
この記事は CyberAgent Developers Advent Calendar 2023 12日目の記事です。
はじめに
CIU (CyberAgent group Infrastructure Unit) の西北(@nishi_network)です。
普段はプライベートクラウド (Cycloud) や機械学習基盤の運用、それに伴う開発業務に従事しています。
今回は、サイバーエージェントの生成AI開発を支える裏側にフォーカスを当て、機械学習基盤の設計や運用、また最新のNVIDIA H100 機械学習基盤構築プロジェクトの裏側について紹介していきます。
サイバーエージェントの機械学習基盤
サイバーエージェントでは、社内向けにAI用途向け機械学習基盤をパブリッククラウド環境だけではなくオンプレミス環境でも運用しています。これらは全社組織であるCIUが運用しており、データセンターの運用からサーバー・ネットワークの構築、更にはマネージドサービスとして提供するまでを一貫して行っています。
弊社ではこれまでパブリッククラウド上のGPU資源を活用してきましたが、高額な費用やクラウド上のGPU資源の枯渇が問題となっていました。
そこで、2020年にNVIDIA社のA100 GPUをCIUが運用しているデータセンターに導入し、機能検証などを実施した後に社内向けに提供を開始しました。
その後、社内の需要に応じてNVIDIA A100 GPUなどの増強を続け、2023年にはLLM(大規模言語モデル)などの大規模な生成AI開発に対応するため、NVIDIA DGX H100サーバーを国内で初導入するなど、社内の需要に対して十分なGPU資源を提供できるよう増強を進めています。
弊社が公開している商用利用可能なLLMであるCyberAgentLM2も、このGPU資源を活用して開発されました。

NVIDIA H100 機械学習基盤構築プロジェクト
サイバーエージェントでは2023年1月にNVIDIA DGX H100サーバーを国内で初導入を発表しました。その裏側でプロジェクトメンバーは2022年から検証・設計を開始し、2023年5月から運用を開始しています。
この基盤では、合計80基のNVIDIA H100 GPUを導入したほか、NVIDIA A100 GPUなどその他のGPUも多数運用しています。
最新の機械学習基盤を構築するには様々なハードルがあり、使用する機器の調査・選定や検証に時間を費やすこととなりました。
その中で特に時間を要したのは、使用予定の機材の仕様を確認して必要な機材を確定する作業でした。まだ発売前でベンダー側で開発中の仕様も確定していない機材の情報を入手しながら進めて行く必要があり、仕様が変更されることも多く度々設計変更を余儀なくされました。
また、GPU間接続ネットワーク(いわゆるインターコネクト)において400GbEの採用にあたり、接続規格に関する情報が十分ではなく、検証機材を借りるなどして手探りで相互接続性を確認する作業が必要になりました。
またデータセンター選定においても、データセンター側も実績がないような電力規模ということもあり、データセンター側と機器の収容や電力・冷却について議論を行いながら進める必要があり最終的な選定まで約半年を要しました。

400GbEを使用した高速なGPU間接続ネットワークについては、JANOG 52にてネットワーク担当が発表していますので公開されている資料をぜひご覧ください。
また、このプロジェクトについて CyberAgent Way でも公開されていますのでぜひご覧ください。
オンプレミス環境で機械学習基盤を運用する難しさ
オンプレミス環境で機械学習基盤を運用しようとすると、従来のCPU資源を提供する計算基盤とは違った難しさに直面します。ソフトウェア・ハードウェア面問わず様々な難しさがありますが、今回はハードウェア(ファシリティ)面としてデータセンターの運用に関わる部分について紹介していきます。
データセンター設計
まず、大きく異なる点は1サーバーあたりの消費電力が桁違いであるということです。
一般的なサーバーでは1台あたりの消費電力は数百W程度です。それに対して高性能なGPUサーバーは1台で6000W ~ 10000W (6kW ~ 10kW) 程度の電力を消費します。この消費電力は一般家庭数世帯分の消費電力に相当し、電力の消費とともに膨大な熱を放出します。
これは、様々な課題を生み出します。
一般的なデータセンターでは、1ラックあたり4~6kVAの電力供給が限界です。そのため多くのデータセンターでは1ラックあたり1台も設置できないということになります。こういった場合、2ラックに1台だけ設置するといった対応を取ることで設置自体は可能となるケースもありますが、集約率や実質的に使用できない間引いたラックの運用コストなどが課題となってきます。
また、サーバーが消費する電力は、冷却ファンに使われる電力を除くとその大半は熱へと変換されます。そのため、電力消費量に対応した冷却設備が必要となり、これも一般的なデータセンターでは対応が難しいものです。
しかしながら、近年ではこういった需要に対応したデータセンターが増え始めています。これらのデータセンターは、1ラックあたり20kVA程度の電力を供給できるようになっており、GPUサーバー2~3台搭載することが可能になっています。これにより、高性能なGPUサーバーを限られた空間でより効率的に設置することが可能になりましたが、従来のサーバーのようにラックの上から下まで設置するといったことはできません。
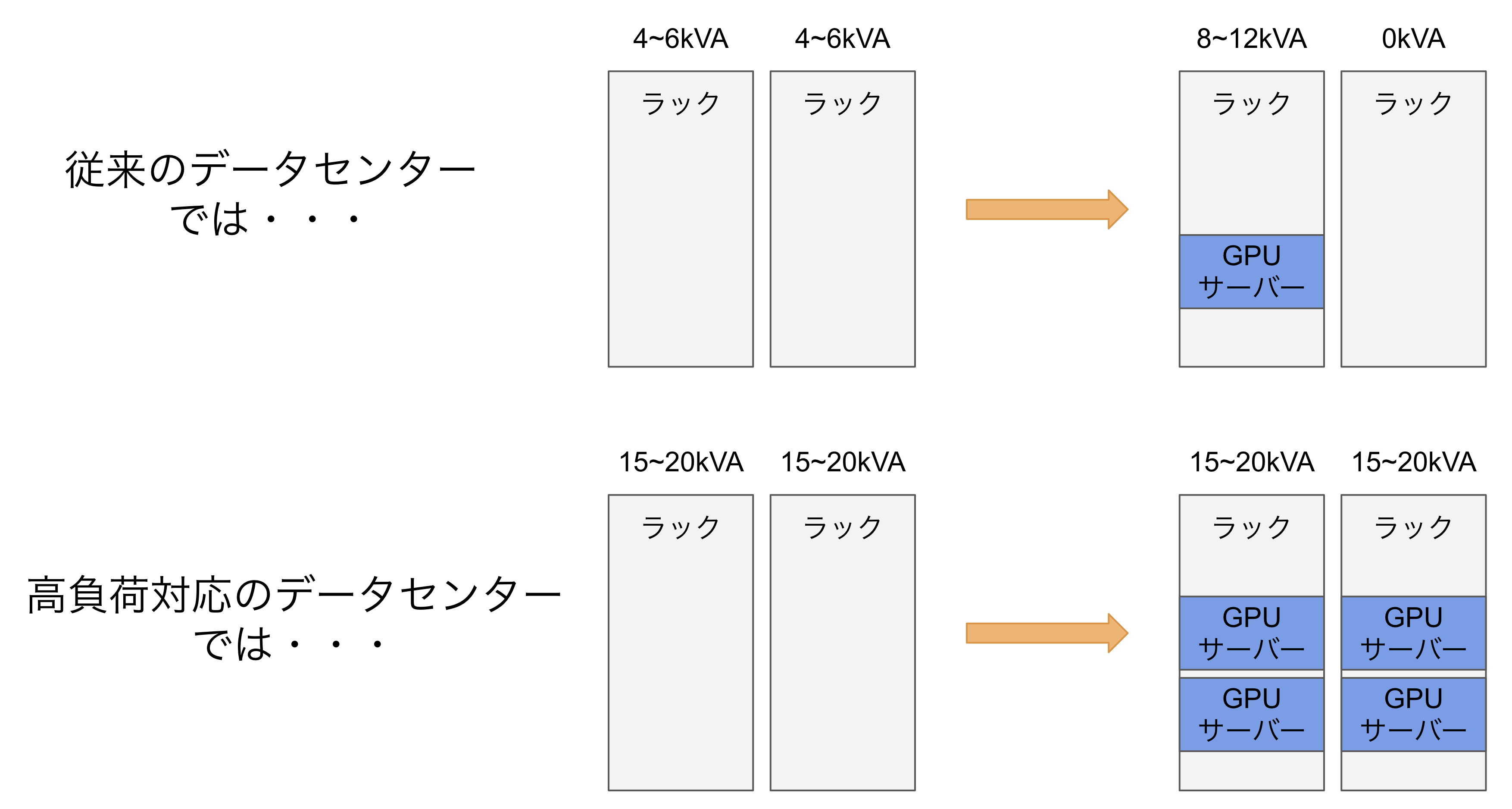
弊社のオンプレミス機械学習基盤では、高負荷対応のデータセンターを選定した上で、可能な限り効率的な設置が可能となるようにラックごとに電源回路数を調整するなどの工夫を行い運用しています。
運用面
一般的なサーバーでは、CPUにかかる負荷が常に100%となることは稀です。特に商用環境の場合、いわゆるゴールデンタイムと呼ばれる時間帯に負荷が上昇し、深夜早朝に落ち着くのが一般的です。しかし、GPUサーバーではGPUをフルに活用して計算を行うため、掛かる負荷が常に100%になることも珍しくありません。
GPU・CPUはともに半導体であり、高負荷な状態で継続的に使用されるということは故障発生の可能性が高くなることを意味します。
実際、CIUが運用しているGPUサーバーでも高頻度でGPUの故障が発生しています。これはCPUの故障率とは全く比べ物にならない故障率となっており、高い頻度で保守業務が発生しています。
また、GPU間を接続するネットワークとして400Gbpsで通信可能なネットワークを構築しており、この電気信号を光信号へと変換する光トランシーバも高頻度で故障が発生しています。
こういった面からも、従来のオンプレミス環境と比較してもより効率的な運用体制の構築が必要不可欠になってきます。弊社では、OSを自動インストールできるような仕組みを開発した他、Ansibleを用いて初期セットアップの手間を減らすなど、技術的に解決できる部分は技術で運用の効率化に取り組んでいます。
知見がない技術領域
こういった最新のGPUを用いた計算基盤を構築・運用するには様々な知識が必要となります。これには、最新のGPUについてはもちろん、GPU間接続の仕組みやプロトコル、高速なネットワーク通信を実現する最新技術、更にはこれらの物理的な規格・仕様などが含まれます。
しかし、どれも最新技術であるがゆえに世界で見てもまだまだ知見が少なく、各ベンダー間の互換性に不明な点が多かったりと、情報が得られないことが多いのが実情です。
実際弊社でも様々な機器をお借りするなどして検証を行いましたが、その中でも実際接続しようとすると物理的に接続できないようなケースで初めて規格の存在を知ったりと、手探りで進めていくような状況で設計面や構築面で難しさを感じた一面でした。
オンプレミス環境で機械学習基盤を運用するメリット
オンプレミスで機械学習基盤を運用するメリットは、弊社の場合は主に3つあります。
- パブリッククラウド上のGPU資源を活用するより大幅にコスト削減が実現できる
- 社内の需要に応じて、パブリッククラウド上に(まだ)無いGPUモデルを提供できる
- パブリッククラウド上のGPU資源枯渇に対して自社保有のGPU資源で対応できる
まず1つ目のコスト削減については、前項でも示したようにGPUサーバーをオンプレミス環境で運用するとなるとそれなりの初期投資が必要になります。しかしながら、弊社の場合は3~5年運用しその人件費を考慮したとしてもパブリッククラウド費でコストメリットがあり、コスト削減に成功しています。
続いて2つ目の社内の需要に柔軟に対応できる点もメリットの1つです。
パブリッククラウドには無いGPUモデルを提供できることや、まだ対応していない最新のGPUモデルをいち早く提供が可能になります。前者は用途に応じて最適なGPUモデルを選択できることで商用環境においてコストメリットに繋がります。また、後者はいち早く最新のGPUモデルを利用できることで、研究分野などで競争力に繋がります。これらはサイバーエージェントにとって非常に重要な要素の1つです。
最後にパブリッククラウド上のGPU資源枯渇に対応できる点です。
世界的にAI開発が活発となる中、各社がパブリッククラウド上のGPU資源を取り合いするような状況が続いています。弊社ではプロジェクトにより一度にたくさんのGPU資源を必要とするケースも有り、必要なGPU資源が確保できない問題が顕在化してきていました。
こういった課題に対しても柔軟に対応できるのもメリットの1つとなっています。
さいごに
今回は、サイバーエージェントの生成AI開発を支える裏側を紹介しました。
こういった高度なコンピューティング環境の設計から構築、運用までを一貫して行うことに興味がある方、ぜひ新卒採用・中途採用への応募をお待ちしております。