
目次
はじめに
こんにちは。メディア統括本部 Data Science Center(DSC)の山田(@___ryamaaa)です。6月15〜18日にサンフランシスコで開催された Databricks Data + AI Summit(DAIS)に現地参加してきました。この記事では、初めて現地参加してみた感想と、Keynote やセッションで得られた知見をまとめておきます。
Databricks Data + AI Summit とは
Databricks が年に1度開催する、データ・AI エンジニア向けの大規模カンファレンスです。
Keynote で共有されていた数字では、今年の現地参加者は30,000名以上(前年比約1.5倍)、バーチャル視聴は数十万人規模で、過去最大規模の開催となりました。日本からも500名以上が現地入りしており、前年の280名からほぼ倍増という規模だったそうです。

毎年ここで多くのアップデートが集中して発表されるため、Databricks を使うエンジニアには欠かせないイベントです。今年も新機能の発表ラッシュだったので、特に気になったものをこの後で紹介します。
Keynote 全体感
今年も Keynote で様々なアップデートがありました。CEO の Ali Ghodsi 氏が一貫して言っていたのは「AI モデル自体はもう十分に賢い。差がつくのは、そこに渡す自社の文脈とガバナンスのほうだ」というメッセージで、これが今年の DAIS の大きなテーマだったと思います。
繰り返し登場したのが、以下の4つのキーワードです。
- Context — 社内データ・知識を一つの基盤に集約してエージェントに渡す
- Control — アクセス制御・ガバナンス・AI 利用の可視化
- Cost — 予算超過時の自動ブレーキやリソース効率化
- Choice — 複数モデル・ハーネスを柔軟に選んで切り替えられる
いずれもエージェント時代に AI を本番で動かすための土台、という位置づけです。今回発表された新機能も、すべてこの4つのどこかに紐づくように整理されていました。
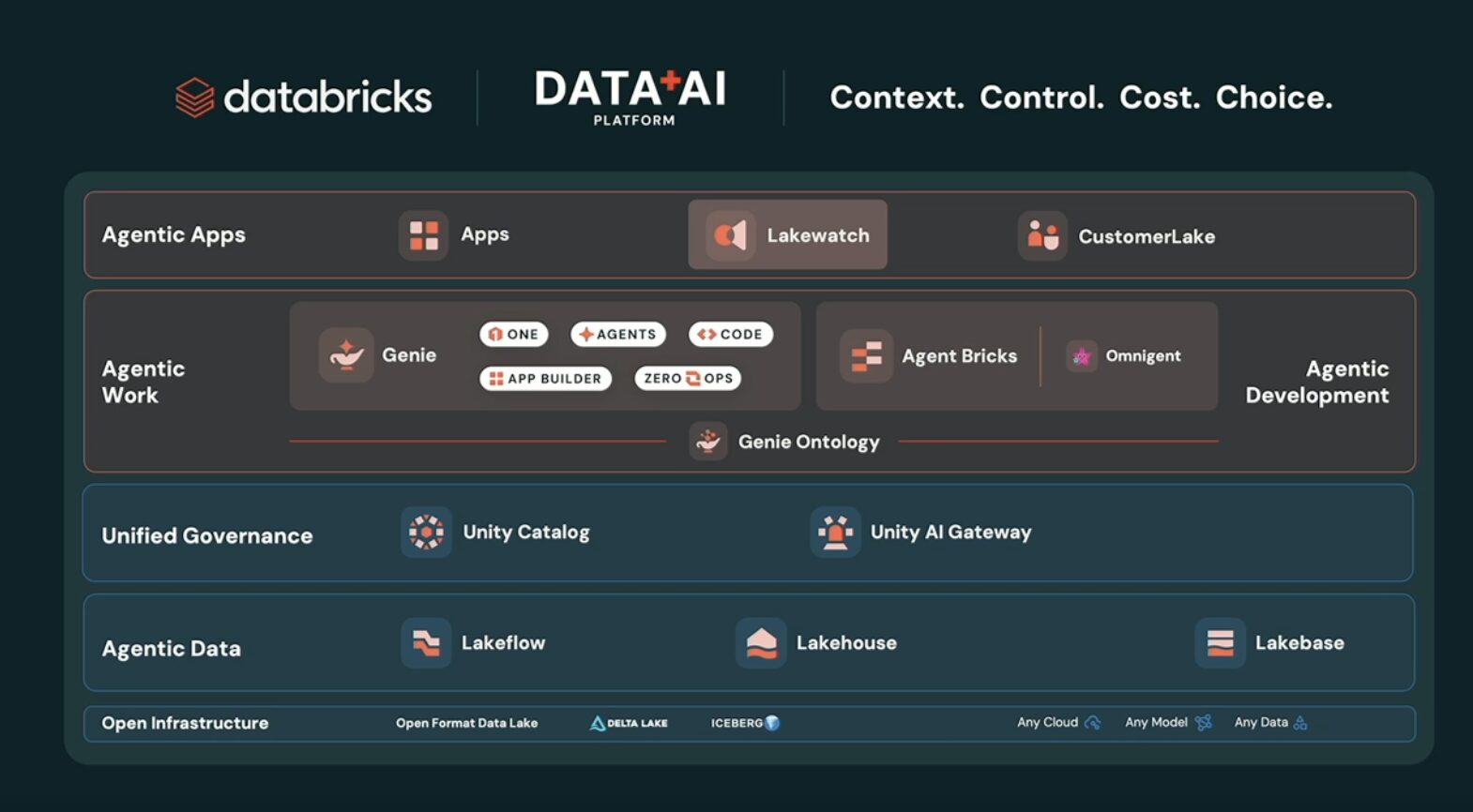
- Agentic Apps: Apps・Lakewatch・CustomerLake
- Agentic Work: Genie(ONE・AGENTS・CODE・APP BUILDER・ZERO OPS)、Agent Bricks、Omnigent
- Unified Governance: Unity Catalog・Unity AI Gateway
- Agentic Data: Lakeflow・Lakehouse・Lakebase
- Open Infrastructure: Delta Lake・Iceberg など、マルチクラウド・マルチモデル対応の基盤
データ処理基盤からエージェント開発、ガバナンスまでを一気通貫で押さえる、という方針が読み取れます。
Keynote の詳細が気になる方は YouTube の公式配信をぜひご覧ください。Day 1 はこちら、Day 2 はこちらで視聴できます。
Keynote で気になった新機能
ここからは、個人的に気になった発表をいくつかピックアップして紹介します。
Genie Ontology — Unity Catalog をエージェントの文脈源泉に
2024年6月にリリースされた当初の Genie は、自然言語で構造化データに質問できる、いわばチャットボット的な位置づけでした。今回これが Genie ファミリーとして整理し直され、Genie One・Genie Agents・Genie Code・Genie App Builder・Genie ZeroOps、そしてこれらを横断的に支える Genie Ontology という構成になりました。テーマは「AI アシスタントから AI ワーカーへ」で、扱える対象がぐっと広がっています(全体像は前掲のプラットフォーム図を参照)。
なかでも個人的に面白かったのが Genie Ontology。Unity Catalog 上のテーブル・クエリ・ダッシュボード・パイプラインに加えて、ドキュメントや Wiki、チケット、チャットスレッドといった実務データから「ナレッジの断片」を自動で抽出して、概念どうしの関係を持った生きたコンテキストグラフとして整理する、というものです。関係性の重み付けには OntoRank という独自アルゴリズム(PageRank の発想に近いもの)が使われていて、どの情報を信頼すべきかを自動で算出する仕組みになっていました。
“Ontology enables accurate search and access to your context”
社内ベンチマークでは、オントロジーなしのコーディングエージェントと比べて、Genie Ontology を使った場合に初回試行の正答率が大幅に上がった、というデータも示されていました。Unity Catalog をちゃんと整備することが、そのままエージェントに渡す文脈の質に効く。今年のテーマと繋がる発表でした。データ基盤を作る側としても、テーブルや権限だけでなく、業務知識まで含めて「AI に渡せる状態」にしておく重要性を感じました。
Genie ZeroOps — データ運用そのものをエージェントに任せる
DevOps から DataOps へ、というのが過去10年の流れだったとすると、今回打ち出されたのはその先、Ops 自体をゼロに近づける ZeroOps という考え方でした。データ運用でしんどいのは新規構築よりも本番障害のトラブルシュートで、上流のスキーマ変更でジョブが落ちたり、不正なデータが混入してテーブルが壊れたり、ML モデルが静かにドリフトして気付かないうちに精度が落ちていたりと様々な問題が起こりうります。Genie ZeroOps はそこを Databricks に組み込まれたバックグラウンドエージェントに任せていこう、という発表でした。
動き方は以下の4ステップです。
- 検出: プラットフォームのオブザーバビリティで継続的に監視(サイレント障害も含む)
- 分析: Unity Catalog のリネージで依存関係をたどって根本原因を特定
- 修復: エージェントがコード修正案を生成
- 検証: シャロークローン(実データを複製せずメタデータだけ複製する方式)と権限・ネットワーク隔離のサンドボックスを使って本番データで検証し、人間が承認したら本番適用
ポイントは、外部の AI エージェントだとそもそも踏み込みづらい、テレメトリ / リネージ / 本番データへの安全アクセスが、Databricks の中で完結するからこそ成立するところです。ジョブやパイプラインだけでなく、テーブルの品質問題や ML モデルのドリフトまでカバー対象になっていて、データ運用チームとしてはかなり嬉しい範囲にみえました。
Omnigent — 複数エージェントを束ねるメタハーネス
Claude Code・Codex・Cursor など、AI エージェントの実行環境(=ハーネス)が一気に増えて、いまやエージェント戦国時代のような状況です。スキル定義やシステムプロンプトといった設定が各ハーネスに紐付いてしまっているので、別のエージェントでも試してみたいと思っても乗り換えコストが高い、というケースが増えてきているかなと思います。Omnigent はハーネスの上にもう1層、共通レイヤーを置くという発想で発表されたメタハーネスで、OSS として公開されています。
できることを大きく3つに分けると、以下のような感じです。
- Composition: Claude Code を本体に置きながら、調査は Codex、レビューはまた別のハーネス、みたいな構成を同じセッションの中で組めます。Claude Code 側のスキルやプロンプトもそのまま引き継げるので、乗り換えのハードルが下がります。
- Control: ポリシーを YAML で書いておけば、サーバー全体/エージェント単位/セッション単位の3レイヤで重ね掛けできます。実行前の人手承認、1セッションあたりのツール呼び出し回数の上限、コスト上限での強制ストップなど、粒度の違うルールを同じ枠組みで効かせられます。
- Collaboration: 実行中のセッションを URL でチームに共有すれば、メンバーがブラウザから入ってきて、同じセッション内で会話できます。途中の発話にインラインコメントを残し、そこからエージェントに続きを任せる、という使い方もできるそうです。
デスクトップアプリ・モバイル両対応で気軽に試せます(インストール手順)。組織で複数のコーディングエージェントを安全に広げていきたい、というケースには、有力な選択肢になりそうです。個人的にも、エージェントを一つに決め打ちするより、用途ごとに使い分ける前提の運用設計が必要になっていくと感じました。
Unity AI Gateway — AI 利用を組織全体でガバナンスする
実際にエージェントを業務に組み込もうとすると、エージェント本体だけでなく、データ供給・外部ツール連携・ガバナンスといった周辺の仕組みも一緒に作る必要があります。エンタープライズではこの塊を量産することになるので、それを効率よく安全に作るための土台が要ります。
Unity AI Gateway は、LLM エンドポイント、MCP サーバー、Claude Code や Codex CLI のようなコーディングエージェントの利用を、Databricks 側で統制するための中央ガバナンス層です。ユーザー・ロール・アプリ単位で利用状況やコストを把握し、権限、レート制限、ガードレール、監査ログを同じ面で扱えます。
管理対象が広いのも特徴で、ファウンデーションモデルのプロンプト・応答だけでなく、MCP(モデルにツールを提供する標準プロトコル)サーバーやツール呼び出し、エージェントのアクション、AI ツール間のランタイムなやり取りまで含みます。
タスクの複雑度に応じてモデルを自動で振り分ける Smart Routing のデモも紹介されていました。すべてのタスクを高性能なフロンティアモデルに投げるのではなく、タスクに応じて必要十分なモデルを選んでくれるのは、実運用でかなりありがたい仕組みだと思います。
会場の様子
Moscone Center は広大な施設で、Keynote ホール・セッションルーム・EXPO ブース・ハンズオンエリアなどが複数の建物に分かれて配置されています。移動だけでも結構な距離を歩きました。



ランチは屋外スペースで配布されていました。サンフランシスコの6月は気温がちょうどよく、外で食べるのも気持ちよかったです。

Hands On Labs のエリアでは、Databricks のプロダクトを実際に触れるハンズオンも開催されていました。
印象に残ったセッション
DAIS は4日間で数百のセッションが並行で走る規模なので、中でも印象に残ったセッションを少しだけ簡単に紹介します。
Agentic Admins: Managing Databricks @ Databricks
エージェントが10万単位で動く未来に、人間が承認チケットを捌き続けるのはもたない、という問題提起から始まったセッションでした。
そこに対する答えとして、Databricks が自社の Databricks 環境を管理するために Agentic Admins(プラットフォーム管理を自律的に行うエージェント)を構築している、という話です。
具体的には、承認の判断を「明らかに安全なので自動承認できるもの」「社内のデータや権限情報を見ればエージェントが判断できるもの」「人間が見るべきもの」の3つに分ける設計でした。全部を人が見るのではなく、自動化できるところを少しずつ増やしながら、人間の判断は例外的なケースに残していく、という考え方です。
最終的にボトルネックになるのは人が判断する時間で、毎回人が見る前提ではなく、よくある判断は仕組みに寄せていく必要がありそうです。
Vendor Sprawl to Lakeflow: Scaling a Governed, Multi-Tenant Platform
ツールが増えすぎてガバナンスとデータ民主化のバランスが崩れる、というよくある悩みに対して、Databricks を単なる分析ツールではなく、再利用可能なデータプラットフォームとして扱う、という事例でした。
Terraform や Lakeflow などを組み合わせて、新しい事業部や新しいデータソースを設定追加だけでオンボードできるようにする、という方向性です。Databricks 上に分析環境を作るというより、データ基盤そのものをプロダクトとして育てていく考え方に近かったです。
そのうえで、Workspace・Tenant・Catalog をそれぞれ別の境界として整理し、必要な設定やコードをモノレポで管理していました。オンボーディングや変更管理を標準化しておくことの大事さを、改めて感じました。
おまけ
ワールドカップも観てきました
DAIS 2026 の開催期間は FIFA ワールドカップ 2026 と重なっていました。今大会はアメリカ・カナダ・メキシコの3カ国共催で、サンフランシスコも開催都市のひとつだったのでスタジアム観戦も楽しんできました。

EXPO ブースでも FOX Sports が出展していて、Lakebase を使ったスポーツ中継のユースケースをテーマにした展示がありました。ブースでは試合映像も流れていて、カンファレンスと W杯が同じ街で同時に開催されているという、なかなかない体験でした。

まとめ
DAIS 2026 全体を通じて感じたのは、AI を「使えるようにする」フェーズから、「本番で安全に使いこなす」フェーズへ移ってきている、ということです。どのセッションでも、ガバナンスなしの AI 展開は危うい、データ基盤の品質がそのまま AI 活用の差になる、という前提が共有されていました。
「AI はもう十分賢い、あとはコンテキスト管理だ」というメッセージは、裏を返せば、データを整備する仕事の価値を改めて言い直したものだと感じます。データ基盤を作る側として、AI に使われる前提でデータ・権限・運用を整えることが、これまで以上に重要になりそうです。来年もぜひ参加したいです!