
はじめに
はじめまして。株式会社タップルでサーバーサイドエンジニアをしている糸井一颯( Issa )です。
本記事では国内最大級の会員数を誇るマッチングアプリであるタップルのマイクロサービス移行について、1年半かけて完遂したその軌跡について記します。
マイクロサービス移行pjの背景
タップルのバックエンドでは、課金やメッセージといった歴史の長い一部の機能については、すでに先行してマイクロサービスとして稼働していました。本プロジェクトは、旧リポジトリに残されたすべての機能を完全に新しいマイクロサービスへと載せ替える一大プロジェクトです。
移行対象となる物量は膨大で、機能数にして約30、APIエンドポイントは130本以上に上り、さらに非同期処理やバッチ処理なども含まれます。
具体的には、マッチングアプリの根幹である「フリック / マッチ機能」をはじめ、「ポイント(アプリ内通貨)」「通知」「プロフィール機能」など、多岐にわたる重要なドメインが対象となりました。
旧リポジトリが抱えていた技術的負債
移行前の旧リポジトリは、長年の運用により以下のような深刻な課題を抱えていました。
ロジックの散逸とスパゲッティ化
10年以上の歴史を持つ、JavaScriptで書かれたモノリシックなアプリケーションでしたが、厳格なコーディング規約が存在せず、強いて言えばレイヤードアーキテクチャ風になっている程度でした。「どこに何を書くべきか」というルールがないため、ビジネスロジックがあちこちに散らばっている状態でした。
開発体験の著しい低下
機能開発が非常に速いスピードで行われるタップルにおいて、既存仕様の把握が困難で影響範囲が見えづらく、安全に手を加えにくいという問題が顕在化していました。
すでに一部の機能がマイクロサービス化されている一方で、プロダクトを成長させるための新規機能開発を止めることはできません。そのため、新しい仕様を追加するたびに旧リポジトリのコードベースがさらに肥大化してしまい、「手を加えるほどマイクロサービス化が一向に進まない」というジレンマに陥っていました。 さらに、新しいマイクロサービスと旧リポジトリの両方で機能やデータの整合性を担保する二重管理のコストも限界に達しつつありました。
期間を定めた完全移行の決断と制約
こうした背景から、ついに「1年半という期間を定めて旧リポジトリの機能を完全に移行しきる」という決断が下されました。しかし、この移行にはただコードを移すだけではない、以下の制約と目的がありました。
- 新規機能開発との並行稼働
新規機能開発等のビジネスの成長を止めることなく、施策開発チームと連携しながら移行を安全に進める必要がありました。
- 単純なrewriteではない「資産化」
これが最も重要なポイントです。本プロジェクトは、単にJavaScriptのコードを機械的にTypeScriptへ置き換えることではありませんでした。既存の仕様を見直し理想の状態にする、さらに不要な機能を削ぎ落としてよりシンプルにする「既存機能の資産化」こそが真の目的でした。
全体的な移行戦略
前述した厳しい制約の中でこの壮大な移行プロジェクトを進める上で、私たちは大きく4つの移行戦略を柱として掲げました。
移行戦略1: 依存関係を整理し、移行順序を定義
新規機能開発を止めずに移行を進める上で、最も重要だったのがマイクロサービスへ移行する順番です。
タップルにおいて、各機能は密接に絡み合っています。
例えば「相手に『いいかも』を送る(フリックする)」という1つのアクションをとっても、単にマッチング状態が更新されるだけでなく「ユーザーの保有ポイントを消費する」「相手に通知を飛ばす」「アイテムの効果を判定する」といったように、複数のドメインの処理が連動して動いています。
ここで、他から依存されている根幹の機能を旧リポジトリに残したまま、依存する側の機能を先に新しいマイクロサービスへ移行してしまうとどうなるでしょうか? 新しいマイクロサービスから旧リポジトリの古いロジックを呼び出すために、複雑なAPI通信や一時的なつなぎ込みのコードを書く必要が生じます。
この複雑さを回避するため、私たちはまず「すべての機能の依存関係を整理・可視化し、常に『他から依存されている機能』から優先してマイクロサービスへ移行する」というアプローチを徹底しました。
この順序を守ることで、常に「旧リポジトリから新しいマイクロサービス(API)を呼び出す」という単方向のクリーンな依存関係を維持することができました。結果として、移行途中の過渡期であってもコードベースがカオスになることを防ぎ、各ドメインの担当者は安全に新規機能開発を並行して進めることが可能になりました。
移行戦略2: 移行スコープを絞る
限られた期間内で「資産化」と「移行の完遂」を両立させるため、私たちは明確な線引きを行いました。
UIが絡む仕様変更は一切やらない
バックエンドのドメインロジックの整理・資産化に100%集中するため、クライアント(iOS / Android)側の修正を伴うような、画面やUI起因の仕様変更はスコープ外としました。これにより、クライアントエンジニアを巻き込んだ調整コストを削減し、後方互換性を保ったまま安全にAPIを移行することに専念できました。
「理想のモデル」と「既存DBスキーマ」の妥協点
稼働中のシステムにおいて、データマイグレーションやDBスキーマの変更は最もリスクと時間がかかる作業です。そこで私たちは、「既存のDBスキーマが、理想のドメインモデルの表現や振る舞いを著しく阻害しない限りは、データマイグレーションを行わない」という現実的な基準を設けました。
移行戦略3: マイクロサービス分割は慎重に
マイクロサービス分割の粒度と「モジュラーモノリス」の選択
機能の依存関係が整理できた後、次に直面したのが「どの単位(粒度)でマイクロサービスとして切り出すか」という問題でした。
マイクロサービスは、分割粒度を細かくしすぎるとインフラリソースの管理コストが跳ね上がり、監視すべきメトリクスも膨大になります。さらに「細かすぎるサービス群のオーナーシップを誰が持つのか?」という運用上の課題も生み出します。
そもそも、物理的なマイクロサービスとして分割するメリットは以下の2点が大きいと考えています。
- スケーラビリティの独立性: 特定の機能のインフラスケール要件に引っ張られず、独立してスケールできること。
- 可用性の向上(障害の局所化): 万が一特定のドメイン(例:一部のアイテム機能)で障害が発生しても、アプリ全体のダウンタイムに繋がらず、コア機能(ログインやユーザの検索/推薦)は稼働し続けられること。
逆に言えば、上記2点が求められない機能において、ネットワーク越しの通信コストや障害点の増加といった代償を払ってまで物理的に分割するメリットは薄いと考えました。
そのため、本プロジェクトでは「本当に独立したマイクロサービスとして切り出すべきか?」について非常に慎重な判断を下しました。
「いつでも切り出せる」モジュラーモノリス構成の採用
特に、今後の施策開発で新たに誕生する機能や、今後大きく進化するのか・あるいは削除されるのかが未定な機能群については、最初から独立したマイクロサービスにするのを避けました。
代わりに、「いつでもマイクロサービス化できるモジュラーモノリス構成のサービス」を用意し、その中にドメインを配置するアプローチをとりました。
これは、インフラ(コンテナ)としては1つのアプリケーションとして稼働させつつも、内部のコードベースにおいては以下のような厳格な境界を引く構成です。
- DBアクセスの分離: モジュールを跨いで、同一のコレクション(テーブル)へ直接アクセスすることを固く禁⽌する。
- 通信のインターフェース化: モジュール間を跨ぐ処理は、直接的なメソッド呼び出しではなく、非同期通信やAPI通信に限定し、モジュール間の密結合を排除する。
このアプローチにより、不要なインフラ管理コストを抑えつつも、将来的に機能が肥大化して「独立したスケール」や「可用性のための障害分離」が必要になった際には、いつでもコードを切り離して単独のマイクロサービスとして移行できる柔軟性を担保することができました。
移行戦略4: DDDとクリーンアーキテクチャの採用
そして最後の柱は、ドメイン駆動設計(DDD)とクリーンアーキテクチャの採用です。
今回のプロジェクトにおいて、「単純にJavaScriptからTypeScriptに書き換えるだけ」の移行は、絶対に避けるべきアンチパターンでした。プロジェクトの真の目的は、既存の機能をより良い価値を生み出すために洗練させ、負債となる機能を削ぎ落として「資産化」することにあったからです。
そこで新しいマイクロサービスでは、ビジネスロジックをインフラやUIから完全に切り離し依存の方向を制御するクリーンアーキテクチャと、エンティティや値オブジェクト・集約といった概念でビジネスロジックそのものを表現するDDDを採用しました。
前者が「どこに何を置くか」という構造を担い、後者が「ビジネスの境界やルールをどうモデルとして整理・表現するか」を担います。
これにより、開発者は既存のコードをただ直訳するのではなく、必然的に
仕様の再定義・モデリング → ドメインモデルの実装 → ドメインを中心としたUsecase・API・DB設計
という手順を踏むことになります。
結果として各ドメインの関心事が綺麗に分離され、単体テストが容易になるとともに、将来的な仕様変更にも柔軟に対応できる堅牢な土台を構築することができました。
タップルでどのような観点でモデリングを行なっているか?についてはチームメンバーか書いてくれた下記の記事ご覧ください。
具体戦術
ここからは、前述した移行戦略を実現するために、実際の開発・運用の現場でどのような仕組みを導入したのかを紹介します。
大規模な移行を安全かつ継続的に進めるためには、アーキテクチャの設計思想だけでなく、「品質と開発生産性をどう両立するか」という実践的な仕組みが不可欠でした。
戦術1:移行を安全に進めるリリース制御と自動テスト
マイクロサービス移行において最も恐れるべき事態は、重大な障害が発生した際に、すぐに元の状態に戻せないことです。このリスクを極限まで減らし、安全かつ段階的な移行を実現するために、私たちはBFF(Backend For Frontend)サーバーを中心とした3つのアプローチでトラフィックとリリースの制御を行いました。
タップルにおけるBFFの取り組みはこちらをご覧ください
https://ca-base-next.cyberagent.co.jp/2022/sessions/bff-openapi-for-tapple/
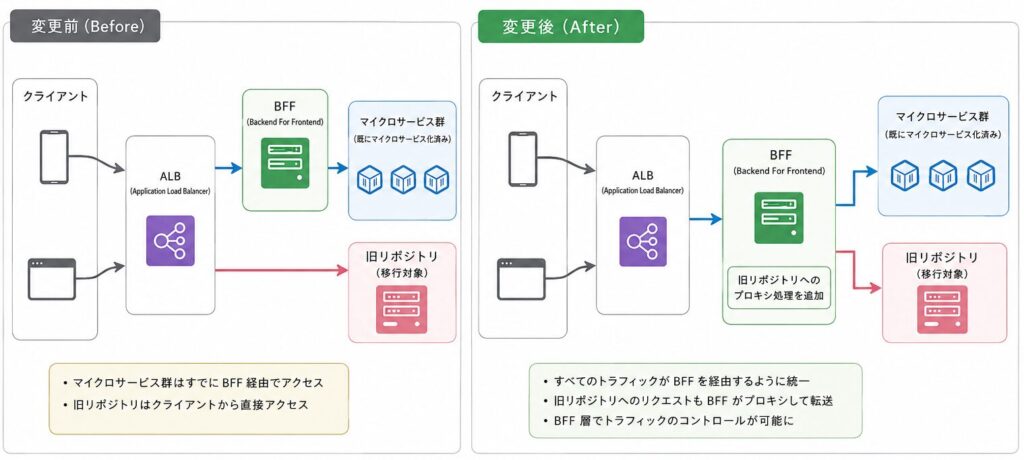
1. 全トラフィックのBFF経由化(ALBリスナールールの変更)
タップルでは元々、すでにマイクロサービス化されている機能群に対しては「クライアント → BFF → 各マイクロサービス」という経路で通信を行っていました。一方で、移行対象である旧リポジトリは、クライアントから直接叩かれている状態でした。
そこで移行の第一歩として、旧リポジトリへのトラフィックもすべてBFFを通るようにALBのリスナールールを変更しました。BFF側には、旧リポジトリへのリクエストをそのままプロキシして旧リポジトリへ流す処理を追加しています。
プロジェクトの初期段階でこの基盤を整備したことで、すべてのAPI通信がBFFを通過するようになり、後述する「トラフィックの振り分け」をBFF層で安全にコントロールする準備が整いました。
2. フィーチャーフラグによる旧・新トラフィックの安全な切り替え
BFFにトラフィックが集約された後は、フィーチャーフラグを用いて旧リポジトリと新しいマイクロサービスへのリクエストを動的に切り替える仕組みを構築しました。
具体的には、BFFの実装内にフラグの判定ロジックを挟み込みます。
- フラグが False の場合: 従来通り、旧リポジトリにトラフィックを流す(デフォルト)
- フラグが True の場合: 新しいマイクロサービスへトラフィックを流す
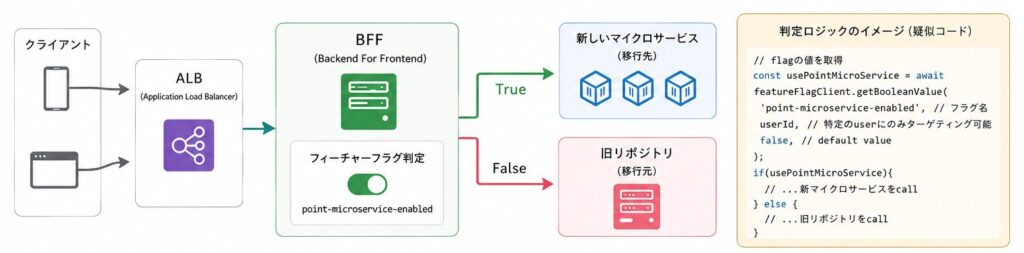
この仕組みの最大のメリットは、万が一、新しいマイクロサービス側で想定外のエラーが発生した場合でも、ロールバック目的の再デプロイをすることなく、フラグを False に戻すだけで瞬時に旧リポジトリへトラフィックを切り戻せるという点です。これにより安全性を完全に担保した状態で本番への切り替えに臨むことができました。
さらにこのフィーチャーフラグは開発生産性に良い効果をもたらしました。機能開発の途中であったり、テストが十分になされていないマイクロサービスのAPIであっても、フラグをオフにした状態であればいつでも本番環境へデプロイすることができます。
結果として、メインブランチへのマージのリードタイムやデプロイの頻度を落とさずにプロジェクトを進めることができました。
タップルでのfeature flagに関する取り組みは下記をご覧ください。
3. 「BFFのE2Eテスト」による互換性保証
「いざトラフィックを新しいマイクロサービスへ流したときに、本当にクライアント側の挙動が壊れないか?」という不安は常につきまといます。これを払拭し、手動QAの工数を大幅に削減するために導入したのが、BFFのE2Eテストです。
開発環境においてモックを使用せず、実際にDBや外部通信を伴うリアルな状態でBFFのI/OをAPIテストとして検証します。
具体的には、全く同じリクエスト条件で以下の2パターンを実行します。
- フィーチャーフラグを
Falseにして、旧リポジトリのAPIを実行する - フィーチャーフラグを
Trueにして、新しいマイクロサービスのAPIを実行する
そして、「BFFの内部でどちらの経路を通っても、クライアントから見た際のレスポンス(データ構造や値)が完全に一致し、互換性が保たれていること」を機械的に証明するテストを構築しました。
これにより、フィーチャーフラグを切り替えた際の挙動の変化やデグレをCI上で確実に検知できるようになりました。結果として、人間による膨大な手動テストの負担を削減しつつ、自信を持ってマイクロサービスへのトラフィック切り替えを行える強固な品質保証体制を実現することができました。
戦術2:DDD浸透の壁を越える仕組み化
新しいアーキテクチャとして「DDD × クリーンアーキテクチャ」を掲げたものの、それを実際の現場に定着させるのは容易ではありませんでした。プロジェクトを前進させるためには、チームビルディングと「仕組み化」という大きな壁を乗り越える必要がありました。
属人的なレビュー体制の限界
本プロジェクトは時折メンバーが入れ替わりながらも、常に7-8人のバックエンドエンジニアで開発を進めていました。
新しく参画したメンバーに対し、DDDを用いたモデリングの手法や、それをTypeScriptでどう表現するのかを浸透させる必要が生じました。
当初は品質を担保するため、私が全メンバーのモデリングから実装までを一つひとつレビューしていました。しかし、次第に日中の業務がすべてレビューと議論だけで埋まってしまい、私自身の開発手が止まるどころか、レビュー待ちによってチーム全体のスループットが低下し私自身がボトルネックになりました。
更に、このレビューの属人化とボトルネック化に拍車をかけたのが、当時台頭し始めていたAIコーディングツールの存在でした。大量に生成されるコードは非決定論的であり、厳密なアーキテクチャ規約を確実に守り切ることはできません。
DDDの文化醸成
この状況を打破するため、人間が気合いでレビューするという属人的な体制からの脱却を図りました。
まず、新メンバーがDDDの勘所をすぐに掴めるように、オンボーディング用のドキュメントやサンプルコードを整備しました。これにより、基礎的な設計思想のキャッチアップを効率化でき、結果的にこの資料はその後も長期的に運用されるチームの重要な資産となりました。
更にこのドキュメントをgitでコードの近くで管理することにより、coding agentによるアウトプットの品質が向上しました。
タップルでのオンボーディングのリアルについては過去のインターン生が執筆してくれた記事をご覧ください。
DDDを機械的に支える仕組み
さらに、機械的な解決策として非常に強力だったものを2つ紹介します。
基底クラスを用いたDDDパターンの構造的保証
DDDには「ルート集約」「エンティティ」「バリューオブジェクト」といった多くの登場人物が存在します。私たちはこれらに対して、単にLintのルールを作るだけでなく、システム全体で共通となる抽象的な基底クラスを定義しました。
各ドメインのモデルを実装する際は、必ずこの祖先クラスを継承することをルール化しました。これにより、エンティティが必ず持つべきプロパティ(IDなど)や、バリューオブジェクトとしての振る舞いが型レベルで強制されるようになり、「定義上と異なる誤った実装」が入り込む余地を根本から無くすことができました。
下記にルート集約の基底クラスの例を示します。
export abstract class RootEntityBase extends EntityBase {
private _domainEvents: BaseEventSchemaType[] = [];
public get domainEvents(): BaseEventSchemaType[] {
return this._domainEvents;
}
// 集約で発生したイベントを記録
public addDomainEvent(event: BaseEventSchemaType): void {
this._domainEvents.push(event);
}
public clearDomainEvents(): void {
this._domainEvents = [];
}
}
ESLintを用いたアーキテクチャ規約違反の自動検知
クリーンアーキテクチャやDDDにおける依存関係のルールや細かい規約をESLintのルールとして自作しました。
これにより、人間がPRレビューで些末な指摘をする前に、CI上で規約違反が自動的に弾かれる仕組みが完成し、レビューの負荷を劇的に下げることに成功しました。下記に使用した技術を参考までに示します。
-
ESLint v9 Flat ConfigJavaScriptおよびTypeScriptの静的解析ツール。v9から導入されたFlat Configにより、設定をJavaScript/TypeScriptのモジュールとしてシンプルに定義できる
-
@typescript-eslintESLintでTypeScriptコードを解析するためのパーサーとユーティリティ。カスタムルールの実装にはこのパッケージが提供する、
TSESLint.RuleModuleという型付きの仕組みを利用しています。 -
@typescript-eslint/rule-testerカスタム ESLint ルールをテストするための公式ユーティリティパッケージです。テストランナーはVitestを使用しています。各ルールの正常系・異常系をユニットテストで検証しています。これにより実際のプロダクションコードを触らずにルールの検証を行うことができます。
export default defineConfig([
{
plugins: { ddd: dddPlugin },
},
{
files: ["**/src/**/*.ts"],
rules: {
"ddd/entity-naming-convention": "error",
"ddd/dependency-direction-restriction": "error",
"ddd/no-cross-aggregate-entity-import": "error",
// ... 全14ルールを error で定義
},
},
])
各マイクロサービスでは、この共通設定をスプレッド構文で展開するだけです。
ここで活きてくるのが、ESLint v9 で導入された Flat Config の柔軟性です。共通パッケージではすべてのルールを error として定義していますが、DDD導入途中のサービスでは、同じルール名を後から再宣言することで warn に上書きできます。
// apps/auth-service/eslint.config.mjs(DDD導入途中のサービス)
import dddConfig from "@matchingagent/eslint-config-recommend/ddd";
export default defineConfig([
...dddConfig, // 共通設定を展開(全ルールが error)
{
files: ["**/src/**/*.ts"],
rules: {
// まだ全面適用できないルールだけ warn に上書き
"ddd/entity-naming-convention": "warn",
"ddd/usecase-responsibility-restriction": "warn",
},
},
]);
この仕組みによりルールの厳格さをサービスごとに柔軟にコントロールしながらも、ルールの定義自体は一箇所で管理できるため、DDDの規約がチーム全体で一貫性を保てています。
下記にルールの具体例を一つ示します。
no-cross-aggregate-entity-import
は、ある集約ルートが別の集約ルートを直接 import することを禁止するルールです。
// ❌ NG: 集約ルートファイル内で、別の集約ルートを直接importしている
import { OrderRootEntity } from "../order";
export class UserRootEntity extends RooEntityBase {
// User集約ルート
}
違反すると以下のようなエラーメッセージが表示され、解決策も提示されます。
error: 別の集約ルート 'orderRootEntity' をimportすることはできません。下記を検討してください
- 別集約と共有するプロパティがある場合はそのプロパティを値オブジェクトにする
- 集約を跨ぐ制約がある場合はdomain-serviceに切り出す
このルールの実装では、import 先のファイルの AST を実際にパースし、RootEntityBase を継承しているかどうかを動的に判定しています。単純なファイルパスのパターンマッチではなく、コードの意味的な構造を解析することで、誤検知を防いでいます。
保守運用について、今のところコストはほぼかかっていません。ルールの意図と適用条件を自然言語で与えるだけで、AST の解析ロジックからテストコードまでを一貫して生成してくれるように Skills で自動化しているので、開発者が TypeScript ESTree の AST 構造を深く理解している必要はありません。
さらに、全ルールに対して @typescript-eslint/rule-tester を用いたユニットテストを整備しているため、ESLint やパーサーのバージョンアップ時にも、既存ルールの挙動が壊れていないことを機械的に検証できます。
インフラレイヤーの自動生成による「ドメインへの集中」
開発者がドメインモデリングという本来一番時間を使うべきコアな作業に 100% 集中できるよう、API のルーターやリポジトリといったインフラ層のコードを自動生成する仕組みを構築しました。これにより、開発者は煩雑な外部 I/O 部分の実装から解放され、ビジネスロジックの表現のみに注力できるようになり、プロジェクト全体の開発スピードと品質が大きく底上げされました。
そこで私たちは、OpenAPI 定義と MongoDB スキーマを入力として、インフラ層のコードを自動生成する仕組みを構築しました。
ここでは MongoDB のスキーマ定義から、リポジトリを自動生成する仕組みを紹介します。
まず開発者はMongoDBスキーマ定義を用意します。
// infra/repository/mongo/model/user.ts(開発者が書く唯一のMongoDBスキーマ定義)
const schema = new Schema({
_id: { type: Number },
name: { type: String, index: true },
email: { type: String, index: true, unique: true },
});
上記のスキーマのフィールド定義とインデックス情報を解析し、ジェネレータは以下の 2 ファイルを自動生成します。
mongo/model/user.ts(スキーマ定義)
↓ 独自ジェネレーター
├── domain/interface/generated/user.ts ← リポジトリインターフェース
└── infra/repository/generated/user.ts ← 基底リポジトリクラス
生成ロジックの特徴は、スキーマのインデックス定義を読み取って、必要なメソッドを自動で判断する点です。
// generated/ 配下に自動生成されるクラス(手動編集禁止)
// user/infra/repository/generated/user.ts
export abstract class UserBaseRepository<E>
implements UserBaseRepositoryInterface<E>
{
// スキーマの _id: Number から、引数の型が number に自動決定される
async defaultFindOneById(_id: number): Promise<E | null> { /* ... */ }
async defaultFindOneByIdOrThrow(_id: number): Promise<E> { /* ... */ }
async defaultFindByIds(ids: number[]): Promise<E[]> { /* ... */ }
// index が貼られているプロパティでの検索メソッドも生成される
async defaultFindByName(names: string[]): Promise<E[]> { /* ... */ }
async defaultFindOneByEmail(email: string): Promise<E> { /* ... */ }
async defaultDeleteOneById(_id: number): Promise<void> { /* ... */ }
async defaultUpdateById(_id: number, entity: E): Promise<void> { /* ... */ }
async defaultCreate(entity: E): Promise<E> { /* ... */ }
// ...
}
開発者が実際に書くのは、自動生成されたクラスを継承し、ドメインモデルと DB ドキュメントの変換ロジックだけを実装する薄いコードです。下記にUser リポジトリを例に示します。
// 開発者が書く実装クラス
// user/infra/repository/userRepository.ts
class UserRepository
extends UserBaseRepository<UserRootEntity> // ← 自動生成されたクラスを extend
implements UserRepositoryInterface
{
// 自動生成されたクラスにメソッドが足りない場合は、自由にメソッドを追加可能
async findByCondition(
condition: UserFindCondition,
): Promise<{ users: UserRootEntity[]; total: number }> {
// ...ビジネス要件に応じた検索ロジック
return this.convertToEntity(userDoc);
}
// 開発者が書くのは DB データ ⇔ 集約の変換ロジックが中心
private convertToEntity(userDoc: UserDocument): UserRootEntity {
return UserRootEntity.reconstruct(
userDoc._id,
userDoc.name,
userDoc.created,
ChargeStatusObject.create(userDoc.status?.charge),
GenderObject.create(userDoc.gender),
);
}
}
ここで重要なのは、MongoDB の 1 コレクション = DDD における 1 集約とは限らないという点です。
ドメインモデル上の集約名と MongoDB のコレクション名が一致するとは限りませんし、一つの集約が複数のコレクションに分散して保存されることもあり得ます。(RDB における「複数テーブルを JOIN して 1 つの集約を組み立てる」のと同じ考え方です。)
そのため、自動生成された Repository クラスは abstract class として生成し、直接 usecase などから利用できないようにしています。これにより、必ず開発者に集約単位のリポジトリを実装することを構造的に強制しています。
この構造により、DB の世界とドメインモデルの世界を橋渡ししながら、開発者の関心をドメインモデル側に寄せることができました。
プロジェクトを終えて
モノレポからの脱却とDDDによる既存機能の資産化。この移行プロジェクトを通じて、タップルのバックエンドはこれからのビジネスの変化に柔軟に対応できる堅牢なシステムへと生まれ変わりました。 そして気づけば、当初はプロジェクト内だけで泥臭く進めていたDDDの取り組みやオンボーディングの仕組みが、今やタップルの全バックエンドエンジニアに浸透し、組織の新たな文化へと定着しています。
さらに、システムをマイクロサービスへ分割したことは、開発組織のあり方にも変化をもたらしました。各機能開発チームが、それぞれのマイクロサービスのオーナーとして権限と責任を持つようになったのです。
これにより、モデリング、レビュー、リリース等の一連のサイクルが各チームへ完全に委譲される状態が実現し、モノレポ時代と比較して開発生産性が向上するという大きな恩恵をもたらしています。
おわりに
本プロジェクトのリーダーに任命された当時、私はまだ入社2年目でした。巨大なシステム移行に大きな不安もあり、いくつかインシデントも起こしました。しかしその度にチームメンバーに助けられながら課題を一つ一つ乗り越え、チームで無事に完遂することができました。そして大変ありがたいことに、この功績からサイバーエージェントのベストエンジニアに選出していただくことができました。
タップルには、若手であってもこのような挑戦を任され、エンジニアとして圧倒的に成長できる環境があります。堅牢なシステムと共に進化し続けるタップルの開発組織に少しでも興味を持っていただけた方は、ぜひ私たちと一緒に働きましょう!
最後までお読みいただき、ありがとうございました。