
はじめに
こんにちは。CyberAgent Dev PlatformでBucketeerのオーナーを務めている沖本友一です。
AIがコードを生成するスピードは、人間がレビューできるスピードを超え始めています。これまで PRが担ってきた「変更をユーザーに届ける前の最後のチェックポイント」という役割は、レビュー時点だけでなく、本番環境でのロールアウト判断にも広がっています。
本記事では、AIが生成したコードを安全にリリースするために、なぜランタイム制御が重要になるのか、そしてフィーチャーフラグを中心とした実践的なワークフローをどのように設計すべきかを解説します。
対象読者
- AIアシスタントやコーディングエージェントを活用した開発を行っている方
- フィーチャーフラグの導入や運用を検討しているエンジニアリングリーダー
- AI生成コードの安全なリリースフローを設計したい方
- MCP(Model Context Protocol)などを通じて、エージェントから設定を変更する仕組みに関心がある方
安全性の前提を変えた2つの変化
変化1:生成スピードがレビュースピードを上回った
以前であればシニアエンジニアが半日かけて書いていた差分も、今ではコーディングアシスタントを使えば数分で生成できます。締切に追われる状況下では、PRが肥大化し、レビューが形式的になり、承認が形骸化していくのは避けられない流れです。
さらに深刻な問題は、そのPRに付随するテストコードまでもが、同じAIモデルによって書かれている可能性があることです。従来、CI(継続的インテグレーション)がパスしていることは「独立した検証レイヤーが機能したこと」を意味していました。しかし、今では「同じ思い込みに基づいたバグ」と「そのバグを見逃すテスト」がセットで生成されているリスクがあります。
変化2:PRの作者がエージェントになりつつある
コーディングエージェントは、もはや単なるオートコンプリートの域を超えています。PRを作成し、ファイルを更新し、ワークフローを起動し、場合によってはマージやデプロイまで実行します。Model Context Protocol (MCP) のようなインターフェースを活用すれば、インフラ、ドキュメント、設定へのアクセスさえ可能になります。
かつてエージェントの誤った判断は「エディタ上での不適切な提案」で終わっていました。しかし、今後は、それがそのまま「本番環境にリリースされる変更」になり得るのです。
これら2つの変化により、「コードとユーザーの間には、慎重に判断を下す人間が存在する」という従来の安全策の前提が揺らいでいます。私たちの多くのレビュープラクティスは、この前提の上に設計されてきましたが、その前提はもはや常に保証されるものではありません。
従来の安全策だけでは足りない理由
こうした状況下では、既存のプリプロダクション(事前検証)の仕組みを強化しようとするのが自然な流れです。確かにレビュー、テスト、CI、ステージング、静的解析、セキュリティチェックは依然として不可欠なプロセスです。しかし、AIの台頭によって、それらの限界がより鮮明になりました。
- ステージング環境の限界:本番環境と全く同じデータ、トラフィック、タイミング、権限、ロケール、ユーザー行動を再現することは極めて困難です。AIが生み出すバグは、まさにこうしたエッジケースに潜みがちです。
- 実装への過学習:コードと一緒に生成されたテストは、実装と同じ誤解(前提条件のミスなど)を共有している可能性があります。「コードが書かれた通りに動くこと」は確認できても、「要件を満たしているか」までは保証できません。
- インフラレベルのカナリアリリースの限界:クラッシュやレイテンシの急上昇、5xxエラーの検知には有効ですが、「サイレントな機能劣化」には対応できません。たとえば、「チェックアウト時に誤った通貨が適用される」「要約から必要な情報が欠落する」「配信停止済みのユーザーに通知が飛ぶ」といった問題です。
AIによって混入する不具合の多くは、本番環境で実際のユーザーと実データに触れて初めて顕在化します。これは規律の問題ではなく、AIを前提とした開発フローにおいて構造的に起こりやすい現象なのです。
ランタイムレビューという考え方
ランタイムレビューとは、リリースの可否判断を「PRのマージ時点」ではなく「本番環境での実際の振る舞い」に基づいて行うレビューモデルのことです。
多くのチームは、フィーチャーフラグを単なる「リリースのためのツール」と考えています。しかし、AIを開発フローに組み込む場合、その定義はより広範なものになります。
AI生成コードにおいて、ランタイム制御には以下の5つの重要な役割があります。
- 影響範囲を限定する:パーセンテージベースの公開であれば、問題が全ユーザーに波及する前に、まずは1%のユーザー層で食い止めることができます。
- ロールバックをデプロイではなく設定変更にする:AIが生成した微細なバグが発生した場合、最初の数分間の対応が勝負を分けます。キルスイッチを実行するために、新たなデプロイを待つ余裕はありません。
- コードを本番指標に結びつける:「エラーが出ていないこと」と「正常に動作していること」は別物です。ロールアウトの成否は、エラー率だけでなく、プロダクトメトリクスやビジネスシグナルと連動させるべきです。
- 説明責任(Audit Trail)を確保する:AIが生成したコードであっても、ロールアウトの判断には「誰が」「なぜ」行ったのかという監査ログが必要です。
- エージェントに許可する操作を制限する:エージェントにフラグの作成・更新権限を与えることはあっても、広範な管理者権限を与える必要はありません。
これは特に、エージェントがコードを書いた場合に重要です。フラグを切り替える瞬間こそが、人間またはポリシーが「この変更をユーザーに届けてよい」と明示的に判断する瞬間となります。その判断は、単なる差分(Diff)の確認ではなく、本番環境での実際の振る舞いに基づいて行われるべきなのです。
ワークフローの全体像
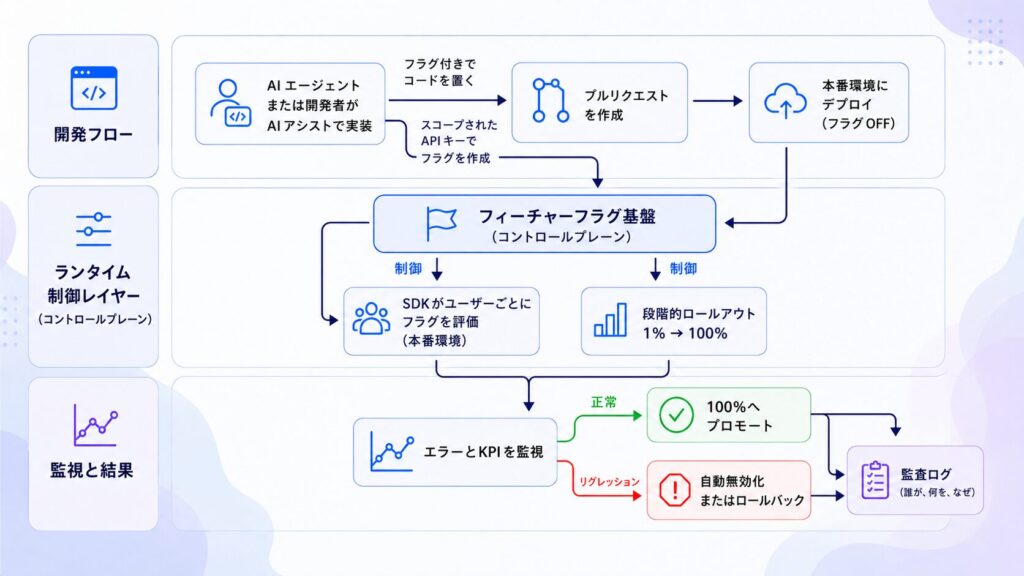
多くのチームに必要なパイプラインは、全く新しいものではありません。継続的デリバリー(CD)に近い形ですが、「リスクの高い瞬間」が「デプロイ時」から「ロールアウト時」へと移動しているのが特徴です。
このモデルでは、デプロイ自体はもはや最も危険なステップではありません。コードはフラグによってOFFの状態のまま、ユーザーには見えない形で本番環境にデプロイされます。そして、証拠を集め判断を下す「ロールアウト」こそが、真のコントロールポイントとなります。
AI生成コードを安全にデプロイするための3つのパターン
理論だけでなく、日常の開発現場で即座に活用できる実践的なパターンを3つ紹介します。これらを組み合わせることで、フラグ、キルスイッチ、監査ログがコードと同期して生成される「AIネイティブな開発ループ」を構築できます。
パターン1:変更をフラグでラップする
AIが生成した変更が、新しいAIモデルへの切り替え、料金計算ロジック、レコメンドアルゴリズム、プロンプトの修正、画面遷移の変更のいずれであっても、必ずboolean型のフラグで制御します。
const useNewSummaryModel = await client.booleanVariation(
user,
'ai-summary-v2',
false
);
if (useNewSummaryModel) {
return generateWithNewModel(input);
}
return generateWithCurrentModel(input);
デフォルトを false にしておくことで、設定漏れやSDK・ネットワークの問題が発生しても、既知の安全なパスへフォールバックできます。
これは大規模な機能だけでなく、むしろ「レビューでは安全そうに見えるが、本番では挙動が変わる可能性がある小さな変更」にこそ有効です。ランキングの微調整、プロンプトの変更、対象ユーザーの判定ルール、既存ロジック周辺のリファクタリングなどがこれに当たります。
パターン2:コードと同時にフラグを作成する
運用のボトルネックとなる「手動でのフラグ作成」を自動化します。変更を準備したエージェントやCIステップが、権限を限定したAPIキーを使用して直接フラグを作成します。
curl -X POST https://api.example.com/v1/feature \
-H "Authorization: $FEATURE_FLAG_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"id": "ai-summary-v2",
"name": "AI Summary v2",
"description": "PR #1423: switch summarization model",
"variations": [
{"value": "true", "name": "on", "description": "use new model"},
{"value": "false", "name": "off", "description": "current model"}
],
"variationType": "BOOLEAN",
"tags": ["ai", "agent-created"],
"onVariationIndex": 0,
"offVariationIndex": 1
}'
これにより、マージ前に「タグ付きで、説明があり、PRと紐付いたフラグ」が準備された状態になります。リスクを最小化するために、フラグ作成時点で以下のすべてを満たしているかを確認してください。
- 生成されたコードがフラグで包まれている
- デフォルト値がOFFになっている(設定漏れ時のフォールバック先が安全な状態)
- PRマージ前にフラグが作成されている
- フラグにオーナー、説明、タグ、有効期限が設定されている(説明にはPR番号など、コードの文脈をたどれる情報を含める)
- 少なくとも1つの本番メトリクス(エラー率、成功率、ビジネス指標など)がフラグに紐づいている
- キルスイッチ(自動無効化ルール)がフラグと同時に作成されている(詳細はパターン3を参照)
- エージェントには限定的なスコープの認証情報が使われており、すべての変更が監査ログに残っている
1〜3番目は「コードとユーザーの間に必ずスイッチを設ける」ためのものです。4〜6番目は「そのスイッチが、判断材料とブレーキを最初から備えている」状態を保証します。7番目は「誰がいつ何を変えたかを後から追える」ためのものです。
パターン3:作成時からキルスイッチを付ける
AI生成コードにおいて、キルスイッチはフラグとセットで作成すべきです。
curl -X POST https://api.example.com/v1/auto_ops_rule \
-H "Authorization: $FEATURE_FLAG_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"featureId": "ai-summary-v2",
"opsType": "EVENT_RATE",
"opsEventRateClauses": [{
"goalId": "ai-summary-error",
"minCount": 100,
"thresholdRate": 0.02,
"operator": "GREATER_OR_EQUAL",
"actionType": "DISABLE"
}]
}'
例えば、「100イベント発生後、エラー率が2%を超えたら自動停止」といったルールを事前に設定します。これにより、オンコールエンジニアはインシデント対応に追われるのではなく、原因調査に集中できるようになります。
メトリクスはアプリケーション内のSDKから送れます。
client.track(user, 'ai-summary-error');
エラーイベントだけでなく、完了率、滞留時間、ユーザー操作の成功率といった「正常系のメトリクス」をAuto Operationsの判定に組み込めば、サイレントな機能劣化にも対応できます。Datadog、New Relic、Dynatraceなど、既存のオブザーバビリティツールからメトリクスを受け取ることも可能です。
重要なのは、ロールアウトが測定可能な健全性の定義に結びついていることです。AI生成コードでは「デプロイに成功した」だけでは不十分で、本当に問うべきは、その変更が実際のユーザーに対して正しく振る舞っているかどうかです。
エージェントがフラグを切り替えるとき
エージェントがロールアウトの変更まで行うようになると、Bucketeer MCP serverのようなツールを通じて、フラグの一覧取得や設定更新、アーカイブを高速に行えるようになります。しかし、人間を介さずにユーザーへの提供内容を変えてしまうリスクもあります。
ここで重要なガードレールは2つです。
- すべての変更に理由を求める: エージェントによる更新も、人間と同様の監査ログを残し、変更理由のコメントを必須にします。
- 書き込み権限と管理者権限を分ける: エージェントにはフラグの作成・更新権限は与えますが、環境の削除や安全策の無効化といった広範な管理者権限は与えないようにします。
多くのチームに今足りないのはツールではなく、こうした「エージェントを前提としたポリシー」です。
フィーチャーフラグ基盤に求められる機能
このワークフローを実現するには、以下の機能を備えた成熟したフィーチャーマネジメントシステムが必要です。Bucketeerはこれらをすべてサポートしています。
- リリース制御:デフォルトOFFのフラグ / パーセンテージや対象セグメント別の段階的ロールアウト(Progressive Rollout、Split Audience Rollout、カスタムターゲティング)
- 安全装置:自動ロールバック / モニタリングツールとの連携(Auto Operations、Flag Triggers)
- ガバナンス:監査ログ / RBAC / 変更理由の記録
- エージェント連携:スコープされたAPIキー / APIやMCPによる外部からのフラグ操作(Public API Keys、MCPベースのフラグ管理)
- ライフサイクル管理:フラグのオーナー・有効期限の管理 / 古くなったフラグのクリーンアップ(Code References)
さらに、Bucketeerはオープンソースとして公開されており、ベンダーロックインのリスクを抑えながら導入できます。
CyberAgent内のプロジェクトであれば、私たちが運用する社内サービスとしてそのまま利用可能です。それ以外の環境では、セルフホストでご利用いただくか、私たちのチームまでお問い合わせください。
エンジニアリングリーダーのためのチェックリスト
1. リリース戦略
- 徹底した隔離:AIが生成した変更は、規模の大小に関わらず必ず「デフォルトOFF」のフラグ配下に置いているか。
- 段階的な展開:1% → 10% → 50% → 100% といった標準的なロールアウトパスと、各ステップ間の待機時間を定義しているか
- メトリクスとの紐付け:AI関連のフラグには、必ず少なくとも1つの「ビジネス指標」または「システム健全性指標」を紐付けているか。
2. ガードレールと自動防御
- 自動ロールバック:異常検知時(エラー率の上昇など)に、人間を介さず即座にフラグを無効化する「Auto-disable」設定がなされているか。
- キルスイッチの整備:インシデント発生時、オンコール担当者が迷わず実行できるよう、フラグ操作の運用手順書(Runbook)が整備されているか。
- ライフサイクル管理:すべてのフラグに「オーナー」と「有効期限」が設定され、Code Referencesなどの仕組みで未使用フラグを継続的に検知・整理しているか。
3. 権限とガバナンス
- 最小権限の原則 (PoLP):コーディングエージェントには管理者権限を与えず、フラグの作成・更新に限定したスコープ付きAPIキーのみを付与しているか。
- 権限の分離:エージェントによる変更と、人間による重要な設定変更(環境削除など)の権限階層が明確に分かれているか。
- エージェントツール経由の操作の統制:MCPなどを介したエージェント主導のフラグ操作にも、人間と同等の監査・承認・コメント必須化のガードレールが適用されているか。
- 変更理由の記録の義務化:人・エージェントを問わず、すべてのフラグ変更に「なぜ変更したのか」のコメントを必須化しているか。
- トレーサビリティの確保:エージェントが行ったすべての操作に対し、監査ログ(誰が・いつ・なぜ)が残る仕組みになっているか。
まとめ
本記事では、AIによるコード生成の加速とエージェントの台頭という2つの変化を出発点に、フィーチャーフラグによる「ランタイムレビュー」という運用モデルを紹介しました。具体的な実践として、変更をフラグで包む、コードと同時にフラグを作る、初日からキルスイッチを付ける、の3つのパターンを取り上げ、エンジニアリングリーダー向けのチェックリストもまとめています。
AI生成コードを安全に届けるには、コードレビューやテストに加えて、本番環境での挙動を見ながら判断できるレイヤーが必要であり、それが「ランタイムレビュー」の役割です。レビューが不要になったわけではなく、判断する場所がPRから本番環境へと広がっただけです。
今後はBucketeerでも、AIエージェントとの連携を前提とした機能改善を引き続き進めていく予定です。BucketeerはオープンソースとしてGitHubで公開しており、CyberAgent内のプロジェクトはもちろん、社外でもセルフホストやサポート相談を歓迎しています。
⭐ 共感いただけた方は、ぜひGitHubのスターやコントリビュートでBucketeerを応援してください。
参考
- Bucketeer 公式サイト
- Bucketeer ドキュメント
- Progressive Rollout
- Auto Operations
- Flag Triggers
- Bucketeer MCP server
- Bucketeer GitHub リポジトリ