
こんにちは.協業リテールメディアdivでデータサイエンティストをしています須ヶ﨑です.本日はLLMを用いて専門性の高いデータを読み解くというトピックをご紹介します.
また,実際にオープンデータである気象データと,NYCタクシーデータを読み解く例をご紹介します.
専門性の高いデータの読み解きがスケールする嬉しさ
今回の記事での「専門性の高いデータ」とは,気象データや株価推移,POSデータ,時系列行動データ,車の運転データ,センサーデータなど,データ自体が直感的に理解しにくく,理解するためには一定の分析,及び,その読み解きを必要とするようなデータを指しています.
さまざまなビジネスにおいて,色々な分野のデータが当たり前に集められるようになり,データの価値やその活用がとても重視されるようになってきています.これらのデータを基軸としたデータ分析によって、顧客のニーズを的確に把握し、効果的なマーケティング戦略を立案することが可能になります。また、生産性の向上やコスト削減、新たなビジネスチャンスの創出などにも役立てることができます。つまり,競合優位性を生み出す基軸となる資産といえます.
しかし、重要な価値のあるデータであっても、そのままではビジネスに活用することはできません。データを読み解き、その中に潜む意味を理解することが重要です。そのためには、対象となるデータについての専門知識が必要であり、データ分析のスキルを持った人材が求められます。例えば,気象データであれば天気予報士,株価推移であればトレーダー,POSデータであれば小売のマーケターなどが,それぞれ専門家としてデータを読み解き価値につなげています.しかし,それらのデータを読み解くスキルを持つ人は希少であります.
そこで専門性の高いデータを読み解くことのスケールができれば,専門的な人員のリソースを,より専門的な作業などに費やすことが可能になります.
また,スケールすることによって,今までと異なる速度で読み解きが行われることになります.これにより,
- 専門性の高いデータを,読み解いた結果を自然言語で検索することでデータの逆引きができる
- 読み解いた結果を集めて,要約やマーケティング知識を用いた整理ができる
- ほぼリアルタイムに,専門的なデータの読み解いた結果を監視できる.
ようになります.
今回はLLMを用いて,専門性の高いデータの読み解き方の一例をお伝えできればと思います.
専門性の高いデータを読み解く困難さ:気象データを例に
最も身近な例としては天気予報があります.まずはこれをご覧ください.
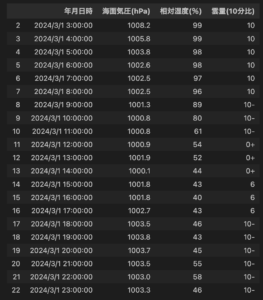
これは2024年3月1日の気象データの一部です.よくみると3時ごろが雲が多く,湿度も高いことから雨降りそうというようなことが言えそうです.しかし海面気圧の推移などは自分に知識がなく,どのように読み解いていいのかがわかりません.また,上記のデータを数ある指標から抜き出して読み解く作業に対しても30分程度かかりました.一方で,気象予報士の方々はこのような気象データを一目で理解し,明日の天気や気温,また,服装のおすすめなどを天気予報として提供されています.
このように,専門性の高いデータを整理し,それを読み解くということは高度な分析スキルによって読み解くことができるもので,一般の人にとっては難しいタスクであります.つまり,専門性の高いデータの解釈をリアルタイムに行うことや複数の場所に対して毎時といった頻度で行うことは,専門的な知識を持つ人材が多く必要であり,現実的でないことがわかります.
今回の取り組み:プロンプトで実現するLLMデータ分析
今回は,LLMをプロンプトのみで利用する(いわゆる,プロンプトチューニング)のみで,専門性の高いデータ分析を実現する方法の一例を紹介します.
専門性の高いデータで起きうる可能性がある,
- ファインチューニング用のデータを大量に用意しにくい.
- ファインチューニングに使ったデータのリークが起こさない方法で実現したい.[arXiv:2403.16139]
ということを考え,プロンプトチューニングのみで実現することにしました.
もちろん,Fine tuningする方法や,言及されている技術としてマルチモーダルなモデルの開発などもなされているため,それらを利用することも可能です.また,今回の記事では,全てプロンプトチューニングで実現しておりますが,対話的な方法への拡張や,各ステップをRAGをはじめとしたLLMの拡張手法を用いて,より高精度にすることも可能です.実際利用する際に精度が足りないなどを感じた場合は適用いただくと良いと思います.
今回はAzureのGPT4.0を用いて実験を行います.
読み解きのためのプロンプトチューニング
今回利用するプロンプトの方針は,専門性を読み解くタスクを,以下の3パートにプロンプト上でタスクを分解し実現します.
- 表形式のデータを言語化する
- 言語化されたデータを,専門性に基づいて読み解き,データが示す意味を言語化した文章の集合にする
- データが示す意味を言語化した文章の集合から,そのデータの要約を行う.
これにより,データの読み込み,専門的な知識を用いたデータの読み解き,読み解かれたデータの解釈をそれぞれ分離して実施します.
実際に気象データを読み解く際に利用するプロンプトは以下になります.
あなたのタスクは,1時間ごとの時系列順で与えられた日本の気象データに対して,1日ごとにその日の気象状態の説明を行うことです.天気の予測については,その日の天気推移の予想,例年とその日の比較,その日におすすめの服装を教えてください.
上記のタスクは,[気象状態の言語化],[気象状態の概要作成],[気象状態概要から天気の予測]の3ステップで行ってください.
回答にはすべてのタスクについて,実施した結果と,タスクで考慮した内容を,タスクごとに分けて出力してください.
ただし,[気象状態の言語化]については代表例のみ出力してください.
[気象状態の言語化]
与えられた気象情報の系列に対して,言語への置き換えを実施してください.
それぞれのデータには"年月日時","海面気圧(hPa)","気温(℃)","風速(m/s)","相対湿度(%)","雲量(10分比)"が含まれています.
START EXAMPLES
input={"年月日時":"2024\\\\/3\\\\/5 00:00:00","海面気圧(hPa)":1021.3,"相対湿度(%)":41,"雲量(10分比)":"10-"}
output="2024年3月5日0時の海面気圧は1021.3hPa,相対湿度は41%で雲量は10割弱です."
END EXAMPLES
[気象状態の概要作成]
与えられた気象情報から,それぞれ早朝,昼,夕方,夜,未明における気象状態の概要を作成してください
その予測を行った理由も明示してください.
START EXAMPLES
input="2024年3月5日0時の海面気圧は1021.3hPa,相対湿度は41%で雲量は10割弱です.2024年3月5日1時の海面気圧は1021.4hPh,相対湿度は41%雲量は10割弱です.2024年3月5日2時の海面気圧は1021.6hPh,相対湿度は46%雲量は10割弱です."
output="2024年3月5日未明は気圧が低くはない,かつ,相対湿度が40%強です"
END EXAMPLES
[気象状態概要から天気の予測]
与えられた気象状態の概要からその日の天気と気温の予測,例年との比較,その日におすすめの服装を教えてください.また,以下の制約を守ってください.
制約
- 気温については必ず含めてください.
- 天気の推移は,「早朝:晴れ(10度程度)->朝:晴れ(10度程度)->昼:曇り(10度程度)->夕方:雨(10度程度)->夜:晴れ(10度程度)->深夜:晴れ(10度程度)」といった流れで教えてください.
- 必ず気象の変化,天気と気温の予測,例年との比較,その日におすすめの服装の5項目を含めてください
- それぞれの項目は,1文でまとめて,箇条書きで出力してください.
数値データの列を,言語の列にする
このタスクでは,データ列を言語に起こすことを指示しています.これはjsonデータをLLMに読み解きやすいように,自然言語に直すタスクを行なっています.このタスクの目的は,LLMがより理解しやすいような言語データへの変換を明示的に行うことにあります.
気象データでは,以下のようなプロンプトを指示しています.
[気象状態の概要作成]
与えられた気象情報から,それぞれ早朝,昼,夕方,夜,未明における気象状態の概要を作成してください
その予測を行った理由も明示してください.
START EXAMPLES
input="2024年3月5日0時の海面気圧は1021.3hPa,相対湿度は41%で雲量は10割弱です.2024年3月5日1時の海面気圧は1021.4hPh,相対湿度は41%雲量は10割弱です.2024年3月5日2時の海面気圧は1021.6hPh,相対湿度は46%雲量は10割弱です."
output="2024年3月5日未明は気圧が低くはない,かつ,相対湿度が40%強です"
END EXAMPLES
研究においてもtableデータをどのように渡して解釈させるのかというテーマである「table to text」が議論になっており,どのようにテーブルデータを渡すべきなのかであったり,TableデータをターゲットとしたLLMなど存在し[arXiv:2310.09263],活発に議論されているようです.
言語の列を意味の列にする
今回の専門性の高いデータを読み解くプロンプトの肝となる部分です.
このタスクでは,専門的な知識を利用して読み解かれたデータを利用して,そのデータを専門性に基づいて読み解き,意味の列への変換を行います.このタスクの目的は,専門的な知識に基づいてデータ自体の意味を生成することで,どんな事象が起きているのかを言語化することにあります.
気象データでは,以下のようなプロンプトを指示しています.
[気象状態概要から天気の予測]
与えられた気象状態の概要からその日の天気と気温の予測,例年との比較,その日におすすめの服装を教えてください.また,以下の制約を守ってください.
制約
- 気温については必ず含めてください.
- 天気の推移は,「早朝:晴れ(10度程度)->朝:晴れ(10度程度)->昼:曇り(10度程度)->夕方:雨(10度程度)->夜:晴れ(10度程度)->深夜:晴れ(10度程度)」といった流れで教えてください.
- 必ず気象の変化,天気と気温の予測,例年との比較,その日におすすめの服装の5項目を含めてください
- それぞれの項目は,1文でまとめて,箇条書きで出力してください.
この例では,実際のデータの言語化結果に出てくる「海面気圧が1021.4hPhである」ということに対して,「1021.4hPhという海面気圧は通常時と比べて気圧が低くはない」という専門的な知識を用いて読み解いている例になります.今回は専門家でない筆者の知識を埋め込んでいますので,この知識をベースとして推論がなされるのかを確認します.
この例ではone shot promptingという手法を用いて,この専門知識の埋め込みを行なっていますが,この知識の埋め込み方については自由度が大きく存在し,プロンプトに関する技術であったり,RAG等を用いてより精度の高い知識の埋め込みを行うことが望ましいです.
意味の列を系列の要約にする
この最後のタスクでは,まとまりで解釈されたものを,要約や予想,解釈を行います.このタスクの目的は,知識で解釈された意味に対して,どのようなことが解釈できるのかを出力することにあります.
気象データでは,以下のようなプロンプトを指示しています.
[気象状態概要から天気の予測]
与えられた気象状態の概要からその日の天気と気温の予測,例年との比較,その日におすすめの服装を教えてください.また,以下の制約を守ってください.
制約
- 気温については必ず含めてください.
- 天気の推移は,「早朝:晴れ(10度程度)->朝:晴れ(10度程度)->昼:曇り(10度程度)->夕方:雨(10度程度)->夜:晴れ(10度程度)->深夜:晴れ(10度程度)」といった流れで教えてください.
- 必ず気象の変化,天気と気温の予測,例年との比較,その日におすすめの服装の5項目を含めてください
- それぞれの項目は,1文でまとめて,箇条書きで出力してください.
今回の例では,この要約部分は行なってほしいタスクに対する制約を与えることで実現しています.
この部分についても,few shot promptingなどを適用することで,要約に関するフォーマットや,どのような知識を用いて要約してほしいのかなどを与えることも可能です.
実験結果
以下が,読み解いた結果になります.詳しいプロンプトチューニングについては,次の章で議論します.
気象データ
2024年3月1日の東京観測所の気象データ [気象庁] を用いて,その日の気象の移り変わりのトレンドを読み解き,その日のおすすめの服装などについて出力します.
このタスクには,気象情報の読み解き方という専門的な知識に加えて,予測された気候においてどんな服装をすればいいのかという一般知識を必要とするタスクです.
利用するデータは,気象庁が提供している気象観測データの中の,東京観測所の2024/03/01のデータを利用します.入力するデータは,時刻情報,海面気圧,相対湿度,雲量の四項目とします.
この例では,前の章で作成したプロンプトを用いて,実際に私の気象についての知識を埋め込んだ解釈が行われるのか確認します.
通常のプロンプトによる結果
プロンプト:以下の気象データに対して,その日の天気推移の予想,例年とその日の比較,その日におすすめの服装を教えてください.
[{json形式のデータ},...]
結果:
このデータを見ると、2024年3月1日の天気は以下のように推移すると予想できます。
- 早朝から午前中にかけては海面気圧が下がり続け、相対湿度と雲量が高いため、雨や曇りの可能性が高いです。
- しかし、午後になると海面気圧が上昇し、相対湿度と雲量が減少するため、天気は回復し、晴れる可能性が高いです。
- 夜になると再び海面気圧が下がり、相対湿度と雲量が増加するため、雨や曇りの可能性が再び高まります。
例年の3月1日と比較すると、相対湿度と雲量が高いため、天気は例年よりも悪い可能性があります。ただし、具体的な比較を行うためには、過去の同日のデータが必要です。
服装のおすすめとしては、朝と夜は雨具が必要な可能性があるため、傘やレインコートを持って出かけることをおすすめします。また、湿度が高いため、通気性の良い服装を選ぶと快適に過ごせるでしょう。午後は天気が回復すると予想されますが、朝と夜の天候変化に備えてレイヤードスタイルの服装が良いでしょう。
今回提案するプロンプトによる結果(最終出力抜粋)
- 天気の推移:早朝は曇り(気温は10度程度)→昼は曇りから晴れ(気温は15度程度)→夕方は晴れ(気温は20度程度)→夜は曇り(気温は15度程度)→深夜は曇り(気温は10度程度)
- 気象の変化:早朝から昼にかけて雲が晴れ、夕方から夜にかけて再び雲が出ると予想されます。
- 天気と気温の予測:全体的に曇りから晴れの一日となると予想されます。気温は10度から20度の間で変動すると予想されます。
- 例年との比較:例年と比較して、気温は平均的で、天気は比較的安定しています。
- その日におすすめの服装:昼間は暖かいので薄着で過ごせますが、早朝と夜は冷え込むため、羽織るものがあると良いでしょう。
当日の天気と気温
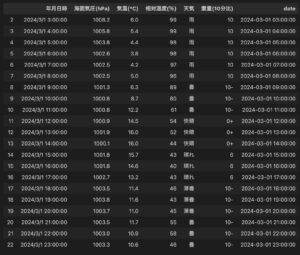
気象データの読み解き結果としては,通常のプロンプトでうまくいっている印象です.特に早い時間で雨が降っていること,および,お昼頃にについては両方のプロンプトで当てられています.
一方,提案するプロンプトにおいては,気温と天気の予測が外れていることがあります.この原因としては,筆者の天気予報の知識を埋め込んだため,GPTが持つ一般的な天気予報の知識より,低い専門性で解釈した結果となっていることが一因として挙げられます.つまり,この部分で気象予報士の方がより精度の高いプロンプトを書くことによって,その知識を反映できるということでもあります.
また,通常のプロンプトでは「比較のために過去のデータが必要」と出力しているように,専門的な解釈が埋め込まれていないために,一般的な知識だけでは読み解けない部分が出てきていることも確認できます.
この例で示されたように,今回提案する方法のメリットとして,それぞれのタスクに対して,専門性が高い人がチューニングすることによって,より精度の高い専門性の高いデータが読み解けるということがあります.
NYCタクシーデータ
NYCタクシーデータセットの例では,専門的な知識の埋め込み部分をすべてLLMに任せるようなプロンプトを用いて実験を行い,専門性の埋め込みを行わない際の影響を測ってみます.
2024年1月のニューヨークのタクシーの移動についてのデータを用いて,JFK空港発のタクシー移動の時間ごとのトレンドを読み解き,利用者の属性を推定してみます.このタスクには,ニューヨークの町がどんな特徴を持つのか,どんな属性の人が集まるかという専門的な知識が必要なタスクです.
利用するデータは,ニューヨーク市が提供しているタクシーの移動履歴データについて,2024年1月mp出発地がジョン・F・ケネディ空港の移動について,到着地点に設定された回数を集計したデータです[TLC Trip Record Data].
通常のプロンプトによる結果
プロンプト:以下の1時間ごとのJFK空港からニューヨークでのタクシーの行き先の設定された回数のデータに対して,何時ごろにどこへの移動が多く存在し,その移動がどのような人物により行われているかを説明してください.また,特異と思われる移動があれば教えてください.
[{json形式のデータ},...]
結果:
データを分析すると、最も多くのタクシーが移動した時間帯は、Lincoln Square Eastへの17時から18時の間で、その回数は8365回です。これは、一般的に職場からの帰宅時間帯にあたりますので、この時間に多くの人々がJFK空港からニューヨーク市内へ移動すると考えられます。
また、特に目立つ移動としては、Upper East Side Northへの14時から15時の間の移動が11252回と非常に多いです。これは一般的な移動パターンから外れており、特定のイベントや集会などが行われていた可能性があります。
このデータからは、移動を行った人物の詳細な情報は得られませんが、時間帯と目的地から推測すると、主にビジネスマンや観光客、地元の住民などが多くを占めていると考えられます。特に、Midtown Centerへの8時から9時の間の移動が8713回と多いことから、この時間帯はビジネスマンの通勤時間と一致します。一方、Times Sq/Theatre Districtへの18時から19時の間の移動が8083回と多いことから、この時間帯は観光客の移動が多いと考えられます。
今回提案するプロンプトによる結果
プロンプト内容
あなたのタスクは1時間ごとのJFK空港からニューヨークでのタクシーの行き先の設定された回数のデータに対して,各時間ごとのニューヨーク州での移動のトレンドを要約することです.
何時ごろにどこへの移動が多く存在し,その移動がどのような人物により行われているかを説明してください.
また,特異と思われる移動があれば教えてください.
上記のタスクは,[移動データの言語化],[地域属性を加味した移動者の属性の推定],[目的地についての時間別の利用者の要約]の3ステップで行ってください.
回答には[目的地についての時間別の利用者の要約]のみを含めてください.また,地域についてはどんな地域なのかの補足もつけてください
[移動データの言語化]
与えられたデータの系列に対して,言語への置き換えを実施してください.
それぞれのデータにはPickUpZoneという名前で移動元,DropOffZoneという名前で移動先,pickup_hourという名前で移動開始時刻,dropoff_countという名前で目的に設定された回数が格納されています.
START EXAMPLES
input={"PickUpZone":"Central Park","DropOffZone":"Midtown Center","pickup_hour":13,"dropoff_count":441}
output="13時にCentral ParkからMidtown Centerへの移動が441回ありました."
END EXAMPLES
[地域属性を加味した移動者の属性の推定]
それぞれの移動に対して,この移動を行なったと思われる人物属性について推定してください.
[目的地についての時間別の利用者の要約]
目的地についての時間別の利用者の要約をしてください.
この際,主要な目的地については3つ,また,主要でない目的地についても3つ含んでください.
また,以下の制約を満たしてください.
- 目的地に対して,目的地の説明を必ず含むこと
- 目的地に対して,JFK空港を出発しとしていること,目的地の説明とその設定された時間から想定される,利用者の属性の推定結果を含むこと
生成された出力
1. **Midtown Center**: ニューヨーク市の中心部に位置し、ビジネスとエンターテイメントの中心地である。午前7時から18時にかけての移動が多く見られ、特に8時には最大で8713回の移動が確認された。利用者は主にビジネスパーソンや観光客と推定される。
2. **Upper East Side North**: ニューヨーク市の高級住宅地域で、美術館やブティックが並ぶエリア。午前8時から22時にかけての移動が多く、特に14時と15時には1万回を超える移動が確認された。利用者は主に地元の住民や文化施設への訪問者と推定される。
3. **Lincoln Square East**: ニューヨーク市の文化的な地区で、劇場やダンススタジオが集まるエリア。午前12時から19時にかけての移動が多く、特に18時には最大で8365回の移動が確認された。利用者は主に芸術愛好家や学生と推定される。
以下に、主要でない目的地とそれぞれの時間帯における利用者の要約を示します。
1. **Clinton East**: ニューヨーク市の住宅地域で、レストランやバーが点在するエリア。午後17時から19時にかけての移動が多く、特に18時には最大で6040回の移動が確認された。利用者は主に地元の住民や飲食店への訪問者と推定される。
2. **East Chelsea**: ニューヨーク市のアートギャラリーが集まる地区。特に18時に5188回の移動が確認された。利用者は主にアート愛好家や地元の住民と推定される。
3. **Murray Hill**: ニューヨーク市の住宅とビジネスが混在する地区。午後14時から21時にかけての移動が多く、特に17時には最大で5700回の移動が確認された。利用者は主にビジネスパーソンや地元の住民と推定される。
NYCタクシーデータの要約結果を見ると,出力フォーマットについては,今回のフローを用いる方法の方が読みやすくはなっていて,出力に制約を与えていることの価値がわかります.しかし,このプロンプトにおいては専門性を用いたデータの読み解き部分をLLMにすべて任せるような構成になっていることにより,出てくる知識としては通常のプロンプトと同様の読み解きしか生成されていません.
このように,専門性については,それぞれのデータの専門家がどう読み解くのかをプロンプトに埋め込むことは,データの読み解きの内容の精度に大きな影響があることがわかります.
今回の方法を用いる際の注意点
上記の実施結果より,今回の手法では以下のような点に気を付ける必要があることがわかりました.
LLMを用いたプロンプトチューニングによる専門性の高いデータ分析は、効率化という大きなメリットを持つ一方で、以下の点に注意する必要があります。
一点目はプロンプトは専門性の高い人が作成する必要があるという点です.効果的なプロンプトを作成するには、分析対象となるデータに関する深い専門知識と、LLMが理解しやすいように指示や質問を表現するスキルが必要です。
二点目は,LLMが出力した分析結果の質について,専門性が高い人による読み解きの妥当性の確認が必要である点です.データの解釈には専門的な知識と経験が必要となるため,分析結果がデータと整合性があるものが出ているのかを確認する必要があります。また,整合性のある分析結果から,妥当な読み解きがなされているのかについても,解釈に対する専門家が妥当であるのかを確認する必要があります.
三点目は,データの量に対してトークン数の制限が存在する点です.自然言語でなく,データをそのままjson等で入力するという特性上,トークン数が大きくかかるような方法になっています.そのため,すべて生データを入れるのではなく,解釈に必要十分な集計を実施してから入力する必要があります.
まとめ
この記事では,専門性の高いデータについてLLMで読み解くというテーマに焦点を当て,プロンプトエンジニアリングを用いて実現する方法を一つご紹介しました.
今回の結果より,必要な情報とともにプロンプトに十分に専門性に基づくデータの読み解き方を埋め込むことができれば,データの解釈をLLMに行わせることが可能であることがわかりました.しかし,専門性の埋め込みを行わなかった場合は,当たり前ですが通常通りLLMを用いているのと同程度の知識しか得られないこともわかりました.
つまり,専門性の高い方がしっかりとプロンプトを作り込むことがとても重要であり,それが可能であれば,専門性の高いデータの読み解くことをスケールできるということがわかりました.
今回は一例ですが,このようなそれなりなレベルの解釈のスケールはLLMの得意分野であるので,皆様の専門的な知識を用いた読み解きのスケール化のヒントになれば幸いです.