
はじめに
こんにちは、FANTECH本部の古谷です。 前回に引き続きCLの、多言語対応についてご紹介します。
CLでの取り組み
CLでは、世界中のユーザへ最高のエンターテイメントを届けるため、多言語対応に力を入れています。 CLが提供する配信は以下の3種類あり、それぞれ配信の特性に応じて多言語化の課題があります。
- ライブキャス配信
複数のアーティストによるライブ配信で低遅延、かつリアルタイムに配信を楽しむことができます。 この特性に対応した仕組みは以下を参照してください。 - オンデマンド配信
オンデマンド配信は、事前に配信データを入稿し、ユーザが見たいタイミングで視聴することができます。 この特性に対応した仕組みは以下を参照してください。 - ライブ配信
大規模なライブを現場の臨場感と共にリアルタイムに配信を楽しむことができます。
ライブ会場からの映像をAWS Elemental MediaLiveを経由することでリアルタイム配信する特性上、事前に翻訳データの用意ができないこと、音声から文字起こしを行えるポイントが限定的、かつ動画との同期するために短時間での処理が要求されることから、多言語対応の障壁があります。
今回は、ライブ配信においてAWS Elemental MediaLive(以降、MediaLiveとします)の出力結果からリアルタイムに7ヶ国分の翻訳データを生成し動画と表示同期する仕組みを導入した事例を紹介します。
概要
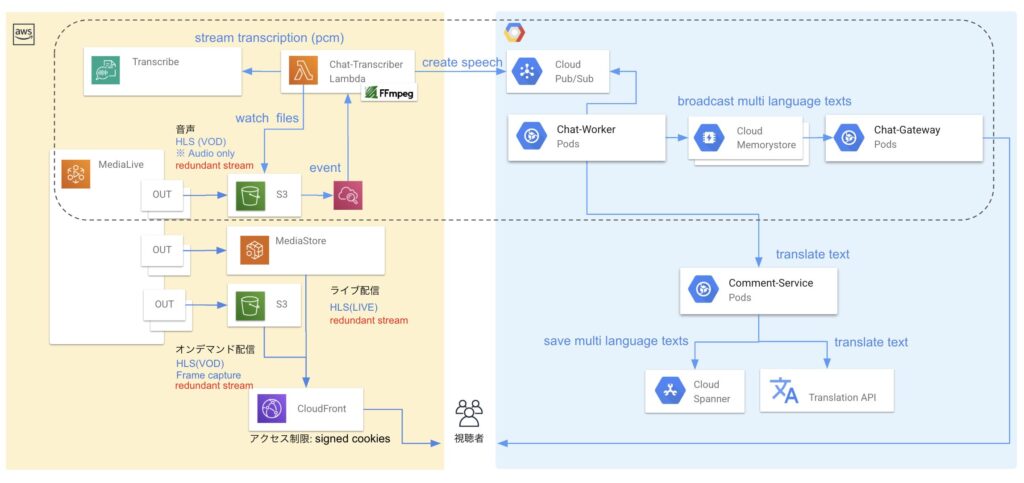
ライブ会場からの映像をMediaLive経由で動画配信すると同時に、リアルタイムに文字起こし、多言語に翻訳して視聴者に届ける仕組みです。音声の文字起こしにはAWS Transcribeを使用し、翻訳にはGoogle Cloud Translationを利用します。翻訳データは、CL リアルタイム性を実現するバックエンドを通じて伝搬されUI上で動画と同期し表示します。
今回の仕組みで考慮したポイントは以下の通りです。
- 動画配信へ遅延・障害の影響を与えないこと 動画配信への影響を避けるため、字幕としてではなく、UI上で翻訳データを同期して表示する方式をとっています。 この方式によりシステムは疎結合になり、仮に翻訳処理系で障害が発生したとしても、動画配信には一切影響がないように設計しています。
- 動画配信と翻訳データの同期 CL リアルタイム性を実現するバックエンドの仕組みにより、動画の再生に間に合うように翻訳データを送信し、音声データから取得したタイムスタンプにより動画と翻訳データの表示を同期しています。 これにより、動画は最短で再生されながらも、翻訳データが適切なタイミングでUI上に表示されることで、ユーザビリティの向上を実現しています。
- 音声データ分割による文字起こし時の文章の途切れを回避 音声データを分割することで部分的に変換処理をしつつも、文字起こしのタイミングで一連のデータとして扱うことで文章が途中で切れてしまうリスクを軽減しています。
翻訳データの生成までの流れ
MediaLiveから出力される音声データから翻訳データを生成する部分の詳細について説明します。 動画配信はMediaLiveによる基本的な配信のため今回は割愛します。
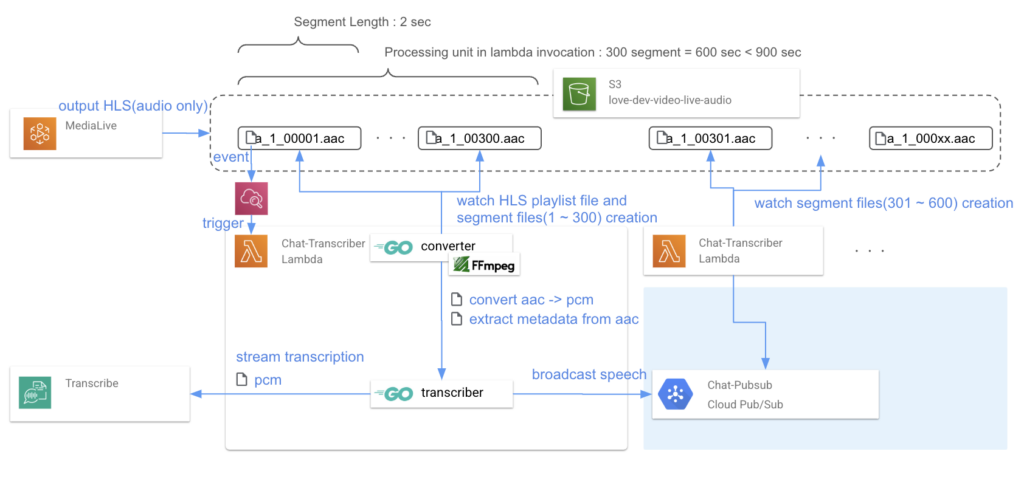
音声データ出力
MediaLiveで動画配信用の出力とは別に、文字起こし用の音声データの出力を行います。
音声データの形式は、Audio only HLSのSegmentファイル(AAC)を選定しました。 選択した理由は以下です。
- 音声データを小さい単位で逐次処理するためにストリーミング形式を選定
- 変換のオーバヘッドを軽減するため音声データ(AAC)を選定
音声データ変換
MediaLiveによるAudio only HLSのSegmentファイル生成を検知し、Lambdaにより以下の処理を行います。
タイムスタンプ取得 動画と翻訳データの表示同期に利用するため、文字起こし開始時点の実時間を表すタイムスタンプを取得します。
※ 今回のケースでは、MediaLiveのAudio only HLS 出力設定 (タイムドメタデータ ID3 フレーム)で PRIVを指定することで挿入されるタイムスタンプを利用しました。
例) id3v2_priv.com.elementaltechnologies.timestamp.utc: 2024-11-05T02:44:26Z
$ ffprobe a_1_00001.aac -hide_banner -select_streams d -show_packets -show_data
[aac @ 0x128805100] Format aac detected only with low score of 25, misdetection possible!
[aac @ 0x128805100] Estimating duration from bitrate, this may be inaccurate
Input #0, aac, from 'a_1_00001.aac':
Metadata:
id3v2_priv.com.apple.streaming.transportStreamTimestamp: \\x00\\x00\\x00\\x00\\x00\\x03\\x1c\\xe0
id3v2_priv.com.elementaltechnologies.timestamp.utc: 2024-11-05T02:44:26Z
Duration: 00:00:02.00, bitrate: 193 kb/s
Stream #0:0: Audio: aac (LC), 48000 Hz, stereo, fltp, 192 kb/s
PCM形式へ変換 AWS TranscribeのTranscribing streaming audioに従いAAC → PCM変換します。
$ ffmpeg -hide_banner -nostats -loglevel error -y -i input.ts -vn -f s16le -acodec pcm_s16le -ac 1 -ar 16000 output.pcm
文字起こし
Audio only HLSのSegmentファイルをPCM形式へ変換しつつ、AWS TranscribeのTranscribing streaming audio によりリアルタイムに文字起こしします。 一連のストリーミング処理を行うことで音声データ分割による文字起こし時の文章の途切れを回避しています。
翻訳
Google Cloud Translation を利用して、文字起こしにて生成した字幕ファイルを多言語に翻訳します。 CLでは、他機能の翻訳でGoogle Cloud Translation を利用している、かつバックエンドの翻訳実行環境がGCPであることから、翻訳精度の統一・運用の簡素化の観点で選定しています。
文字起こし時点で、会話をベースに一連のテキストが字幕化されているため、翻訳もその一連のテキストをベースに翻訳をかけることができテキストの途切れの考慮が減る分、実装を簡潔にできます。
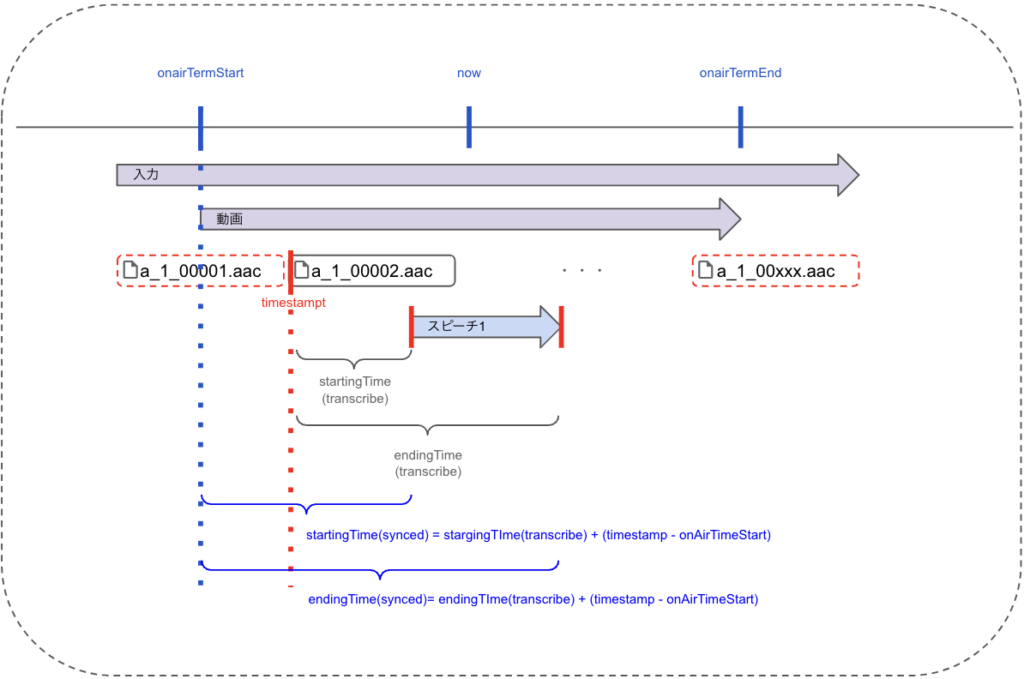
動画と翻訳データの表示同期
音声データ変換時に取得した文字起こし開始時点の実時間を表すタイムスタンプを用いて、動画のどのタイミングで翻訳データを表示するのかを計算し、UI上で動画と翻訳データの表示の同期を行います。
今後について
今回の仕組みを導入したことでCLが提供するすべての動画配信において、字幕・翻訳による多言語対応が完了しました。
これは、CLのメインコンテンツである動画配信の品質を維持しながら、世界中のユーザーに最高のエンターテインメントを届けるためのアプローチです。
もちろん、サービスの特性によっては異なるアプローチが適している場合もあるかと思いますが、今回の取り組みがひとつの参考事例としてお役に立てば幸いです。
最後までお読みいただき、ありがとうございました。