
ABEMAの広告配信システムのバックエンド開発を担当している黒崎 ( @kuro_m88 )です。
AI エージェントはモデルやハーネスの進化とともに、人間の介入なしに複雑なタスクをこなせるようになってきました。
AI エージェントは、1 回推論して終わるのではなく、推論とツール実行、外部 API 呼び出し、結果の確認を何度も繰り返しながらタスクを進めていきます。
実際のタスク実行では、外部 API 待ちや人間の確認待ちのような待機が入りやすく、途中で失敗した場合には手前からの再開も必要になります。
本記事では、こうしたワークロードを入口に Durable Execution が何を解決する概念なのかを紹介し、具体例として AWS Lambda の Durable Execution のモデルをベースに説明します。
さらに aws-durable-execution-sdk-js の実装を読み解き、それを Go SDK として再実装してみました。
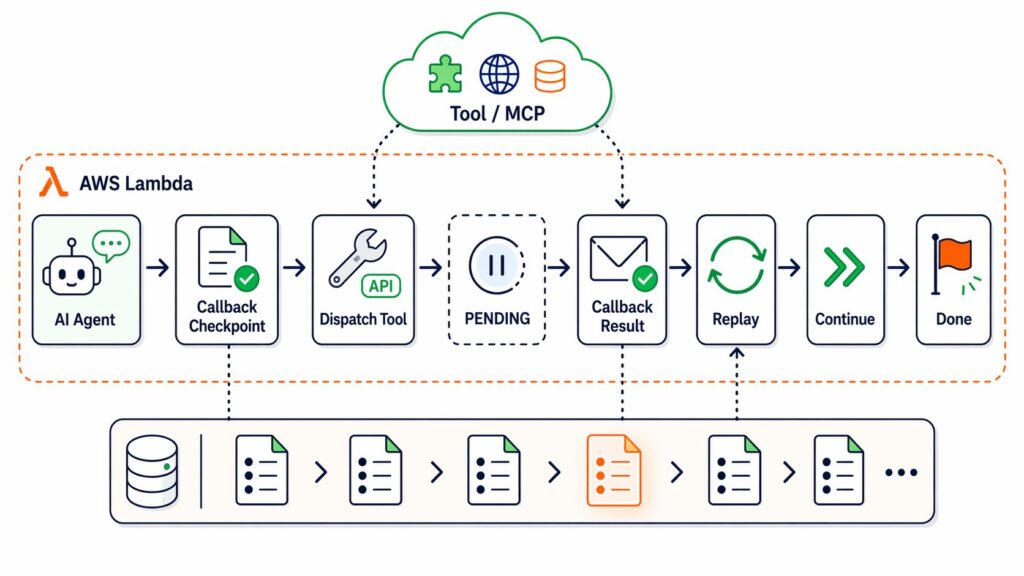
Durable Execution という言葉自体は複数のプロダクトや文脈で使われていますが、標準化された定義は見つけられなかったため、長時間実行・待機・失敗からの再開を扱うための実行モデルを指す言葉として捉えています。
AI エージェントのワークロードと Durable Execution の相性
AI エージェントの実行時間は、モデル推論もそうですが、それ以外の要因によって長くなりがちです。
たとえば次のような処理は、どれも AI エージェントでは自然に出てきます。
- LLM の推論 API の応答待ち
- MCP サーバーを含むツール呼び出しやデータ取得待ち
- 人間の承認や確認待ち
- 失敗時の再試行による待ち
- 途中結果を保持したままの再開
- サブエージェントによる処理の分岐
これらの間、実行環境を占有し続けると、待機中にも CPU やメモリを消費し続けることになります。
特にこうしたタスクを大量に並列実行することを考えると、待機の間実行環境を確保し続ける構成は無駄が多く、スケールさせづらくなります。さらに、途中失敗のたびに最初からやり直すしかない構成だと、実行が長時間になるほどコストだけでなく期待される時間内にタスクを完遂できない確率も上がります。
個人の業務環境規模ではそこまで大きな問題にならないかもしれませんが、プラットフォームとして大規模に AI エージェントを運用する場合、これらは無視できない課題になります。
Durable Execution は、処理の途中状態を保持しながら、中断と再開を前提に実行を進めていくための概念です。そのため、「途中で止まり、あとで再開し、失敗しても必要なところからやり直したい」ワークロードと相性がよいです。
Durable Execution は AI の技術そのものではありませんが、長時間動作しながら待機や再開を扱う AI エージェントを支える実行基盤を考えるうえで重要な概念です。
Durable Execution は何を解決するのか
Durable Execution は、長い処理を単にそのまま動かし続ける仕組みではありません。
本質は、途中状態を記録しながら安全に再開できるようにすることです。
「外部応答を待つ」「一定時間スリープする」「途中の結果を保持したまま別の処理へ進む」といった場面で、実行をいったん区切りつつ、一連の処理としては継続している状態を表現できます。
Go の goroutine で非同期 I/O を扱うときの感覚に少し近いかもしれません。Go ではコード上は外部の API 呼び出し等を待つように書けますが、待機中に OS スレッドを占有し続けるわけではなく、Go ランタイムがその goroutine を一時停止して実行対象から外し、I/O の完了をきっかけに再び実行可能な状態へ戻します。
Durable Execution も、プログラマには逐次的な処理として見せながら、長い待機中に実行環境を占有し続けないという点では似ています。
ただし、任意のタイミングで実行途中の呼び出し状態やローカル変数、つまり継続やコールスタックに相当するものを丸ごと保存し、あとからそのまま再開するのは簡単ではありません。言語ランタイムや実行環境への依存も強くなり、多言語の SDK として一般化するのも難しくなります。
そのため、実用上は処理を再開可能な単位に分解し、処理単位ごとの入力、結果、状態遷移を記録するモデルとして実装されることが多くなります。
再開時には、確定済みの単位は保存済みの結果を使い、未完了のところから続きの処理へ進みます。
概念的には、次のように永続化可能な状態が積み上がっていくイメージです。
{
"state": [
{
"operation": "fetch-user",
"status": "started",
"input": { "id": "u-1" }
},
{
"operation": "fetch-user",
"status": "completed",
"result": { "id": "u-1", "name": "Alice" }
},
{
"operation": "wait-for-approval",
"status": "waiting",
"resumeAfter": "external-callback"
}
]
}
利用者として実装する上でも、「何が保存されて、何が保存されないのか」は把握しておく必要があります。
保存されるもの:
- operation の ID、Type、SubType、Status
- operation 結果の payload
- wait、retry、callback に必要な制御情報
- error object
自動では保存されないもの:
- 言語ランタイム上のコールスタック
- クロージャに閉じたローカル変数のその時点の値
- durable operation 外で進んでいた副作用の途中経過
つまり Durable Execution は「普通の関数を途中からそのまま再開する」仕組みではなく、「checkpoint 可能な処理単位の列に分解した一連の処理を再生可能にする」仕組みだと捉えると理解しやすくなります。
AWS Lambda の Durable Execution はどう動くのか
AWS Lambda の Durable Execution では、1 回の実行(invocation)が実行全体を完結させるのではなく、execution state と checkpoint を介して次の invocation へ処理を受け渡していきます。
そのため、関数の返り値も単なる成功・失敗だけではなく、SUCCEEDED、FAILED、PENDING のように「この invocation が全体の中でどういう状態にあるか」を表すものになります。
AWS Lambda Durable Execution では、この checkpoint 可能な処理単位が durable operation として表現されます。
AWS の API 定義では、CheckpointDurableExecution が CheckpointToken と Updates を受け取り、GetDurableExecutionState が replay に必要な Operations を返します。
https://docs.aws.amazon.com/lambda/latest/api/API_CheckpointDurableExecution.html
https://docs.aws.amazon.com/lambda/latest/api/API_GetDurableExecutionState.html
再開時には、Lambda runtime から現在の durable execution を表す ARN、checkpoint token、初期の execution state が渡されます。
SDK は言語に関係なく、この情報をもとに execution context を初期化し、必要に応じて GetDurableExecutionState で replay 用の operation 履歴を取得します。
JSON として見ると、入力はおおむね次のような形になります。
{
"DurableExecutionArn": "arn:test:execution:manual",
"CheckpointToken": "manual-token-1",
"InitialExecutionState": {
"Operations": [
{
"Id": "execution-root",
"Type": "EXECUTION",
"Status": "STARTED",
"ExecutionDetails": {
"InputPayload": "{\"name\":\"alice\"}"
}
}
]
}
}
SDK は取得した operation 履歴を見ながら、いまが通常実行なのか replay なのかを判断します。
もし未完了の wait や callback があれば、その invocation は PENDING で終わり、後続の再開 invocation に処理が引き継がれます。
逆に処理全体が完了したときだけ SUCCEEDED が返り、エラーで継続不能なときは FAILED になります。
責務をざっくり分けると次のようになります。
- Lambda runtime: durable execution の生成、再開、state API と checkpoint API の提供
- SDK: durable API の提供、checkpoint 作成、replay 整合性の維持
- アプリコード: operation 境界の設計、冪等性、決定性の担保
Durable Execution は Lambda の新しい実行モデルではありますが、実際に replay で破綻しないように operation を並べ、checkpoint を正しく作る責務は SDK とアプリ側に残っています。
外部 API 呼び出しや DB 書き込みのような副作用は、durable operation の境界内に置いたうえで、一意な識別用のキーなどを使って冪等にしておくのが基本です。
Lambda Durable Execution での実装方法
ここまで checkpoint や replay の話をしてきたので、複雑な仕組みに見えたかもしれません。
ただ、実際に利用する側のコードは SDK によってかなり隠蔽されており、見た目としては通常の非同期処理に近い形で書けます。
AWS が提供している JavaScript/TypeScript SDK では、Lambda handler を withDurableExecution で包み、handler の中で context.step() や context.wait() のような durable operation を呼び出します。
公式ドキュメントでも、SDK は checkpoint 管理と replay coordination を隠蔽し、逐次的なコードとして書けるようにするものとして説明されています(Durable execution SDK)。
たとえば、ユーザー情報を取得し、少し待ってから次の処理へ進むだけなら、コードの見た目はかなり普通の非同期処理に近くなります。
export const handler = withDurableExecution(
async (event: Event, context: DurableContext) => {
const user = await context.step("fetch-user", async () => {
const res = await fetch(`https://example.com/users/${event.userId}`);
return await res.json();
});
await context.wait({ seconds: 30 });
const result = await context.step("build-result", async () => {
return {
user,
processedAt: new Date().toISOString(),
};
});
return result;
},
);
このコードだけ見ると、fetch-user、30 秒の wait、build-result を順番に実行しているだけに見えます。
しかし SDK の内部では、step の結果や wait の開始状態が checkpoint され、待機が必要な場合は invocation を PENDING で終了します。
再開時には handler が最初から replay されますが、完了済みの step は関数本体を再実行せず、checkpoint 済みの結果を返します。
ここで重要なのは、外部 API 呼び出しや現在時刻の取得のように結果が毎回変わりうる処理を step の中に閉じ込めている点です。
副作用を持つ処理や非決定的な処理は、replay で再実行されても結果が壊れないように、durable operation の境界内に置き、必要に応じて冪等性キー(idempotency key)などで冪等にしておく必要があります。
このように、アプリケーションコードの見た目は普通の async/await に近い一方で、実際には withDurableExecution と DurableContext が Lambda invocation、checkpoint、replay の境界を管理しています。
Go SDK を実装してみる
私は最近は Go を書くことが多いので、Go SDK が欲しかったのですが、2026年4月時点では公式 SDK は JavaScript/TypeScript、Python、Java の3 言語のみで、Go SDK は提供されていませんでした。
いずれ Go も公式にサポートされるのではないかと期待していますが、前述の調査から Lambda Durable Execution の仕組みはプログラミング言語に依存しないものであるとわかっていたので、JavaScript SDK を参考に Go SDK を実装してみました。
まず JavaScript SDK でのインターフェースと内部での概念を読み解くところから始めました。といっても、重要と思われる概念と知りたいポイントだけをピックアップして、残りの調査は Codex に任せたので、かなり効率的に全体像を掴めました。
実装に関しては、JavaScript SDK の調査結果をもとに Codex (GPT-5.5) も活用しながら進めました。
生成された実装はほぼそのまま採用できるレベルでしたが、公式 SDK の挙動と照らし合わせながらレビューすると、replay や checkpoint の整合性に関わる部分ではいくつか修正が必要でした。
実装した SDK は GitHub で公開しています。
https://github.com/kurochan/aws-durable-execution-go/
JavaScript SDK の調査、Go SDK の実装を通して得られた知見や視点は以下のようなものがありました。
replay で同じ operation 列をたどるための設計
replay では、以前の invocation で完了済みの operation を再実行するのではなく、checkpoint 済みの結果を読み直して先に進みます。
そのため Durable Execution の実装では、replay 時に初回実行と同じ operation 列を同じ順序でたどれるのが重要になります。
Go 版では JavaScript SDK と同様に、Step などを実行するたびに type、name、subtype が既存 checkpoint と一致するかを検証しています。
一致しないまま replay を続けると、どの checkpoint をどの処理の結果として扱うべきかが不定になるため、安全のために non-deterministic execution としてエラーにしています。
step ID と child context で分岐を表現する
直列の Step だけであれば、状態遷移はまだ単純です。
難しくなるのは RunInChildContext、Map、Parallel のように分岐を扱い始めたときです。
JavaScript SDK を読むと、step ID は階層を持った ID として採番され、backend 送信時にはハッシュ化されます。
Go 版でもこの考え方に合わせて、内部では親子関係を持った step ID を扱い、checkpoint の送受信ではハッシュ化した ID をキーにしています。
この分離をしておかないと、ancestor 判定や child context の cleanup が曖昧になります。
RunInChildContext は、単なる便利 API ではなく、独立した replay 単位を作るための仕組みとして重要です。
Map や Parallel も最終的には child context を使って分岐を表現しており、各分岐がそれぞれの順序で replay できるように設計されています。
実装上は DurableContext の RunInChildContext と、concurrent.go の Map / Parallel が対応する箇所です。
AWS Lambda で動かす
リポジトリには、Go SDK を使った Lambda サンプルを https://github.com/kurochan/aws-durable-execution-go/tree/main/examples/lambda-sample として置いています。
こちらを実際にデプロイして動かしてみると、以下の画像のような実行履歴になりました。
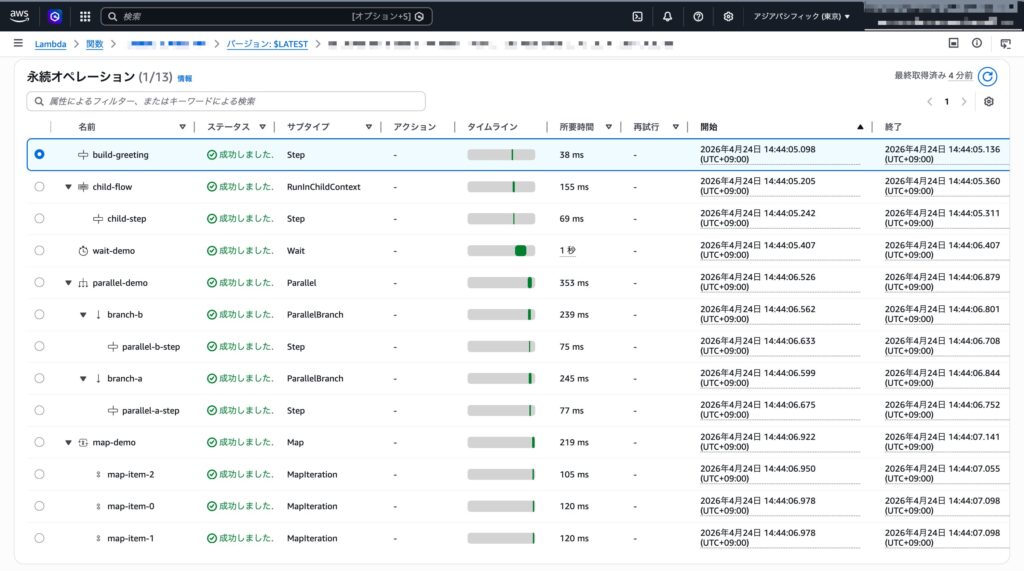
通常の Lambda Function の実行と違い、durable operationごとに分割して実行されているのがわかります。
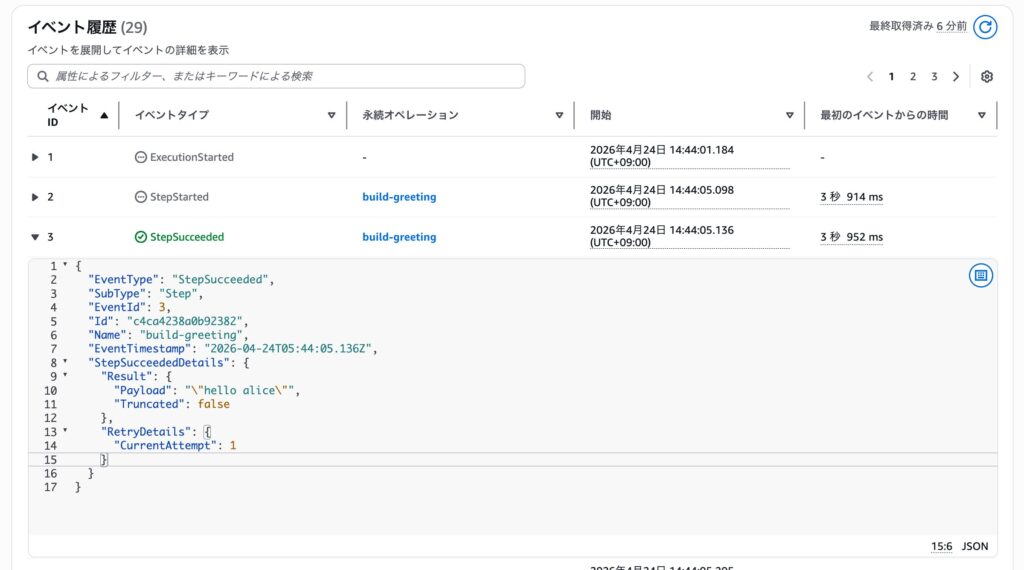
各 operation が保存した state もみられます。
コードと実行結果を眺めることで、より理解を深められると思います。
おわりに
この記事では、AI エージェントのワークロードと Durable Execution の相性を入口に、AWS Lambda の Durable Execution がどういうモデルで動いているのか、そしてそれを Go SDK として表現するとどうなるのかを紹介しました。
今までは REST API のようにステートレスなアプリケーションの実装をする機会が多かったですが、今後は AI エージェントのようなワークロードの開発の機会も増えていきそうなので、この機会に触れてみることができてよかったです。
他にも AWS Lambda Durable Execution は最大1年間実行を継続可能な特徴もあったりするので、 今までは Step Functions で実装していたものの、ワークフローが複雑になりすぎてしまったものの置き換えなど、期待できるユースケースが色々ありそうですね!