
はじめまして。
「ボーイフレンド(仮)きらめき☆ノート」(以降、ボイきら)でサーバサイドエンジニアをしております、伊藤です。今回はAWS(主にAurora周り)とPHPを使用して高信頼性かつハイパフォーマンスなシステムを構築するためのノウハウを共有させて頂きたいと思います。
目次
はじめに
キャッシュの話
自動化・自動生成の話
Auroraの話
Zephirの話
おわりに
はじめに
まずはじめに、ボイきらのサービスとシステムの概要を簡単にご紹介します。
サービスの概要

ボイきらは2016年11月15日にリリースした女性向けリズムゲームです。事前登録は24万人を突破し、リリース後はAppleStoreの無料ランキングで1位を獲得しました。サービスの運用で特徴的なのはリリースが約2ヶ月で以下の5種類の新イベントを計11回も開催していることです。
- マラソンイベント
- レイドイベント
- ハイスコアイベント
- PVPイベント
- バレンタインイベント
システムの概要
一方でシステムの停止時間はメンテナンス時間の6時間とシステム障害の10分で合計6時間10分で、サービスの稼働率は約99.5%です。
またAPIサーバの平均レスポンス時間(動的コンテンツのみ)で計測した場合約140msです。またEC2(c4.2xlarge)1台あたりの最大スループットは350(req/sec)です。
インフラの構成は以下のようになっています。
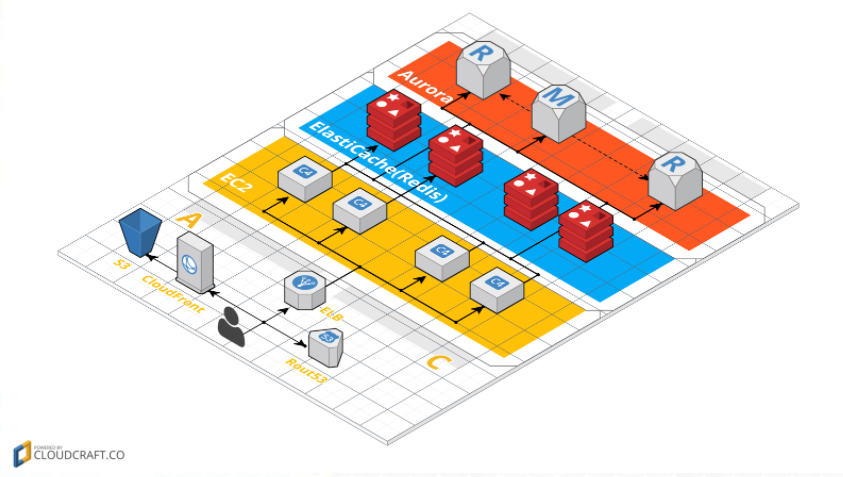
比較的レガシーな構成ですが、以下の3つの点で工夫しました。
CDNの活用
クライアントのアセットやマスターデータ、Webviewなどの静的なコンテンツは全てCDNから配信を行っています。これによって負荷の分散やレスポンス時間の向上を図っています。
ElastiCache(Redis)はインスタンスサイズを抑えて台数を増やす
Redisはシングルスレッドで動作するため、CPUのコア数が増えてもパフォーマンスの向上が見込めません。リクエストが増加した時などに設定ファイルの修正のみで簡単にスケールアウト出来るような実装をしています。
AuroraのReaderを積極的に活用
ボイきらではシャーディングを行っていません。シャーディングはDBの書き込みの負荷分散には有効な手段ですがデメリットもあります。たとえばユーザIDを使用しない検索を行いたい場合に最大で分割数回のクエリを発行する必要が発生します。一般的にシャーディングするテーブルとしないテーブルでDBを分けることで上記のケースが発生しにくくすることが可能ですが、XAトランザクションの実装などが必要になります。Auroraのスケールアップで書き込みの性能も線形的に増加する特性を考慮し、シャーディングを行う必要がないと判断しました。その代わりに読み込みはすべてReaderを使用することで、Writerの負荷分散を行っています。
キャッシュの話
ハイパフォーマンスのシステムを実現するためにはキャッシュを利用することが不可欠です。この章ではボイきらのマスターデータとプレイヤーデータのキャッシュをご紹介します。
PHPにおけるキャッシュの必要性
まずはPHPの言語仕様を簡単にご紹介します。
リクエストごとに独立したメモリ空間を持つ
変数をリクエスト間で共有したりすることは基本的には出来ません。ステートレスの状態で起動することは、メモリリークが発生しにくいなどのメリットはありますが、マスターデータなどをリクエストのたびにDBから取得したりするとパフォーマンスが大きく劣化します。
リクエストごとにスクリプトの読み込みとコンパイルが発生する
サーバを再起動せずにデプロイが可能というメリットはありますが、フルスタックなフレームワークを使用すると相当数なファイルの読み込みとコンパイルが発生するのでこれもパフォーマンスの低下の大きな要因になります。
ボイきらではAPCuとOPcacheを使用することで上記の課題に対処しています。
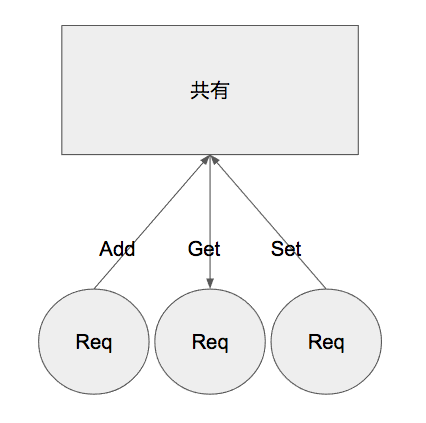
APCuの概要
APCuとはPHP内に共有メモリをもつためのモジュールです。以下の図のようにGET, SET, ADDなどの操作がサポートされています。
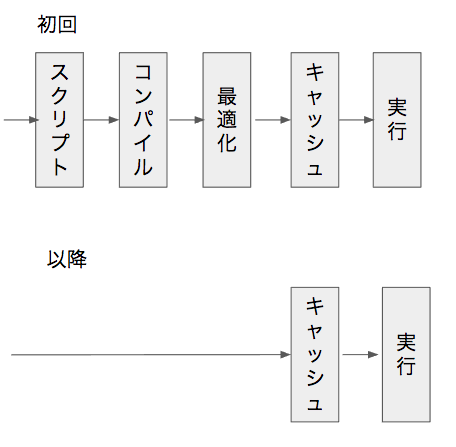
OPcacheの概要
OPcacheとはPHPのオペコードの最適化とキャッシュを行うPHPのモジュールです。以下の図のように初回のリクエストではスクリプトの読み込みなどが発生しますが、その後オペコードをメモリにキャッシュします。以降はキャッシュしたオペコードを直接実行します。
マスターデータ
概要
続いてマスターデータのキャッシュについてご紹介します。
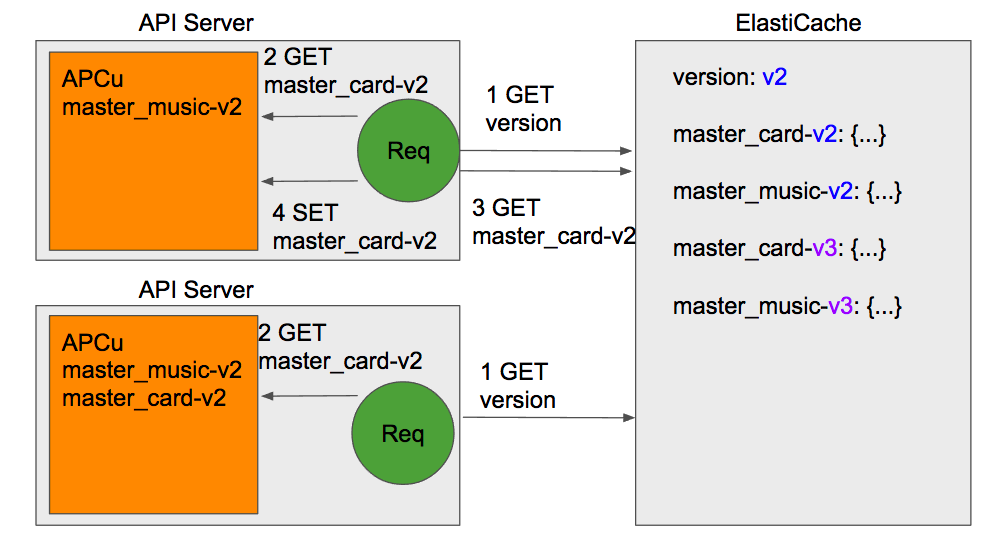
ボイきらでは上記の図のようにマスターデータを1台のElastiCacheと各APIサーバのAPCuに保存しています。
まず各APIサーバからマスターデータの取得する場合の流れをご紹介します。各リクエストではまずElastiCacheからマスターデータのバージョンを取得します。続いてマスターデータ名とバージョンからキャッシュキーを生成して、APCuから対象のマスターデータを取得します。APCuにマスターデータが保存されていない場合はElastiCacheから対象のマスターデータを取得してAPCuにキャッシュします。こうすることで一度取得したマスターはローカルのAPCuにキャッシュされ、その後は通信を行うことなくマスターデータを取得することが可能になります。RedisではなくAPCuを使用した経緯としては、負荷試験で両者を比較した結果APCuのほうが20%ほどスループットが高かった点、各APIサーバにRedisを立てるとその分の監視などの運用コストが増える点などを考慮したためです。
次にマスターデータのリリースの流れをご紹介します。まず次のマスターデータのバージョンから各マスターデータのキャッシュキーを作成しElastiCacheに保存します。次にElastiCacheに保存されたバージョンを新しいものに書き換えます。こうすることで1台のElastiCacheの変更をかけるだけで、各APIサーバのマスターデータを一括して管理することが可能になり、運用コストが減少します。
フォーマット
続いてマスターデータのキャッシュのフォーマットについてご紹介します。
キャッシュのフォーマットにはCSV, JSON, Serialize(PHP独自)などいくつか存在しますが、ボイきらではSerializeを採用しました。採用理由は以下の2点です。
- 正規化されたマスターデータを整形したデータを保存するため
- デコードが高速なフォーマットを使用したかったため
以下の図は1.のデータの整形のイメージです。
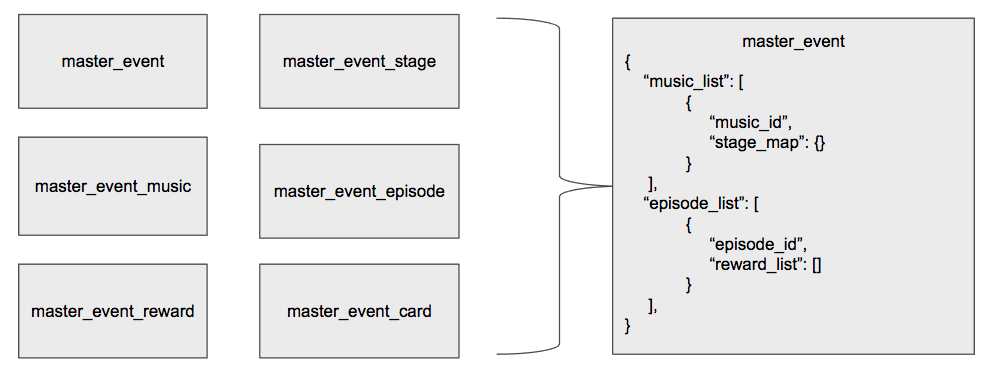
上記の図のように関連するマスターデータをリストやマップなどを使用してまとめることで、多くのAPIでは使いやすいデータのフォーマットになります。一般的には各APIのロジック中にマスターデータを取得して整形することが多いと思いますが、ボイきらではキャッシュ時にこれを行うことで、APIの計算量の削減を行なっています。
続いて2.に上げたデコードの速度をJSONとSerializeで比較した結果をご紹介します。
検証環境はCentOS6.5にPHP7、CPUが1core, メモリが1GBです。また検証に使用したマスターデータはカードマスターで27カラムで1000レコードです。

SerializeのデータはJSONよりも約3倍ほどデコードが高速でした。一方でキャッシュデータのサイズは約1.2倍ほどSerializeのデータの方が大きくなりました。ボイきらでは全てのマスターデータをキャッシュした時のサイズを測定し、今後マスターデータが肥大化した場合でもこのデータサイズの差は問題ない範囲と判断しました。
さらにSerializeのメリットは速度だけではありません。Serializeはエンコード時にクラスのオブジェクトのプロパティやメソッドの情報を保存し、デコード後に使用することが可能です。整形後のデータのアクセスメソッドを実装することで、以下のようにAPIのロジックではデータ構造を意識せずに実装を行うことが可能になります。このようにデータ構造とロジックを分離することでマスターデータの追加や修正に強い実装を行うことができます。
// キャッシュオブジェクトを作成する
$master_event_cache = new MasterEventCache($data);
// オブジェクトから文字列に変換
$master_event_string = serialize($master_event_cache);
// 文字列からオブジェクトに変換
$master_event = unserialize($master_event_string);
// メソッドが使用可能
$master_event->check_term();
$master_event_episode = $master_event->get_music($episode_id);
$master_event_reward_list = $master_event_episode->get_reward($stage_id);
プレイヤーデータ
概要
ボイきらではDBから取得したブレイヤーデータのレコードをリクエスト内の変数にキャッシュしています。キャッシュの主な目的は以下の2点です。
- DBへのアクセス回数を減らすため
- リクエストの最後に更新処理をまとめて実行するため
仕組み
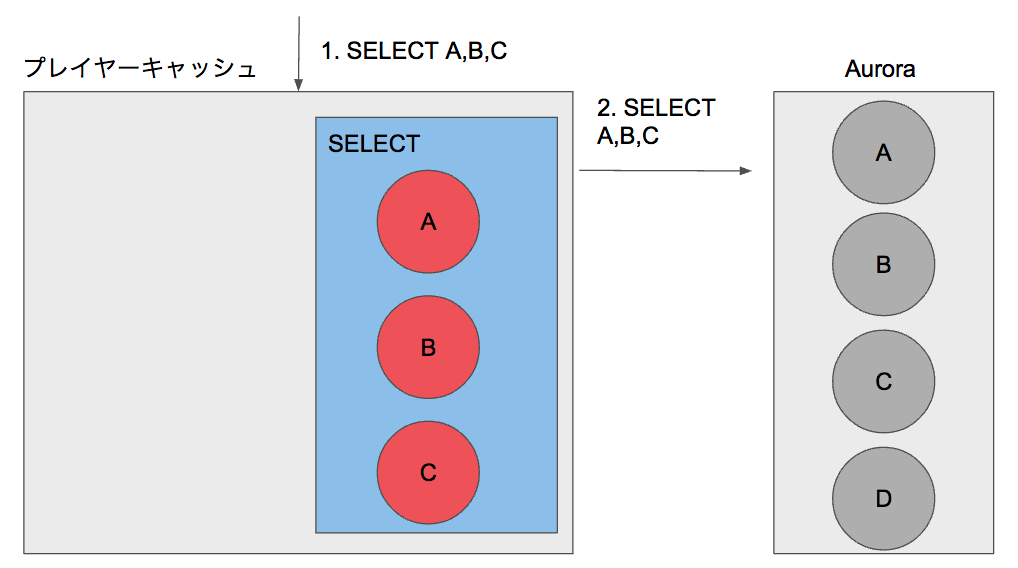
1.と2.を実現するためのキャッシュの流れを以下の図でご紹介します。
ボイきらではAPI実装時にプレイヤーデータを取得する際には原則的にPlayerクラスを使用します。Playerクラスには以下の図のようなキャッシュを保存するための領域が存在します。例えば図のようにAuroraに保存されたレコードA,B,CをSELECTする場合、Playerクラスではまずキャッシュに存在するかチェックします。もし存在しない場合はAuroraにクエリを発行し、取得したレコードを変数にキャッシュします。
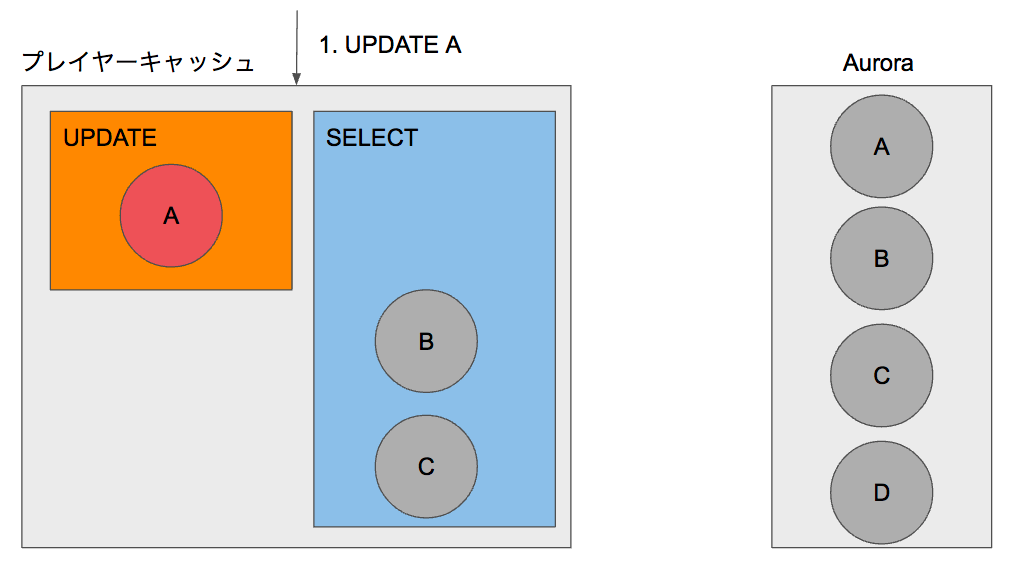
続いてUPDATEの流れをご紹介します。PlayerクラスからレコードAの更新を行うと、SELECTのキャッシュ領域に保存されたモデルを更新し、UPDATEのキャッシュ領域に移動します。この段階ではまだUPDATEのクエリがAuroraに送られることはありません。
さらにINSERTの処理もご紹介します。Playerクラスから新たにレコードEをINSERTすると、INSERTのキャッシュ領域にEのモデルが保存されます。ここでもAuroraにはクエリが発行されません。
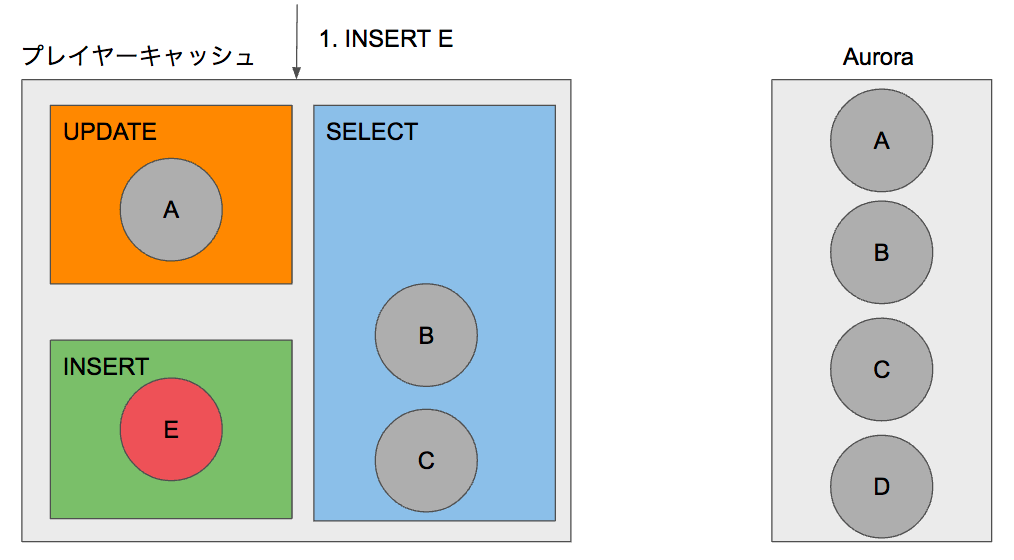
この状態でPlayerクラスからレコードA,B,EをSELECTすると、すべてキャッシュに存在しているためAuroraにはクエリが発行されることなく、キャッシュされたモデルを返却します。
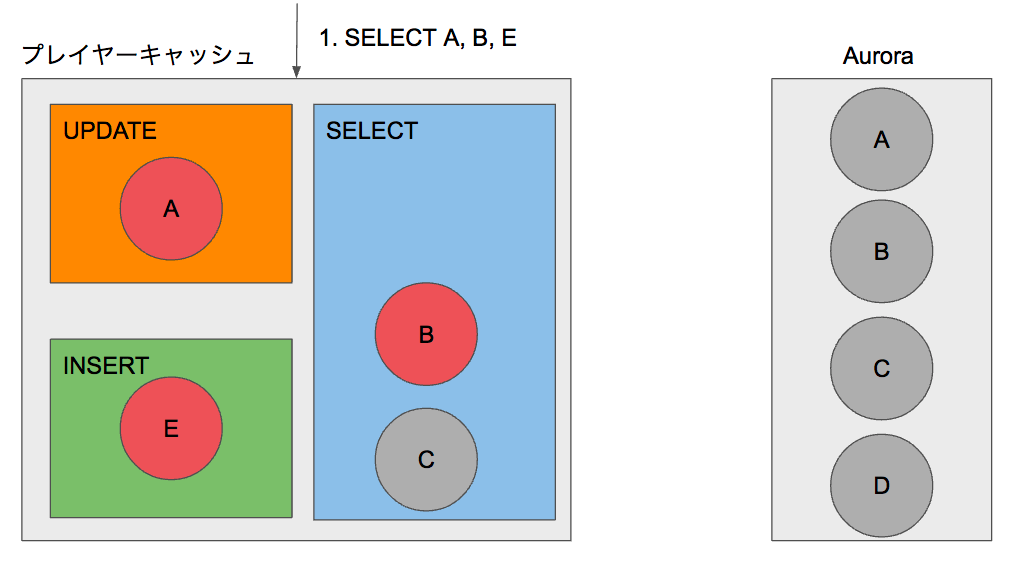
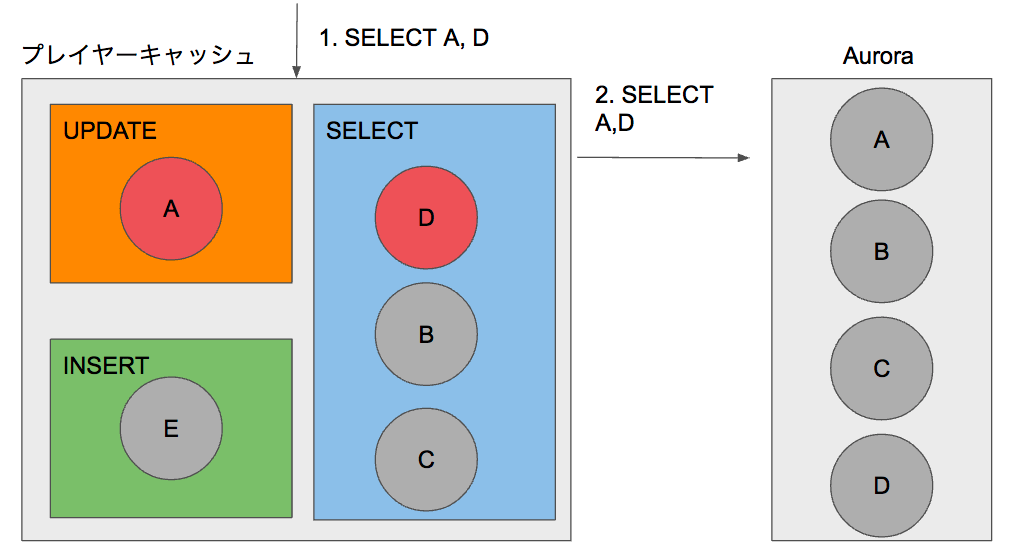
ただしキャッシュに存在するレコードAと存在しないレコードDをSELECTした場合は変則的な処理を行います。まずキャッシュにDが存在しないことを確認し、続いてAuroraからレコードA,Dを取得します。続いてレコードDをSELECTの領域にキャッシュします。最後にUPDATEの領域にキャッシュされたレコードAとAuroraから取得したレコードDのモデルを返却します。キャッシュに既に存在する場合はDBよりキャッシュを優先して返却することで、UPDATEのクエリを発行せずとも一貫したSELECTの結果を担保することが可能です。
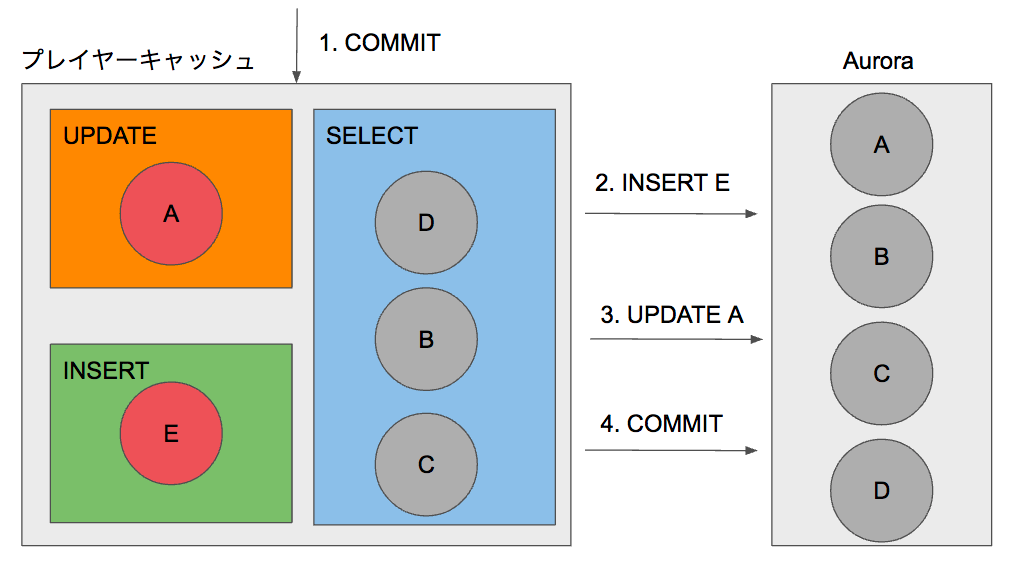
最後にコミットについてご紹介します。ボイきらではリードレプリカを使用してDBの負荷分散を行なっているため、リクエストの最後にまとめて更新系とコミットのクエリが発行しています。Playerクラスでコミットを行うとUPDATEやINSERTの領域に保存されたモデルからクエリを生成して更新とコミットを行います。
キャッシュの有無の判定
ボイきらではSELECTのクエリからキャッシュの有無を判定しています。例えばクエリAとクエリBのWhere句の条件がA = {id: 1, type: 1}, B = {id: 1}だとすると、クエリAはクエリBの上位集合となります。その一方でそれぞれのクエリの結果をリザルトA, リザルトBとするとリザルトAはリザルトBの部分集合となります。つまりWhere句の条件をキャッシュして、比較することでキャッシュの全走査をせずにキャッシュの有無を判別することが可能です。

自動化・自動生成の話
概要
ボイきらでは開発の効率化や運用ミスの削減のため、様々な自動化・自動生成に取り組んできました。本日はサーバの実装周りでの自動化を中心に簡単にご紹介したいと思います。以下は自動化を行なった項目です。
- スプレッドシードで記入されたテーブル定義書からDDLの自動生成
- DDLからサーバのDAOクラスの自動生成
- DDLからテストのモックデータの自動生成
- DDLからテーブル定義のJsonSchemaの自動生成
- テーブル定義のJsonSchemaからマスターデータのバリデーションの自動化
- テーブル定義のJsonSchemaからクライアントのDTOクラスの自動生成
- Req/Res定義のJsonSchemaからコントローラのバリデーションの自動化
- Req/Res定義のJsonSchemaからAPI定義書の自動生成
- Req/Res定義のJsonSchemaからクライアントのDTOクラスの自動生成
上記の自動化・自動生成の仕組みにより、APIを実装する時は以下の2つの作業を手動で行うだけで、サーバとクライアントに必要なファイルが揃います。
- スプレッドシートにテーブル定義を記入
- Req/Resの定義をJsonSchemaのフォーマットで記入
プレイヤーデータの差分管理
ボイきらではクライアントとサーバ間でプレイヤーデータを差分管理しています。差分管理の流れを以下の図でご紹介します。

まずログイン時のレスポンスにサーバはクライアントに対象のプレイヤーの全データを返却します。その後、サーバでは各APIでプレイヤーデータの更新があった場合は、追加・更新・削除があったデータを共通レスポンスとしてクライアントに返却します。クライアントでは共通レスポンスがあった場合、端末に保存した対象のプレイヤーデータを更新します。
この処理をサーバとクライアントがお互いの基盤部分で行うことで、API実装者はクライアントのViewに必要なレスポンスの返却のみを実装すればよくなり、開発工数を大幅に削減することが可能です。
Auroraの話
概要
ボイきらではプレイヤーデータの永続化にRDS Aurora(以降Aurora)を使用しています。通常のRDSとAuroraのMultiAZ構成時の比較を以下の表にまとめました。
 RDSはミラーリング方式のためMultiAZを行うとパフォーマンスが劣化します。一方でAuroraはQuorum方式で全ての書き込みが完了する前にレスポンスを返却するためMultiAZ配置してもパフォーマンスの劣化が少ないです。
RDSはミラーリング方式のためMultiAZを行うとパフォーマンスが劣化します。一方でAuroraはQuorum方式で全ての書き込みが完了する前にレスポンスを返却するためMultiAZ配置してもパフォーマンスの劣化が少ないです。
またRDSは別MultiAZで作成したインスタンスをリードレプリカとして使用することが出来ません。一方でAuroraはMultiAZで作成したインスタンスをリードレプリカとして使用することが可能です。
またレプリ遅延に関してもRDSは負荷に応じて数秒単位まで増加するのに対して、Auroraは概ね20ミリ秒です(ボイきらでは)。
さらにAuroraにはReaderのエンドポイントが存在するため、フェイルオーバー時のエンドポイントの更新などの仕組みをアプリエンジニアが実装する必要がありません。
レプリ遅延対策
以上の特徴からAuroraでMultiAZ構成で使用する場合は、待機系をリードレプリカとして使用することが推奨されます。しかし遅延を考慮した実装がされていないと、以下の状況の時にデータ不整合が発生する可能性があります。
- ボタン連打や不正ツールによって、同一クライアントから並列で複数のリクエストが送られた場合
- 急な負荷増加によってレプリ遅延が増加した場合
- 同ーリクエストの処理中に1度UPDATEしたレコードに対して再度SELECTした場合
ボイきらではプレイヤーキャッシュの仕組みによって3.の場合の不整合は発生しないようになっていますが、1.と2.の対策は行なっています。
並行リクエストの対策
- 各コントローラの最初でユーザIDを使用してロック
- リクエストで送信されたワンタイムトークンとAuroraのWriterに保存されたワンタイムトークンを比較
- ワンタイムトークンが一致した場合は、レスポンスに新しいワンタイムトークンを発行して返却
- ワンタイムトークンが一致しない場合は、エラーを返却
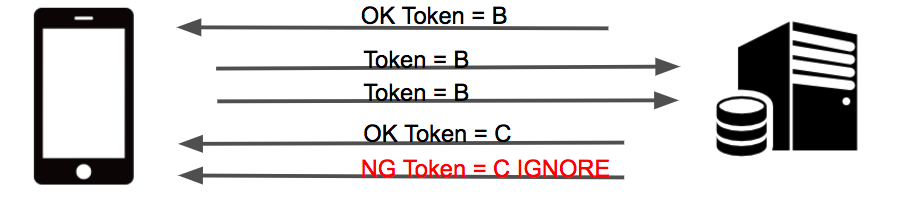
ただし意図せぬ連打でエラーダイアログが出るのはユーザ体感が悪いため、このエラーではクライアントはダイアログなどを出さないようにしています。リリース直後ではこのエラーは1日に数千件発生していました。
レプリ遅延増加時の対策
- 各コントローラの最初にWriterとReaderのワンタイムトークンを比較
- ワンタイムトークンが一致した場合は、レスポンスに新しいワンタイムトークンを追加して返却
- ワンタイムトークンが一致しない場合は、エラーを返却
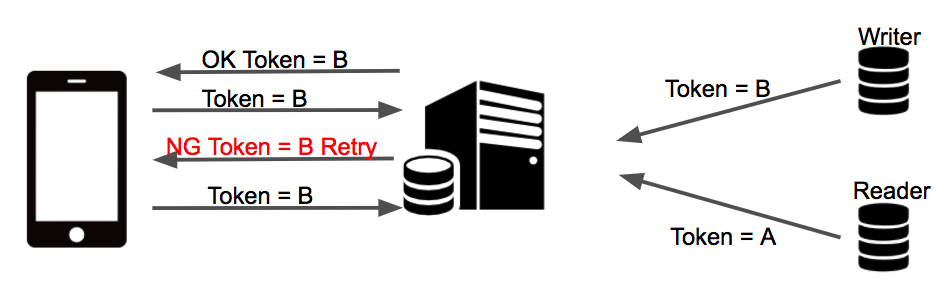
ただしこのエラーでもエラーダイアログは出さずに、同じリクエストを再度クライアントに送ってもらうように制御しています。リリース直後ではこのエラーは1日に数十件発生していたので、Auroraでもレプリ遅延が大きくなる場合があることが分かります。
Zephirの話
最後におまけとして、PHP5とPHP7とZephirのパフォーマンスの検証をご紹介したいと思います。
Zepherとは
PHPはC言語で記述したライブラリを拡張ライブラリ(以降エクステンション)として指定することが可能です。C言語で実装されたエクステンションはPHPよりも高速に動作するため、多くのMySQLやRedisのライブラリはC言語で書かれています。しかしC言語はメモリ管理が難しく保守も大変なため、これまではサービス独自のエクステンションを作るのは敷居が高い状態でした。
Zephirの登場によって、PHPライクな構文で記述したソースをC言語に変換してエクステンションを作成することが可能になり、エクステンションの作成が容易になりました。最近ではPhalconPHPのような高速なフレームワークや、サービスのロジックの高速化したい部分に使用されるようになりました。
検証結果
検証環境ですがOSはCentOS6.5を使用し, PHPはnginxとPHP-FPMとOPcacheを使用しています。CPUは1coreでメモリは1GBです。ZephirはPHP7から実行しています。
また検証した処理は以下の通りです。
- each: 配列A(要素数1,000,000)の全ての要素を2倍した配列を作成する
- without: 配列Aに存在して配列B(要素数1,000)に存在しない要素の配列を作成する
- search: 配列Aから要素Aを検索してインデックスを返却する
- repeat: 要素Aが1,000,000個入っている配列を作成する
結果は以下の通りです。
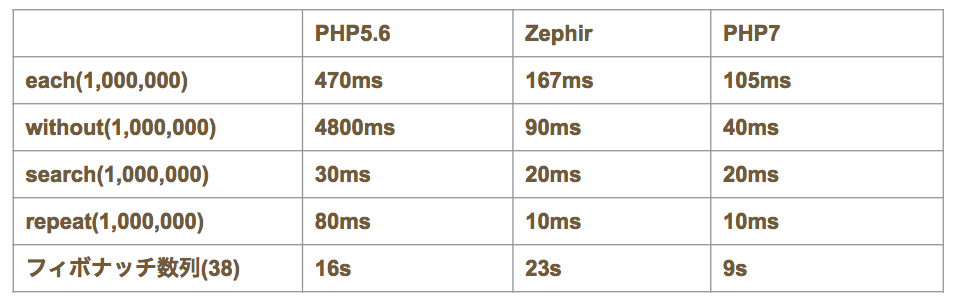 PHP5とZephierを比較するとZephirの方がかなり速い結果となりました。一方でZephirとPHP7では若干PHP7のほうが速いという結果となっています。上記の結果からPHP7を使用できる環境ではZephirを使用しても高速化はあまり期待出来ないことが分かります。
PHP5とZephierを比較するとZephirの方がかなり速い結果となりました。一方でZephirとPHP7では若干PHP7のほうが速いという結果となっています。上記の結果からPHP7を使用できる環境ではZephirを使用しても高速化はあまり期待出来ないことが分かります。
おわりに
本記事ではPHP7とマスターキャッシュやプレイヤーキャッシュを活用して、ハイパフォーマンスなシステムを実現する手法についてご紹介しました。
次に実装工数の削減やヒューマンエラーを減少させるための、各種自動化・自動生成の項目についてご紹介しました。
次にAWSでRDSを使用するシステムではAuroraのReaderを活用することで、コストパフォーマンスを向上することができることを紹介しました。それと合わせて、Readerを使用することで発生するレプリ遅延の対策もご紹介しました。
本記事ではPHPが中心でしたが、キャッシュやAuroraの遅延対策などは他言語でも活用が出来ると思いますので、ご参考になれたらと思っています。