみわけなくしかの,こゑきくときぞあきはかなしき
from langchain.document_loaders import DirectoryLoader, CSVLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.faiss import FAISS
FAISS_DB_DIR = "vectorstore"
# Document Loaders
loader = DirectoryLoader(path="data", loader_cls=CSVLoader, glob='*.csv')
raw_docs = loader.load()
# データ件数
print(len(raw_docs))
# Document Transformers
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=50)
docs = text_splitter.split_documents(raw_docs)
# Embedding
embeddings = OpenAIEmbeddings()
faiss_db = FAISS.from_documents(documents=docs, embedding=embeddings)
# Vector Store
faiss_db.save_local(FAISS_DB_DIR)
# Retrievers
retriever = faiss_db.as_retriever()
query = "おくやま"
context_docs = retriever.get_relevant_documents(query)
print(f"len={len(context_docs)}")
first_doc = context_docs[0]
print(f"metadata={first_doc.metadata}")
print(first_doc.page_content)
このコードでは おくやま を検索の queryに指定しています。
これを実行すると、vectore storeが作成され、以下の様に出力されます。
|- data
|- data.csv
|- vectorstore
|- index.faiss
|- index.pkl
index.faiss, index.pklは、Faissが作成したファイルです。
5
len=4
metadata={'source': 'data/data.csv', 'row': 4}
下の句: 声聞く時ぞ秋は悲しき
上の句(ひらがな): おくやまにもみぢふみわけなくしかの
下の句(ひらがな): こゑきくときぞあきはかなしき
5つのドキュメントであること、Retrieverの queryに近い文章が出力されていることが確認できます。
Embeddingに OpenAIのEmbeddingの text-embedding-ada-002を使用しましたが、multilingual-e5-base に切り替える場合は、`HuggingFaceEmbeddings(model_name=”intfloat/multilingual-e5-base”)`に変更するだけです。
Chat Bot化
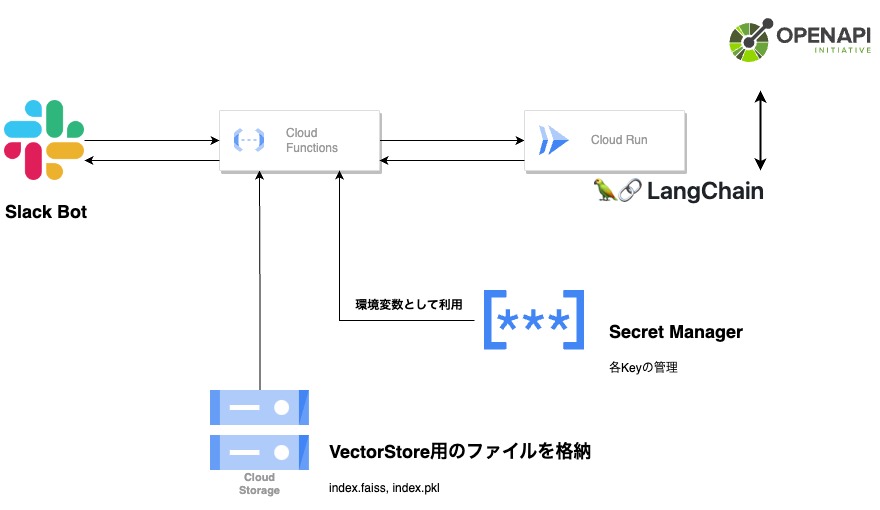
上記では、Vector Storeの検索を行いましたが、Google Cloud Platformで動くサーバレス構成を簡単に挙げます。
- 各キーは、Secret Managerで管理され、Cloud Functionsのシークレットとして管理します。
- Vectore Storeも都度の生成は必要がないため、Cloud Strage上で管理します。
Slackにストリーミングで回答する
Slackへの回答が長時間かかる場合、利用側が不安に感じることがあります。
それがボットが動いているのか、回答の生成に時間がかかっているのかを利用側にわかりやすく伝えることは重要です。
そこで、逐次的なストリーミング回答が役立つかもしれません。ChatGPTのWEB UIでは、ユーザーがリアルタイムでモデルの出力を見ることができるため、これをSlackへの回答にも取り入れてみましょう。
具体的な実装方法として、Slackへの投稿時間と現在日時のインターバルで逐次的な回答を返す方法が考えられます。
次の実装を例に考えてみます。
import time
from langchain.callbacks.base import BaseCallbackHandler
# チャット更新間隔(秒)
CHAT_UPDATE_INTERVAL_SEC = 3
# Slack bolt app.
app = App(token=os.getenv("SLACK_TOKEN"),
signing_secret=os.getenv("SLACK_SIGN_IN_SECRET"),
raise_error_for_unhandled_request=True
)
class StreamingCallbackHandler(BaseCallbackHandler):
last_send_time = time.time()
message = ""
def __init__(self, channel: str, ts: str):
self.channel = channel
self.ts = ts
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
"""Run on new LLM token. Only available when streaming is enabled."""
now = time.time()
self.message += token
if now - self.last_send_time > CHAT_UPDATE_INTERVAL_SEC:
self.last_send_time = now
app.client.chat_update(channel=self.channel, ts=self.ts, text=f"{self.message}...")
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Run when LLM ends running."""
app.client.chat_update(channel=self.channel, ts=self.ts, text=self.message)
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Run when LLM errors."""
コードの一部を取り上げ、特に on_llm_new_tokenメソッドに焦点を当ててみます。
on_llm_new_tokenは、ストリーミングが有効である場合のみ、LLMから新しいトークンが生成されるたびに呼び出され、生成されたデータをリアルタイムで受け取ることができます。
BaseCallbackHandlerを継承した、StreamingCallbackHandlerと命名したクラスを作成し、ストリーミングを行うための on_llm_new_token をオーバーライドします。
class StreamingCallbackHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
ChatOpenAIの、callbacks引数に指定します。
on_llm_new_token をオーバーライドした処理に従い、回答がストリーミングされます。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, streaming=True, callbacks=[callback])
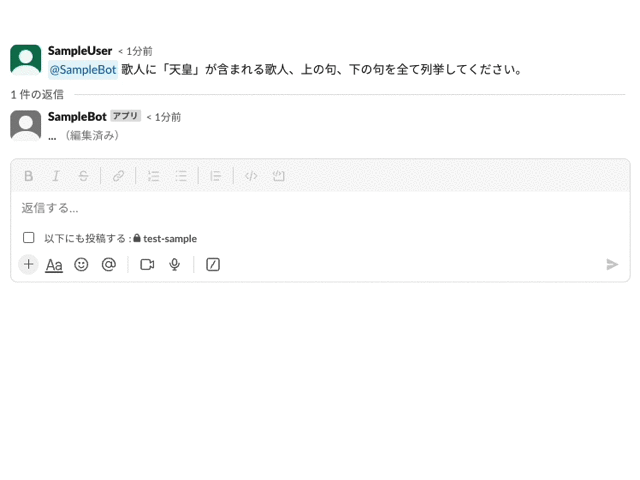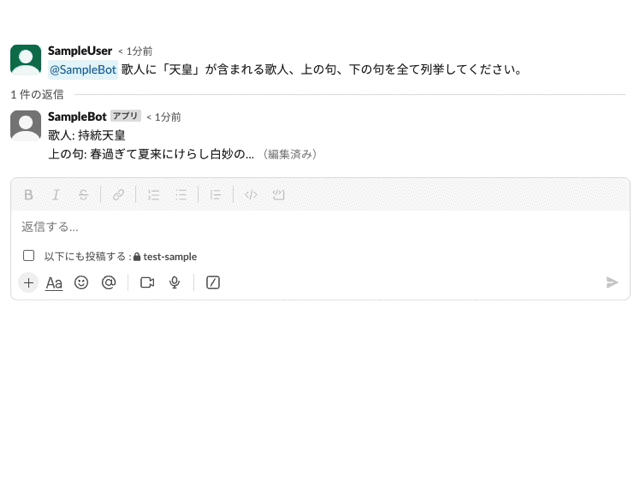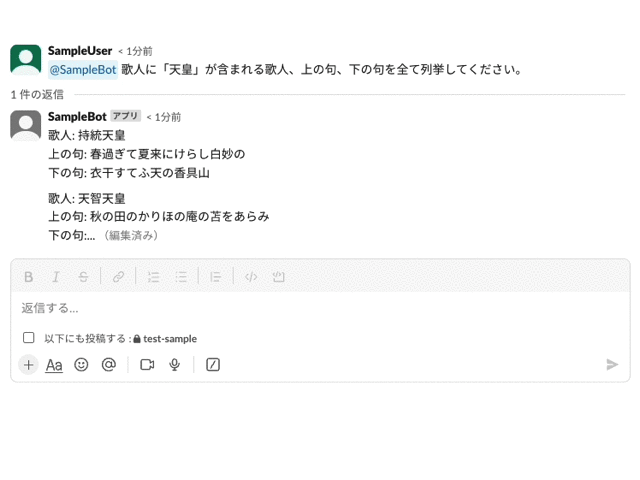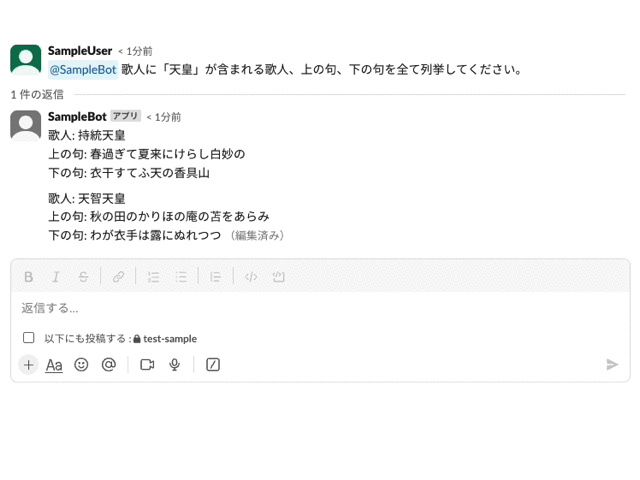
簡易な実装のため、これだけでは SlackのAPIレート制限に触れてしまう可能性があります。
利用する際は、利用環境に応じた最適化が必要です。
最後に
今回は、LangChainとLLMの組み合わせによるデータ連携手法のご紹介でした。
今後もLLMはもちろんのこと、次世代技術の展望に目を向け、新たなツールや手法を積極的に導入することで、より良いサービス提供を目指します。